標準データフローのフィールド マッピングに関する考慮事項
データを Dataverse テーブルにロードするときは、データフローの編集エクスペリエンスでソース クエリの列を宛先 Dataverse テーブルの列にマップします。 データのマッピング以外にも、考慮すべき考慮事項とベスト プラクティスがあります。 この記事では、データフロー更新の動作と、その結果として宛先テーブル内のデータを制御するさまざまなデータフロー設定について説明します。
データフローが更新ごとにレコードを作成するか更新/挿入するかを制御する
データフローを更新するたびに、ソースからレコードがフェッチされ、Dataverse にロードされます。 データフローを複数回実行すると (データフローの構成方法に応じて)、次のことが可能になります。
- 宛先テーブルにそのようなレコードが既に存在する場合でも、データフローが更新されるたびに新しいレコードを作成します。
- テーブルにレコードがまだ存在しない場合は新しいレコードを作成し、テーブルにすでに存在する場合は既存のレコードを更新します。 この動作はupsertと呼ばれます。
キー列を使用すると、宛先テーブルにレコードを更新/挿入するようデータフローに指示されますが、キーを選択しない場合は、宛先テーブルに新しいレコードを作成するようデータフローに指示されます。
キー列は、テーブル内のデータ行の一意で決定的な列です。 たとえば、Orders テーブルで、Order ID がキー列である場合、同じ Order ID を持つ 2 つの行があってはなりません。 また、1 つの注文 ID (たとえば、ID 345 の注文) は、テーブル内の 1 行のみを表す必要があります。 データフローから Dataverse のテーブルのキー列を選択するには、マップ テーブル エクスペリエンスでキー フィールドを設定する必要があります。
新しいテーブルを作成するときのプライマリ名とキー フィールドの選択
次の図は、データフローで新しいテーブルを作成するときに、ソースから設定されるキー列を選択する方法を示しています。
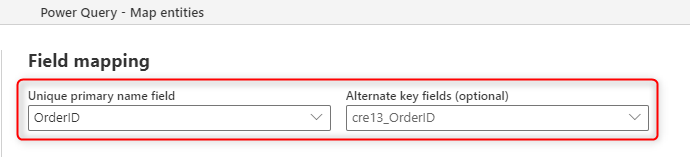
フィールド マッピングに表示されるプライマリ名フィールドはラベル フィールドのためのものです。このフィールドは一意である必要はありません。 テーブルで重複をチェックするために使用されるフィールドは、[ 代替キー] フィールドに設定したフィールドになります。
テーブルに主キーがあると、主キーにマップされたフィールドに重複したデータがある場合でも、重複したエントリがテーブルに読み込まれることがなくなります。 この動作により、テーブル内のデータの品質が維持されます。 テーブルに基づいたレポート ソリューションを構築するには、高品質のデータが不可欠です。
プライマリ名フィールド
プライマリ名フィールドは、Dataverse で使われる表示フィールドです。 このフィールドは、他のアプリケーションでテーブルの内容を表示するためにデフォルトのビューで使用されます。 このフィールドは主キー フィールドではないので、そのように考えないでください。 このフィールドは表示フィールドであるため、重複した値を持つことができます。 ただし、ベスト プラクティスは、連結フィールドを使ってプライマリ名フィールドにマップすることです。そのため、名前は完全に説明的です。
代替キー フィールドは主キーとして使われるものです。
既存のテーブルにロードする際のキー フィールドの選択
データフロー クエリを既存の Dataverse テーブルにマッピングする場合、宛先テーブルにデータをロードするときに使用するかどうか、およびどのキーを使用するかを選択できます。
次の図は、既存の Dataverse テーブルにレコードを更新/挿入するときに使用するキー列を選択する方法を示しています。

テーブルの一意の ID 列を設定し、それを既存の Dataverse テーブルにレコードを更新挿入するためのキー フィールドとして使用します
すべての Microsoft Dataverse テーブル行には、GUID として定義されている一意の識別子を持っています。 これらの GUID は各テーブルの主キーです。 デフォルトでは、テーブルの主キーはデータフローで設定できず、レコードの作成時に Dataverse によって自動生成されます。 たとえば、外部テーブルと Dataverse テーブルの両方で同じ主キー値を維持しながら、データを外部ソースと統合するなど、テーブルの主キーの活用が望ましい高度なユースケースがあります。
Note
- この機能は、既存のテーブルにデータをロードする場合にのみ使用できます。
- 一意の識別子フィールドは GUID 値を含む文字列のみを受け入れます。他のデータ型または値を使用すると、レコードの作成が失敗します。
テーブルの一意の識別子フィールドを利用するには、データフローの作成中に [テーブルのマップ] ページで [既存のテーブルにロード] を選択します。 次の図に示す例では、CustomerTransactions テーブルにデータを読み込み、データ ソースの TransactionID 列をテーブルの一意の識別子として使用します。
Select keyドロップダウンで、テーブルの一意の識別子 (常に「テーブル名 + ID」という名前) を選択できることに注意してください。 テーブル名は「CustomerTransactions」であるため、一意の識別子フィールドの名前は「CustomerTransactionId」になります。

選択すると、列マッピング セクションが更新され、宛先列として一意の識別子が含まれます。 その後、各レコードの一意の識別子を表すソース列をマップできます。
![データを [一意識別子] 列にマッピングします。](media/get-best-of-standard-dataflows/map-to-primary-key.png#lightbox)
キー フィールドに適した候補
キー フィールドは、テーブル内の一意の行を表す一意の値です。 このフィールドがあることは、テーブル内に重複レコードが存在することを避けるのに役立つため、重要です。 このフィールドは 3 つのソースから取得できます。
ソース システムの主キー (前述の例では OrderID など)。 データフロー内で Power Query の変換によって作成された連結フィールド。
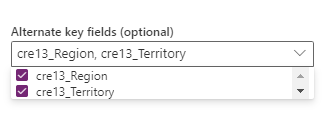
[代替キー] オプションで選ばれるフィールドの組み合わせ。 キー フィールドとして使われるフィールドの組み合わせは、複合キー とも呼ばれます。
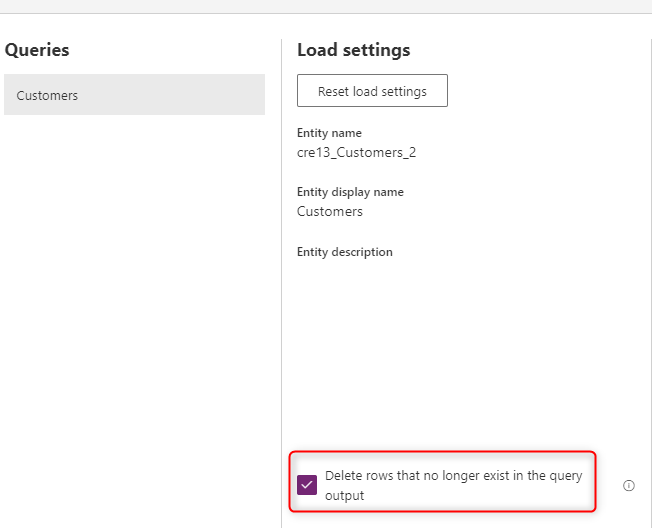
存在しなくなった行を削除する
テーブル内のデータをソース システムのデータと常に同期させたい場合は、クエリ出力に存在しなくなった行を削除 オプションを選択します。 ただし、このアクションを実行するには主キー (データフローのフィールド マッピングの代替キー) に基づいて行を比較する必要があるため、このオプションではデータフローが遅くなります。
このオプションは、次回のデータフロー更新のクエリ出力に存在しないデータ行がテーブル内にある場合、その行がテーブルから削除されることを意味します。
Note
標準 V2 データフローは、データフロー出力に存在しない行を宛先テーブルから削除するために、createdon フィールドと modifiedon フィールドに依存します。 これらの列が宛先テーブルに存在しない場合、レコードは削除されません。
既知の制限事項
- ポリモーフィックなルックアップ フィールドへのマッピングは、現在サポートされていません。
- 複数レベルのルックアップ フィールド (別のテーブルのルックアップ フィールドを指すルックアップ) へのマッピングは、現在サポートされていません。
- [状態] フィールドと [状態の理由] フィールドへのマッピングは現在サポートされていません。
- 改行文字を含む複数行テキストへのデータのマッピングはサポートされていないため、改行は削除されます。 代わりに、改行タグ
<br>を使用して、複数行のテキストを読み込んで保存することができます。 - 複数選択オプションを有効にして構成された Choice フィールドへのマッピングは、特定の条件下でのみサポートされます。 データフローは、複数選択オプションが有効になっている Choice フィールドにのみデータを読み込み、ラベルの値 (整数) のカンマ区切りリストが使用されます。 たとえば、ラベルが「Choice1、Choice2、Choice3」で、対応する整数値が「1、2、3」である場合、最初と最後の選択肢を選択するには、列の値を「1,3」にする必要があります。
- 標準 V2 データフローは、データフロー出力に存在しない行を宛先テーブルから削除するために、
createdonフィールドとmodifiedonフィールドに依存します。 これらの列が宛先テーブルに存在しない場合、レコードは削除されません。 - IsValidForCreate プロパティが
falseに設定されているフィールドへのマッピングは、サポートされていません (例えば、連絡先エンティティのアカウントフィールド)。