概要
概要
Microsoft Power Query は、多くの機能を含む強力な "データの取得" エクスペリエンスを提供します。 Power Query の中核となる機能は、サポートされているデータ ソースの豊富なコレクションから 1 つ以上のデータをフィルター処理して結合する、つまり "マッシュアップ" することです。 そのようなデータのマッシュアップは、Power Query 数式言語 (非公式には M として知られています) を使用して表されます。 Power Query は、Excel、Power BI、Analysis Services、Dataverse など、さまざまな Microsoft 製品に M ドキュメントを埋め込み、繰り返し可能なデータのマッシュアップを可能にします。
このドキュメントでは、M の仕様を提供します。このドキュメントでは、言語に対する最初の直感と知識の構築を目的とした短い導入の後に、いくつかの段階的な手順で言語を詳細に説明しています。
"字句の構造" は、構文的に有効なテキストのセットを定義します。
値、式、環境、変数、識別子、評価モデルによって、言語の "基本概念" が形成されます。
"値" の詳細な仕様 (プリミティブと構造化の両方) によって、言語のターゲット ドメインが定義されます。
値には、それ自体が特殊な値である "型" があります。どちらも、基本的な種類の値を特徴付けて、構造化された値の形状に固有の追加のメタデータを保持します。
M では、"演算子" のセットによって、作成できる式の種類が定義されます。
もう 1 つの特別な値である "関数" は、M の豊富な標準ライブラリの基礎を提供し、新しい抽象化の追加を許可します。
式の評価中に演算子または関数を適用すると、"エラー" が発生することがあります。 エラーは値ではありませんが、エラーを値にマップする "エラーの処理" 方法があります。
"let 式" を使用すると、より少ない手順で複雑な式を作成するために使用される補助定義を導入できます。
"if 式" は条件付き評価をサポートします。
"セクション" は、単純なモジュール化メカニズムを提供します (Power Query ではまだセクションは活用されていません)。
最後に、"統合文法" は、このドキュメントの他のすべてのセクションから文法のフラグメントを 1 つの完全な定義に収集します。
コンピューター言語の研究者の場合: このドキュメントで指定されている数式言語のほとんどは、純粋、高階、動的に型指定された、部分的遅延の関数型言語です。
式と値
M の中央構造体は、"式" です。 式を評価 (計算) して、1 つの "値" を生成することができます。
多くの値は式としてリテラルに記述できますが、値は式ではありません。 たとえば、式 1 は値 1 として評価され、式 1+1 は値 2 として評価されます。 この区別は微妙ですが、重要です。 式は評価のレシピです。値は評価の結果です。
次の例は、M で使用できるさまざまな種類の値を示しています。規則として、値は、その値だけを評価する式に出現するリテラル形式を使用して書き込まれます (// は、行の末尾まで続くコメントの先頭を示していることにご注意ください)。
プリミティブ 値は、数値、論理、テキスト、null などの単一要素の値です。 null 値を使用すると、どのようなデータも存在しないことを示すことができます。
123 // A number true // A logical "abc" // A text null // null value"リスト" 値は順序を付けて値を並べたものです。 M では無限リストがサポートされていますが、リテラルとして記述されている場合、リストは固定長になります。 中かっこ文字
{と}は、リストの先頭と末尾を表します。{123, true, "A"} // list containing a number, a logical, and // a text {1, 2, 3} // list of three numbers"レコード" は、"フィールド" のセットです。 フィールドは、名前と値のペアであり、名前はそのフィールドのレコード内で一意のテキスト値です。 レコード値のリテラル構文では、引用符なしで名前を記述できます。"識別子" とも呼ばれる形式です。 次に示すのは、"
A"、"B"、"C" という 3 つのフィールドを含むレコードで、それぞれのフィールドには、1、2、3の値があります。[ A = 1, B = 2, C = 3 ]"テーブル" とは、列 (名前によって識別される) と行で構成される一連の値です。 テーブルを作成するためのリテラル構文はありませんが、リストまたはレコードからテーブルを作成するために使用できる標準関数がいくつかあります。
例:
#table( {"A", "B"}, { {1, 2}, {3, 4} } )これにより、次の形状のテーブルが作成されます。
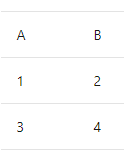
"関数" は、引数を指定して呼び出されると新しい値を生成する値です。 関数は、かっこで囲まれた関数の "パラメータ"、移動記号
=>、関数を定義する式を、この順序で列記することによって記述します。 この式は、通常、パラメーター (名前) を参照します。(x, y) => (x + y) / 2`
評価
M 言語の評価モデルは、スプレッドシートでよく見られる評価モデルに従ってモデル化されます。計算の順序は、セル内の式の間の依存関係に基づいて決定できます。
Excel のようなスプレッドシートで式を記述した場合、左側の数式が計算されると右側の値になります。

M では、式の一部が式の他の部分を名前で参照でき、評価プロセスによって、参照される式が計算される順序が自動的に決定されます。
レコードを使用して、前のスプレッドシートの例に相当する式を作成できます。 フィールドの値を初期化するときは、次のように、フィールド名を使用してレコード内の他のフィールドを参照できます。
[
A1 = A2 * 2,
A2 = A3 + 1,
A3 = 1
]
上の式は、次の式と同等です (どちらも等しい値に評価されます)。
[
A1 = 4,
A2 = 2,
A3 = 1
]
レコードは、他のレコードの中に含める ("入れ子" にする) ことができます。 "参照演算子" ([]) を使用して、レコードのフィールドに名前でアクセスできます。 たとえば、次のレコードには、レコードが含まれる Sales という名前のフィールドと、Sales レコードの FirstHalf および SecondHalf のフィールドにアクセスする Total という名前のフィールドがあります。
[
Sales = [ FirstHalf = 1000, SecondHalf = 1100 ],
Total = Sales[FirstHalf] + Sales[SecondHalf]
]
上の式は、評価される場合は次と同等です。
[
Sales = [ FirstHalf = 1000, SecondHalf = 1100 ],
Total = 2100
]
レコードは、リスト内に含めることもできます。 数値インデックスを使用してリスト内の項目にアクセスするには、"位置指定インデックス演算子" ({}) を使用できます。 リスト内の値を参照するには、0 から始まるリストの先頭からのインデックスを使用します。 たとえば、次のリストの 1 番目と 2 番目の項目を参照するには、インデックス 0 と 1 を使用します。
[
Sales =
{
[
Year = 2007,
FirstHalf = 1000,
SecondHalf = 1100,
Total = FirstHalf + SecondHalf // 2100
],
[
Year = 2008,
FirstHalf = 1200,
SecondHalf = 1300,
Total = FirstHalf + SecondHalf // 2500
]
},
TotalSales = Sales{0}[Total] + Sales{1}[Total] // 4600
]
リストおよびレコードのメンバー式 (および let 式) は、"遅延評価" を使用して評価されます。これは、必要な場合にのみ評価されることを意味します。 他のすべての式は、"即時評価" を使用して評価されます。これは評価プロセス中に検出されると、すぐに評価されることを意味します。 これについて考える良い方法は、リストまたはレコード式を評価すると、(参照またはインデックス演算子によって) 要求されたときに、リスト項目またはレコード フィールドがどのように計算される必要があるかを思い出させるリストまたはレコードの値が返されることを覚えておくことです。
関数
M では、"関数" は、一連の入力値からの 1 つの出力値へのマッピングです。 関数を記述するには、最初に必要な入力値のセット (関数のパラメーター) に名前を付け、次に、移動記号 (=>) の後にそれらの入力値 (関数の本体) を使用して関数の結果を計算する式を指定します。 次に例を示します。
(x) => x + 1 // function that adds one to a value
(x, y) => x + y // function that adds two values
関数は、数値またはテキスト値と同様の値です。 次の例は、後で他のいくつかのフィールドから "呼び出される" (実行される) Add フィールドの値である関数を示しています。 関数が呼び出されると、関数本文の式内の必要な入力値セットに論理的に置き換えられる値のセットが指定されます。
[
Add = (x, y) => x + y,
OnePlusOne = Add(1, 1), // 2
OnePlusTwo = Add(1, 2) // 3
]
ライブラリ
M には、"標準ライブラリ" (または単に "ライブラリ") と呼ばれる式から使用できる共通の定義セットが含まれています。 これらの定義は、一連の名前付きの値で構成されます。 ライブラリによって提供される値の名前は、式によって明示的に定義されていなくても、式内で使用できます。 次に例を示します。
Number.E // Euler's number e (2.7182...)
Text.PositionOf("Hello", "ll") // 2
オペレーター
M には、式で使用できる演算子のセットが含まれています。 演算子はオペランドに適用され、シンボリック式を形成します。 たとえば、式 1 + 2 では、1 と 2 の数値がオペランドで、演算子は加算演算子 (+) です。
演算子の意味は、オペランドの値の種類によって異なる場合があります。 たとえば、プラス演算子は、数値以外の種類の値にも使用できます。
1 + 2 // numeric addition: 3
#time(12,23,0) + #duration(0,0,2,0)
// time arithmetic: #time(12,25,0)
オペランド依存の意味を持つ演算子のもう 1 つの例として、複合演算子 (&) があります。
"A" & "BC" // text concatenation: "ABC"
{1} & {2, 3} // list concatenation: {1, 2, 3}
[ a = 1 ] & [ b = 2 ] // record merge: [ a = 1, b = 2 ]
演算子によっては、すべての値の組み合わせに対応していない場合があることに注意してください。 次に例を示します。
1 + "2" // error: adding number and text isn't supported
式は、評価されるときに、未定義の演算子条件がエラーとして評価されます。
Metadata
"メタデータ" は、値に関連付けられている値に関する情報です。 メタデータは、"メタデータ レコード" と呼ばれるレコード値として表されます。 メタデータ レコードのフィールドは、値のメタデータを格納するために使用できます。
すべての値には、メタデータ レコードがあります。 メタデータ レコードの値が指定されていない場合は、メタデータ レコードは空になります (フィールドはありません)。
メタデータ レコードは、追加情報を任意の種類の値に控えめな方法で関連付ける手段を提供します。 メタデータ レコードを値に関連付けても、値やその動作は変更されません。
メタデータ レコード値 y は、構文 x meta y を使用して既存の値 x に関連付けられます。 たとえば、次のコードでは、Rating フィールドと Tags フィールドを含むメタデータ レコードがテキスト値 "Mozart" に関連付けられています。
"Mozart" meta [ Rating = 5, Tags = {"Classical"} ]
空ではないメタデータ レコードを既に保持している値の場合、メタを適用した結果は、既存のメタデータ レコードと新しいメタデータ レコードのレコードのマージの計算になります。 たとえば、次の 2 つの式は、互いに同等で、前の式とも同等です。
("Mozart" meta [ Rating = 5 ]) meta [ Tags = {"Classical"} ]
"Mozart" meta ([ Rating = 5 ] & [ Tags = {"Classical"} ])
Value.Metadata 関数を使用して、特定の値のメタデータ レコードにアクセスできます。 次の例では、ComposerRating フィールドの式で Composer フィールドの値のメタデータ レコードにアクセスしてから、メタデータ レコードの Rating フィールドにアクセスします。
[
Composer = "Mozart" meta [ Rating = 5, Tags = {"Classical"} ],
ComposerRating = Value.Metadata(Composer)[Rating] // 5
]
Let 式
これまでに示した例の多くには、式の結果に式のすべてのリテラル値が含まれていました。 let 式を使用すると、一連の値を計算し、名前を割り当ててから、in に続く後続の式で使用できます。 たとえば、売上データの例では、次のようにできます。
let
Sales2007 =
[
Year = 2007,
FirstHalf = 1000,
SecondHalf = 1100,
Total = FirstHalf + SecondHalf // 2100
],
Sales2008 =
[
Year = 2008,
FirstHalf = 1200,
SecondHalf = 1300,
Total = FirstHalf + SecondHalf // 2500
]
in Sales2007[Total] + Sales2008[Total] // 4600
上記の式の結果は、Sales2007 と Sales2008 の名前にバインドされた値から計算された数値 (4600) です。
If 式
if 式は、論理条件に基づいて 2 つの式のどちらかを選択します。 次に例を示します。
if 2 > 1 then
2 + 2
else
1 + 1
論理式 (2 > 1) が true の場合は最初の式 (2 + 2) が選択され、false の場合は 2 番目の式 (1 + 1) が選択されます。 選択された式 (この場合は 2 + 2) が評価され、if 式の結果になります (4)。
エラー
"エラー" は、式を評価するプロセスが値を生成できなかったことを示します。
エラーは、エラー状態を検出した演算子や関数によって、またはerror 式を使用することによって、生成されます。 エラーは try 式を使用して処理されます。 エラーを生成するときは、エラーが発生した理由を示すために使用できる値を指定します。
let Sales =
[
Revenue = 2000,
Units = 1000,
UnitPrice = if Units = 0 then error "No Units"
else Revenue / Units
],
UnitPrice = try Number.ToText(Sales[UnitPrice])
in "Unit Price: " &
(if UnitPrice[HasError] then UnitPrice[Error][Message]
else UnitPrice[Value])
上の例では、Sales[UnitPrice] フィールドにアクセスし、結果を生成する値を書式設定しています。
"Unit Price: 2"
Units フィールドが 0 の場合、UnitPrice フィールドでエラーが発生し、try によって処理されます。 結果の値は次のようになります。
"No Units"
try 式では、適切な値とエラーが try 式で処理されたかどうか、またはエラーが発生したかどうかを示すレコード値と、エラーを処理するときに抽出された適切な値またはエラー レコードに変換されます。 たとえば、エラーを発生させてすぐに処理する次の式について考えてみます。
try error "negative unit count"
この式は、前の単価の例での [HasError]、[Error]、[Message] のフィールド参照を説明する、次のような入れ子になったレコード値に評価されます。
[
HasError = true,
Error =
[
Reason = "Expression.Error",
Message = "negative unit count",
Detail = null
]
]
一般的なケースは、エラーを既定値に置き換えることです。 try 式とオプションの otherwise 句を使用して、コンパクトな形式でそれだけを実現できます。
try error "negative unit count" otherwise 42
// 42