Network Performance Monitor ソリューション:パフォーマンスの監視
重要
2021 年 7 月 1 日以降、既存のワークスペースに新しいテストを追加したり、Network Performance Monitor で新しいワークスペースを有効にしたりできなくなります。 2021 年 7 月 1 日より前に作成されたテストは使い続けることができます。 現在のワークロードに対するサービスの中断を最小限に抑えるには、2024 年 2 月 29 日より前に、Network Performance Monitor から Azure Network Watcher の新しい接続モニターにテストを移行します。
Network Performance Monitor のパフォーマンス モニター機能を使うと、ネットワーク内のさまざまなポイントでネットワーク接続を監視できます。 クラウド展開やオンプレミスの場所、複数のデータ センターやブランチ オフィス、ミッション クリティカルな多層アプリケーション/マイクロ サービスを監視できます。 パフォーマンスの監視では、ユーザーから不満があがる前に、ネットワークの問題を検出できます。 次のような利点があります。
- 各種サブネット間の損失と待ち時間を監視し、アラートを設定する。
- ネットワーク上のすべてのパス (冗長パスを含む) を監視する。
- 再現が難しい、ネットワークに関する一過性の問題と特定時点の問題をトラブルシューティングする。
- パフォーマンス低下の原因となっている特定のセグメントをネットワーク上で見つけ出す。
- SNMP を必要とせずに、ネットワークの正常性を監視する。

構成
Network Performance Monitor の構成を開くには、Network Performance Monitor ソリューションを開き、 [構成] を選びます。
新しいネットワークの作成
Network Performance Monitor のネットワークは、サブネット用の論理コンテナーです。 必要に応じて、ネットワーク インフラストラクチャの監視を体系化するのに役立ちます。 フレンドリ名を付けたネットワークを作成し、ビジネス ロジックに従ってそのネットワークにサブネットを追加できます。 たとえば、London という名前のネットワークを作成し、London データ センター内のすべてのサブネットを追加できます。 または、ContosoFrontEnd という名前のネットワークを作成し、アプリのフロントエンドを提供する Contoso という名前のすべてのサブネットをこのネットワークに追加することもできます。 このソリューションでは、環境内で検出されたすべてのサブネットを含んだ、既定のネットワークが自動的に作成されます。
ネットワークを作成するたびに、サブネットをそれに追加します。 その後、そのサブネットは既定のネットワークから削除されます。 ネットワークを削除すると、その中のすべてのサブネットは既定のネットワークに自動的に戻されます。 既定のネットワークは、ユーザー定義のネットワークに含まれていないすべてのサブネット用のコンテナーとして機能します。 既定のネットワークは編集したり削除したりすることができず、 常にシステム内に存在します。 ユーザー定義のネットワークは必要な数だけ作成できます。 ほとんどの場合、組織内のサブネットは複数のネットワークに配置されています。 1 つまたは複数のネットワークを作成し、ビジネス ロジックに合わせてサブネットをグループ化します。
新しいネットワークを作成するには:
- [ネットワーク] タブを選びます。
- [ネットワークの追加] を選び、ネットワークの名前と説明を入力します。
- 1 つ以上のサブネットを選び、 [追加] を選びます。
- [保存] を選んで構成を保存します。
監視ルールの作成
Performance Monitor は、2 つのサブネットワーク間、または 2 つのネットワーク間のネットワーク接続のパフォーマンスがしきい値を超えた場合に、正常性イベントを生成します。 システムは、これらのしきい値を自動的に学習できます。 ユーザー設定のしきい値を指定することもできます。 既定のルールはシステムによって自動的に作成されます。一対のネットワーク/サブネットワーク リンクの間で発生した損失または待機時間がシステムの学習したしきい値を超えた場合に、このルールに従って正常性イベントが作成されます。 このプロセスによりソリューションは、監視ルールが明示的に作成されていない間もネットワーク インフラストラクチャを監視できます。 既定のルールが有効になっている場合、すべてのノードは、監視用に有効にされている他のすべてのノードに代理トランザクションを送信します。 既定のルールは、小規模なネットワークの場合に役立ちます。 たとえば、マイクロサービスを実行している少数のサーバーがあり、それらのサーバーすべてが相互に接続されていることを確認したいシナリオなどです。
Note
既定のルールを無効にし、カスタムの監視ルールを作成することをお勧めします (特に、多数のノードを監視用に使う大規模なネットワークの場合)。 カスタム監視ルールを作ると、ソリューションで生成されるトラフィックが減少し、ネットワークの監視を管理しやすくなります。
ビジネス ロジックに従って、監視ルールを作成します。 たとえば、本社に対する 2 つのオフィス サイトのネットワーク接続のパフォーマンスを監視するような場合です。 オフィス サイト 1 のすべてのサブネットをネットワーク O1 にグループ化します。 次に、オフィス サイト 2 のすべてのサブネットをネットワーク O2 にグループ化します。 最後に、本社のすべてのサブネットをネットワーク H にグループ化します。2 つの監視ルール (O1 と H の間、O2 と H の間) を作成します。
カスタム監視ルールを作成するには:
- [モニター] タブの [ルールの追加] を選び、ルールの名前と説明を入力します。
- 監視する一対のネットワーク リンクまたはサブネットワーク リンクを一覧から選択します。
- ネットワークのドロップダウン リストから目的のサブネットワークが含まれるネットワークを選びます。 次に、対応するサブネットワークのドロップダウン リストからサブネットワークを選びます。 ネットワーク リンク内のすべてのサブネットワークを監視する場合は、 [すべてのサブネットワーク] を選びます。 同様に、対象となるもう 1 つのサブネットワークを選びます。 選んだサブネットワーク リンク中の特定のものを監視の対象から除外するには、 [例外を追加] を選びます。
- 代理トランザクションの実行用に、ICMP プロトコルと TCP プロトコルのいずれかを選びます。
- 選んだ項目の正常性イベントを作成したくない場合は、 [このルールの対象になるリンクの稼働状況の監視を有効にする] をオフにします。
- 監視条件を選択します。 正常性イベントの生成に関するカスタムしきい値を設定するには、しきい値を入力します。 選んだネットワーク ペア/サブネットワーク ペアに対して選んだしきい値を条件の値が上回ると、正常性イベントが生成されます。
- [保存] を選んで構成を保存します。
監視ルールを保存した後、 [アラートの作成] を選んで、そのルールを Alert Management に統合することができます。 アラート ルールは、検索クエリで自動的に作成されます。 その他の必要なパラメーターは自動的に設定します。 アラート ルールを使うと、Network Performance Monitor 内の既存のアラートに加え、電子メール ベースのアラートを受け取ることができます。 アラートによって、Runbook で修正アクションをトリガーしたり、Webhook を使って、それらを既存のサービス管理ソリューションと統合させたりすることもできます。 アラートの設定を編集するには、 [Manage Alert]\(アラートの管理\) を選びます。
さらに、追加の Performance Monitor ルールを作成したり、ソリューション ダッシュボードから機能を使うこともできるようになりました。
プロトコルの選択
Network Performance Monitor では、代理トランザクションを使って、パケット損失やリンク待ち時間などのネットワーク パフォーマンス メトリックスを計算します。 この概念の理解を深めるために、ネットワーク リンクの一方の終端に接続された Network Performance Monitor エージェントについて考えてみます。 この Network Performance Monitor エージェントは、ネットワークの別の端に接続されている 2 つ目の Network Performance Monitor エージェントにプローブ パケットを送信します。 2 つ目のエージェントは応答パケットで応答します。 このプロセスが数回繰り返されます。 1 つ目の Network Performance Monitor エージェントは、応答の数と各応答を受信するまでの所要時間を測定することで、リンク待ち時間とパケットの破棄を評価します。
これらのパケットの形式、サイズ、シーケンスは、監視ルールの作成時に選択したプロトコルによって決定されます。 パケットのプロトコルに基づいて、中間ネットワーク デバイス (ルーター、スイッチなど) はこれらのパケットを異なる方法で処理することがあります。 そのため、プロトコルの選択は結果の精度に影響します。 プロトコルの選択によって、Network Performance Monitor ソリューションの展開後に手動手順を実行する必要があるかどうかも決まります。
Network Performance Monitor では、代理トランザクションを実行するために、ICMP と TCP のいずれかのプロトコルを選択できます。 代理トランザクションのルールを作成するときに ICMP を選んだ場合、Network Performance Monitor エージェントは ICMP ECHO メッセージを使ったネットワーク待ち時間とパケット損失を計算します。 ICMP ECHO では、従来の Ping ユーティリティによって送信されるものと同じメッセージを使います。 プロトコルとして TCP を使った場合、Network Performance Monitor エージェントはネットワーク経由で TCP SYN パケットを送信します。 その後、TCP ハンドシェイクが完了すると、RST パケットを使って接続が削除されます。
プロトコルを選ぶ前に、次の情報を考慮してください。
複数のネットワーク ルートの検出。 TCP は複数のルートを検出する際の精度が高く、各サブネットに必要なエージェントの数が少なくなります。 たとえば、TCP を使う 1 つまたは 2 つのエージェントでサブネット間のすべての冗長パスを検出できます。 ICMP を使って同様の結果を得るには、複数のエージェントが必要になります。 ICMP を使う場合、2 つのサブネット間に複数のルートがあるとすると、送信元サブネットまたは宛先サブネットに 5 個以上のエージェントが必要になります。
結果の精度。 ルーターやスイッチは、ICMP ECHO パケットに対して TCP パケットよりも低い優先順位を割り当てる傾向があります。 特定の状況で、ネットワーク デバイスの負荷が大きいときには、TCP で取得されるデータはアプリケーションで発生する損失と待ち時間をより厳密に反映します。 これは、アプリケーション トラフィックのほとんどが TCP 経由で流れるためです。 このような場合、TCP に比べ、ICMP では結果の精度が低くなります。
ファイアウォールの構成: TCP プロトコルでは、TCP パケットが宛先ポートに送信される必要があります。 Network Performance Monitor エージェントによって使われる既定のポートは 8084 です。 エージェントを構成するときに、ポートを変更することができます。 ネットワーク ファイアウォールまたは (Azure での) ネットワーク セキュリティ グループ (NSG) 規則が、このポートでのトラフィックを許可していることを確認してください。 また、エージェントがインストールされているコンピューターのローカル ファイアウォールが、このポートでのトラフィックを許可するように構成されていることも確認する必要があります。 Windows を実行しているコンピューターのファイアウォール規則は PowerShell スクリプトを使って構成できますが、ネットワーク ファイアウォールは手動で構成する必要があります。 これに対し、ICMP はポートを使って動作しません。 ほとんどのエンタープライズ シナリオでは、Ping ユーティリティなどのネットワーク診断ツールを使えるように、ICMP トラフィックはファイアウォールで許可されています。 コンピューター間で ping を実行できる場合、ファイアウォールを手動で構成しなくても、ICMP プロトコルを使うことができます。
Note
一部のファイアウォールでは、ICMP がブロックされ、その結果、再送信によってセキュリティ情報およびイベント管理システムに大量のイベントが生成されることがあります。 選んだプロトコルがネットワーク ファイアウォールまたは NSG によってブロックされないことを確認してください。 ブロックされると、Network Performance Monitor はネットワーク セグメントを監視できません。 監視には TCP を使うことをお勧めします。 次のような TCP を使用できないシナリオでは、ICMP を使います。
- Windows クライアントで TCP RAW ソケットが許可されていないために、Windows クライアントベースのノードを使っている場合。
- ネットワーク ファイアウォールまたは NSG で TCP がブロックされる場合。
- プロトコルを切り替える方法がわからない場合。
デプロイ時に ICMP を使用することを選択した場合、既定の監視ルールを編集することで、いつでも TCP に切り替えることができます。
- [ネットワーク パフォーマンス]>[監視]>[構成]>[監視] に移動します。 次に、[既定のルール] を選択します。
- [プロトコル] セクションまでスクロールし、使用するプロトコルを選びます。
- [保存] を選んで変更を適用します。
既定のルールで特定のプロトコルを使っている場合でも、別のプロトコルを使う新しいルールを作成できます。 一部のルールで ICMP を使い、別のルールで TCP を使っている場合は、ルールの組み合わせを作成することもできます。
チュートリアル
正常性イベントの根本原因の簡単な調査を見てみましょう。
ソリューション ダッシュボードで、正常性イベントがネットワーク リンクの異常を示します。 問題を調査するには、 [監視対象のネットワーク リンク] タイルを選びます。
ドリルダウン ページで、DMZ2-DMZ1 ネットワーク リンクが正常な状態でないことが示されます。 このネットワーク リンクの [View subnet links]\(サブネット リンクの表示\) を選びます。
ドリルダウン ページには、DMZ2-DMZ1 のネットワーク リンクのすべてのサブネットワーク リンクが表示されます。 両方のサブネットワーク リンクの待機時間がしきい値を超えており、そのためにネットワーク リンクの状態が異常になっています。 両方のサブネットワーク リンクについて待機時間の傾向を確認することもできます。 グラフの時間の選択コントロールを使って、必要な時間範囲に絞り込みます。 待機時間がピークに到達した時刻を確認できます。 後でこの期間のログを検索して問題を調査します。 詳しく調査するには、 [ノード リンクの表示] を選びます。
![[サブネットワーク リンク] ページ](media/network-performance-monitor-performance-monitor/subnetwork-links.png)
前のページと同様に、特定のサブネットワーク リンクのドリルダウン ページで、それを構成するノード リンクが一覧表示されます。 前の手順で実行したのと同様のアクションをここでも実行できます。 [トポロジの表示] を選び、2 つのノードの間にあるトポロジを表示します。
![[ノード リンク] ページ](media/network-performance-monitor-performance-monitor/node-links.png)
選択した 2 つのノードの間に存在するパスはすべてトポロジ マップにプロットされます。 2 つのノードの間にあるルートのホップバイホップ トポロジを、トポロジ マップで視覚化できます。 これにより、2 つのノードの間に存在するルートの数とデータ パケットに使われたパスが、わかりやすい図で表示されます。 ネットワーク パフォーマンスのボトルネックは赤で示されます。 問題のあるネットワーク接続またはネットワーク デバイスの場所を特定するには、トポロジ マップで赤い要素を確認します。
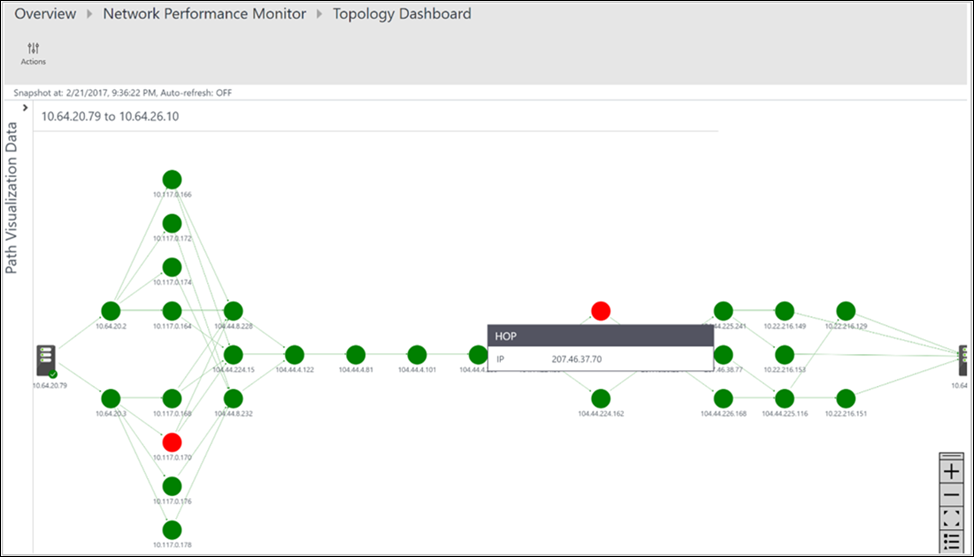
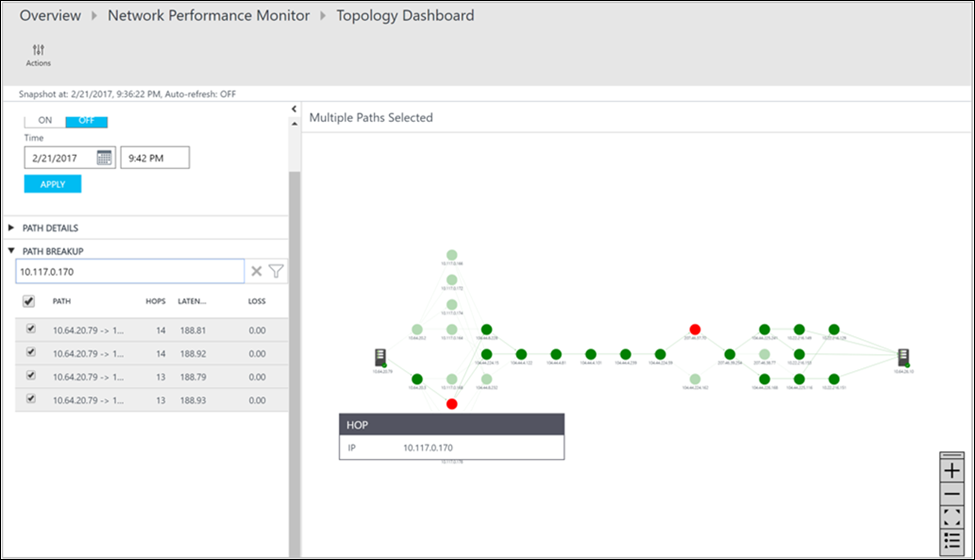
[操作] ウィンドウでは、各パスの損失、待ち時間、ホップの数を確認できます。 スクロール バーを使ってこれらの異常なパスの詳細を表示します。 フィルターを使用して、ホップに異常のあるパスを選択することで、選択したパスのみのトポロジがプロットされます。 トポロジ マップを拡大したり縮小したりするには、マウス ホイールを使います。
次の図では、ネットワークの特定のセクションに対する問題領域の根本原因が、赤のパスとホップで示されています。 トポロジ マップのノードを選ぶと、FQDN や IP アドレスなど、ノードのプロパティが表示されます。 また、ホップを選ぶとその IP アドレスが表示されます。
次のステップ
詳細なネットワーク パフォーマンスのデータ レコードを表示するために、ログを検索します。