AKS 上の HDInsight 上の Apache Flink アプリケーション モード クラスター
大事な
AKS 上の Azure HDInsight は、2025 年 1 月 31 日に廃止されました。 この発表 でについて詳しく学びましょう。
ワークロードの突然の終了を回避するには、ワークロードを Microsoft Fabric または同等の Azure 製品 に移行する必要があります。
大事な
この機能は現在プレビュー段階です。 Microsoft Azure プレビューの 追加使用条件 には、ベータ版、プレビュー版、または一般公開されていない Azure 機能に適用される、より多くの法的条件が含まれています。 この特定のプレビューの詳細については、AKS プレビュー情報 Azure HDInsightを参照してください。 ご質問や機能の提案については、AskHDInsight に詳細を記載して送信し、Azure HDInsight Community をフォローしてさらなる更新情報をご確認ください。
AKS 上の HDInsight では、Flink アプリケーション モード クラスターが提供されるようになりました。 このクラスターを使用すると、使いやすいインターフェイスと Azure Resource Management Rest API を使用して、Azure portal を使用してクラスター Flink アプリケーション モードのライフサイクルを管理できます。 アプリケーション モード クラスターは、専用リソースを使用して大規模で実行時間の長いジョブをサポートし、リソース集中型または広範なデータ処理タスクを処理するように設計されています。
このデプロイ モードを使用すると、特定の Flink アプリケーションに専用リソースを割り当て、大規模なワークロードを効率的に処理するのに十分なコンピューティング能力とメモリを確保できます。

利点
ジョブ jar を使用してクラスターのデプロイを簡略化しました。
ユーザー フレンドリ REST API: AKS 上の HDInsight には、Update、Savepoint、Cancel、Delete などのアプリ モードジョブ操作を管理するためのわかりやすい ARM Rest API が用意されています。
ジョブの更新と状態管理の管理が簡単: ネイティブの Azure portal 統合により、ジョブを更新し、最後に保存した状態 (セーブポイント) に復元するための手間のかからないエクスペリエンスが提供されます。 この機能により、ジョブのライフサイクル全体にわたって継続性とデータの整合性が確保されます。
Azure Pipelines またはその他の CI/CD ツールを使用して Flink ジョブを自動化する: AKS 上の HDInsight を使用すると、Flink ユーザーはわかりやすい ARM Rest API にアクセスでき、Flink ジョブ操作を Azure Pipeline やその他の CI/CD ツールにシームレスに統合できます。
主な機能
セーブポイントを使用してジョブを停止および開始する: ユーザーは、以前の状態 (Savepoint) から Flink AppMode ジョブを正常に停止して開始できます。 セーブポイントを使用すると、ジョブの進行状況が確実に維持され、シームレスな再開が可能です。
ジョブの更新: ユーザーは、ストレージ アカウントの jar を更新した後、実行中の AppMode ジョブを更新できます。 この更新では、セーブポイントが自動的に取得され、新しい jar で AppMode ジョブが開始されます。
ステートレス更新: AppMode ジョブの新しい再起動の実行は、ステートレス更新によって簡略化されます。 この機能により、ユーザーは更新されたジョブ jar を使用してクリーンな再起動を開始できます。
セーブポイント管理: ユーザーはいつでも、実行中のジョブのセーブポイントを作成できます。 これらのセーブポイントを一覧表示し、必要に応じて特定のチェックポイントからジョブを再開するために使用できます。
キャンセル: ジョブを完全に取り消します。
の削除: AppMode クラスターを削除します。
Flink アプリケーション クラスターを作成する方法
前提 条件
次のセクションの前提条件を満たす:
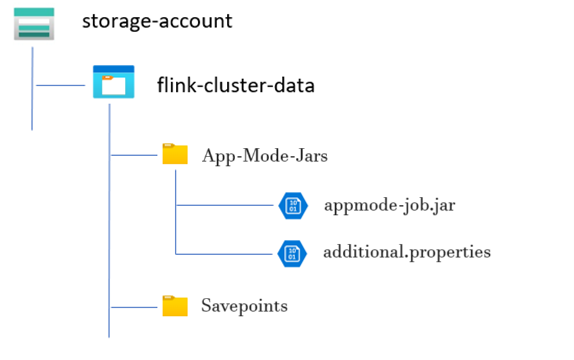
ストレージ アカウントにジョブジャーを追加する。
Flink アプリ モード クラスターを設定する前に、いくつかの準備手順が必要です。 これらの手順の 1 つは、クラスターのストレージ アカウントにアプリ モード ジョブ JAR を配置することです。
アプリ モード ジョブ JAR 用のディレクトリを作成します。
専用コンテナー内に、アプリ モード ジョブ JAR ファイルをアップロードするディレクトリを作成します。 このディレクトリは、Flink クラスターまたはジョブのクラスパスに含める JAR ファイルを格納する場所として機能します。
Savepoints ディレクトリ (省略可能):
ユーザーがジョブの実行中にセーブポイントを取得する場合は、これらのセーブポイントを格納するための別のディレクトリをストレージ アカウント内に作成します。 このディレクトリは、セーブポイントのチェックポイント データとメタデータを格納するために使用されます。
ディレクトリ構造の例:

Flink アプリ モード クラスターを作成する
Flink AppMode クラスターは、クラスター プールのデプロイが完了したら作成できます。既存のクラスター プールの使用を開始する場合の手順を確認します。
Azure portal で、「AKS の HDInsight クラスター プール/HDInsight/HDInsight」と入力し、AKS クラスター プール上の Azure HDInsight を選択してクラスター プール ページに移動します。 AKS クラスター プールの HDInsight ページで、新しい Flink クラスターを作成するクラスター プールを選択します。

特定のクラスター プール ページで、[+ 新しいクラスター] をクリックし、次の情報を入力します。
財産 説明 予約 このフィールドには、クラスター プールに登録された Azure サブスクリプションが自動的に入力されます。 リソース グループ このフィールドは、クラスター プール上のリソース グループを自動的に設定して表示します。 地域 このフィールドは、クラスター プールで選択されたリージョンを自動的に設定して表示します。 クラスター プール このフィールドは自動入力され、現在クラスターが作成されているクラスター プール名を表示します。 別のプールにクラスターを作成するには、ポータルでクラスター プールを見つけて、[+ 新しいクラスター] をクリックします。 HDInsight on AKS のプールバージョン このフィールドには、現在クラスターが作成中のクラスター プールのバージョンが自動入力されて表示されます。 AKS バージョンの HDInsight 新しいクラスターの AKS 上の HDInsight のマイナーバージョンまたはパッチ バージョンを選択します。 クラスターの種類 ドロップダウン リストから Flink を選択します。 クラスター名 新しいクラスターの名前を入力します。 ユーザー割り当てマネージド ID ドロップダウン リストから、クラスターで使用するマネージド ID を選択します。 マネージド サービス ID (MSI) の所有者であり、MSI にクラスターのマネージド ID オペレーター ロールがない場合は、ボックスの下のリンクをクリックして、AKS エージェント プール MSI から必要なアクセス許可を割り当てます。 MSI に既に適切なアクセス許可がある場合、リンクは表示されません。 MSI に必要な他のロールの割り当ての前提条件を参照してください。 ストレージ アカウント ドロップダウン リストから、Flink クラスターに関連付けるストレージ アカウントを選択し、コンテナー名を指定します。 マネージド ID には、クラスターの作成時に "ストレージ BLOB データ所有者" ロールを使用して、指定されたストレージ アカウントへのアクセス権がさらに付与されます。 仮想ネットワーク クラスターの仮想ネットワーク。 サブネット クラスターの仮想サブネット。 Flink SQL の Hive カタログの有効化:
財産 説明 Hive カタログを使用する 外部 Hive メタストアを使用するには、このオプションを有効にします。 Hive向けのSQLデータベース ドロップダウン リストから、hive-metastore テーブルを追加する SQL Database を選択します。 SQL 管理者ユーザー名 SQL Server 管理者のユーザー名を入力します。 このアカウントは、メタストアが SQL データベースと通信するために使用されます。 キーボールト ドロップダウン リストから、SQL Server 管理者ユーザー名のパスワードを含むシークレットを含む Key Vault を選択します。 クラスターの作成に使用されている MSI に対するキーのアクセス許可、シークレットのアクセス許可、証明書のアクセス許可など、必要なすべてのアクセス許可を持つアクセス ポリシーを設定する必要があります。 MSI には Key Vault 管理者ロールが必要です。 IAM を使用して必要なアクセス許可を追加します。 SQL パスワード シークレット名 SQL データベースのパスワードが格納されている Key Vault のシークレット名を入力します。 
手記
既定では、Hive カタログには、クラスターの作成時に使用されるストレージ アカウントとコンテナーと同じストレージ アカウントが使用されます。
[次へ: 構成] を選択して続行します。
[構成] ページで、次の情報を入力します。
財産 説明 ノード サイズ ヘッド ノードとワーカー ノードの両方の Flink ノードに使用するノード サイズを選択します。 ノードの数 Flink クラスターのノード数を選択します。既定では、ヘッド ノードは 2 です。 ワーカー ノードのサイズ設定は、Flink のタスク マネージャーの構成を決定するのに役立ちます。 ジョブ マネージャーと履歴サーバーはヘッド ノード上にあります。 [展開] セクションで、アプリケーション モード 展開の種類を選択、次の情報を指定します。
財産 説明 Jar パス ジョブ jar の ABFS (ストレージ) パスを指定します。 たとえば、 abfs://flink@teststorage.dfs.core.windows.net/appmode/job.jarエントリクラス (省略可能) アプリケーション モード クラスターのメイン クラス。 例: com.microsoft.testjob 引数 (省略可能) あなたのジョブのメインクラスの引数。 保存ポイント名 ジョブの起動に使用する古いセーブポイントの名前 アップグレード モード 既定のアップグレード オプションを選択します。 このオプションは、クラスターでメジャー バージョンのアップグレードが行われている場合に使用されます。 使用できるオプションは 3 つあります。 UPDATE: アップグレード後にユーザーが最後のセーブポイントから回復する場合に使用されます。 STATELESS_UPDATE: アップグレード後にユーザーがジョブを新たに再起動する場合に使用されます。 LAST_STATE_UPDATE: アップグレード後にユーザーが最後のチェックポイントからジョブを回復する場合に使用されます Flink ジョブの構成 Flink ジョブに必要な構成をさらに追加します。 [ジョブ ログの集計] を選択します。 ジョブ ログをリモート ストレージにアップロードする場合は、チェック ボックスをオンにします。 ジョブ問題のデバッグに役立ちます。 ジョブ ログの既定の場所は "StorageAccount/Container/DeploymentId/logs" です。 "pipeline.remote.log.dir" を構成することで、既定のログ ディレクトリを変更できます。 ログ収集の既定の間隔は 600 秒です。ユーザーは、"pipeline.log.aggregation.interval" を構成することで変更できます。
[サービス構成] セクションで、次の情報を指定します。
財産 説明 タスク マネージャーの CPU 整数。 タスク マネージャーの CPU のサイズを (コア単位で) 入力します。 タスク マネージャーのメモリ (MB 単位) タスク マネージャーのメモリ サイズを MB 単位で入力します。 最小 1,800 MB。 ジョブ マネージャーの CPU 整数。 ジョブ マネージャーの CPU の数を (コア単位で) 入力します。 ジョブ マネージャーのメモリ (MB) メモリ サイズを MB 単位で入力します。 最小 1,800 MB。 履歴サーバーの CPU 整数。 ジョブ マネージャーの CPU の数を (コア単位で) 入力します。 履歴サーバーのメモリ (MB) メモリ サイズを MB 単位で入力します。 最小 1,800 MB。 ![Apache Flink の [クラスターの作成] タブを示すスクリーンショット。](media/application-mode-cluster-on-hdinsight-on-aks/create-cluster-configuration-tab.png)
[次へ: 統合] ボタンをクリックして、次のページに進みます。
[統合] ページで、次の情報を指定します。
財産 説明 ログ分析 この機能は、クラスター プールに関連付けられている Log Analytics ワークスペースでログ収集を有効にした後に選択できる場合にのみ使用できます。 Azure Prometheus この機能は、Azure Monitor ワークスペースにメトリックとログを送信して、クラスター内の Insights とログを直接表示することです。 ![Apache Flink の [クラスター統合の作成] タブを示すスクリーンショット。](media/application-mode-cluster-on-hdinsight-on-aks/create-cluster-integrations-tab.png)
[次へ: タグ] ボタンをクリックして、次のページに進みます。
[タグ] ページで、次の情報を指定します。
財産 説明 名前 随意。 クラスター リソースに関連付けられているすべてのリソースを簡単に識別するために、AKS の HDInsight などの名前を入力します。 価値 これは空白のままにしておくことができます。 資源 選択したすべてのリソースを選択します。 [次へ: 確認と作成] を選択して続行します。
[確認と作成] ページで、ページの上部にある 検証に成功した メッセージを探し、[作成] をクリックします。


![Apache Flink の [クラスターの作成] タブを示すスクリーンショット。](media/application-mode-cluster-on-hdinsight-on-aks/create-cluster-configuration-tab.png#lightbox)
![Apache Flink の [クラスター統合の作成] タブを示すスクリーンショット。](media/application-mode-cluster-on-hdinsight-on-aks/create-cluster-integrations-tab.png#lightbox)
進行中のデプロイページが表示され、クラスターが作成されます。 クラスターの作成には 5 ~ 10 分かかります。 クラスターが作成されると、"デプロイが完了しました" というメッセージが表示されます。 ページから離れた場合は、通知で現在の状態を確認できます。
ポータルからアプリケーション ジョブを管理する
HDInsight AKS には、Flink ジョブを管理する方法が用意されています。 失敗したジョブを再起動できます。 ポータルからジョブを再起動します。
ポータルから Flink ジョブを実行するには、次の場所に移動します。
ポータル > HDInsight を AKS クラスタープール > Flink クラスター > 設定 > Flink ジョブ。

停止: ジョブの停止にパラメーターは必要ありませんでした。 ユーザーは、アクションを選択してジョブを停止できます。 ジョブが停止すると、ポータルのジョブステータスが「停止済み」に変更されます。
開始: セーブポイントからジョブを開始します。 ジョブを開始するには、停止したジョブを選択して開始します。
更新: 更新は、更新されたジョブ コードを使用してジョブを再開するのに役立ちます。 ユーザーは、ストレージの場所で最新のジョブ jar を更新し、ポータルからジョブを更新する必要があります。 このアクションは、セーブポイントを使用してジョブを停止し、最新の jar で再開します。
ステートレス更新: ステートレスは更新に似ていますが、最新のコードでジョブを新たに再起動する必要があります。 ジョブが更新されると、ポータル上のジョブの状態が [実行中] として表示されます。
セーブポイント: Flink ジョブのセーブポイントを取得します。
キャンセル: ジョブを終了させる。
削除: AppMode クラスターを削除します。
ジョブの詳細の表示: ジョブの詳細を表示するには、ユーザーがジョブ名をクリックすると、ジョブと最後のアクションの結果に関する詳細が表示されます。
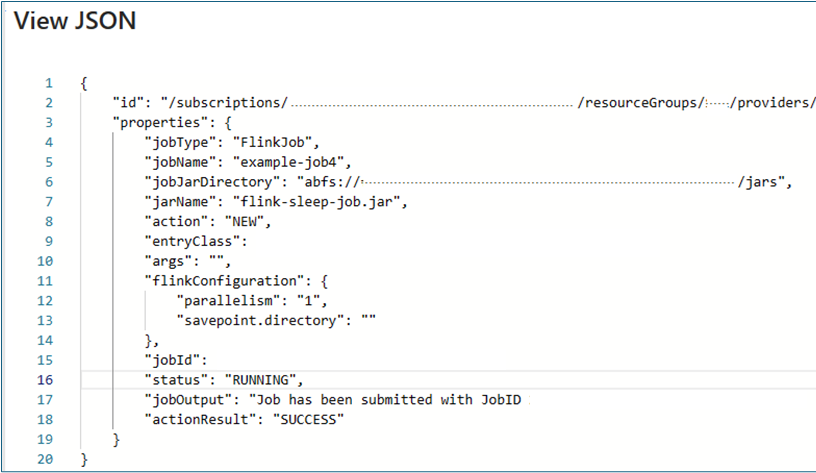

失敗したアクションの場合、この json ビューには、エラーの詳細な例外と理由が表示されます。