SharePoint での構造化およびフリーフォーム ドキュメント処理の概要
注:
従量課金制を設定している場合、2025 年 6 月まで、構造化された自由形式のドキュメント処理やその他の選択されたコンテンツ サービスを無料で試すことができます。 詳細と制限事項については、「Microsoft Syntexを試してサービスを調べる」を参照してください。
構造化ドキュメント処理モデル (レイアウトメソッド) を使用して、フィールドとテーブルの値を自動的に識別します。 フォームや請求書などの構造化ドキュメントまたは半構造化ドキュメントに最適です。
自由形式ドキュメント処理モデル (フリーフォーム選択方法) を使用して、文字やコントラクトなどの非構造化ドキュメントやフリーフォーム ドキュメントから情報を自動的に抽出します。
注:
Microsoft は、Syntex でモデルをトレーニングおよび処理するために使用するデータのプライバシーと所有権を尊重します。 お客様のorganizationのデータは、AI モデル、大言語モデル、またはその他のモデルをトレーニングするために Microsoft によって使用または転送されることはありません。 データは、organizationのテナント内に安全に保持されます。 詳細については、「 Microsoft データ保護とプライバシー」を参照してください。
構造化モデルとフリーフォーム モデルの概要
Microsoft Syntexでは、Microsoft Power Apps AI Builder ドキュメント処理を使用して、SharePoint ドキュメント ライブラリ内に構造化およびフリーフォームのドキュメント処理モデルを作成します。
AI Builder ドキュメント処理を使用すると、機械学習テクノロジを使用して、フォームや請求書などの構造化ドキュメントや半構造化ドキュメント、コントラクトや通信などの非構造化ドキュメントやフリーフォーム ドキュメントからキーと値のペアとテーブル データを識別および抽出する構造化されたドキュメント処理モデルまたはフリーフォーム ドキュメント処理モデルを作成できます。
組織は、多くの場合、メール、FAX、電子メールなど、さまざまなソースから大量の請求書を受け取ります。 これらのドキュメントを処理してデータベースに手動で入力すると、かなりの時間がかかる場合があります。 AI を使用してドキュメントからテキスト、キーと値のペア、テーブルを抽出することで、Syntex はこのプロセスを自動化します。
注:
organizationでこれらのモデルを使用する方法の詳細については、「導入の開始」と「シナリオとユース ケース」を参照してください。
たとえば、ドキュメント ライブラリにアップロードされるすべてのドキュメントを識別する構造化ドキュメント処理モデルまたはフリーフォーム ドキュメント処理モデルを作成できます。 各ドキュメントから、重要な特定のデータを抽出して表示できます。
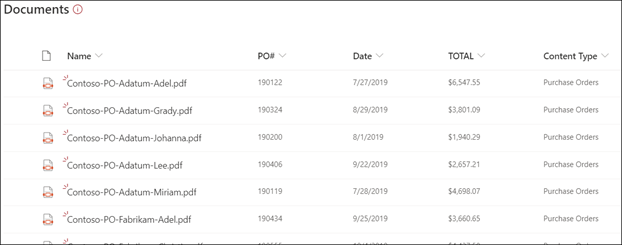
サンプルファイルを使用してモデルをトレーニングし、フォームから抽出する情報を定義します。 文書のレイアウトは、モデルをトレーニングすることで学習されます。 開始するのに必要なフォーム ドキュメントは5つだけです。 Syntex は、キーと値のペアのサンプル ファイルを分析し、検出されなかった可能性のあるファイルを手動で識別することもできます。 AI ビルダーを使用すると、サンプルファイルでモデルの精度をテストできます。
構造化または自由形式のドキュメント処理モデルは、それが有効になっている SharePoint ドキュメント ライブラリでのみ作成できます。 有効になっている場合は、ドキュメント ライブラリに [分類と抽出 ] オプションを表示できます。
ドキュメント ライブラリで有効にする必要がある場合は、Microsoft 365 管理者にお問い合わせください。
要件と制限事項
このモデルを選択するときに考慮すべき要件については、 構造化および自由形式のドキュメント処理の要件と制限事項を参照してください。