セマンティック モデルの増分更新とリアルタイム データ
Power BI のセマンティック モデルの増分更新とリアルタイム データを使用すると、動的なデータを効率的に処理し、モデル更新のパフォーマンスを向上することができます。 パーティションの作成と管理を自動化すると、増分更新では、更新する必要があるデータの量が削減され、リアルタイム データを含めることができます。 この記事では、Power BI の増分更新機能を構成し、それを使用して、変化が激しいデータをキャプチャし、パフォーマンスを向上する方法について説明します。
増分更新では、新規および更新されたデータを頻繁に読み込むセマンティック モデル テーブルの自動パーティション作成と管理を行うことによって、スケジュールされた更新操作を拡張します。 ほとんどのモデルでは、リレーショナルまたはスター データベース スキーマ内のファクト テーブルのように、頻繁に変更されて指数関数的に増える可能性のあるトランザクション データが 1 つまたは複数のテーブルに格納されています。 増分更新ポリシーでテーブルをパーティション分割し、最新のインポート パーティションのみを更新し、必要に応じてリアルタイム データ用に別の DirectQuery パーティションを使うと、更新が必要なデータ量を大幅に減らすことができます。 同時に、このポリシーを使って、データ ソースでの最新の変更をクエリ結果に確実に含めることができます。
増分更新とリアルタイム データを使用すると、次のようになります。
- 変化が激しいデータの更新サイクルを減らす必要があります。 DirectQuery モードでは、クエリのプロセス中に最新のデータ更新を取得するので、更新頻度を短くする必要はありません。
- 更新が速くなります。 更新する必要があるのは変更された最新のデータのみです。
- 更新の信頼性が高くなります。 揮発性のデータ ソースに対して長時間の接続は必要ありません。 ソース データに対するクエリはより高速に実行され、ネットワークの問題が妨げになる可能性を減らします。
- リソースの消費量が減ります。 更新するデータが少ないと、Power BI とデータ ソース システムの両方のメモリや他のリソースの全体的な使用が減ります。
- 大規模なセマンティック モデルが有効になっています。 何十億行にもなる可能性のあるセマンティック モデルは、更新操作ごとにデータセット全体を完全に更新しなくても拡張できます。
- 設定は簡単です。 増分更新の "ポリシー" は、ほんの数タスクで Power BI Desktop で定義されます。 Power BI Desktop がレポートを発行すると、サービスは、更新のたびにそれらのポリシーを自動的に適用します。
サービスに Power BI Desktop モデルを発行するときは、新しいモデル内の各テーブルに 1 つのパーティションがあります。 この 1 つのパーティションには、そのテーブルのすべての行が格納されます。 テーブルが大きい場合、たとえば数千万行以上の場合、そのテーブルの更新には長い時間がかかり、過剰な量のリソースが消費される可能性があります。
増分更新を使用すると、サービスにより動的にパーティション分割され、頻繁に更新する必要があるデータが、それほど頻繁に更新できないデータから分離されます。 テーブル データは、大文字と小文字が区別される予約済みの名前 RangeStart と RangeEnd で、Power Query の日付/時刻パラメーターを使用してフィルター処理されます。 Power BI Desktop で増分更新を構成すると、モデルに読み込まれる短期間のデータのみをフィルター処理するためにこれらのパラメーターが使われます。 Power BI Desktop がレポートを Power BI サービスに発行すると、最初の更新操作で、サービスは、増分更新ポリシー設定に基づいて増分更新と履歴のパーティション、状況に応じてリアルタイムの DirectQuery パーティションを作成します。 次に、サービスはこれらのパラメーター値をオーバーライドして、各行の日時値に基づいて各パーティションのデータをフィルター処理してクエリを実行します。
その後の各更新では、クエリのフィルター処理により、パラメーターによって動的に定義された更新期間内の該当する行だけが返されます。 更新期間内の日付/時刻を含むそれらの行が更新されます。 日時が更新期間内ではなくなった行は、履歴期間の一部になりますが、更新されません。 増分更新ポリシーにリアルタイム DirectQuery パーティションが含まれている場合は、そのフィルターも更新され、更新期間後に発生した変更も取得されるようになります。 更新と履歴の両方の期間がロールフォワードされます。 新しい増分更新パーティションが作成されると、更新期間内にはなくなった更新パーティションは履歴パーティションになります。 時間が経つと、履歴パーティションはマージされるので、詳細度は低くなります。 履歴パーティションがポリシーで定義されている履歴期間内にはなくなると、モデルから完全に削除されます。 この動作は、"ローリング ウィンドウ パターン" と呼ばれます。
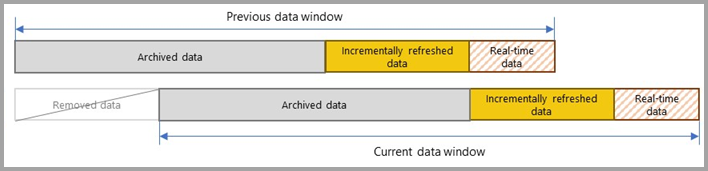
増分更新の利点は、サービスによってこのすべてが、定義した増分更新ポリシーに基づいて処理されることです。 実際、そこから作成されたプロセスとパーティションは、サービスには表示されません。 ほとんどの場合、モデルの更新のパフォーマンスを大幅に向上させるために必要なのは、適切に定義された増分更新ポリシーだけです。 ただし、リアルタイムの DirectQuery パーティションは Premium 容量のデータに対してのみサポートされています。 また、Power BI Premium では、XML for Analysis (XMLA) エンドポイントを使って、より高度なパーティション分割と更新のシナリオに対応できます。
要件
以下のセクションでは、サポートされるプランとデータ ソースについて説明します。
サポートされているプラン
増分更新は、Power BI Premium、ユーザーごとの Premium、Power BI Pro、Power BI Embedded モデルに対してサポートされています。
DirectQuery を使用してリアルタイムで最新のデータを取得する方法は、Power BI Premium、Premium Per User、Power BI Embedded のモデルに対してのみサポートされています。
サポートされるデータ ソース
増分更新およびリルタイム データは、SQL Database や Azure Synapse などの構造化されたリレーショナル データ ソースに最適ですが、他のデータ ソースにも使用できます。 どのような場合でも、データ ソースは次をサポートしている必要があります。
日付のフィルター処理 - データ ソースは、日付でデータをフィルター処理するためのメカニズムをサポートしている必要があります。 リレーショナル ソースの場合、これは通常、ターゲット テーブルの日付/時刻データ型または整数データ型の日付列です。 RangeStart および RangeEnd パラメーター (日付/時刻データ型である必要があります) は、日付列に基づいてテーブル データをフィルター処理します。 yyyymmdd の形式の整数代理キーの日付列の場合は、RangeStart および RangeEnd パラメーターの日付/時刻値を変換する関数を作成して、日付列の整数代理キーに一致させることができます。 詳細については、「増分更新とリアルタイム データを構成する」の「DateTime を整数型に変換する」を参照してください。
その他のデータ ソースの場合、RangeStart パラメーターと RangeEnd パラメーターは、フィルター処理を有効にする何らかの方法でデータ ソースに渡す必要があります。 ファイルとフォルダーが日付別に整理されているファイルベースのデータ ソースの場合、RangeStart パラメーターと RangeEnd パラメーターを使ってファイルとフォルダーをフィルター処理し、読み込むファイルを選択できます。 Web ベースのデータ ソースの場合、RangeStart および RangeEnd パラメーターを HTTP 要求に統合できます。 たとえば、AppInsights インスタンスからのトレースの増分更新には、次のクエリを使用できます。
let
strRangeStart = DateTime.ToText(RangeStart,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
strRangeEnd = DateTime.ToText(RangeEnd,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
Source = Json.Document(Web.Contents("https://api.applicationinsights.io/v1/apps/<app-guid>/query",
[Query=[#"query"="traces
| where timestamp >= datetime(" & strRangeStart &")
| where timestamp < datetime("& strRangeEnd &")
",#"x-ms-app"="AAPBI",#"prefer"="ai.response-thinning=true"],Timeout=#duration(0,0,4,0)])),
TypeMap = #table(
{ "AnalyticsTypes", "Type" },
{
{ "string", Text.Type },
{ "int", Int32.Type },
{ "long", Int64.Type },
{ "real", Double.Type },
{ "timespan", Duration.Type },
{ "datetime", DateTimeZone.Type },
{ "bool", Logical.Type },
{ "guid", Text.Type },
{ "dynamic", Text.Type }
}),
DataTable = Source[tables]{0},
Columns = Table.FromRecords(DataTable[columns]),
ColumnsWithType = Table.Join(Columns, {"type"}, TypeMap , {"AnalyticsTypes"}),
Rows = Table.FromRows(DataTable[rows], Columns[name]),
Table = Table.TransformColumnTypes(Rows, Table.ToList(ColumnsWithType, (c) => { c{0}, c{3}}))
in
Table
増分更新が構成されている場合は、データ ソースに対して RangeStart および RangeEnd パラメーターに基づく日付/時刻フィルターを含む Power Query 式が実行されます。 最初のソース クエリの後のクエリ ステップでフィルターを指定する場合は、クエリ フォールディングで、最初のクエリ ステップと、RangeStart および RangeEnd パラメーターを参照するステップを組み合わせることが重要です。 たとえば、次のクエリ式では、Table.SelectRows は Sql.Database ステップの直後に続き、SQL Server でフォールディングがサポートされるため、フォールディングされます。
let
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(Data, each [OrderDateKey] >= Int32.From(DateTime.ToText(RangeStart,[Format="yyyyMMdd"]))),
#"Filtered Rows1" = Table.SelectRows(#"Filtered Rows", each [OrderDateKey] < Int32.From(DateTime.ToText(RangeEnd,[Format="yyyyMMdd"])))
in
#"Filtered Rows1"
"最終的なクエリ" でフォールディングをサポートする必要はありません。 たとえば、次の式では、フォールディング処理されない NativeQuery を使用しますが、RangeStart および RangeEnd パラメーターを SQL に直接統合します。
let
Query = "select * from dbo.FactInternetSales where OrderDateKey >= '"& Text.From(Int32.From( DateTime.ToText(RangeStart,"yyyyMMdd") )) &"' and OrderDateKey < '"& Text.From(Int32.From( DateTime.ToText(RangeEnd,"yyyyMMdd") )) &"' ",
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Value.NativeQuery(Source, Query, null, [EnableFolding=false])
in
Data
ただし、DirectQuery を使用したリアルタイム データの取得方法が増分更新ポリシーに含まれている場合、非フォールディング変換は使用できません。 リアルタイム データが含まれない純粋なインポート モード ポリシーの場合は、クエリのマッシュアップ エンジンによってフィルターがローカルで補正および適用されることがあります。その場合は、データソースからテーブルのすべての行を取得する必要があります。 これにより、増分更新の速度が遅くなり、プロセスで Power BI サービスまたはオンプレミス データ ゲートウェイのリソースが不足する可能性があり、事実上、増分更新の目的が無効になります。
クエリ フォールディングのサポートはデータ ソースの種類によって異なるため、検証を実行して、データ ソースに対して実行されるクエリにフィルターのロジックが含まれていることを確認する必要があります。 ほとんどの場合、Power BI Desktop では、増分更新ポリシーを定義するときにこの検証を実行しようとします。 SQL Database、Azure Synapse、Oracle、Teradata などの SQL ベースのデータ ソースの場合、この検証は信頼できます。 ただし、他のデータ ソースでは、クエリをトレースしないと検証できない場合があります。 Power BI Desktop でクエリを確認できない場合は、[増分更新ポリシーの構成] ダイアログに警告が表示されます。
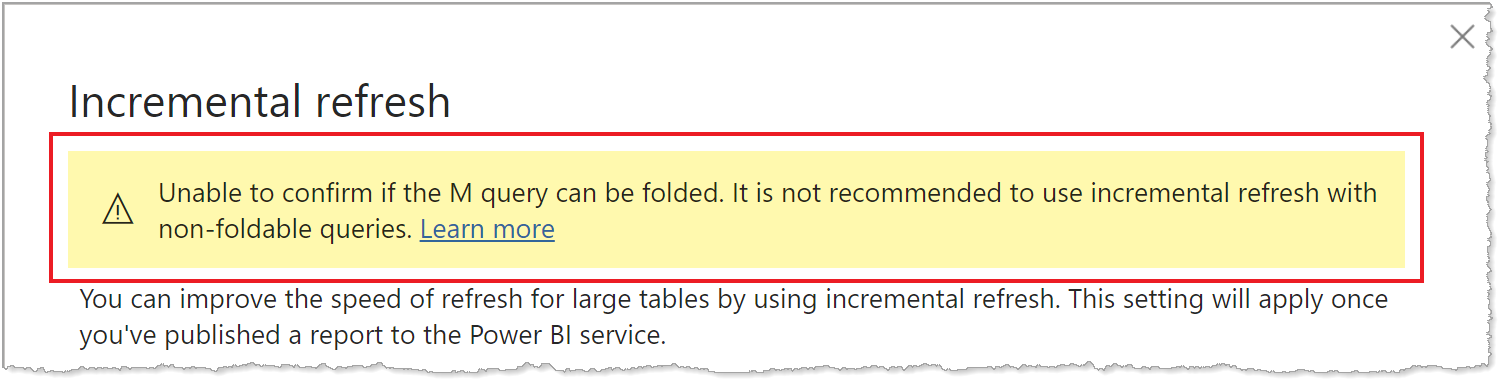
この警告が表示され、必要なクエリ フォールディングが行われていることを確認したい場合は、Power Query 診断機能を使うか、SQL Profiler などのデータ ソースでサポートされているツールを使ってクエリをトレースします。 クエリ フォールディングが行われていない場合は、データ ソースに渡されているクエリにフィルターのロジックが含まれていることを確認します。 そうでない場合、クエリには、フォールディングを妨げる変換が含まれている可能性があります。
増分更新ソリューションを構成する前に、「Power BI Desktop でのクエリ フォールディングのガイダンス」と Power Query のクエリ フォールディングに関するページを十分に読んで理解しておいてください。 これらの記事は、データ ソースとクエリでクエリ フォールディングがサポートされているかどうかを判断するのに役立ちます。
単一のデータ ソース
Power BI Desktop を使って増分更新とリアルタイム データを構成する場合や、表形式モデルのスクリプト言語 (TMSL) または表形式オブジェクト モデル (TOM) を使って XMLA エンドポイント経由の高度なソリューションを構成する場合は、インポートと DirectQuery のいずれを問わず、"すべてのパーティション" で 1 つのソースからデータのクエリを実行する必要があります。
その他のデータ ソースの種類
さらにカスタム クエリ関数とクエリ ロジックを使うことで、フォルダーに格納された Excel ブック ファイル、SharePoint のファイル、RSS フィードといったデータ ソースのように RangeStart と RangeEnd に基づくフィルターを 1 つのクエリで渡す場合に、増分更新を他の種類のデータ ソースに対して使うことができます。 これらは高度なシナリオであり、ここで説明する以上のさらなるカスタマイズとテストが必要であることに注意してください。 固有のシナリオで増分更新を使う方法の推奨事項については、この記事の後半にある「コミュニティ」のセクションを確認してください。
時間制限
増分更新に関係なく、Power BI Pro モデルには 2 時間という更新時間の制限があり、DirectQuery を使ったリアルタイム データの取得方法はサポートされていません。 Premium 容量のモデルの場合、時間制限は "5 時間" です。 更新操作は、処理負荷が高く、メモリを集中的に使用します。 完全な更新操作では、更新操作が完了するまではサービスでモデルのスナップショットがメモリに保持されるため、モデルだけに必要なメモリ量の 2 倍もの量が使用される可能性があります。 また、更新操作は処理負荷が高いため、使用可能な CPU リソースを大量に消費する可能性もあります。 更新操作は、データ ソースへの揮発性の接続と、それらのデータ ソース システムでクエリ出力をすばやく返す機能にも依存する必要があります。 時間制限は、使用可能なリソースの過剰消費を制限するための保護手段です。
注意
Premium 容量では、XMLA エンドポイントを介して実行される更新操作には時間制限がありません。 詳細については、XMLA エンドポイントを使用した高度な増分更新に関するページを参照してください。
増分更新では更新操作がモデル内のパーティション レベルで最適化されるため、リソースの消費を大幅に削減できます。 同時に、増分更新を使う場合でも、XMLA エンドポイントを使わない限り、更新操作は同じ 2 時間と 5 時間の制限に制約されます。 効果的な増分更新ポリシーは、更新操作で処理されるデータの量を減らすだけでなく、モデルに格納される不要な履歴データの量も減らします。
クエリは、データ ソースの既定の時間制限によって制限することもできます。 ほとんどのリレーショナル データ ソースでは、Power Query M 式の時間制限をオーバーライドできます。 たとえば、次の式では、SQL Server のデータ アクセス関数を使用して、CommandTimeout を 2 時間に設定しています。 ポリシーの範囲によって定義されている各期間で、コマンド タイムアウトの設定を監視するクエリが送信されます。
let
Source = Sql.Database("myserver.database.windows.net", "AdventureWorks", [CommandTimeout=#duration(0, 2, 0, 0)]),
dbo_Fact = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(dbo_Fact, each [OrderDate] >= RangeStart and [OrderDate] < RangeEnd)
in
#"Filtered Rows"
何十億もの行が含まれる可能性が高い Premium 容量の "大規模な" モデルの場合は、最初の更新操作をブートストラップすることができます。 ブートストラップを使うと、サービスでモデルのテーブルおよびパーティション オブジェクトを作成できますが、データをパーティションに読み込んで処理することはできません。 SQL Server Management Studio を使うと、パーティションを個別に、順番に、または並行して処理できるため、1 つのクエリで返されるデータの量を減らすことができるだけでなく、5 時間の時間制限を回避することもできます。 詳細については、高度な増分更新に関するページの「最初の完全な更新でタイムアウトを回避する」を参照してください。
現在の日付と時刻
既定では、現在の日付と時刻は、更新時の世界協定時刻 (UTC) に基づいて決定されます。 オンデマンド、スケジュール済み、REST API の更新では、現在の日付と時刻を決定するときに考慮される別のタイム ゾーンを [更新] で構成できます。 たとえば、タイム ゾーンが構成された、太平洋標準時の午後 8:00 (米国およびカナダ) に発生する更新では、(翌日になる) UTC ではなく、太平洋標準時に基づいて現在の日付と時刻が決定されます。
![[タイム ゾーン] の入力フィールドを示す [スケジュールされている更新] ダイアログのスクリーンショット。](media/incremental-refresh-overview/time-zone.png)
XMLA TMSL 更新コマンドなど、Power BI サービスを介して呼び出されない更新操作では、タイム ゾーンの構成と既定の UTC は考慮されません。
増分更新とリアルタイム データを構成する
このセクションでは、増分更新とリアルタイム データを構成することに関する重要な概念について説明します。 詳細なステップバイステップの手順については、「増分更新とリアルタイム データを構成する」を参照してください。
増分更新の構成は Power BI Desktop で行います。 ほとんどのモデルでは、いくつかのタスクだけが必要です。 ただし、次の点に配慮してください。
- Power BI サービスに発行した後に、Power BI Desktop から同じモデルを再度発行することはできません。 再度発行すると、既にモデル内にある既存のパーティションとデータが削除されます。 Premium 容量に発行する場合、その後のメタデータ スキーマの変更は、オープンソースの ALM Toolkit または TMSL などのツールを使用して行うことができます。 詳細については、高度な増分更新に関するページの「メタデータのみの配置」を参照してください。
- Power BI サービスに発行した後に、モデルを .pbix として Power BI Desktop にダウンロードすることはできません。 サービス内のモデルは非常に大きくなる可能性があるため、一般的なデスクトップ コンピューターでダウンロードして開くことは現実的ではありません。
- DirectQuery を使用してリアルタイム データを取得する場合、モデルを Premium 以外のワークスペースに発行することはできません。 リアルタイム データを使用した増分更新は、Power BI Premium でのみサポートされます。
パラメーターを作成する
Power BI Desktop で増分更新を構成するには、まず、大文字と小文字を区別する予約済みの名前 RangeStart と RangeEnd を使用して、2 つの Power Query 日時パラメーターを作成します。 Power Query エディターの [パラメーターの管理] ダイアログで定義されたこれらのパラメーターを使用して、最初に、その期間内の日時を含む行のみを含めるために、Power BI Desktop モデル テーブルに読み込まれたデータをフィルター処理します。 RangeStart は最も古い日付/時刻または最も古い日付/時刻を表し、RangeEnd は最新または最新の日付/時刻を表します。 モデルがサービスに発行されると、RangeStart と RangeEnd は、増分更新ポリシー設定で指定された更新期間によって定義されたデータをクエリするために、サービスによって自動的にオーバーライドされます。
たとえば、FactInternetSales データ ソース テーブルの 1 日あたり新しい行は、平均 10,000 行です。 Power BI Desktop のモデルに最初に読み込まれる行数を制限するために、RangeStart と RangeEnd の間に 2 日間の期間を指定します。
![[パラメーターの管理] ダイアログのスクリーンショット。RangeStart と RangeEnd のパラメーターが表示されています。](media/incremental-refresh-overview/manage-parameters.png)
データのフィルター処理
RangeStart と RangeEnd のパラメーターを定義するのは、テーブルの日付列にカスタムの日付フィルターを適用する場合です。 フィルターを適用すると、[適用] を選んだときにモデルに読み込まれるデータのサブセットが選ばれます。
![列のコンテキスト メニューのスクリーンショット。[カスタム フィルター] が選ばれています。](media/incremental-refresh-overview/custom-filter.png)
FactInternetSales の例を使うと、パラメーターに基づいてフィルターを作成し、ステップを適用した後、2 日間のデータ (約 20,000 行) がモデルに読み込まれます。
ポリシーの定義
フィルターが適用され、データのサブセットがモデルに読み込まれたら、テーブルの増分更新ポリシーを定義します。 モデルがサービスに発行された後、ポリシーは、テーブル パーティションを作成および管理し、更新操作を実行するために、サービスによって使用されます。 ポリシーを定義するには、[増分更新とリアルタイム データ] ダイアログ ボックスを使用して、必要な設定と省略可能な設定の両方を指定します。
![[増分更新とリアルタイム データ] ダイアログのスクリーンショット。オンになった [Incrementally refresh this table] (このテーブルを増分更新する) オプションが表示されています。](media/incremental-refresh-overview/incremental-refresh-dialog.png)
テーブル
テーブルの選択 リスト ボックスは、テーブル ビューで選択したテーブルに既定で設定されます。 スライダーを使用してテーブルの増分更新を有効にします。 テーブルの Power Query 式に RangeStart と RangeEnd のパラメーターに基づくフィルターが含まれていない場合、トグルは使用できません。
必須の設定
[アーカイブ データの開始: 更新日前] の設定により、履歴期間 (その期間内の日付/時刻を含む行がモデルに含まれる)、現在の不完全な履歴期間の行、および現在の日付と時刻までの更新期間の行が決まります。
たとえば、5 "年" を指定した場合、テーブルには過去 5 年分の履歴データが年パーティションに格納されます。 このテーブルには、更新期間中の現在の年の行も、四半期、月、または日単位のパーティションで格納されます。
Premium 容量のモデルの場合、過去の履歴パーティションは、この設定で決定された詳細度で選択的に更新できます。 詳細については、高度な増分更新に関するページの「パーティション」を参照してください。
[増分更新データを開始する: 更新日前] の設定により、増分更新期間 (その期間内の日時を含むすべての行が更新パーティションに含められ、更新操作ごとに更新される) が決まります。
たとえば、3 日間の更新期間を指定した場合、更新操作ごとにサービスによって RangeStart と RangeEnd のパラメーターがオーバーライドされて、現在の日付と時刻に応じて開始および終了する、3 日以内の日時を含む行に対するクエリが作成されます。 現在の更新操作時刻までの過去 3 日間の日時を含む行が更新されます。 この種類のポリシーでは、サービス内の FactInternetSales モデル テーブルの新しい行が 1 日あたり平均 10,000 行で、更新操作ごとに約 30,000 行が更新されると予測できます。
正確なレポートを得るために必要な最小限の行数のみが含まれる期間を指定してください。 複数のテーブル用のポリシーを定義する場合は、テーブルごとに異なる保存および更新期間が定義されている場合でも、同じ RangeStart と RangeEnd のパラメーターを使う必要があります。
オプション設定
[DirectQuery で最新データをリアルタイムで取得します (Premium のみ)] の設定を使用すると、DirectQuery を使用し、増分更新期間を超えて、データ ソースの選択したテーブルから最新の変更をフェッチできます。 増分更新期間より後の日付/時刻を持つすべての行は DirectQuery パーティションに含められ、すべてのモデル クエリを使用してデータ ソースからフェッチされます。
たとえば、この設定を有効にした場合、サービスでは更新操作ごとに RangeStart と RangeEnd のパラメーターをオーバーライドしたまま、更新日より後の日時を含む行に対するクエリが作成され、現在の日付と時刻に応じて開始されます。 現在の更新操作より後の日時の行も含まれます。 この種のポリシーでは、サービスの FactInternetSales モデル テーブルには、最新のデータ更新が格納されます。
[完了日のみを更新] 設定を有効にすると、1 日のすべての行が更新操作に含められます。 この設定は、[DirectQuery で最新データをリアルタイムで取得します (Premium のみ)] の設定を有効に "しない限り"、省略可能です。 たとえば、毎朝午前 4:00 に更新を実行するようスケジュールされているとします。 午前 0 時から午前 4:00 までの 4 時間の間に、データ ソース テーブルに新しいデータ行が出現した場合、それらを考慮に含めるのは好ましくありません。 石油ガス業界での 1 日あたりのバレル数など、一部のビジネス メトリックは、部分的な日数では意味がありません。 別の例としては、前月のデータが 12 日に承認されるような財務システムからのデータ更新があります。 更新期間を 1 か月に設定し、12 日に実行するように更新をスケジュールします。 このオプションを選択すると、たとえば 1 月のデータは 2 月 12 日に更新されます。
'Refresh' の下のタイム ゾーンが UTC 以外に構成されていない限り、サービスの更新操作は UTC 時間で実行され、有効な日付と完了期間を決定できます。
[データ変更の検出] 設定を使用すると、さらに選択的な更新が実行できます。 識別に使用する日付/時刻列を選択して、データが変更された日だけを更新することができます。 この設定は、そのような列がデータ ソースに存在することを前提としています。一般的にこれは監査目的です。 この列は、 と RangeStart のパラメーターを指定したデータのパーティション分割に使う列と同じにすることはできません。RangeEnd この列の最大値が、増分範囲の各期間に対して評価されます。 前回の更新以降に変更されていない場合、期間を更新する必要はありません。そのため、増分更新される日数が 3 日から 1 日にさらに短くなる可能性があります。
現在の設計では、データの変更を検出する列は永続化されてメモリにキャッシュされる必要があります。 カーディナリティとメモリの消費量を減らすには、次の手法を使用できます。
- おそらく Power Query 関数を使用して、更新時にこの列の最大値のみを保持します。
- 更新頻度の要件で許容されるレベルに有効桁数を減らします。
- XMLA エンドポイントを使用してデータの変更を検出するためのカスタム クエリを定義し、列の値の全体的な永続化を回避します。
場合によっては、[データ変更の検出] オプションを有効にすると、さらに強化できます。 たとえば、メモリ内キャッシュでの最終更新列の永続化を回避したり、更新が必要なパーティションのみにフラグを付けるために抽出、変換、読み込み (ETL) プロセスによって構成または命令テーブルが準備されるというシナリオを有効にしたりできます。 このようなケースで Premium 容量の場合は、TMSL や TOM を使って、データ変更の検出動作をオーバーライドします。 詳細については、高度な増分更新に関するページの「データ変更の検出のためのカスタム クエリ」を参照してください。
公開
増分更新ポリシーを構成した後、モデルをサービスに発行します。 発行が完了したら、"モデル" に対して最初の更新操作を実行できます。
注意
DirectQuery で最新のデータをリアルタイムで取得する増分更新ポリシーが適用されるセマンティック モデルは、Premium ワークスペースにのみ公開できます。
Premium 容量に割り当てられているワークスペースに発行されたモデルの場合、モデルが 1 GB を超えると考えられる場合は、サービスでの最初の更新操作を実行する実行する "前" に [大規模なセマンティック モデルのストレージ形式] 設定を有効にして、更新操作のパフォーマンスを向上し、モデルがサイズ制限を超えないようにすることができます。 詳細については、「Power BI Premium の大規模なモデル (プレビュー)」を参照してください。
重要
Power BI Desktop がモデルをサービスに発行した後に、その .pbix をダウンロードすることはできません。
更新
サービスに発行した後、モデルに対して最初の更新操作を実行します。 進行状況を監視できるように、この更新は個別 (手動) の更新にする必要があります。 最初の更新操作の完了には、かなりの時間がかかることがあります。 パーティションを作成し、履歴データを読み込んで、リレーションシップや階層などのオブジェクトを構築または再構築し、計算済みのオブジェクトを再計算する必要があります。
増分更新パーティションだけが更新されるため、その後の更新操作では、個別またはスケジュール済みのどちらでもはるかに高速になります。 パーティションのマージや再計算などの他の処理操作も引き続き実行する必要がありますが、通常、最初の更新よりもはるかに短い時間で済みます。
レポートの自動更新
DirectQuery で最新のデータをリアルタイムで取得する増分更新ポリシーが適用されたモデルを使うレポートの場合、一定の間隔で、または変更検出に基づいてページの自動更新を有効にし、レポートに最新のデータが遅延なく取り込まれるようにすることをお勧めします。 詳細については、「Power BI でのページの自動更新」を参照してください。
高度な増分更新
モデルが、XMLA エンドポイントが有効になっている Premium 容量にある場合は、高度なシナリオ用に増分更新をさらに拡張できます。 たとえば、SQL Server Management Studio を使用して、パーティションを表示および管理したり、最初の更新操作をブートストラップしたり、過去の履歴パーティションを更新したりできます。 詳細については、XMLA エンドポイントを使用した高度な増分更新に関するページを参照してください。
コミュニティ
Power BI には、MVP、BI プロフェッショナル、および同僚がディスカッション グループ、ビデオ、ブログなどの専門知識を共有する、活気のあるコミュニティがあります。 増分更新について学習する場合は、次のリソースを参照してください。
- Power BI コミュニティ
- Bing で "Power BI 増分更新" を検索する
- Bing で "ファイルの増分更新" を検索する
- Bing で "増分更新を使用して既存のデータを保持する" を検索する