行のグループ化または要約
Power Query では、1 つ以上の列の値に従って行をグループ化することで、さまざまな行の値を 1 つの値にグループ化できます。 次の 2 種類のグループ化操作から選択できます。
列のグループ化。
行のグループ化。
このチュートリアルでは、次のサンプル テーブルを使用しています。
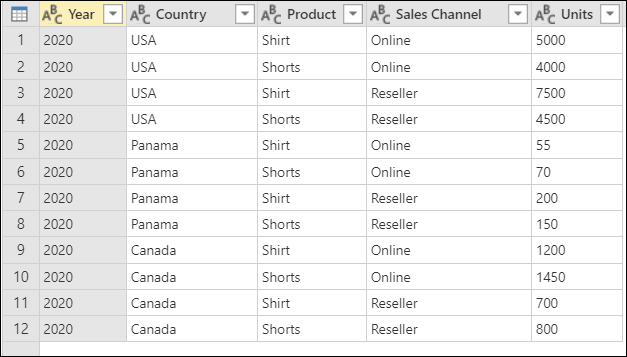
[Year] (2020)、[Country] (米国、パナマ、またはカナダ)、[Product] (シャツまたはショーツ)、[Sales Channel] (オンラインまたはリセラー)、[Units] (55 から 7500 までのさまざまな値) を示す列を含むテーブルのスクリーンショット
[グループ化] ボタンの場所
[グループ化] ボタンは、次の 3 つの場所で見つけることができます。
[ホーム] タブの [変換] グループ。
![[ホーム] タブで [グループ化] オプションが強調表示された Power Query のリボンのスクリーンショット。](media/group-by/home-icon.png)
[変換] タブの [テーブル] グループで。
![[変換] タブで [グループ化] オプションが強調表示された Power Query のリボンのスクリーンショット。](media/group-by/transform-icon.png)
ショートカット メニューで、右クリックして列を選択した場合。
![ショートカット メニューで [グループ化] オプションが強調されているテーブルのスクリーンショット。](media/group-by/right-click-icon.png)
集計関数を使用して 1 つ以上の列でグループ化する
この例での目標は、国と販売チャネルのレベルで販売された合計ユニット数を集計することです。 [Country] および [Sales Channel] 列を使用してグループ化操作を実行します。
- [ホーム] タブで [グループ化] を選択します。
- 複数の列を選択してグループ化できるように、[詳細] オプションを選択します。
- Country 列を選びます。
- [グループ化の追加] を選択します。
- [販売チャネル] 列を選択します。
- 新規列名に総合単位を入力、操作に合計を選択、列に単位を選択します。
- [OK] を選択します。
![集計列が入力された [グループ化] ダイアログのスクリーンショット。](media/group-by/add-aggregated-column-window.png)
この操作により、次の表が得られます。
![[Country]、[Sales Channel]、[Total units] 列を含むサンプル出力テーブルのスクリーンショット。](media/group-by/add-aggregated-column-final.png#lightbox)
利用可能な操作
Group by 機能を使用すると、使用可能な操作を 2 つの方法で分類できます。
- 行レベルの操作
- 列レベルの操作
次の表では、これらの各操作について説明します。
| 操作名 | カテゴリ | 説明 |
|---|---|---|
| Sum | 列の操作 | 列のすべての値を合計します |
| Average | 列の操作 | 列から平均値を計算します |
| 中央値 | 列の操作 | 列から中央値を計算します |
| Min (最小値) | 列の操作 | 列から最小値を計算します |
| Max (最大値) | 列の操作 | 列から最大値を計算します |
| Percentile | 列の操作 | 0 ~ 100 の入力値を使用して列からパーセンタイルを計算します。 |
| 個別の値をカウントする | 列の操作 | 列から個別の値の数を計算します。 |
| カウント | 行の操作 | 指定されたグループからの行の合計数を計算します。 |
| 個別の行をカウントする | 行の操作 | 指定されたグループからの個別の行の数を計算します。 |
| すべての行 | 行の操作 | テーブル値内のすべてのグループ化された行を集計なしで出力します。 |
Note
個別の値のカウント および パーセンタイル の操作は、Power Query Online でのみ使用できます。
1 つ以上の列でグループ化する操作を実行します。
この例では、元のサンプルから始めて、合計数量を含む列と、国および販売チャネル レベルで要約された最高成績の製品の名前と販売数量を示す他の 2 つの列を作成します。

[グループ化] 列として次の列を使用します。
- 国
- Sales Channel
次の手順に従って、2 つの新しい列を作成します。
- [合計] 操作を使用して [Units] 列を集計します。 この列に「Total units」という名前を付けます。
- [すべての行] 操作を使用して、新しい [Products] 列を追加します。
![非集計列を含む [グループ化] ダイアログのスクリーンショット。](media/group-by/row-operation-window.png)
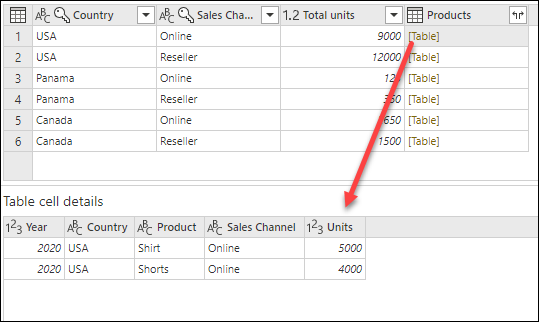
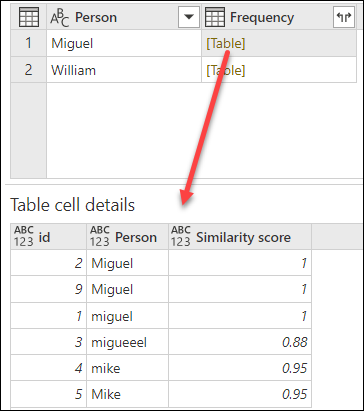
この操作が完了したら、Products 列の各セル内に [Table] の値がどのように含まれているかに注目してください。 各 [Table] 値には、元のテーブルの country 列と Sales Channel 列によってグループ化されたすべての行が含まれます。 セル内の余白を選択することにより、ダイアログの下部にそのテーブルの内容のプレビューを表示できます。
Note
詳細プレビュー ウィンドウに、グループ化操作に使用された一部の行が表示されないことがあります。 [Table] 値を選択すると、対応する group-by 操作に関連するすべての行を表示できます。
次に、新しい [Products] 列内にあるテーブルの [Units] 列の値が最も大きな行を抽出し、その新しい列に「Top performer product」という名前を付ける必要があります。
最も売れている製品の情報を抽出する
新しい商品列に[表]値を設定した状態で、リボンの列の追加タブを開き、全般グループからカスタムカラムを選択して新しいカスタム列を作成します。
![]()
この新しい列に「Top performer product」という名前を付けます。 [カスタム列の式] に数式 Table.Max([Products], "Units" ) を入力します。
![Table.Max の式が入力された [カスタム列] ダイアログのスクリーンショット。](media/group-by/row-operation-custom-column-formula.png)
その数式の結果により、[Record] 値を含む新しい列が作成されます。 これらのレコード値は、基本的には 1 行だけを含むテーブルです。 これらのレコードには、Products 列の各 [Table] 値の Units 列の最大値を含む行が含まれています。
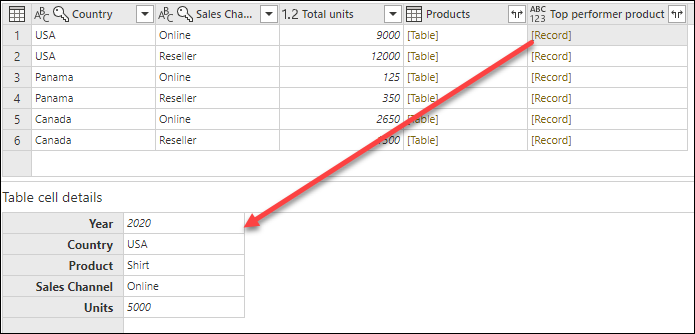
[レコード] 値を含むこの新しい トップパフォーマンス製品 列を使用すると、![]() 展開アイコンを選択し、 製品 と> ユニット を選択できます。 フィールドを選択し、OK を選択します。
展開アイコンを選択し、 製品 と> ユニット を選択できます。 フィールドを選択し、OK を選択します。
![[Top performer product] 列のレコード値の展開操作のスクリーンショット。](media/group-by/row-operation-custom-column-expand-window.png)
[Products] 列を削除し、新しく展開された両方の列のデータ型を設定すると、結果は次の画像のようになります。

あいまいグループ化
Note
次の機能は Power Query Online でのみ使用できます。
"あいまいグループ化" を実行する方法を示すには、次の画像に示されているサンプル テーブルを検討してください。
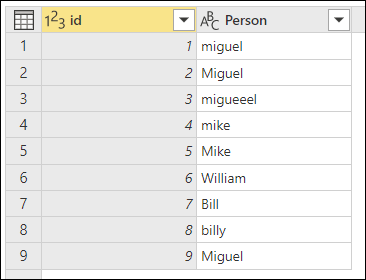
あいまいグループ化の目標は、テキスト文字列に対して近似一致アルゴリズムを使用するグループ化操作を実行することです。 Power Query では、Jaccard 類似性アルゴリズムを使用して、インスタンスのペア間の類似性を測定します。 次に、凝集型階層クラスタリングを適用してインスタンスをグループ化します。 次の画像は、テーブルが [Person] 列でグループ化されている、予測される出力を示しています。
![[Person] が Miguel と Mike、[Frequency] が 3 と 2 である入力を示すテーブルのスクリーンショット。](media/group-by/fuzzy-grouping-sample-final-table-no-transform-table.png)
あいまいグループ化を実行するには、この記事で前に説明したのと同じ手順を実行します。 唯一の違いは、今回は [グループ化] ダイアログ ボックスで [あいまいグループ化を使用する] チェック ボックスをオンにすることです。
![[グループ化] ダイアログ ボックスのあいまいグループ化のチェック ボックスのスクリーンショット。](media/group-by/fuzzy-grouping-button-group-by-window.png)
行の各グループに対して、Power Query では、最も頻度の高いインスタンスを "正規の" インスタンスとして選択します。 複数のインスタンスが同じ頻度で出現している場合は、Power Query によって最初のインスタンスが選択されます。 [グループ化] ダイアログ ボックスで [OK] を選択すると、予測していた結果が表示されます。
ただし、[あいまいグループオプション] を展開することによって、あいまいグループ化操作をより細かく制御できます。
![あいまいグループ オプションが強調されている [グループ化] ダイアログのスクリーンショット。](media/group-by/fuzzy-grouping-fuzzy-group-options.png)
あいまいグループ化では、次のオプションを使用できます。
- [類似性のしきい値 (省略可能)]: このオプションは、類似した 2 つの値をどのようにグループ化する必要があるかを示します。 最小設定の ゼロ (0) では、すべての値がグループ化されます。 最大設定の 1 では、厳密に一致する値のみがグループ化されます。 既定値は 0.8 です。
- [大文字と小文字を区別しない]: 文字列を比較するときに、大文字と小文字が無視されます。 既定では、このオプションは有効になっています。
- [テキストのパーツを組み合わせてグループ化する]: このアルゴリズムでは、テキストのパーツを組み合わせて (Micro と soft を Microsoft に組み合わせるなど) 値をグループ化することを試みます。
- 類似度スコアを表示: 入力値とファジーグループ化後に計算された代表値との間の類似度スコアを表示します。 この情報を行ごとのレベルで表示するには、すべての行 などの操作を追加する必要があります。
- [変換テーブル (省略可能)]: 値をマップして (MSFT を Microsoft にマッピングするなど) それらをグループ化する変換テーブルを選択できます。
この例では、値をどのようにマップできるかを示すために変換テーブルが使用されます。 この変換テーブルには、次の 2 つの列があります。
- From: テーブル内で検索するテキスト文字列。
- To: From 列のテキスト文字列を置き換えるために使用されるテキスト文字列。
次の画像は、この例で使用されている変換テーブルを示しています。
![mike と William という [From] の値と Miguel と Bill という [To] の値を示すテーブルのスクリーンショット。](media/group-by/fuzzy-grouping-sample-transformation-table.png)
重要
変換テーブルの列と列名は、前の図と同じであることが重要です ("From" と "To" というラベルが付けられている必要があります)。 それ以外の場合、Power Query はテーブルを変換テーブルとして認識しません。
[Group by] ダイアログ ボックスに戻り、ファジー グループ オプション を展開し、操作を行数 からすべての行 に変更し、[類似性スコアを表示]オプションを選択し、変換テーブルドロップダウン メニューを選択します。
![あいまいグループ化のサンプルの [変換テーブル] ドロップダウン メニューのスクリーンショット。](media/group-by/fuzzy-grouping-sample-transformation-table-window.png)
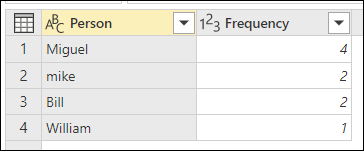
変換テーブルを選択したら、OK を選択します。 その操作の結果、次の情報が得られます。
この例では、ケースを無視 オプションが有効になっているため、変換テーブル の From 列の値が考慮されずにテキスト文字列を検索するために使用されます。 文字列の場合。 まず、この変換操作が実行されてから、あいまいグループ化操作が実行されます。
類似性スコアは、人物列の隣のテーブル値にも表示されます。これは、値がどのようにグループ化されたか、およびそれぞれの類似性スコアを正確に反映しています。 必要に応じてこの列を展開したり、新しい [頻度] 列の値を他の種類の変換に使用したりできます。
Note
複数の列でグループ化する場合、値を置換することで類似性スコアが増加する場合、変換テーブルはすべての列で置換操作を実行します。
変換テーブルのしくみの詳細については、「変換テーブルの規範」を参照してください。