テキスト アクション
テキスト アクションを使用すると、デスクトップ フローでテキスト値を処理、操作、および変換できます。
テキスト値のリストを単一のテキスト値にマージするには、テキストの結合アクションを使用します。 そのアクションではリストと区切り記号を指定する必要があります。
単一のテキスト値をリストに分割するには、テキストの分割アクションを展開し、テキスト値と区切り記号を指定してリスト アイテムを区切ります。
テキストのサブテキストを置き換えるには、 テキストの置換 アクションを使用します。 たとえば、次の例では、テキスト Product Characteristics の Characteristics への置き換えを行います。
![[テキストを置換する] アクションのスクリーンショット。](media/text/replace-text-example.png)
テキストの解析 アクションを使用して、別のテキスト内のテキスト値を検索します。
一部のテキスト アクションでは、正規表現を使用することができます。 テキストの解析 アクションで 正規表現である を有効にして、正規表現で指定されたテキストを検索します。 正規表現に関する詳細については、正規表現言語 - クイック リファレンス を参照してください。
さらに、最初の出現のみ を無効にして、一致したすべてのテキストの位置のリストを返すようにします。
次の例では、大文字で始まる Items detected in Stock 内のすべての単語を検索します。 生成された Matches という名前のリストには、値 Items と Stock が格納されます。 Positions リストには、値が見つかった位置 (1 と 18) が格納されます。
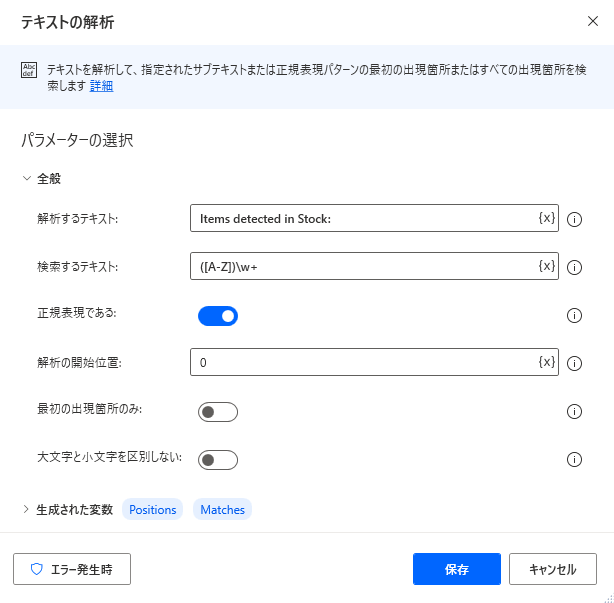
Power Automate では、テキスト内の検索だけでなく、テキストのトリミング アクションを使用して、テキストからテキスト値をトリミングすることができます。 トリミングするテキストは、最初に出現する特定の文字または文字列マーカーによって定義できます。 指定したテキスト フラグの前、後、または間で値をトリミングできます。
トリミングされたテキストは CroppedText 変数に格納され、IsFlagFound 変数を使用すると、アクションが設定されたフラグを検出したかどうかを確認できます。
数字を数値として保存するには、テキストを数値に変換 アクションを使用します。 逆変換を実行するには、数値をテキストに変換アクションを実行します。
同様に、テキストを日時に変換と日時をテキストに変換アクションを使って、日付が正しくフォーマットされていることを確認します。
テキスト アクションで [エンティティを認識] を使用する
デスクトップ フローを使用すると、エンティティをテキストで認識するアクションを通じて、数値、日付、測定単位など、自然言語のテキストからさまざまなエンティティを抽出できます。
![テキスト アクションの [エンティティを認識] のスクリーンショット](media/text/recognize-entities-text-action.png)
テキスト内のエンティティを認識するアクションは、入力としてテキストまたはテキストを含む変数を取得し、結果を含むデータブルを返します。 各エンティティはその構造に基づいて異なる結果を返しますが、すべてのデータ テーブルには、入力テキストのエンティティ部分を格納する元のテキストフィールドが含まれています。
次のテーブルは、テキスト内のエンティティを認識するアクションが認識できるエンティティのさまざまな例を示しています。
| Entity | テキストの入力 | 返された値 |
|---|---|---|
| 日時 | 2019 年 1 月 4 日に戻る | 値: 1/4/2019 12:00:00 AM 元のテキスト: 2019 年 1 月 4 日 |
| 日時 | 今夜午後 7 時に会議をスケジュールする | 値: 9/30/2021 7:00:00 PM 元のテキスト: 今夜の午後 7 時 |
| 分析コード | あなたの体重は 200 lbs です | 値: 200 単位: ポンド 元のテキスト: 200 ポンド |
| ディメンション | 竜巻が長さ約 10 マイルのエリアを通り抜けました | 値: 10 単位: マイル 元のテキスト: 10 マイル |
| 温度 | 外の気温は摂氏 40 度です | 値: 40 単位: C 元のテキスト: 摂氏 40 度 |
| 通貨型 | 当四半期の利息収入は 27 % 減少し、2 億 5,400 万ドルになりました | 値: 254000000 単位: ドル 元のテキスト: 2 億 5,400 万ドル |
| 数値の範囲 | この数は 20 より大きく、35 以下です | 開始: 20 終了: 35 元のテキスト: 20 より大きく 35 以下 |
| 数値の範囲 | 5 から 10 | 開始: 5 終了: 10 元のテキスト: 5 から 10 まで |
| 数値の範囲 | 4.565 未満 | 開始: 0 終了: 4.565 元のテキスト: 4.565 未満 |
| Number | ダース | 値: 12 元のテキスト: 1 ダース |
| Number | 3 分の 2 | 値: 0.666666666666667 元のテキスト: 3 分の 2 |
| 序数 | 私は最初の 2 冊が好きです | 値: 1 元のテキスト: 1 番目 |
| 序数 | 11 番目 | 値: 11 元のテキスト: 11 番目 |
| パーセント | 100 % | 値: 100 元のテキスト: 100 パーセント |
| 電話番号 | 電話番号: +1 209-555-0100 | 値: +1 209-555-0100 元のテキスト: +1 209-555-0100 |
| メール | felix@contoso.com | 値:felix@contoso.com 元のテキスト:felix@contoso.com |
| IP アドレス | 私の PC IP アドレスは 1.1.1.1 です | 値: 1.1.1.1 元のテキスト: 1.1.1.1 |
| 参照投稿 | @Alice | 値:@Alice 元のテキスト:@Alice |
| ハッシュタグ | #News | 値: #ニュース 元のテキスト: #ニュース |
| [URL] | www.microsoft.com | 値:www.microsoft.com 元のテキスト:www.microsoft.com |
| GUID | 123e4567-e89b-12d3-a456-426655440000 | 値: 123e4567-e89b-12d3-a456-426655440000 元のテキスト: 123e4567-e89b-12d3-a456-426655440000 |
| 引用されるテキスト | [値] フィールドに値を入力します | 値: "値" 元のテキスト: "値" |
Note
テキスト内のエンティティを認識するアクションは 14 の言語をサポートします。 ただし、一部のエンティティは特定の言語で使用できない場合があります。 言語制限の詳細については、Microsoft Recognizers テキスト - 異文化間でサポートされているエンティティを参照してください。
テキストに行を追加
テキストの値に新しい行を追加します。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Original text | いいえ | テキスト値 | 元のテキスト | |
| Line to append | はい | Text 値 | 新しい行として追加するテキスト |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| Result | Text 値 | 新しいテキスト |
例外
このアクションには例外は含まれません。
サブテキストの取得
テキスト値からサブテキストを取得します。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Original text | いいえ | テキスト値 | テキストのセクションの取得元のテキスト | |
| Start index | N/A | テキストの開始、文字の位置 | 文字の位置 | テキスト取得の開始位置を見つける方法を指定します |
| Character position | いいえ | 数値 | 取得する最初の文字の位置です。 この値はゼロベースのインデックスであり、最初の文字をゼロから数えます | |
| Length | N/A | テキストの終わり、文字数 | Number of chars | サブテキストがテキストの末尾まで続くのか、一定の文字数のみを含むかを指定します |
| Number of chars | いいえ | 数値 | 取得する文字数 |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| Subtext | Text 値 | 取得するサブテキスト |
例外
| 例外 | 内容 |
|---|---|
| 開始インデックスまたは長さが範囲外です | 開始インデックスまたは長さが範囲外であることを示します |
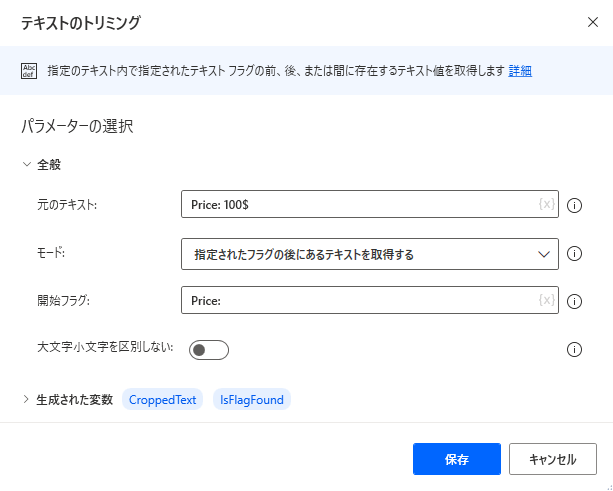
テキストのトリミング
指定のテキスト内で指定されたテキスト フラグの前、後、または間に存在するテキスト値を取得します。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Original text | いいえ | Text 値 | テキストのセクションの取得元のテキスト | |
| Mode | N/A | 指定したフラグの前のテキストを取得、指定したフラグの後のテキストを取得、指定した 2 つのフラグの間のテキストを取得 | 指定されたフラグの前にあるテキストを取得する | テキストをフラグの前、後、または間のどこから取得するかを指定します。 |
| 開始フラグ | いいえ | Text 値 | 取得したテキストは、このフラグの後になります。 フラグには任意の文字やテキストを使用できます | |
| 終了フラグ | いいえ | Text 値 | 取得したテキストは、このフラグの前になります。 フラグには任意の文字やテキストを使用できます | |
| Ignore case | N/A | ブール値 | False | 大文字と小文字を区別した照合でフラグを検索するかどうかを指定します |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| CroppedText | Text 値 | トリミングされた新しいテキスト |
| IsFlagFound | ブール値 | フラグが見つかったかどうかを示します |
例外
このアクションには例外は含まれません。
テキストをパディングする
既存のテキストの左または右に文字を追加することによって固定長のテキストを作成します。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Text to pad | はい | テキスト値 | 長くするテキスト | |
| Pad | N/A | 左、右 | 左へ移動 | 既存のテキストの左または右に文字を追加するかどうかを指定します |
| Text for padding | はい | テキスト値 | 元のテキストを長くするために追加される文字またはテキスト | |
| Total length | はい | 数値 | 10 | 最終的なパディングされたテキストの文字数の合計です。 最終的なテキストが指定した長さになるまでテキストのパディングが繰り返し追加されます |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| PaddedText | Text 値 | パディング後の新しいテキスト |
例外
このアクションには例外は含まれません。
テキストのトリミング
既存のテキストの先頭または末尾から空白文字 (スペース、タブ、改行など) がすべて削除されます。
テキストのトリミング アクションは、テキスト値を入力として受け取り、What to trim パラメーターに従ってテキスト出力を生成します。 What to trim パラメーターで使用可能なオプションは次のとおりです:
- 先頭の空白文字
- 末尾の空白文字
- 先頭と末尾の空白文字
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Text to trim | はい | テキスト値 | トリミングするテキスト | |
| What to trim | N/A | 先頭から空白文字、末尾から空白文字、先頭と末尾から空白文字 | 先頭と末尾の空白文字 | 空白文字の削除を開始する位置を指定します |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| TrimmedText | Text 値 | トリミング後の新しいテキスト |
例外
このアクションには例外は含まれません。
テキストを反転
テキスト文字列の文字の順序を逆にします。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| 反転させるテキスト | いいえ | Text 値 | 反転させるテキスト |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| ReversedText | Text 値 | 反転した新しいテキスト |
例外
このアクションには例外は含まれません。
テキストの文字の大きさを変更する
テキストの文字の大きさを大文字、小文字、タイトルの文字の大きさ、または文の文字の大きさに変更します。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Text to convert | はい | テキスト値 | 変換するテキスト | |
| Convert to | N/A | 大文字、小文字、タイトル大文字、大文字小文字 | 大文字 | 使用するテキストの文字の大きさのスタイルを指定します |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| TextWithNewCase | Text 値 | 変換後の新しいテキスト |
例外
このアクションには例外は含まれません。
テキストを数値に変換
数値のテキスト表現を、数値を含む変数に変換します。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Text to convert | いいえ | テキスト値 | 数値のみを含むテキスト変数を数値変数に変換します。 スペースは無視されますが、数字以外のテキストは例外をスローします |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| TextAsNumber | 数値 | 新しい数値 |
例外
| 例外 | 内容 |
|---|---|
| 指定されたテキスト値を有効な数値に変換できません | 指定されたテキスト値を有効な数値に変換できないことを示します |
数値をテキストに変換
指定された形式を使って数値をテキストに変換します。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Number to convert | いいえ | 数値 | テキストに変換する数値 | |
| Decimal places | はい | 数値 | 2 | 切り捨て前に含まれる小数点以下の桁数です。 ゼロを末尾に追加して、このようにテキストを埋めることもできます |
| Use thousands separator | N/A | ブール値 | 有効 | 句読点を 1000 の桁区切り記号として使うかどうかを指定します |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| FormattedNumber | Text 値 | テキストとして形式設定された数値 |
例外
このアクションには例外は含まれません。
テキストを datetime に変換
日付/時刻値のテキスト表現を datetime 値に変換します。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Text to convert | いいえ | テキスト値 | datetime 値に変換するテキストです。 このテキストは、識別可能な日付時間の値の形式である必要があります | |
| Date is represented in custom format | N/A | ブール値 | 無効 | 変換するテキストに標準以外の認識できない形式の日時表現が含まれているかどうかを指定します |
| Custom format | いいえ | テキスト値 | テキストに日付が格納される形式です。 カスタム形式は、たとえば、日付を yyyyMMdd、時間を hhmmss と表すことができます |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| TextAsDateTime | 日時 | datetime 値 |
例外
| 例外 | 内容 |
|---|---|
| 指定されたテキスト値を有効な datetime に変換できません | 指定されたテキスト値を有効な datetime に変換できないことを示します |
datetime をテキストに変換
指定されたカスタム形式を使って、datetime 値をテキストに変換します。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Datetime to convert | いいえ | Datetime | テキストに変換する datetime 値 | |
| Format to use | N/A | 標準、カスタム | Standard | 標準の datetime 形式を使うか、カスタム形式を作成するかを指定します |
| Custom Format | いいえ | テキスト値 | 日時の値を表示するカスタム形式です。 datetime は、日付の場合は MM/dd/yyyy、時刻の場合は hh: mm: sstt などと表すことができます | |
| Standard format | N/A | 短い日付、長い日付、短い時間、長い時間、完全な日時 (短時間)、完全な日時 (長時間)、一般的な日時 (短時間)、一般的な日時 (長時間)、並べ替え可能な日時 | 短い日付形式 | アクションが datetime 値を表示するために使う標準 datetime 形式 |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| FormattedDateTime | Text 値 | テキスト値として形式設定された datetime |
例外
このアクションには例外は含まれません。
ランダム テキストの作成
ランダムな文字で構成される指定された長さのテキストを生成します。 このアクションは、パスワードの生成に役立ちます。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Use uppercase letters (A-Z) | N/A | ブール値 | 有効 | 生成されるテキストに大文字を含めるかどうかを指定します |
| Use lowercase letters (a-z) | N/A | ブール値 | 有効 | 生成されるテキストに小文字を含めるかどうかを指定します |
| Use digits (0-9) | N/A | ブール値 | 有効 | 生成されるテキストに数字を含めるかどうかを指定します |
| 記号 ( , . <> ? ! + - _ # $ ^ ) を使用します | N/A | ブール値 | True | 生成されるテキストに記号を含めるかどうかを指定します |
| Minimum length | はい | 数値 | 6 | ランダムテキストの最小の長さ。 特定の長さのテキストの場合、その数値に最小値と最大値を設定します |
| Maximum length | はい | 数値 | 10 | ランダムテキストの最大の長さ。 特定の長さのテキストの場合、その数値に最小値と最大値を設定します |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| RandomText | Text 値 | 生成されるランダム テキスト |
例外
このアクションには例外は含まれません。
テキストの結合
項目を指定した区切り記号で区切って、リストをテキスト値に変換します。
リストのすべての内容を 1 つのテキスト値に結合するには、テキストの結合 アクションを使用します。 まず、Specify list to join プロパティで使用するそれぞれのリストを指定します。 Delimiter to separate list items プロパティ ドロップダウン リストでそれぞれ選択することで、結合テキスト内のリスト項目を区切る区切り記号を選択できます。
- なし は、リスト内のすべての項目を区切り記号で区切らずに結合して、単一の結合リテラルを作成します。
- 標準 では、Standard delimiter プロパティ ドロップダウン リストでそれぞれのオプションを選択することで、区切り記号をスペース、タブ、または新しい行として設定できます。 Times プロパティを変更することで、各リスト項目間に区切り記号を表示する回数を選択することもできます。
- カスタム では、独自の区切り記号を設定できます。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Specify the list to join | いいえ | テキスト値のリスト | テキストに変換するリスト | |
| Delimiter to separate list items | N/A | なし、標準、カスタム | いいえ | 区切り記号を使うかどうか、標準の区切り記号とカスタム区切り記号のどちらを使うかを指定します |
| Custom delimiter | いいえ | テキスト値 | 区切り記号として使う文字 | |
| Standard delimiter | N/A | スペース、タブ、改行 | スペース | 使う区切り記号を指定 |
| Times | はい | 数値 | 1 | 指定した区切り記号の使用回数を指定します |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| JoinedText | Text 値 | 区切った後の新しいテキスト |
例外
このアクションには例外は含まれません。
テキストの分割
指定された区切り記号または正規表現によって区切られたテキストの部分文字列を含むリストを作成します。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| The text to split | いいえ | テキスト値 | 分割するテキスト | |
| Delimiter type | N/A | 標準、カスタム | Standard | 使用される区切り記号が標準の形式かカスタム形式か |
| Custom delimiter | いいえ | テキスト値 | 区切り記号として使用された文字 | |
| Standard delimiter | N/A | スペース、タブ、改行 | スペース | 使用される区切り記号 |
| Times | はい | 数値 | 6 | 区切り記号の使用回数を指定します |
| Is regular expression | N/A | ブール値 | False | 区切り文字を正規表現にするかどうかを指定します。 正規表現は、区切り文字のさまざまな可能性をもたらします。 たとえば、「\ d」は、区切り文字が任意の数字であることを意味します |
Note
Power Automate の正規表現エンジンは .NET です。 正規表現に関する詳細については、正規表現言語 - クイック リファレンス を参照してください。
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| TextList | テキスト値 の リスト | 新しいリスト |
例外
| 例外 | 内容 |
|---|---|
| 指定された正規表現が無効です | 指定された正規表現が無効であることを示します |
テキストの解析
テキストを解析して、指定されたサブテキストまたは正規表現パターンの最初の出現箇所またはすべての出現箇所を解析します。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Text to Parse | いいえ | テキスト値 | 解析するテキスト | |
| Text to Find | いいえ | テキスト値 | 検索するサブテキストまたは正規表現 | |
| Is regular expression | N/A | ブール値 | 無効 | サブテキストが正規表現であるかどうかを指定します。 たとえば、「\ d」は、サブテキストが任意の数字であることを意味します |
| Start Parsing at Position | いいえ | 数値 | 「検索するテキスト」の検索を開始する位置です。 最初の位置はゼロなので、最初から開始するには 0 を使用します | |
| First occurrence only | N/A | ブール値 | 有効 | 最初の出現箇所のみを検索するか、[検索するテキスト] の各出現箇所を検索するかを指定します |
| Ignore case | N/A | ブール値 | 無効 | 大文字と小文字を区別して指定されたテキストを検索するかどうかを指定します |
Note
Power Automate の正規表現エンジンは .NET です。 正規表現に関する詳細については、正規表現言語 - クイック リファレンス を参照してください。
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| Position | 数値 | 「検索するテキスト」の「解析するテキスト」への位置。 元のテキスト内にテキストが見つからない場合、この変数は値 -1 を保持します |
| Positions | 数値の一覧 | 「検索するテキスト」の「解析するテキスト」への位置。 元のテキスト内にテキストが見つからない場合、この変数は値 -1 を保持します |
| Match | テキスト値 | 指定された正規表現に一致する結果 |
| Matches | テキスト値のリスト | 指定された正規表現に一致する結果 |
例外
| 例外 | 内容 |
|---|---|
| 指定された正規表現が無効です | 指定された正規表現が無効であることを示します |
テキストを置換する
指定されたサブテキストのすべての出現を、指定された別のテキストに置き換えます。 正規表現でも使用できます。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Text to parse | いいえ | テキスト値 | 解析するテキスト | |
| Text to find | いいえ | テキスト値 | 検索するサブテキストまたは正規表現 | |
| Use regular expressions for find and replace | N/A | ブール値 | 無効 | サブテキストが正規表現であるかどうかを指定します。 正規表現は、サブテキストのさまざまな可能性をもたらします。 たとえば、「\ d」は、サブテキストが任意の数字であることを意味します |
| Ignore case | N/A | ブール値 | 無効 | 大文字と小文字を区別して置換するサブテキストを検索するかどうかを指定します |
| Replace with | いいえ | テキスト値 | 検索されたテキストを置き換えるためのテキストまたは正規表現 | |
| Activate escape sequences | N/A | ブール値 | 無効 | 特別なシーケンスを使用するかどうかを指定します。 たとえば、置換テキスト内の '\t' はタブとして解釈されます |
Note
Power Automate の正規表現エンジンは .NET です。 正規表現に関する詳細については、正規表現言語 - クイック リファレンス を参照してください。
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| Replaced | Text 値 | 更新後の新しいテキスト |
例外
このアクションには例外は含まれません。
正規表現のエスケープ テキスト
文字の最小セット (、*、+、?、|、{、[、]、^、$、.、#、空白) をエスケープ コードに置き換えてエスケープします。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| Text to escape | いいえ | Text 値 | エスケープするテキスト |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| EscapedText | Text 値 | エスケープ テキスト |
例外
このアクションには例外は含まれません。
エンティティをテキストで認識する
数値、単位、日時のエンティティ、および自然言語で表現された (複数言語対応) その他のエンティティをテキストで認識します。
入力パラメーター
| 引数 | オプション | 受入 | Default Value | 説明設定 |
|---|---|---|---|---|
| 認識を行うテキスト | いいえ | テキスト値 | エンティティを認識するテキスト | |
| エンティティ型 | N/A | 日時、寸法、温度、通貨、数値範囲、数値、序数、パーセント、電話番号、メール、IP アドレス、メンション、ハッシュタグ、URL、GUID、引用符付きテキスト | 日時 | 認識するエンティティの種類 (日付、メール、URL など) |
| Language | N/A | 英語、中国語 (簡体字)、スペイン語、スペイン語 (メキシコ)、ポルトガル語、フランス語、ドイツ語、イタリア語、日本語、オランダ語、韓国語、スウェーデン語、トルコ語、ヒンディー語 | 英語 | テキストの言語を指定してください |
生成された変数
| 引数 | タイプ | 説明設定 |
|---|---|---|
| RecognizedEntities | Datatable | 認識されたエンティティ |
例外
このアクションには例外は含まれません。
HTML コンテンツを作成
リッチ HTML コンテンツを生成し、変数に格納します。
このアクションにより、ユーザーは書式設定された直感的な方法でHTMLコンテンツを作成し、テキスト変数に保存できるようになります。 この変数は、HTML 形式が必要な次のアクションで使用できます。
この機能は主に、’本文' 入力パラメータに関する電子メール送信アクション '電子メールの送信'、'Exchange 電子メール メッセージの送信'、および 'Outlook 経由の電子メール メッセージの送信' に役立ちます。 具体的には、Body is HTML オプションが有効な場合、生成された変数は、フローの後続の電子メール送信アクションの 'Body' パラメータでそのまま使用できます。。
入力パラメーター
入力パラメーターは、埋め込み HTML エディターを使用して構成されます。
HTML エディターの初期ビューでは、レンダリングされた HTML コンテンツをすぐに編集でき、上部にあるツールバーを通じて一連の書式設定オプションが提供されます。これには、リンク、画像 (ローカル パスまたは URL 経由)、テーブル、さらに動的コンテンツの変数を挿入する機能も含まれます。
テキスト エディタ オプションを有効にすると、対応する要素タグを含む HTML 言語を使用できるビューに切り替わります。
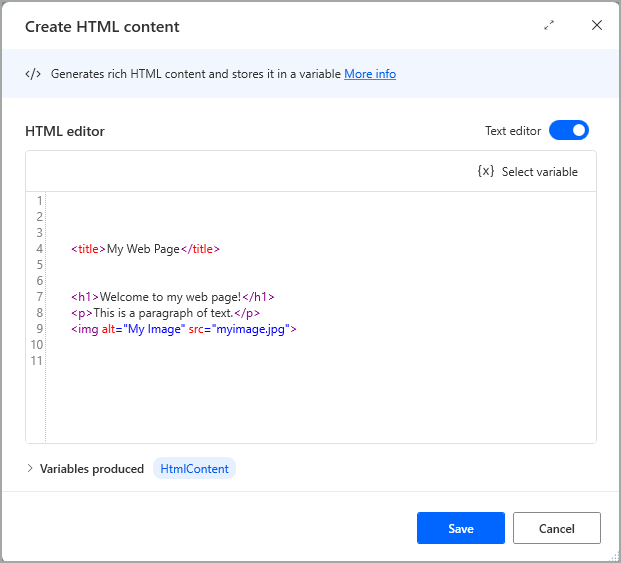
<head> 要素と <body> 要素は、HTML コンテンツをレンダリングするためにテキスト エディターで必要ありません。
生成される変数
| 引数 | タイプ | Description |
|---|---|---|
HtmlContent |
テキスト値 | HTML コードです |
例外
このアクションには例外は含まれません。