並列コンピューティング ジョブについて
HPC Pack クラスターで実行できる並列コンピューティング ジョブの最も一般的な種類は、
このトピックでは、次の操作を行います。
MPI ジョブ の
SOA ジョブ を
する
MPI ジョブ
Windows 用に開発されたメッセージ パッシング インターフェイス (MPI) の Microsoft 実装である MS-MPI を使用すると、MPI アプリケーションを HPC クラスター上のタスクとして実行できます。
MPI タスクは本質的に並列です。 並列タスクは、アプリケーションとそれをサポートするソフトウェアに応じて、さまざまな形式をとることができます。 MPI アプリケーションの場合、並列タスクは通常、複数のコアで同時に実行される 1 つの実行可能ファイルで構成され、プロセス間で通信が行われます。
次の図は、並列タスクを示しています。
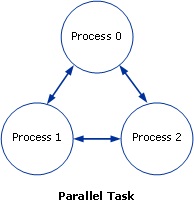
MPI アプリケーションを実行するタスクの場合、タスク コマンドの前に mpiexecを付ける必要があります。したがって、並列タスクのコマンドの形式は mpiexec [mpi_options] <myapp.exe> [arguments]である必要があります。ここで、myapp.exe は実行するアプリケーションの名前です。
mpiexec コマンドは、MPI プロセスの配置、ネットワーク アフィニティ、およびその他の実行時パラメーターを制御できるさまざまな引数を受け取ります。 これらのパラメーターの詳細については、Microsoft HPC Pack コマンド ライン リファレンスを参照してください。
手記
並列タスクの場合、Windows HPC Server 2008 には、アルゴンネ国立研究所の MPICH2 標準に基づく MPI パッケージが含まれています。 MS-MPI
SDK の詳細については、「Microsoft HPC Pack」を参照してください。
単一タスクまたは MPI ジョブを作成する方法については、「基本タスクまたは MPI タスクの定義 - ジョブ マネージャー」を参照してください。
パラメトリック スイープ ジョブ
パラメトリック スイープ ジョブは、同じアプリケーションの複数のインスタンス (通常はシリアル アプリケーション) で構成され、同時に実行され、入力ファイルによって入力され、出力ファイルに出力されます。 通常、入力と出力は、1 つの共通フォルダーまたは個別の共通フォルダーに存在するように設定された一連のインデックス付きファイル (input1、input2、input3..、output1、output2、output3...) です。 タスク間に通信や相互に依存する傾向はありません。 ジョブの実行中にクラスターで使用可能なリソースによっては、タスクが並列で実行される場合と実行されない場合があります。
次の図は、パラメトリック スイープ ジョブを示しています。
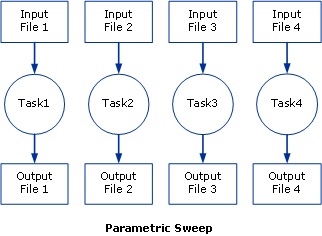
パラメトリック スイープ ジョブを作成する方法については、「パラメトリック スイープ タスクの定義 - ジョブ マネージャー」を参照してください。
タスク フロー ジョブ
タスク フロー ジョブでは、通常、あるタスクが別のタスクの結果に依存するため、一連の異なるタスクが所定の順序で実行されます。 ジョブには多くのタスクを含めることができます。その一部はパラメトリック、シリアル、および並列です。 たとえば、MPI タスクとパラメトリック タスクで構成されるタスク フロー ジョブを作成できます。 タスク間の依存関係を定義することで、タスクの実行順序を確立できます。
次の図は、タスク フロー ジョブを示しています。
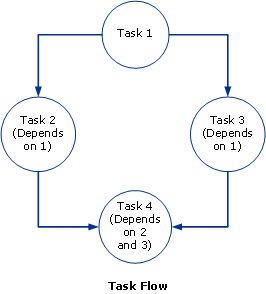
タスク 1 が最初に実行されます。 タスク 2 と 3 のみが並列で実行できる点に注意してください。これは、どちらも他方に依存しないためです。 タスク 4 は、タスク 2 と 3 の両方が完了した後に実行されます。
タスク フロー ジョブを作成する方法については、「タスクの依存関係の定義 - ジョブ マネージャー」を参照してください。
SOA ジョブ
サービス指向アーキテクチャ (SOA) は、分散型の疎結合システムを構築するためのアプローチです。 SOA システムでは、個別の計算関数は、サービスと呼ばれるソフトウェア モジュールとしてパッケージ化されます。 サービスは、ネットワーク全体に分散し、他のアプリケーションからアクセスできます。 たとえば、アプリケーションが並列計算を繰り返し実行する場合、コア計算をサービスとしてパッケージ化し、クラスターにデプロイできます。 これにより、開発者は、低レベルのコードを書き直すことなく、驚異的な並列問題を解決し、アプリケーションを迅速にスケールアウトできます。 アプリケーションは、複数のサービス ホスト (コンピューティング ノード) にコア計算を分散することで、より高速に実行できます。 エンド ユーザーはコンピューターでアプリケーションを実行し、クラスター ノードは計算を実行します。
クライアント アプリケーションは、エンドユーザーが 1 つ以上のサービスの機能にアクセスするためのインターフェイスを提供します。 開発者は、クラスター SOA クライアント アプリケーションを作成して、Windows HPC クラスターにデプロイされているサービスへのアクセスを提供できます。 バックエンドでは、クライアント アプリケーションは、Service タスクを含むジョブをクラスターに送信し、ブローカー ノードとのセッションを開始し、サービス要求を送信して応答 (計算結果) を受信します。 ヘッド ノードのジョブ スケジューラは、ジョブ スケジュール ポリシーに従ってサービス ジョブにリソースを割り当てます。 サービス タスクのインスタンスは、割り当てられた各リソースで実行され、SOA サービスを読み込みます。 ジョブ スケジューラは、サービス要求の数に基づいてリソースの割り当てを調整しようとします。
手記
クライアントが永続セッションを作成した場合、ブローカーは MSMQ を使用してすべてのメッセージを格納します。 ブローカーによって格納される応答は、意図的または意図しない切断後でも、いつでもクライアントによって取得できます。
次の図は、クラスターで SOA ジョブがどのように実行されるかを示しています。
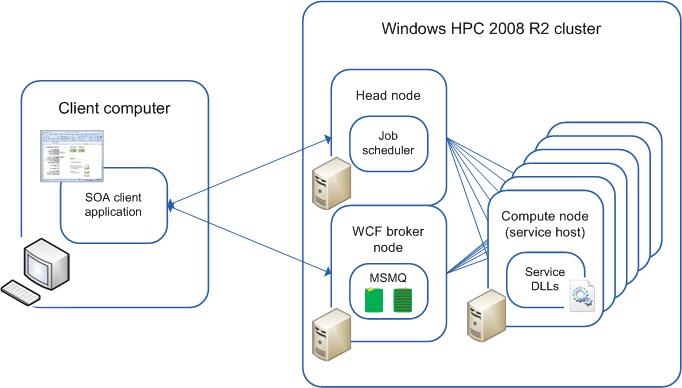
HPC クラスターの SOA クライアントの作成の詳細については、「SOA アプリケーションと Microsoft HPC Pack」を参照してください。
手記
HPC Services for Excel では、SOA インフラストラクチャを使用して、Microsoft Excel の計算をクラスターにオフロードできます。
Microsoft Excel の計算オフロード
HPC Pack の一部のバージョンに含まれる HPC Services for Excel では、Excel 計算を HPC Pack クラスターにオフロードするための多数のモデルがサポートされています。 クラスター アクセラレーションに適したブックには、並列で実行できる独立した計算が含まれます。 複雑で実行時間の長いブックの多くは繰り返し実行されます。つまり、異なる入力データ のセットに対して 1 回の計算を何度も実行します。 これらのブックには、複雑な Microsoft Visual Basic for Applications (VBA) 関数や計算負荷の高い XLL アドインが含まれている場合があります。HPC Services for Excel では、ブックをクラスターにオフロードしたり、UDF をクラスターにオフロードしたりできます。
Microsoft Excel 2010 は、Windows HPC クラスターで Excel 2010 UDF を実行できるようにすることで、UDF モデルをクラスターに拡張します。 サポートされているクラスターが使用可能な場合、ユーザーはクラスター コネクタを選択し、Excel オプション ダイアログ ボックスの [詳細 オプションでクラスター名を指定することで、そのクラスターを使用するように Excel 2010 に指示できます。 クラスターでは、UDF は従来の UDF とよく似ていますが、計算は 1 つ以上のサーバーによって実行される点が異なります。 主な利点は、並列化です。 ブックに実行時間の長い UDF の呼び出しが含まれている場合、複数のサーバーを使用して関数を同時に評価できます。 クラスターで実行するには、UDF をクラスターセーフな XLL ファイルに含める必要があります。
詳細については、「HPC Services for Excel」を参照してください。
その他の参照
並列コンピューティング ジョブの定義に使用できるジョブとタスクのプロパティについては、次を参照してください。
HPC ジョブ マネージャーを使用したジョブの作成、送信、監視の詳細については、以下を参照してください。
ジョブの作成と送信の - ジョブ マネージャー
コマンド プロンプト ウィンドウまたは HPC PowerShell を使用したジョブの作成、送信、監視の詳細、および SDK、SOA プログラミング モデル、Excel 計算オフロードの使用に関する情報など、開発者リソースについては、このドキュメント セットの追加の記事を参照してください。