Power BI 散布図の高密度サンプリング
Power BI サンプリング アルゴリズムにより、散布図による高密度データの表現が向上します。
たとえば、一年あたりの各店舗のデータ ポイントが数万になる組織の営業活動から散布図を作成することがあります。 このような情報の散布図では、そのデータの有意な表現からデータをサンプリングして、時間の経過と共に売上がどのように発生しているかを示します。 高密度データ サンプリングの詳細は、この記事で説明しています。

Note
この記事で説明する高密度サンプリング アルゴリズムは、Power BI Desktop と Power BI サービスの両方の散布図に使用できます。
高密度散布図のしくみ
これまで、Power BI では、決定論的な方法で基になるデータ全体のサンプル データ ポイントのコレクションを選択して散布図を作成していました。 具体的には、Power BI では、散布図グラフの系列の最初と最後の行のデータを選択し、次に合計 3,500 個のデータ ポイントを散布図グラフにプロットできるように、残りの行を均等に分割します。 たとえば、サンプルに 35,000 行がある場合、プロットする最初と最後の行を選択し、次にすべての 10 番目ごとの行 (35,000/10 = すべての 10 番目ごとの行 = 3,500 データ ポイント) もプロットします。 また、以前は、データ系列内の null 値またはプロットできないポイント (テキスト値など) は表示されませんでした。そのためそれらは視覚化を生成するときに考慮されませんでした。 このようなサンプリングでは、散布図の見かけ上の密度も、表現可能なデータ ポイントに基づいているため、暗黙的な視覚的密度は、サンプリングされたポイントの状況であり、基になるデータの完全なコレクションではありませんでした。
高密度サンプリングを有効にすると、Power BI は、重複するポイントを排除するアルゴリズムを実装し、視覚化を操作するときに、視覚化上のポイントに確実に到達できるようにします。 また、このアルゴリズムではデータ セット内のすべてのポイントがビジュアルで表現されるので、代表的なサンプルのプロットだけではなく、選択されたポイントの意味を示すコンテキストが提供されます。
定義上、高密度データは、対話機能に応答する視覚エフェクトを作成するためにサンプリングされます。 視覚化のデータ ポイントが多すぎると低速になり、トレンドが見えにくくなるおそれがあります。 データのサンプリング方法は、最適な視覚化エクスペリエンスを提供して、すべてのデータを確実に表現する、サンプリング アルゴリズムの作成を促します。 Power BI では、アルゴリズムが改善され、全体的なデータ セットの重要なポイントの応答性、表現、および明確な保存の最適な組み合わせが提供されます。
注意
高密度サンプリング アルゴリズムを使用する散布図は、すべての散布図と同じように、正方形の視覚化にプロットするのが最も効果的です。
散布図サンプリング アルゴリズムのしくみ
散布図の高密度サンプリング用のアルゴリズムでは、基になるデータをより効果的に取得して表現する方法を採用し、重複するポイントを排除しています。 このアルゴリズムは、各データ ポイントの小さな半径 (視覚化の特定のポイントの視覚的な円のサイズ) から操作を開始します。 次に、すべてのデータ ポイントの半径を増加させます。 2 つ以上のデータ ポイントが重複する場合は、半径サイズが増加した 1 つの円がそれらの重複したデータ ポイントを表します。 このアルゴリズムでは、半径値の結果として適切な数のデータ ポイント (3,500) が散布図に表示されるようになるまで、データ ポイントの半径を増加し続けます。
このアルゴリズムのメソッドでは、外れ値が確実に結果のビジュアルで表現されます。 アルゴリズムは、さらに重複を判断するときにスケールを優先します。そのため、指数スケールが基になる視覚化されるポイントに忠実に視覚化されます。
アルゴリズムは、散布図の全体的な形状も維持します。
注意
散布図の高密度サンプリング アルゴリズムを使用する場合、目標はデータの "正確な分布" であり、視覚化の暗黙的な密度ではありません。 たとえば、特定のエリア内に多くの重複する円 (密度) がある散布図が表示され、多くのデータ ポイントがそこに集まる必要があるとします。 高密度サンプリング アルゴリズムでは、1 つの円を使用して多数のデータ ポイントを表すことができるため、このような視覚化の暗黙的な密度 (または "クラスタリング") は表示されません。 特定のエリアの詳細を取得するには、スライサーを使用してズーム インすることができます。
さらに、プロットできないデータ ポイント (null 値やテキスト値など) は無視されるので、プロットできる別の値が選択されます。 これにより、散布図の真の形がさらに確実に維持されます。
散布図の標準のアルゴリズムを使用する場合
高密度のサンプリングを散布図に適用できず、元のアルゴリズムが使用される状況があります。 そのような状況は次のとおりです。
[値] で値を右クリックして、メニューから [データのない項目を表示する] に設定した場合、散布図は元のアルゴリズムに戻ります。
[再生軸] フィールドに値がある場合、散布図は元のアルゴリズムに戻ります。
散布図の X と Y の両方の軸が存在しない場合、図は元のアルゴリズムに戻ります。
[分析] ウィンドウで [比率線] を使用すると、図は元のアルゴリズムに戻ります。
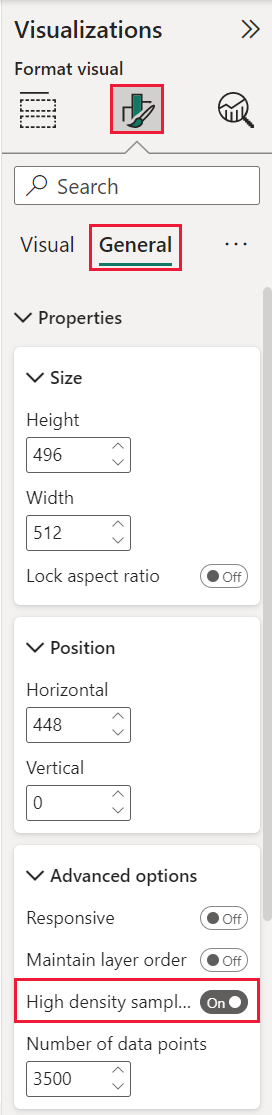
散布図の [高密度サンプリング] を有効にする方法
[高密度サンプリング] を [オン] に切り替えるには、散布図を選択し、[ビジュアルの書式設定] ペインに移動し、[全般] カードを展開して、そのカードの下部にある [高密度サンプリング] トグル スライダーを [オン] にスライドします。
Note
切り替えをオンにすると、Power BI は、使用可能なときには常に高密度サンプリングの使用を試行します。 このアルゴリズムを使用できない場合 (たとえば、[再生] 軸に値を配置した場合)、グラフが標準アルゴリズムに戻っていても、切り替えは [オン] のままです。 その後 [再生] 軸の値を削除した場合 (または、高密度サンプリング アルゴリズムを使用できるように条件が変化した場合)、機能はアクティブなので、グラフでは自動的にそのグラフの高密度サンプリングが使用されます。
注意
データ ポイントはインデックスによってグループ化または選択されます。 凡例を使用しても、アルゴリズムのサンプリングには影響しません。 視覚化の順序にのみ影響します。
考慮事項と制限事項
高密度サンプリング アルゴリズムは、Power BI の重要な改善点です。 ただし、高密度サンプリング アルゴリズムは、Power BI サービスに基づくモデル、インポートしたモデル、または DirectQuery へのライブ接続でのみ動作します。