Power BI Desktop のデータ型
この記事では、Power BI Desktop とデータ分析式 (DAX) でサポートされるデータ型について説明します。
Power BI は、データを読み込むときに、ソース列のデータ型を、より効率的なストレージ、計算、およびデータ視覚化をサポートするデータ型に変換しようとします。 たとえば、Excel からインポートする値の列に小数部の値がない場合、Power BI Desktop はデータ列を整数型
一部の DAX 関数には特別なデータ型の要件があるため、この概念は重要です。 多くの場合、DAX ではデータ型暗黙的に変換されますが、変換されない場合もあります。 たとえば、DAX 関数で
列のデータ型を決定して指定する
Power BI Desktop では、Power Query エディター、テーブル ビュー、またはレポート ビューで、列のデータ型を決定して指定できます。
Power Query エディターで列を選択し、リボンの [変換] グループの [データ型] を選択します。
![Power Query エディターのスクリーンショット。[データ型] ドロップダウンが選択されています。](media/desktop-data-types/pbiddatatypesinqueryeditort.png)
データ ビューまたはレポート ビューでは、列を選んでから、リボンの [列ツール] タブで [データ型] の横にあるドロップダウン矢印を選びます。
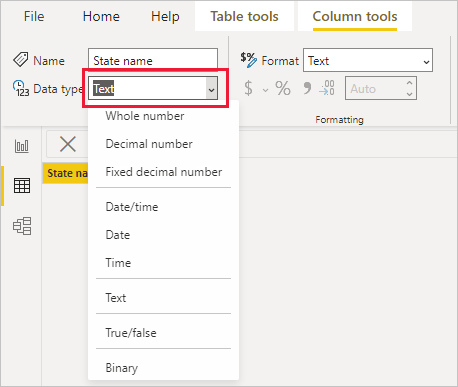
Power Query エディターの [データ型] ドロップダウン選択には、テーブル ビューまたはレポート ビューに存在しない 2 つのデータ型があります。日付/時刻/タイムゾーン
バイナリ データ型は、Power Query エディターの外部ではサポートされていません。 Power Query エディターでは、バイナリ ファイルを Power BI モデルに読み込む前に他のデータ型に変換する場合、バイナリ ファイルを読み込むときに バイナリ データ型を使用できます。
数値の種類
Power BI Desktop では、10 進数の、固定の 10 進数、整数の 3 つの数値の種類がサポートされています。
表形式オブジェクト モデル (TOM) の列の DataType プロパティを使って、数値型の DataType 列挙型を指定できます。 Power BI のオブジェクトをプログラムで変更する方法の詳細については、「表形式オブジェクト モデルを使用して Power BI セマンティック モデルをプログラム
10 進数
10 進数 は最も一般的な数値型であり、小数部の値と整数を持つ数値を処理できます。 10 進数 は、-1.79E +308 から -2.23E -2.23E までの負の値を持つ 64 ビット (8 バイト) の浮動小数点数を表します。、 2.23E -308 から 1.79E +308までの正の値、および 0。 34、34.01、34.000367063 などの数値は有効な 10 進数です。
10 進数 型で表すことができる最も高い精度は 15 桁です。 小数点区切り記号は、数値の任意の場所で使用できます。 この型は、Excel が数値を格納する方法に対応し、TOM はこの型を DataType.Double Enum として指定します。
固定小数点
固定小数点 データ型には、小数点区切り記号の固定位置があります。 小数点区切り記号は常に右に 4 桁の数字を持ち、19 桁の有効桁数を使用できます。
固定の 10 進数 型は、丸めによってエラーが発生する可能性がある場合に役立ちます。 小数部の値が小さい数値が蓄積され、数値が少し不正確になる場合があります。 固定小数点 型は、小数点区切り記号の右側の 4 桁を超える値を切り捨てることで、このようなエラーを回避するのに役立ちます。
このデータ型は、SQL Server の Decimal (19,4)、または Analysis Services と Power Pivot in Excel の Currency データ型に対応します。 TOM は、この型 DataType.Decimal 列挙型として指定します。
整数
整数 は、64 ビット (8 バイト) の整数値を表します。 整数であるため、整数 小数点以下の桁数はありません。 この型では、-9,223,372,036,854,775,807 (-2^63+1の正または負の整数の 19 桁を使用できます。 ) と 9,223,372,036,854,775,806 (2^63-2) であるため、数値データ型の可能な最大数を表すことができます。
固定小数点 型と同様に、整数 型は、丸めを制御する必要がある場合に役立ちます。 TOM は、データ型 整数 を DataType.Int64 Enum として表します。
手記
Power BI Desktop データ モデルでは 64 ビット整数値がサポートされていますが、JavaScript の制限により、Power BI ビジュアルで安全に表現できる最大数は、9,007,199,254,740,991 (2^53-1) です。 データ モデルの数値が大きい場合は、ビジュアルに追加する前に、計算によってサイズを小さくできます。
数値型の計算の精度
10 進数 データ型の列値は、浮動小数点数の IEEE 754 標準に従って、おおよその データ型で格納されます。 近似データ型には固有の精度制限があります。正確な数値を格納する代わりに、近似値が非常に近い(丸められた) 可能性があるためです。
浮動小数点値が浮動小数点の桁数を確実に定量化できない場合、精度の損失 (不正確な) が発生する可能性があります。 一部のレポート シナリオでは、不正確な計算結果が予期しない、または不正確に見える可能性があります。
10 進数 データ型の値間で等値関連の比較計算を行うと、予期しない結果が返される可能性があります。 等値比較には、等しい =、>より大きい、<未満、>=以上、および <=以下が含まれます。
この問題は、DAX 式で RANKX 関数 を使用する場合に最も顕著です。これにより、結果が 2 回計算され、結果の数値が若干異なります。 レポート ユーザーは 2 つの数値の違いに気付かない場合がありますが、ランクの結果が著しく不正確になる可能性があります。 予期しない結果を避けるために、列のデータ型を
稀に、データ型が の
必要な計算で、負の数値の大部分を合計する前に正の数値の大部分を合計した場合、最初の大きな正の部分合計が結果を歪める可能性があります。 計算によって正と負の数値のバランスが取れた場合、クエリの精度が維持されるため、より正確な結果が返されます。 予期しない結果を避けるために、列のデータ型を 10 進数の から 固定 10 進数 または 整数に変更できます。
日付/時刻型
Power BI Desktop では、Power Query エディターで 5 つの 日付/時刻 データ型がサポートされます。 日付/時刻/タイムゾーン と 期間 は、読み込み時に Power BI Desktop データモデルに変換されます。 このモデルでは、日付/時刻がサポートされています。または、値を 日付 または 時刻 として個別に書式設定できます。
日付/時刻 は、日付と時刻の両方の値を表します。 基になる 日付/時刻 値は 10 進数 型として格納されるため、2 つの型間で変換できます。 時間部分は、1/300 秒 (3.33 ミリ秒) の倍数全体に対する分数として格納されます。 データ型は、1900 年から 9999 年までの日付をサポートします。
日付 は、時刻部分のない日付のみを表します。 日付 は、小数部の値がゼロの 日付/時刻 値としてモデルに変換されます。
時間 は、日付部分のない時刻のみを表します。 時間 は、小数点の左側に数字を含まない 日付/時刻 値としてモデルに変換されます。
日付/時刻/タイムゾーン は、タイムゾーンオフセットを持つ UTC 日付/時刻を表し、モデルに読み込まれると 日付/時刻 に変換されます。 Power BI モデルでは、ユーザーの場所またはロケールに基づいてタイムゾーンが調整されることはありません。 米国内のモデルに読み込まれた値 09:00 は、レポートを開いたり表示したりすると、09:00 として表示されます。
期間 は時間の長さを表し、モデルに読み込まれると 10 進数 型に変換されます。 10 進数型なので、日付/時刻の値を加算または減算すると正しい結果が得られ、大きさを示す視覚エフェクトで値を簡単に使用できます。
テキストの種類
Text データ型は Unicode 文字データ文字列であり、文字、数字、または日付をテキスト形式で表すことができます。 文字列長の実際の上限は、Power BI の基になる Power Query エンジンに基づく約 32,000 文字の Unicode 文字と、テキスト データ型の長さに対する制限です。 実際の上限を超えるテキスト データ型は、エラーが発生する可能性があります。
Power BI でテキスト データを格納する方法により、特定の状況でデータの表示が異なる場合があります。 次のセクションでは、Power Query エディターでデータ クエリを実行してから Power BI に読み込む間に、テキスト データの外観が若干変化する一般的な状況について説明します。
大文字と小文字の区別
Power BI でデータを格納およびクエリするエンジンは、大文字と小文字 区別されないであり、異なる大文字と小文字を同じ値として扱います。 "A" は "a" と等しくなります。 一方、Power Query では "大文字と小文字の区別があり"、"A" は "a" と同じではありません。 大文字と小文字の区別の違いにより、Power BI への読み込み後にテキスト データの大文字と小文字が一見不可解に変更される場合があります。
次の例は、注文データを示しています。注文ごとに一意の OrderNo 列と、注文時に手動で入力された住所ユーザー名を示す Addressee 列。 Power Query エディターには、システムに入力された同じ Addressee 名を持つ複数の注文が表示され、大文字と小文字が異なります。
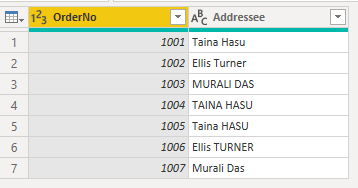 のさまざまな大文字と小文字を使用したテキスト データのスクリーンショット
のさまざまな大文字と小文字を使用したテキスト データのスクリーンショット
Power BI がデータを読み込んだ後、[データ] タブの重複する名前の大文字小文字の表記は、元のエントリから大文字小文字の組み合わせの1つに変更されます。
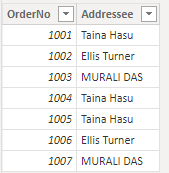
この変更は、Power Query エディターでは大文字と小文字が区別されるため、ソース システムに格納されているデータとまったく同じように表示されるためです。 Power BI にデータを格納するエンジンでは大文字と小文字が区別されないため、文字の小文字と大文字のバージョンは同一として扱われます。 Power BI エンジンに読み込まれた Power Query データは、適宜変更される可能性があります。
Power BI エンジンは、データを読み込むときに、先頭から行を個別に評価します。 Addresseeなどの各テキスト列に対して、エンジンは一意の値のディクショナリを格納して、データ圧縮によるパフォーマンスを向上させます。 エンジンは、Addressee 列の最初の 3 つの値を一意として表示し、ディクショナリに格納します。 その後、エンジンでは大文字と小文字が区別されないため、名前は同一として評価されます。
エンジンは、"Taina Hasu" を "TAINA HASU" や "Taina HASU" と同一視するため、それらのバリエーションは格納されず、最初に格納されたバリエーションを参照します。 "MURALI DAS" という名前は大文字で表示されます。これは、データを上から下に読み込むときにエンジンが最初に評価したときに名前が表示されるからです。
この図は、評価プロセスを示しています。

前の例では、Power BI エンジンはデータの最初の行を読み込み、
4 行目の場合、エンジンは値をディクショナリ内の名前と比較し、名前を検索します。 エンジンは大文字と小文字を区別しないので、"TAINA HASU" と "Taina Hasu" は同じです。 エンジンはディクショナリに新しい名前を追加しませんが、既存の名前を参照します。 残りの行でも同じプロセスが発生します。
手記
Power BI にデータを格納およびクエリするエンジンでは大文字と小文字が区別されないため、大文字と小文字を区別するソースを使用して DirectQuery モードで作業する場合は、特別な注意を払います。 Power BI では、ソースが重複する行を削除したと想定しています。 Power BI では大文字と小文字が区別されないため、大文字と小文字のみが異なる 2 つの値が重複として扱われますが、ソースではそのように扱われません。 このような場合、最終的な結果は未定義です。
このような状況を回避するには、大文字と小文字を区別するデータ ソースで DirectQuery モードを使用する場合は、ソース クエリまたは Power Query エディターで大文字と小文字を正規化します。
先頭と末尾の空白
Power BI エンジンは、テキスト データに続く末尾のスペースを自動的にトリミングしますが、データの前にある先頭のスペースは削除しません。 混乱を避けるために、先頭または末尾のスペースを含むデータを操作するときは、Text.Trim 関数を使用して、テキストの先頭または末尾にあるスペースを削除する必要があります。 先頭のスペースを削除しないと、値が重複しているためにリレーションシップの作成に失敗したり、ビジュアルが予期しない結果を返したりする可能性があります。
次の例は、顧客に関するデータを示しています。顧客の名前を含む 名 列と、エントリごとに一意の Index 列。 わかりやすくするために、名前は引用符で囲まれています。 顧客名は 4 回繰り返されますが、そのたびに先頭と末尾のスペースの組み合わせが異なります。 これらのバリエーションは、時間の経過と共に手動でデータを入力する場合に発生する可能性があります。
| 行 | 先頭のスペース | 末尾のスペース | 名前 | インデックス | テキストの長さ |
|---|---|---|---|---|---|
| 1 | いいえ | いいえ | "ディラン・ウィリアムズ" | 1 | 14 |
| 2 | いいえ | はい | "ディラン・ウィリアムズ" | 10 | 15 |
| 3 | はい | いいえ | "ディラン・ウィリアムズ" | 20 | 15 |
| 4 | はい | はい | "ディラン・ウィリアムズ" | 40 | 16 |
Power Query エディターでは、結果のデータは次のように表示されます。
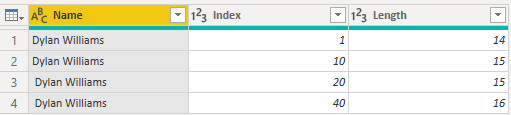
データの読み込み後に Power BI の [テーブル] タブに移動すると、同じテーブルが次の図のようになります。行数は前と同じです。
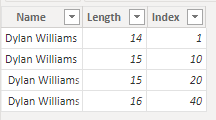
ただし、このデータに基づくビジュアルでは、2 つの行だけが返されます。

上の図では、最初の行の Index フィールドの合計値は 60 であるため、ビジュアルの最初の行は、読み込まれたデータの最後の 2 行を表します。 2 行目としての合計 インデックス 値が 11、最初の 2 行を表します。 ビジュアルテーブルとデータテーブルの行数の違いは、エンジンが末尾のスペースを自動的に削除またはトリミングすることによって発生しますが、先頭のスペースは削除されません。 そのため、エンジンは 1 行目と 2 行目、3 行目と 4 行目が同一と評価され、ビジュアルはこれらの結果を返します。
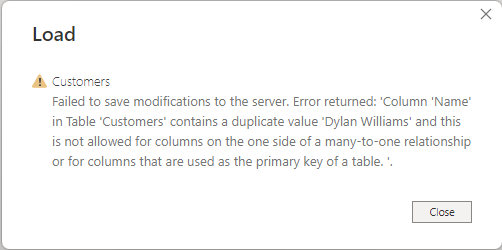
この動作により、重複する値が検出されるため、リレーションシップに関連するエラー メッセージが発生する可能性もあります。 たとえば、リレーションシップの構成によっては、次の図のようなエラーが表示される場合があります。
他の状況では、重複する値が検出されるため、多対一または一対一のリレーションシップを作成できない場合があります。
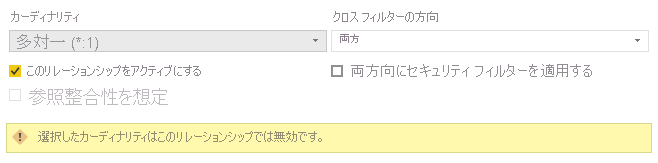
これらのエラーは先頭または末尾の空白まで遡ることができ、解決するには、Text.Trim または [変換] の [形式]>[トリミング] を使って、Power Query エディターで空白を削除します。
True/False 型
True/false データ型は、True または Falseのいずれかのブール値です。 最良かつ最も一貫性のある結果を得るには、ブール値の true/false 情報を含む列を Power BI に読み込むときに、列の種類を True/Falseに設定します。
Power BI では、特定の状況でデータの変換と表示が異なります。 このセクションでは、ブール値を変換する一般的なケースと、Power BI で予期しない結果を生み出す変換に対処する方法について説明します。
この例では、顧客がニュースレターにサインアップしたかどうかに関するデータを読み込みます。 TRUE の値は、顧客がニュースレターにサインアップしたことを示し、値 FALSE は、顧客がサインアップしていないことを示します。
ただし、Power BI サービスにレポートを発行すると、true または
このテーブルの簡略化されたクエリは、次の図に表示されます。
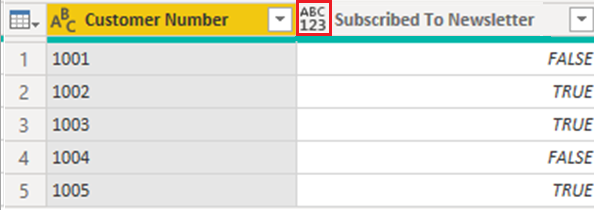
Subscribed To Newsletter 列のデータ型は [任意] に設定されており、その結果、Power BI はデータをテキストとしてモデルに読み込みます。
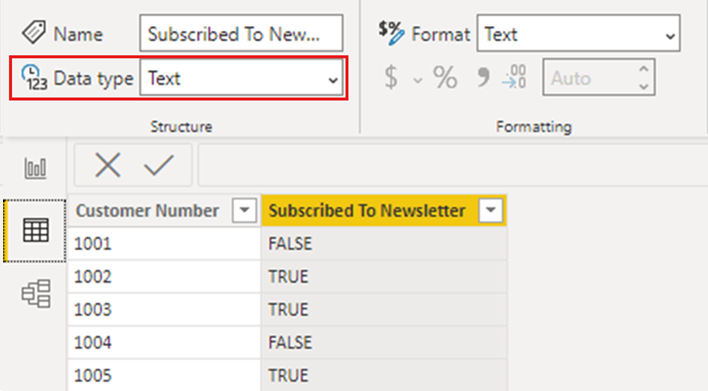
顧客ごとの詳細情報を示す単純な視覚化を追加すると、データは、Power BI Desktop と Power BI サービスに発行された場合の両方で、予想どおりにビジュアルに表示されます。
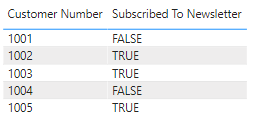
ただし、Power BI サービスでセマンティック モデルを更新すると、ビジュアルの Subscribed to Newsletter 列には、TRUE または FALSEとして表示される代わりに、値が -1 および 0として表示されます。
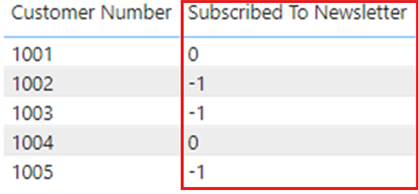
Power BI Desktop からレポートを最新の情報に更新すると、Subscribed To Newsletter 列には再度 TRUE または FALSE が予想どおりに表示されますが、Power BI サービスで最新の情報に更新すると、値は再度変更されて -1 と 0 が表示されます。
このような状況を回避する解決策は、Power BI Desktop でブール型の列 True または False を入力し、レポートを再発行することです。
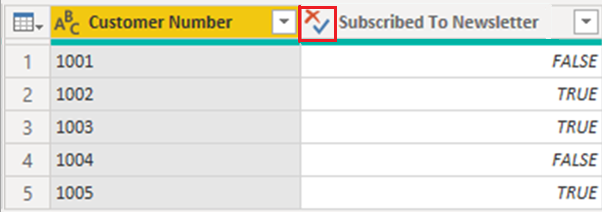
変更すると、視覚エフェクトでの Subscribed To Newsletter 列の値の表示が少し変わります。 表に入力されているすべての大文字のテキストではなく、最初の文字のみが大文字になります。 この変更は、列のデータ型を変更した結果の 1 つです。
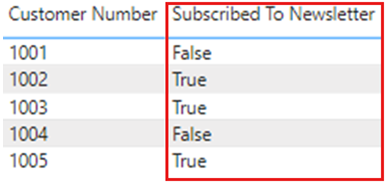
データ型を変更し、Power BI サービスに再発行し、更新が行われると、レポートには、期待どおりに値が True または Falseとして表示されます。
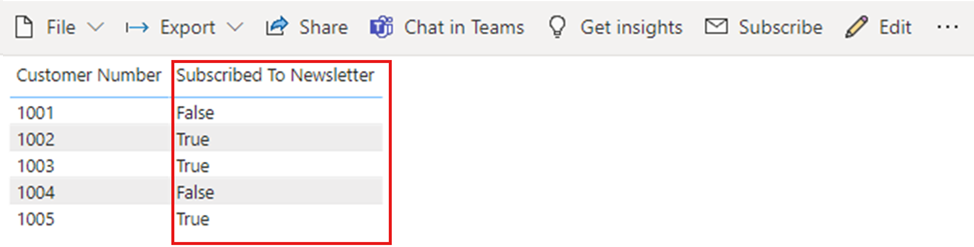
要約すると、Power BI でブール値データを操作する場合は、Power BI Desktop で列が True/False データ型に設定されていることを確認します。
空白型
空白 は、SQL null を表し、置き換える DAX データ型です。 BLANK 関数を使用して空白を作成し、ISBLANK 論理関数を使用して空白をテストできます。
バイナリ型
Binary データ型を使用して、任意のデータをバイナリ形式で表すことができます。 Power Query エディターでは、バイナリ ファイルを Power BI モデルに読み込む前に他のデータ型に変換する場合に、バイナリ ファイルを読み込むときにこのデータ型を使用できます。
Power BI データ モデルでは、バイナリ列はサポートされていません。 バイナリ の選択は、従来の理由からテーブル ビューとレポート ビューのメニューに存在しますが、バイナリ列を Power BI モデルに読み込もうとすると、エラーが発生する可能性があります。
手記
バイナリ列がクエリの手順の出力にある場合、ゲートウェイを介してデータを更新しようとするとエラーが発生する可能性があります。 クエリの最後の手順として、バイナリ列を明示的に削除することをお勧めします。
テーブルの種類
DAX では、集計やタイム インテリジェンス計算など、多くの関数で Table データ型が使用されます。 一部の関数では、テーブルへの参照が必要です。 他の関数は、他の関数への入力として使用できるテーブルを返します。
入力としてテーブルを必要とする一部の関数では、テーブルに評価される式を指定できます。 一部の関数では、ベース テーブルへの参照が必要です。 特定の関数の要件については、DAX 関数リファレンスを参照してください。
暗黙的および明示的なデータ型変換
各 DAX 関数には、入力と出力として使用するデータの種類に固有の要件があります。 たとえば、一部の関数では、一部の引数には整数が必要で、他の関数の場合は日付が必要です。 その他の関数には、テキストまたはテーブルが必要です。
引数として指定した列のデータが関数に必要なデータ型と互換性がない場合、DAX はエラーを返す可能性があります。 ただし、可能な限り DAX は、データを必要なデータ型に暗黙的に変換しようとします。
例えば:
- 日付を文字列として入力すると、DAX は文字列を解析し、Windows の日付と時刻の形式の 1 つとしてキャストしようとします。
TRUE + 1 を追加すると、結果として2 を得ることができます。これは、DAX がTRUE を暗黙的に数値1 に変換し、その後 1 + 1を計算するためです。 - 1 つの値がテキスト ("12") で表され、もう一方が数値 (12) として表される 2 つの列に値を追加すると、DAX によって文字列が暗黙的に数値に変換され、数値の結果に加算されます。 式
= "22" + 22 は、44返します。 - 2 つの数値を連結しようとすると、DAX によって文字列として表示され、連結されます。 式
= 12 & 34 は、"1234"返します。
暗黙的なデータ変換の表
演算子は、要求された操作を実行する前に必要な値をキャストすることによって、DAX が実行する変換の種類を決定します。 次の表には、演算子の一覧と、交差するセル内のデータ型とペアになる各データ型に対して DAX が行う変換が示されています。
手記
これらのテーブルには、テキスト データ型が含まれていません。 数値がテキスト形式で表されている場合、Power BI は数値の種類を決定し、データを数値として表そうとする場合があります。
加算 (+)
| 整数 | 通貨 | 実数 | 日付/時刻 | |
|---|---|---|---|---|
| 整数 | 整数 | 通貨 | 実数 | 日付/時刻 |
| 通貨 | 通貨 | 通貨 | 実数 | 日付/時刻 |
| 実数 | 実数 | 実数 | 実数 | 日付/時刻 |
| 日付/時刻 | 日付/時刻 | 日付/時刻 | 日付/時刻 | 日付/時刻 |
たとえば、加算演算で通貨データと組み合わせて実数を使用する場合、DAX は両方の値を REAL に変換し、結果を REAL として返します。
減算 (-)
次の表では、行ヘッダーは minuend (左側) で、列ヘッダーはサブトラヘンド (右側) です。
| 整数 | 通貨 | 実数 | 日付/時刻 | |
|---|---|---|---|---|
| 整数 | 整数 | 通貨 | 実数 | 実数 |
| 通貨 | 通貨 | 通貨 | 実数 | 実数 |
| 実数 | 実数 | 実数 | 実数 | 実数 |
| 日付/時刻 | 日付/時刻 | 日付/時刻 | 日付/時刻 | 日付/時刻 |
たとえば、減算操作で他のデータ型で日付を使用する場合、DAX は両方の値を日付に変換し、戻り値も日付になります。
手記
データ モデルは単項演算子 - (負) をサポートしますが、この演算子はオペランドのデータ型を変更しません。
乗算 (*)
| 整数 | 通貨 | 実数 | 日付/時刻 | |
|---|---|---|---|---|
| 整数 | 整数 | 通貨 | 実数 | 整数 |
| 通貨 | 通貨 | 実数 | 通貨 | 通貨 |
| 実数 | 実数 | 通貨 | 実数 | 実数 |
たとえば、乗算演算で整数と実数を組み合わせた場合、DAX は両方の数値を実数に変換し、戻り値も REAL になります。
除算 (/)
次の表では、行見出しが分子、列見出しが分母です。
| 整数 | 通貨 | 実数 | 日付/時刻 | |
|---|---|---|---|---|
| 整数 | 実数 | 通貨 | 実数 | 実数 |
| 通貨 | 通貨 | 実数 | 通貨 | 実数 |
| 実数 | 実数 | 実数 | 実数 | 実数 |
| 日付/時刻 | 実数 | 実数 | 実数 | 実数 |
たとえば、除算演算で整数と通貨値を組み合わせた場合、DAX は両方の値を実数に変換し、結果も実数になります。
比較演算子
比較式では、DAX では、文字列値より大きいブール値と、数値または日付/時刻値より大きい文字列値が考慮されます。 数値と日付/時刻の値のランクは同じです。
DAX では、ブール値または文字列値の暗黙的な変換は行われません。 BLANK または空白の値は、他の比較値のデータ型に応じて、
次の DAX 式は、この動作を示しています。
=IF(FALSE()>"true","Expression is true", "Expression is false")は "Expression is true" を返します。=IF("12">12,"Expression is true", "Expression is false")は "Expression is true" を返します。=IF("12"=12,"Expression is true", "Expression is false")は "Expression is false" を返します。
DAX では、次の表に示すように、数値型または日付/時刻型の暗黙的な変換が行われます。
| 比較 演算子 |
整数 | 通貨 | 実数 | 日付/時刻 |
|---|---|---|---|---|
| 整数 | 整数 | 通貨 | 実数 | 実数 |
| 通貨 | 通貨 | 通貨 | 実数 | 実数 |
| 実数 | 実数 | 実数 | 実数 | 実数 |
| 日付/時刻 | 実数 | 実数 | 実数 | 日付/時刻 |
空白、空の文字列、0 個の値
DAX は、同じ新しい値の型である BLANK によって、null、空白値、空のセル、または欠損値を表します。 BLANK 関数を使用すると、空白を生成することもできます。空白かどうかをテストするには、ISBLANK 関数を使用します。
加算や連結などの操作でブランクを処理する方法は、個々の関数によって異なります。 次の表は、DAX 数式と Microsoft Excel 数式が空白を処理する方法の違いをまとめたものです。
| 表現 | DAX | エクセル |
|---|---|---|
| BLANK + BLANK | BLANK | 0 (ゼロ) |
| BLANK + 5 | 5 | 5 |
| BLANK * 5 | BLANK | 0 (ゼロ) |
| 5/BLANK | 無限大 | エラー |
| 0/BLANK | NaN | エラー |
| BLANK/BLANK | BLANK | エラー |
| FALSE OR BLANK | FALSE | FALSE |
| FALSE AND BLANK | FALSE | FALSE |
| TRUE OR BLANK | TRUE | TRUE |
| TRUE AND BLANK | FALSE | TRUE |
| BLANK OR BLANK | BLANK | エラー |
| BLANK AND BLANK | BLANK | エラー |
関連コンテンツ
Power BI Desktop とデータを使用して、あらゆる種類の操作を実行できます。 Power BI の機能の詳細については、次のリソースを参照してください。
- Power BI Desktop とは
- Power BI Desktop の
クエリの概要 - Power BI Desktop でのデータ ソース
- Power BI Desktop でデータを 整形し、結合する
- Power BI Desktop での一般的なクエリ タスク