スケーラブル カスタマイズ設計: トランザクション デザイン パターン
注意
これは、スケーラブル カスタマイズ設計に関する 4 つめのトピックです。 最初から始めるには、Microsoft Dataverse におけるスケーラブル カスタマイズ設計 を参照してください。
このセクションでは、回避または最小化する設計パターンとその影響について説明します。 それぞれの設計パターンは、解決されるビジネス上の課題という観点から考慮する必要があり、調査するための選択肢として役立ちます。
ロックを避けないようにする
ロックは SQL Server と Dataverse の重要なコンポーネントであり、システムの正常な動作と一貫性を保つために不可欠です。 このため、特にスケールで、デザインへの影響を理解することが重要です。
トランザクションの使用: Nolock のヒント
ビューで頻繁に使用される Dataverse プラットフォームの 1 つの機能は、クエリを nolock のヒントで実行できることを指定する機能です。これにより、このクエリにロックが不要であることをデータベースに伝えます。
ビューは、ビューおよびそれ以降のアクションのトップに間に直接リンクがないため、この方法を使用します。 そのユーザー、またはその間にいる他のユーザーによって、他にも多くのアクティビティが発生する可能性があります。ビューに表示されるデータのテーブル全体をロックして、ユーザーが移動するまで待機するのは実用的ではなく、利益もありません。
大規模なデータセットに対するクエリは、そのデータのいずれかと対話しようとしている他のユーザーに影響を与える可能性があるため、ロックが不要であると指定できるということは、システムのスケーラビリティに対して大きなメリットがあります。
SDK を介してプラットフォームのクエリを作成するときに、nolock が使用できるように指定することは有益です。 これは、このクエリがデータベース内で読み取りロックを取得する必要がないことを認識していることを示しています。 クエリに特に有効なのは、次の場合です。
- スコープのデータ全体があるとき
- 競合の激しいリソースでクエリが実行されたとき
- シリアル化は重要ではない
前述の自動付番のロックの例のように、後の操作が結果の変更に依存しない場合は、Nolock を使用しないでください。
それが役に立つ可能性のあるシナリオの例としては、電子メールが既存のケースに関連しているかどうかを判断することが挙げられます。 他のユーザーが新しいケースを作成するのをブロックして、電子メールが確実に作成されないようにすることは、一貫性のコントロールに対して有益だとは言えません。
代わりに、関連するケースにクエリを実行して既存のケースに電子メールを添付するか、他のケースを生成できるようにする一方で新しいケースを作成するといった、妥当な努力をするほうがより適切です。 特に、これら 2 つのアクションの間のタイミングには固有のリンクがないため、電子メールが数秒早く受信してリンクが検出されなかった可能性があります。
ロックのヒントが特定のシナリオに有効であるかどうかは、通常、競合が発生する可能性と影響、および取得と後続の間にあるアクションの一貫性を保証しないことによるビジネス上の影響の判断に基づきます。 ロックを回避してもビジネス上の影響が生じない場合は、nolock を使用することが最適化の良い選択肢となります。 ビジネスに潜在的な影響がある場合は、その影響について、ロックを回避することによるパフォーマンスと拡張性のメリットを比較検討することができます。
ロックの順番を考える
ブロックの影響を減らす、特にデッドロックを回避するのに役立つ可能性があるもう 1 つの方法は、実装内でのロックの順序付けに対する一貫性のあるアプローチです。
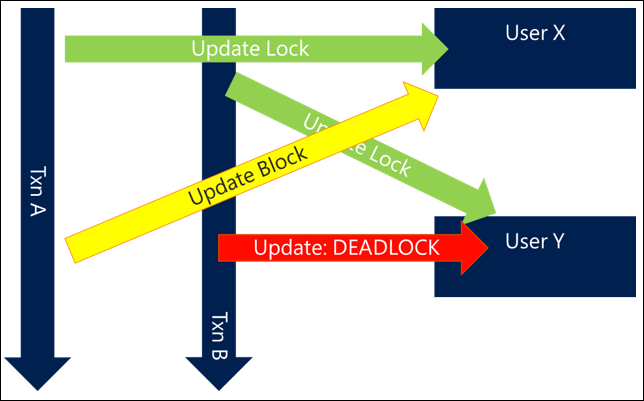
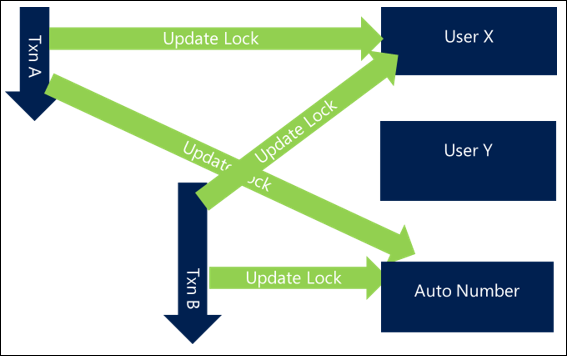
単純で一般的な例は、ユーザーのグループを更新または対話するときです。 関連ユーザーを更新するリクエスト (チームへのメンバーの追加やアクティビティ内のすべての参加者の更新など) がある場合に、2 つの同時アクティビティが同じユーザーを更新しようとすると、次のような動作になる可能性があり、その結果、デッドロックが発生します。
- トランザクション A はユーザー X を更新してからユーザー Y を更新しようとします
- トランザクション B はユーザー Y を更新してからユーザー X を更新しようとします
両方の要求が同時に開始されるため、トランザクション A はユーザー X をロックし、トランザクション B はユーザー Y をロックすることができますが、各ユーザーが他のユーザーをロックしようとするとすぐにブロックされ、その後デッドロックが発生します。
一貫した方法でアクセスするリソースを順番に並べるだけで、多くのデッドロックされる状況を防ぐことができます。 順序付けメカニズムは、一貫性があり、できるだけ効率的に実行できる限り、多くの場合重要ではありません。 たとえば、名前または GUID でユーザーを並べ替えることで、少なくともデッドロックを回避する一定レベルの一貫性を確保できます。
このアプローチを使用するシナリオでは、トランザクション A はユーザー X を取得しますが、トランザクション B もユーザー Y よりもユーザー X を取得しようとします。 これは、トランザクション A が完了するまでトランザクション B がブロックされることを意味しますが、このシナリオではデッドロックが回避され、正常に完了します。
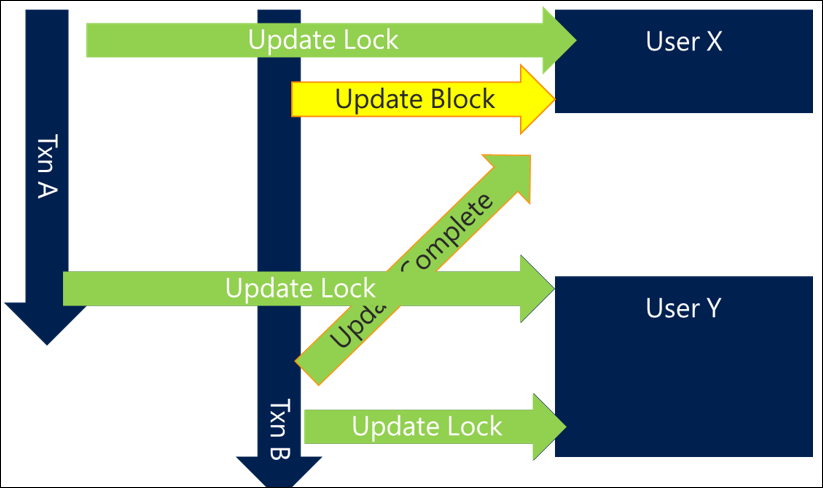
より複雑で効率的なシナリオでは、最初に最も一般的に参照されていないユーザーをロックし、最後により頻繁に参照されているユーザーをロックすることです。これにより、次の設計パターンにつながります。
最短期間、競合するロックを保持する
自動付番アプローチのような、ロックが必要な競合の激しいリソースの存在を回避する方法がないというシナリオがあります。 その場合、ブロックの問題を回避することはできませんが、最小限に抑えることはできます。
競合の激しいリソースがある場合は、プロセス内の機能的に論理的なポイントにそのリソースとの対話を含めないで、できるだけトランザクションの終わりで、そのトランザクションとの対話を行うことをお勧めします。
この方法では、まだこのリソースをある程度ブロックすることになりますが、リソースがロックされる時間が短縮されるため、リソースを待っている間に他の要求がブロックされる可能性と時間が減少します。
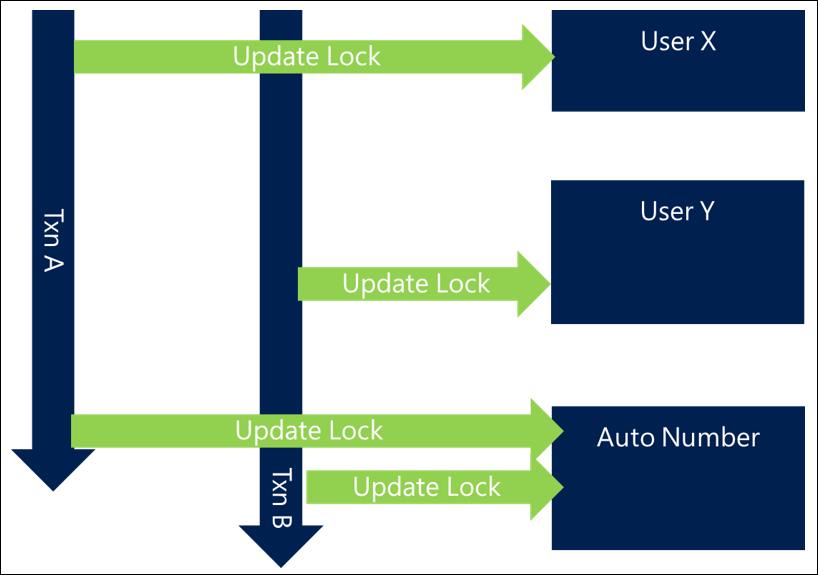
対話の長さを減らす
同様に、ロックは、2つのプロセスが同時に同じリソースにアクセスする必要がある場合にのみブロックの問題になります。 ロックを保持するトランザクションが短くなればなるほど、2つのプロセスが同じリソースにアクセスしたとしても、それらがまったく同時に同じリソースを必要とし、衝突を引き起こす可能性は低くなります。 トランザクションの保持時間が短いほど、ブロックが問題になる可能性は低くなります。
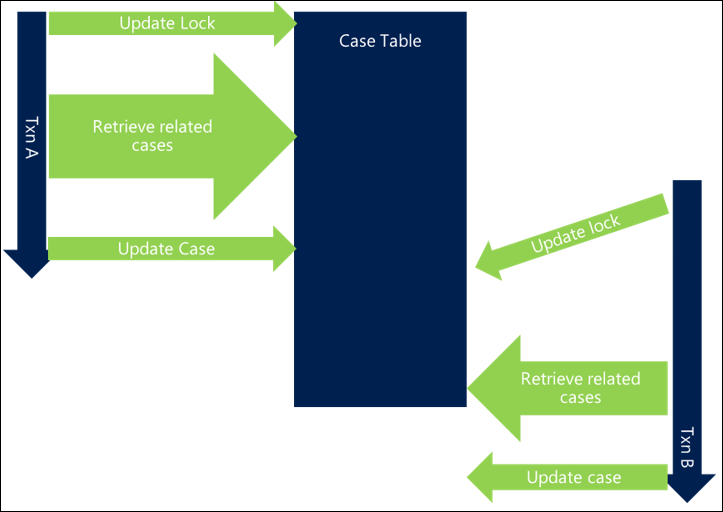
次の例では、同じロックが選択されますが、トランザクション内の他の処理は、トランザクションの全体の長さが拡張され、同じリソースに対する要求が重複することを意味します。 つまり、ブロックが発生し、各リクエストは全体的に遅くなるということです。
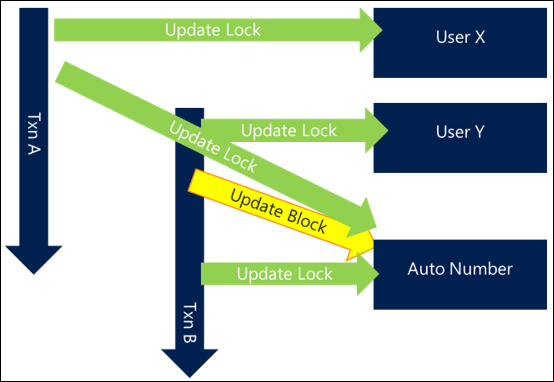
トランザクションの全長を短くすることで、最初のトランザクションは 2 番目の要求が開始される前にロックを完了して解放します。つまり、ブロックがなく、両方のトランザクションが効率的に完了します。
トランザクションの寿命を延ばすリクエスト内の他のアクティビティは、特に複数のリクエストが重複している場合にブロックの可能性を高め、システムが大幅に遅くなる可能性があります。
トランザクションを短くする方法はたくさんあります。
最適化要求
各トランザクションは一連のデータベース要求で構成されています。 各要求ができるだけ高く効率的になされれば、トランザクション全体の長さを減らして競合する可能性を低減します。
各クエリを確認して、以下の事を判断します。
クエリが、必要なもの、たとえば列、レコード、エンティティ タイプなどを尋ねるだけです。
- これにより、インデックスを使用してクエリを効率的に処理できる可能性が最大化されます
- アクセスする必要があるテーブルとリソースの数を減らし、データベース サーバ内の他のリソースのオーバーヘッドを減らし、クエリ時間を短縮します
- 特に、別のテーブルへの結合が要求があったが、その要求を回避される可能性がある場合や、その要求が不要な場合に、不要なリソースをブロックしないようにします
クエリを補助するためのインデックスが用意されているか、効率的な方法でクエリを実行しているか、スキャンではなくインデックス シークが行われる
インデックスを導入しても、基礎となるテーブル内のレコードの作成または更新がロックされるのを避けることはできません。 インデックス自体が変更される可能性があるため、関連レコードが更新されると、インデックス内の項目もロックされます。 インデックスが存在しても、この問題を完全に回避することはできません。
次の例では、関連する案件の取得が最適化されておらず、トランザクション全体の長さが増し、スレッド間でブロックが発生しています。
クエリを最適化することで、クエリの実行にかかる時間が短縮され、衝突の可能性が低くなるため、ブロックが減少します。
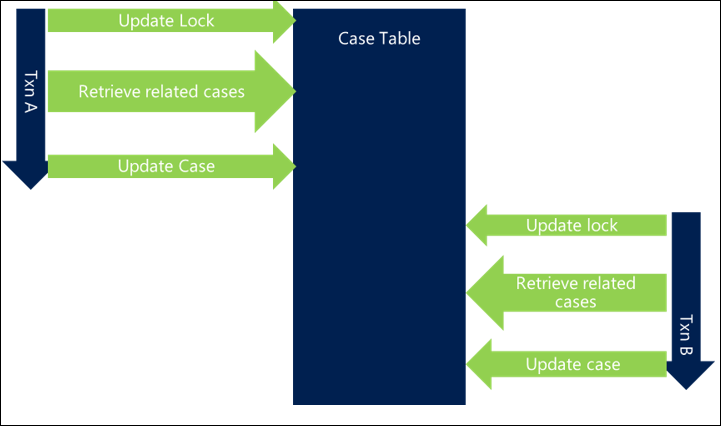
データベース サーバーが可能な限り効率的にクエリを処理できることを確認することで、トランザクションの全体的な時間を大幅に短縮し、ブロックの可能性を減らすことができます。
イベントのチェーンを削減する
前の例で示したように、関連する一連のイベントの結果はトランザクション時間全体に重大な影響を与えるかもしれないので、ブロックの可能性が生じます。 これは、同期プラグインとワークフローをトリガーし、それが他のアクションをトリガーし、さらに同期プラグインとワークフローをトリガーする場合に特に当てはまります。
同期して発生する長いイベントのチェーンを回避するために、実装を慎重に検討および設計することは、トランザクション全体の長さを短縮するのに役立ちます。 これにより、実行されたロックをより迅速に解放し、ブロックする可能性を減らすことができます。
また、二次ロックが大きな問題になる可能性も低くなります。 アカウント作成の自動付番の例では、最初の問題は自動付番テーブルへのアクセスです。しかし、多くの異なるアクションが 1 つのシーケンスで実行されると、関連するユーザー レコードへの更新など、二次ブロックも表面化し始める可能性があります。 複数の競合するリソースが関与すると、ブロックを回避することがさらに難しくなります。
いくつかのアクティビティが同期または非同期である必要があるかどうかを検討することは、同じアクティビティが達成される一方で初期の影響が少ないという意味です。 特に実行時間が長いアクションや、競合の激しいリソースに依存するアクションの場合は、非同期アクションで実行しメイントランザクションからそれらを分離すると、大きなメリットがあります。 次の自動付番の値で警察犯罪レポートを更新して連続番号スキームを確実に維持するなど、アクションをより広いプラットフォーム ステップで完了または失敗させる必要がある場合、このアプローチは機能しません。 これらのシナリオでは、影響を最小限に抑えるために他のアプローチをとる必要があります。
次の例が示すように、単純にアクションをプラットフォーム トランザクションの外側で実行することを意味する、いくつかのアクションを非同期プロセスに移動することによって、トランザクションの長さが短くなり、並行処理の可能性が高まることを意味します。
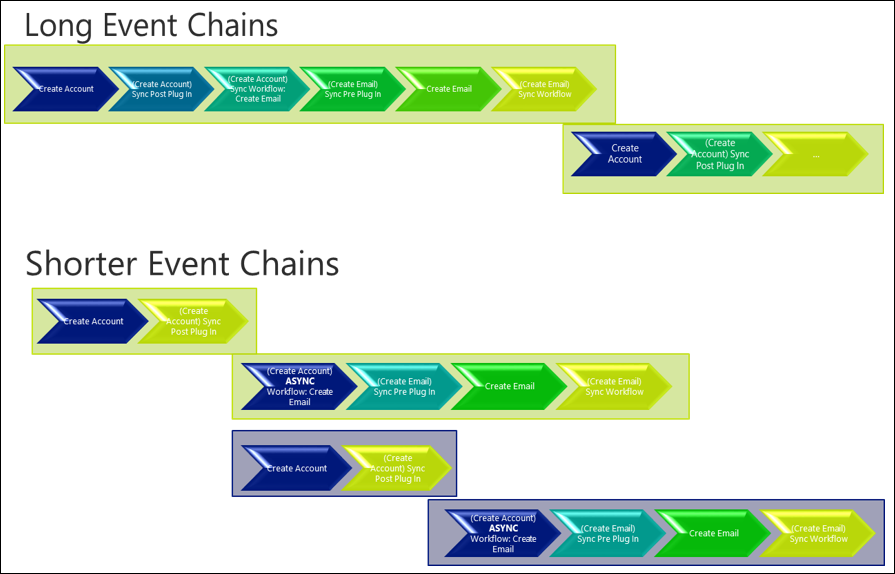
同じレコードに対する複数の更新を避ける
複数レイヤーの機能アクティビティを設計するときは、必要なアクションを論理的で簡単に従うことができるアクティビティ フローに分割することをお勧めしますが、多くの場合、これによって同じレコードに対する、複数の別々の更新が発生します。
ケースを処理するシナリオでは、最初に提起された顧客に基づいて既定の所有者でケースを更新し、その後、その顧客に自動的に通信を送りケースに対する最終連絡日を更新する別のプロセスを待機することは、機能的には完全に論理的です。
ただし、これは、次のように Dataverse が同じレコードを更新するための多数の要求があることを意味しています。
- 各要求は個別のプラットフォームの更新であり、Dataverse サーバーに全体的な負荷がかかり、トランザクション全体の長さを増大させるため、ブロックされる可能性が高くなります。
- また、ケース レコードがそのケースで最初に実行されたアクションからロックされることを意味します。つまり、ロックは残りのトランザクションを通じて保持されます。 ケースが複数の並列プロセスによってアクセスされる場合、それは他のアクティビティのブロックを引き起こす可能性があります。
同じレコードへの更新を単一の更新ステップに統合し、その後のトランザクションで、特にレコードが作成後すぐに複数の人によって激しい競合やアクセスがある場合、全体的なスケーラビリティに大きな利点があります。
同じレコードに対する更新を単一のプロセスに統合するかどうかの決定は、実装の複雑さと、個別の更新によってもたらされる競合の可能性とのバランスをとることに基づいて行われます。 しかし、ボリュームの大きいシステムでは、これは競合の激しいリソースにとってメリットがあります。
必要なものだけを更新する
有益なアクティビティを除外して Dataverse システムのメリットを減らさないことが重要ですが、ビジネス上の価値はほとんどないが技術的な複雑さを増すカスタマイズを含めるように要求されることがよくあります。
タスクを作成するたびに、現在割り当てられているタスクの数でユーザー レコードも更新すると、ユーザー レコードも競合する可能性があるため、二次レベルのブロックが発生する可能性があります。 必ずしもアクションにとって重要ではないにもかかわらず、それが各要求がブロックして待つ必要があるかもしれない別のリソースを追加するでしょう。 その例では、ユーザーに対するタスクの数を格納することが重要であるのか、それともオンデマンドで計算できるのか、Dataverse の階層およびロールアップ フィールド機能をネイティブで使用するといったような別の場所に格納できるのかどうかを慎重に検討してください。
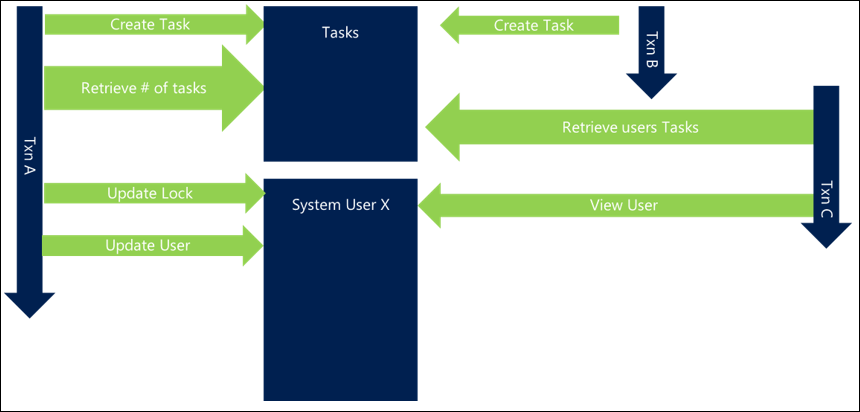
後で示すように、システム ユーザー レコードを更新すると、スケーラビリティの観点から悪影響が出る可能性があります。
同じイベントでトリガーされた複数のカスタマイズ
同じイベントで複数のアクションをトリガーすると、リクエストの性質上、これらのアクションが同じ関連オブジェクトまたは親オブジェクトと対話する可能性が高いため、衝突の可能性が高くなります。
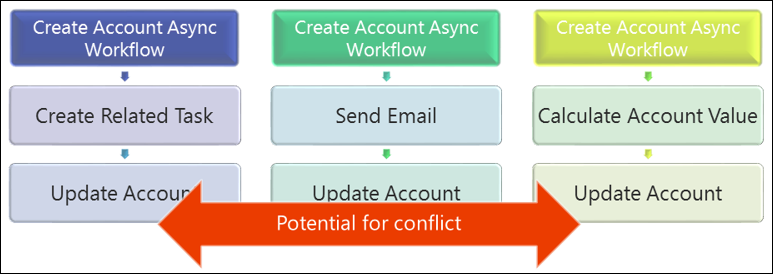
これは、慎重に検討または回避する必要があるパターンです。特に異なる人が異なるプロセスを実装するときには、競合を見落としがちなためです。
異なる種類のカスタマイズを使用する場合
カスタマイズの種類ごとに、使用方法が異なります。 次の表は、それぞれを考慮して使用する必要がある場合、および使用に適していない場合の一般的なパターンをまとめたものです。
さまざまな動作間の妥協点を検討する必要がある場合が多いので、これにより、考慮すべきいくつかの共通の特性とシナリオについてのガイダンスが得られますが、各シナリオを評価し、すべての関連要因に基づいて適切なアプローチを選択する必要があります。
| 前 / 後 ステージ | 同期 / 非同期 | カスタマイズの種類 | を使用する場合 | when_not_to_use_dmm |
|---|---|---|---|---|
| 事前検証 | Sync | プラグイン | 入力値の短期検証 | 長期実行アクション。 後のステップが失敗した場合にロールバックする必要がある関連アイテムを作成するとき。 |
| 事前操作 | Sync | ワークフロー / プラグイン | 入力値の短期検証 プラットフォームのステップの失敗の一部としてロールバックする必要がある関連アイテムを作成するとき。 |
長期実行アクション。 アイテムとその GUID を作成するには、項目に対して保存する必要があるときに、プラットフォームを作成 / 更新します。 |
| 事後操作 | Sync | ワークフロー / プラグイン | プラットフォームのステップに通常通り従い、後のステップが失敗した場合にロールバックする必要がある短期間のアクション (たとえば、新しく作成されたアカウントの所有者に対するタスクの作成)。 作成したアイテムの GUID を必要とし、失敗した場合にプラットフォームのステップをロールバックする必要がある関連アイテムの作成 |
長期実行アクション。 失敗がプラットフォーム パイプラインのステップの完了に影響を及ぼさないようにします。 |
| イベント パイプラインには無し | 同期 | ワークフロー / プラグイン | ユーザー エクスペリエンスに影響を与えると思われる中程度の長さのアクション。 失敗した場合にロールバックできないアクション。 失敗した場合にプラットフォームのステップのロールバックを強制するべきではないアクション。 |
非常に長い時間実行されているアクション。 これらは、Dataverse で管理するべきではありません。 コストの低いアクション。 コストの低いアクションに対して非同期な振る舞いを生成することによるオーバーヘッドは、非常に大きくなる可能性があります。可能であれば、これらを同期的に行い、非同期処理のオーバーヘッドを避けてください。 |
| N/A 呼び出された場所のコンテキストを取る |
ユーザー定義アクション | Web リソースなどの外部ソースから起動されたアクションの組み合わせ | 常にプラットフォーム イベントに応答してトリガーする場合は、プラグイン / ワークフローを使用してください。 |
プラグイン / ワークフローはバッチ処理メカニズムではない
長時間実行されるアクションや大量のアクションは、プラグインやワークフローからの実行を想定していません。 Dataverse は、計算プラットフォームとしての使用を想定したものではありません。特に、関連性のない大規模なアップデートを押し進めるコントローラーとしての使用は想定していません。
それを行う必要がある場合は、Azure ワーカー ロールなどの別のサービスからオフロードして実行します。
セキュリティ設定
一般的なエスカレーション領域は、セキュリティ設定のスケーラビリティです。 これはコストのかかる操作なので、理解なく慎重に検討せず大量に行うと、問題が発生する可能性が常にあります。
チーム セットアップ
- 常に同じ順序でユーザーを追加します。次の方法でデッドロックを回避します。
- 更新が必要な場合にのみユーザーを更新します。不必要にユーザーのキャッシュを無効にしないようにします。
所有者 v。 アクセス チーム
- ユーザーのチームが定期的に変わる場合は、所有者チームの頻繁な使用は注意してください。変更するたびに、Web サーバーのユーザー キャッシュが無効になります
- 理想としては、夜間といったようなユーザーが作業をしていないときに変更を加え、影響を軽減する
たくさんのチーム メンバーシップ / BU
- 多数のチーム / BU が複雑な計算を追加するシナリオを慎重に検討してください。
カスケード動作
- 割り当てなど、カスケード共有を検討する
ユーザー レコードの慎重な更新
- ユーザー キャッシュが強制的にリロードされ、セキュリティ特権が再計算されるため、負荷のかかる作業となるので、基本的な部分の変更がない限り、システム ユーザー レコードを定期的に更新しない
- 例えば、システム ユーザーを使用して、そのユーザーのオープン アクティビティの数を記録しない
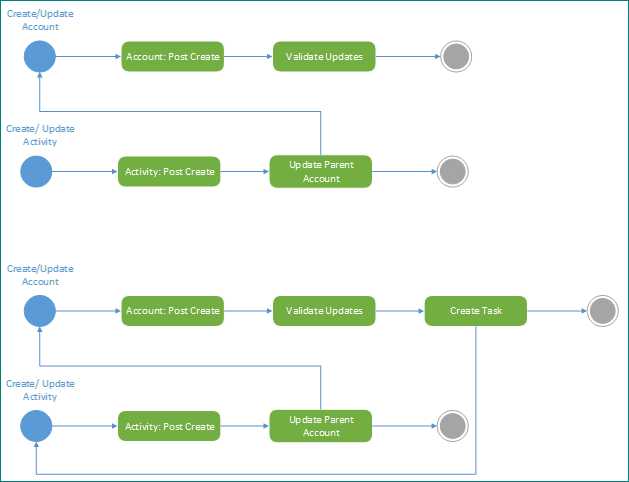
ダイアグラム関連のアクション
予防策として、またブロックの問題を診断するためのツールとして非常に有益なアクティビティは、Dataverse プラットフォームでトリガーされる関連アクションを図にすることです。 これを行うことは、システム内の意図的および意図的でない依存関係とトリガーの両方を強調するのに役立ちます。 自分のソリューションに対してこれを行うことができない場合、実装が実際のところ何をするかについての明確な像が、自分の中で描けていない可能性があります。 意図しない結果を明らかにすることができるので、実装時にそのような図を作成することをお勧めします。
次の例では、最初は 2 つのプロセスがどのように完璧に連携して動作するのかを強調していますが、継続的なメンテナンスでタスクを作成するための新しい手順を追加すると意図しないループが発生する可能性があります。 このドキュメントにある方法を使用すると、設計段階でこれが強調され、システムへ影響を与えないようにすることができます。
テレメトリとトレースを確認する
Application Insights 環境を設定して、Dataverse プラットホームで取得された診断とパフォーマンスに関するテレメトリを受信することができます。 Application Insights を使用して Dataverse テレメトリを分析する方法に関する説明
Application Insights 環境を構築したのち、Microsoft.Xrm.Sdk.PluginTelemetry.ILogger インターフェイスをプラグイン コードで使用して、テレメトリ データを直接 Application Insights に書き込むことができます。 ILogger を使用して、テレメトリを Application Insights リソースに書き込む方法に関する説明
特定のエラーが発生している場合は、サーバーのトレース ファイルを使用して、関連する問題がプラットフォーム内のどこで発生している可能性があるのか知る際にも便利です。 詳細: トレースの使用
サマリー
Dataverse でのスケーラブルなカスタマイズ設計 とそれに続く記事 データベースのトランザクション、同時実行の問題の記事、そしてこのトピックでは、次の概念と、Dataverse のスケーラブルなカスタマイズを設計および実装する方法を理解するのに役立つ例と方法を紹介しました。
覚えておくべきいくつかの重要なことは次のとおりです。
ロック / トランザクション
- ロックとトランザクションは、健全なシステムにとって不可欠です
- しかし、誤って使用すると、問題が発生する可能性があります
プラットフォームの制約
- プラットフォームの制約はしばしばエラーの形で現れます
- しかし、制約が問題の原因であることはめったにありません
- プラットフォームや他のアクティビティが影響を受けないよう、保護するために存在します
トランザクション用の設計
- 実装がトランザクションの動作を念頭に置いて設計されている場合、これにより、高いスケーラビリティとユーザー パフォーマンスの向上がもたらされます
注意
ドキュメントの言語設定についてお聞かせください。 簡単な調査を行います。 (この調査は英語です)
この調査には約 7 分かかります。 個人データは収集されません (プライバシー ステートメント)。