Crosstabs using RevoScaleR
Important
This content is being retired and may not be updated in the future. The support for Machine Learning Server will end on July 1, 2022. For more information, see What's happening to Machine Learning Server?
Crosstabs, also known as contingency tables or crosstabulations, are a convenient way to summarize cross-classified categorical data—that is, data that can be tabulated according to multiple levels of two or more factors. If only two factors are involved, the table is sometimes called a two-way table. If three factors are involved, the table is sometimes called a three-way table.
For large data sets, cross-tabulations of binned numeric data, that is, data that has been converted to a factor where the levels represent ranges of values, can be a fast way to get insight into the relationships among variables. In RevoScaleR, the rxCube function is the primary tool to create contingency tables.
For example, the built-in data set UCBAdmissions includes information on admissions by gender to various departments at the University of California at Berkeley. We can look at the contingency table as follows:
UCBADF <- as.data.frame(UCBAdmissions)
z <- rxCube(Freq ~ Gender:Admit, data = UCBADF)
(Because cross-tabulations are explicitly about exploring interactions between variables, multiple predictors must always be specified using the interaction operator ":", and not the terms operator "+".)
Typing z yields the following output:
Call:
rxCube(formula = Freq ~ Gender:Admit, data = UCBADF)
Cube Results for: Freq ~ Gender:Admit
Data: UCBADF
Dependent variable(s): Freq
Number of valid observations: 24
Number of missing observations: 0
Statistic: Freq means
Gender Admit Freq Counts
1 Male Admitted 199.66667 6
2 Female Admitted 92.83333 6
3 Male Rejected 248.83333 6
4 Female Rejected 213.00000 6
This data set is widely used in statistics texts because it illustrates Simpson’s paradox, which is that in some cases a comparison that holds true in a number of groups is reversed when those groups are aggregated to form a single group. From the preceding table, in which admissions data is aggregated across all departments, it would appear that males are admitted at a higher rate than women. However, if we look at the more granular analysis by department, we find that in four of the six departments, women are admitted at a higher rate than men:
z2 <- rxCube(Freq ~ Gender:Admit:Dept, data = UCBADF)
z2
This yields the following output:
Call:
rxCube(formula = Freq ~ Gender:Admit:Dept, data = UCBADF)
Cube Results for: Freq ~ Gender:Admit:Dept
Data: UCBADF
Dependent variable(s): Freq
Number of valid observations: 24
Number of missing observations: 0
Statistic: Freq means
Gender Admit Dept Freq Counts
1 Male Admitted A 512 1
2 Female Admitted A 89 1
3 Male Rejected A 313 1
4 Female Rejected A 19 1
5 Male Admitted B 353 1
6 Female Admitted B 17 1
7 Male Rejected B 207 1
8 Female Rejected B 8 1
9 Male Admitted C 120 1
10 Female Admitted C 202 1
11 Male Rejected C 205 1
12 Female Rejected C 391 1
13 Male Admitted D 138 1
14 Female Admitted D 131 1
15 Male Rejected D 279 1
16 Female Rejected D 244 1
17 Male Admitted E 53 1
18 Female Admitted E 94 1
19 Male Rejected E 138 1
20 Female Rejected E 299 1
21 Male Admitted F 22 1
22 Female Admitted F 24 1
23 Male Rejected F 351 1
24 Female Rejected F 317 1
Letting the Data Speak Example 1: Analyzing U.S. 2000 Census Data
The CensusWorkers.xdf data set contains a subset of the U.S. 2000 5% Census for individuals aged 20 to 65 who worked at least 20 weeks during the year from three states. Let’s examine the relationship between wage income (represented in the data set by the variable incwage) and age.
A useful way to observe the relationship between numeric variables is to bin the predictor variable (in our case, age), and then plot the mean of the response for each bin. The simplest way to bin age is to use the F() wrapper within our initial formula; it creates a separate bin for each distinct value of age. (More precisely, it creates a bin of length one from the low value of age to the high value of age—if some ages are missing in the original data set, bins are created for them anyway.)
We create our original model as follows:
# Letting the data speak: Example 1
readPath <- rxGetOption("sampleDataDir")
censusWorkers <- file.path(readPath, "CensusWorkers.xdf")
censusWorkersCube <- rxCube(incwage ~ F(age), data=censusWorkers)
We first look at the results in tabular form by typing the returned object name, censusWorkersCube, which yields the following output:
Call:
rxCube(formula = incwage ~ F(age), data = censusWorkers)
Cube Results for: incwage ~ F(age)
File name:
C:\Program Files\Microsoft\MRO-for-RRE\8.0\R-3.2.2\library\RevoScaleR\SampleData\CensusWorkers.xdf
Dependent variable(s): incwage
Number of valid observations: 351121
Number of missing observations: 0
Statistic: incwage means
F_age incwage Counts
1 20 12669.94 6500
2 21 14114.23 6479
3 22 15982.00 6676
4 23 18503.92 6884
5 24 20672.06 6931
6 25 23856.25 7273
7 26 25938.17 7116
8 27 26902.97 7584
9 28 28531.59 8184
10 29 30153.10 8889
11 30 30691.10 9055
12 31 31647.06 8670
13 32 33459.31 8459
14 33 34208.33 8574
15 34 34364.06 9058
16 35 35739.92 9743
17 36 36945.24 9888
18 37 36970.63 9860
19 38 37331.39 10211
20 39 38899.67 10378
21 40 38279.34 10756
22 41 39678.52 10503
23 42 40748.10 10511
24 43 39910.90 10296
25 44 40524.19 10122
26 45 41450.27 10074
27 46 40521.07 9703
28 47 41371.40 9527
29 48 42061.04 9093
30 49 41618.36 8776
31 50 42789.36 8868
32 51 41912.11 8506
33 52 43169.23 8690
34 53 41864.13 8362
35 54 42920.45 6275
36 55 42939.81 6171
37 56 41157.10 5915
38 57 40984.69 5881
39 58 40553.04 5047
40 59 38738.45 4512
41 60 37200.02 3775
42 61 35978.18 3704
43 62 35000.53 3206
44 63 34098.00 2563
45 64 32964.57 2248
46 65 31698.98 1625
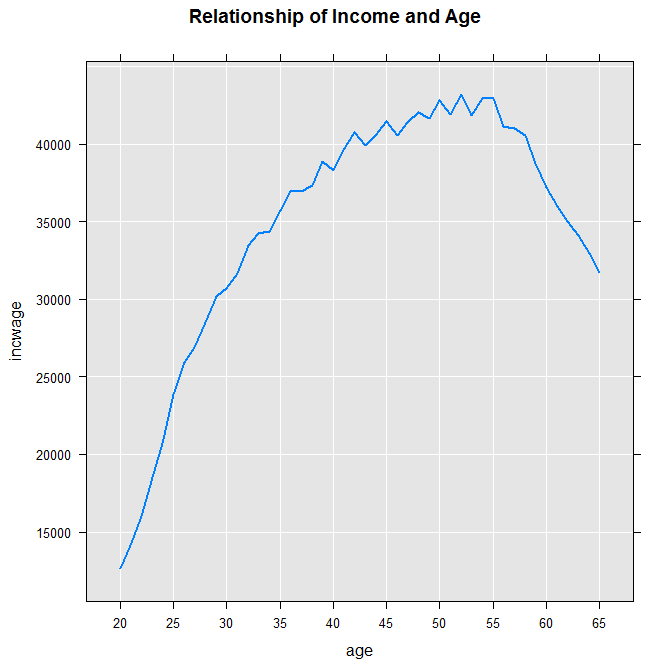
As we wanted, the table contains average values of incwage for each level of age. If we want to create a plot of the results, we can use the rxResultsDF function to conveniently convert the output into a data frame. The F_age factor variable will automatically be converted back to an integer age variable. Then we can plot the data using rxLinePlot:
censusWorkersCubeDF <- rxResultsDF(censusWorkersCube)
rxLinePlot(incwage ~ age, data=censusWorkersCubeDF,
title="Relationship of Income and Age")
The resulting plot shows clearly the relationship of income on age:
Transforming Data
Because crosstabs require categorical data for the predictors, you have to do some work to crosstabulate continuous data. In the previous section, we saw that the F() wrapper can do a transformation within a formula. The transforms argument to rxCrossTabs can be used to give you greater control over such transformations.
For example, the kyphosis data from the rpart package consists of one categorical variable, Kyphosis, and three continuous variables Age, Number, and Start. The Start variable indicates the topmost vertebra involved in a certain type of spinal surgery, and has a range of 1 to 18. Since there are 7 cervical vertebrae and 12 thoracic vertebrae, we can specify a transform that classifies the start variable as either cervical or thoracic as follows:
# Transforming Data
cut(Start, breaks=c(0, 7.5, 19.5), labels=c("cervical", "thoracic"))
Similarly, we can create a factorized Age variable as follows (in the original data, age is given in months; with our set of breaks, we cut the data into ranges of years):
cut(Age, breaks=c(0, 12, 60, 119, 180, 220), labels=c("<1", "1-4",
"5-9", "10-15", ">15"))
We can now crosstabulate the data using the preceding transforms and it is instructive to start by looking at the three two-way tables formed by tabulating Kyphosis with the three predictor variables:
library(rpart)
rxCube(~ Kyphosis:Age, data = kyphosis,
transforms=list(Age = cut(Age, breaks=c(0, 12, 60, 119,
180, 220), labels=c("<1", "1-4", "5-9", "10-15", ">15"))))
Call:
rxCube(formula = ~Kyphosis:Age, data = kyphosis, transforms = list(Age = cut(Age,
breaks = c(0, 12, 60, 119, 180, 220), labels = c("<1", "1-4",
"5-9", "10-15", ">15"))))
Cube Results for: ~Kyphosis:Age
Data: kyphosis
Number of valid observations: 81
Number of missing observations: 0
Kyphosis Age Counts
1 absent <1 13
2 present <1 0
3 absent 1-4 13
4 present 1-4 4
5 absent 5-9 17
6 present 5-9 6
7 absent 10-15 19
8 present 10-15 7
9 absent >15 2
10 present >15 0
rxCube(~ Kyphosis:F(Number), data = kyphosis)
Call:
rxCube(formula = ~Kyphosis:F(Number), data = kyphosis)
Cube Results for: ~Kyphosis:F(Number)
Data: kyphosis
Number of valid observations: 81
Number of missing observations: 0
Kyphosis F_Number Counts
1 absent 2 12
2 present 2 0
3 absent 3 19
4 present 3 4
5 absent 4 16
6 present 4 2
7 absent 5 12
8 present 5 5
9 absent 6 2
10 present 6 2
11 absent 7 2
12 present 7 3
13 absent 8 0
14 present 8 0
15 absent 9 1
16 present 9 0
17 absent 10 0
18 present 10 1
rxCube(~ Kyphosis:Start, data = kyphosis,
transforms=list(Start = cut(Start, breaks=c(0, 7.5, 19.5),
labels=c("cervical", "thoracic"))))
Call:
rxCube(formula = ~Kyphosis:Start, data = kyphosis, transforms = list(Start = cut(Start,
breaks = c(0, 7.5, 19.5), labels = c("cervical", "thoracic"))))
Cube Results for: ~Kyphosis:Start
Data: kyphosis
Number of valid observations: 81
Number of missing observations: 0
Kyphosis Start Counts
1 absent cervical 8
2 present cervical 9
3 absent thoracic 56
4 present thoracic 8
From these, we see that the probability of the post-operative complication Kyphosis seems to be greater if the Start is a cervical vertebra and as more vertebrae are involved in the surgery. Similarly, it appears that the dependence on age is non-linear: it first increases with age, peaks in the range 5-9, and then decreases again.
Cross-Tabulation with rxCrossTabs
The rxCrossTabs function is an alternative to the rxCube function, which performs the same calculations, but displays its results in format similar to the standard R xtabs function. For some purposes, this format can be more informative than the matrix-like display of rxCube, and in some situations can be more compact as well.
As an example, consider again the admission data example:
# Cross-Tabulation with rxCrossTabs
z3 <- rxCrossTabs(Freq ~ Gender:Admit:Dept, data = UCBADF)
z3
Call:
rxCrossTabs(formula = Freq ~ Gender:Admit:Dept, data = UCBADF)
Cross Tabulation Results for: Freq ~ Gender:Admit:Dept
Data: UCBADF
Dependent variable(s): Freq
Number of valid observations: 24
Number of missing observations: 0
Statistic: sums
Freq, Dept = A (sums):
Admit
Gender Admitted Rejected
Male 512 313
Female 89 19
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Freq, Dept = B (sums):
Admit
Gender Admitted Rejected
Male 353 207
Female 17 8
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Freq, Dept = C (sums):
Admit
Gender Admitted Rejected
Male 120 205
Female 202 391
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Freq, Dept = D (sums):
Admit
Gender Admitted Rejected
Male 138 279
Female 131 244
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Freq, Dept = E (sums):
Admit
Gender Admitted Rejected
Male 53 138
Female 94 299
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Freq, Dept = F (sums):
Admit
Gender Admitted Rejected
Male 22 351
Female 24 317
You can see the row, column, and total percentages by calling the summary function on the rxCrossTabs object:
summary(z3)
Call:
rxCrossTabs(formula = Freq ~ Gender:Admit:Dept, data = UCBADF)
Cross Tabulation Results for: Freq ~ Gender:Admit:Dept
Data: UCBADF
Dependent variable(s): Freq
Number of valid observations: 24
Number of missing observations: 0
Statistic: sums
Freq, Dept = A (sums):
Admitted Rejected Row Total
Male 512.000000 313.000000 825.00000
Row% 62.060606 37.939394
Col% 85.191348 94.277108
Tot% 54.876742 33.547696 88.42444
Female 89.000000 19.000000 108.00000
Row% 82.407407 17.592593
Col% 14.808652 5.722892
Tot% 9.539121 2.036442 11.57556
Col Total 601.000000 332.000000
Grand Total 933.000000
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Freq, Dept = B (sums):
Admitted Rejected Row Total
Male 353.000000 207.000000 560.000000
Row% 63.035714 36.964286
Col% 95.405405 96.279070
Tot% 60.341880 35.384615 95.726496
Female 17.000000 8.000000 25.000000
Row% 68.000000 32.000000
Col% 4.594595 3.720930
Tot% 2.905983 1.367521 4.273504
Col Total 370.000000 215.000000
Grand Total 585.000000
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Freq, Dept = C (sums):
Admitted Rejected Row Total
Male 120.00000 205.00000 325.00000
Row% 36.92308 63.07692
Col% 37.26708 34.39597
Tot% 13.07190 22.33115 35.40305
Female 202.00000 391.00000 593.00000
Row% 34.06408 65.93592
Col% 62.73292 65.60403
Tot% 22.00436 42.59259 64.59695
Col Total 322.00000 596.00000
Grand Total 918.00000
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Freq, Dept = D (sums):
Admitted Rejected Row Total
Male 138.00000 279.00000 417.00000
Row% 33.09353 66.90647
Col% 51.30112 53.34608
Tot% 17.42424 35.22727 52.65152
Female 131.00000 244.00000 375.00000
Row% 34.93333 65.06667
Col% 48.69888 46.65392
Tot% 16.54040 30.80808 47.34848
Col Total 269.00000 523.00000
Grand Total 792.00000
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Freq, Dept = E (sums):
Admitted Rejected Row Total
Male 53.000000 138.00000 191.00000
Row% 27.748691 72.25131
Col% 36.054422 31.57895
Tot% 9.075342 23.63014 32.70548
Female 94.000000 299.00000 393.00000
Row% 23.918575 76.08142
Col% 63.945578 68.42105
Tot% 16.095890 51.19863 67.29452
Col Total 147.000000 437.00000
Grand Total 584.000000
::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Freq, Dept = F (sums):
Admitted Rejected Row Total
Male 22.000000 351.00000 373.0000
Row% 5.898123 94.10188
Col% 47.826087 52.54491
Tot% 3.081232 49.15966 52.2409
Female 24.000000 317.00000 341.0000
Row% 7.038123 92.96188
Col% 52.173913 47.45509
Tot% 3.361345 44.39776 47.7591
Col Total 46.000000 668.00000
Grand Total 714.000000
You can see, for example, that in Department A, 62 percent of male applicants are admitted, but 82 percent of female applicants are admitted, and in Department B, 63 percent of male applicants are admitted, while 68 percent of female applicants are admitted.
A Large Data Example
The power of rxCrossTabs is most evident when you need to tabulate a data set that won’t fit into memory. For example, in the large airline data set AirOnTime87to12.xdf, you can obtain the mean arrival delay by carrier and day of week as follows (if you have downloaded the data set, modify the first line as follows to reflect your local path):
The
blocksPerReadargument is ignored if run locally using R Client. Learn more...
# A Large Data Example
bigDataDir <- "C:/MRS/Data"
bigAirData <- file.path(bigDataDir, "AirOnTime87to12/AirOnTime87to12.xdf")
arrDelayXT <- rxCrossTabs(ArrDelay ~ UniqueCarrier:DayOfWeek,
data = bigAirData, blocksPerRead = 30)
print(arrDelayXT)
Gives the following output:
Call:
rxCrossTabs(formula = ArrDelay ~ UniqueCarrier:DayOfWeek, data = bigAirData,
blocksPerRead = 30)
Cross Tabulation Results for: ArrDelay ~ UniqueCarrier:DayOfWeek
File name: C:\MRS\Data\AirOnTime87to12\AirOnTime87to12.xdf
Dependent variable(s): ArrDelay
Number of valid observations: 145576737
Number of missing observations: 3042918
Statistic: sums
ArrDelay (sums):
DayOfWeek
UniqueCarrier Mon Tues Wed Thur Fri Sat Sun
AA 15956852 13367087 16498840 20554660 20714146 9359729 14577582
US 11797366 11688903 14065606 17379113 19541862 5865427 10264583
AS 3144578 2677858 3182356 3980209 4415144 2433581 3039129
CO 8464507 7966834 9537366 11901028 11749616 3553719 6562487
DL 18146092 15962559 19474389 24077435 24933864 10483280 16414060
EA 782103 832332 796811 1152825 1405399 638911 670924
HP 3577460 3170343 3700890 4734543 5015896 2864314 3985741
NW 7750970 7818040 9256994 11199718 10294116 3726129 6504924
PA (1) 191137 235924 225260 290844 345238 174284 229677
PI 1164688 1391526 1456173 1515403 1568266 939820 986642
PS 88144 111282 122520 133567 173422 44362 88891
TW 3356944 3459185 4060151 5027427 5267750 1669048 2377671
UA 15941096 14731587 17801128 21060697 20920843 9174567 13688577
WN 12438738 8978339 12215989 21556781 26787623 4972506 15973176
ML (1) 20735 50927 55881 75030 62855 44549 18173
KH 20744 -26425 -24265 30078 98529 33595 43026
MQ 7065052 5152746 5893882 7136735 8087443 2947023 5540099
B6 1886261 1340744 1736450 2373151 2930423 1012698 1969546
DH 795614 527649 708129 801968 986930 227907 504644
EV 5733212 3684210 4005374 5262924 5874647 1753361 4418290
FL 2666677 1694294 1810548 2928247 3068538 819827 2188420
OO 4717107 3106319 3438056 4725854 5481441 2797745 4764041
XE 4870453 3904752 4532069 5349375 5315818 1636826 3531446
TZ 228508 147963 197371 224693 275340 39722 148940
HA -72468 -92714 -66578 4840 153830 -2082 -22196
OH 2276399 1567510 1830571 2336032 2702519 922531 1659708
F9 551932 484426 566122 858027 729273 337695 526887
YV 1959906 1419073 1463954 1930992 2152270 1270104 1830749
9E 787776 579608 590038 709161 869358 304151 586378
VX 10208 37079 12956 42661 73457 2943 39987
Using Sparse Cubes
An additional tool that may be useful when using rxCube and rxCrossTabs with large data is the useSparseCube parameter. Compiling cross-tabulations of categorical data can sometimes result in a large number of cells with zero counts, yielding at its core a “sparse matrix”. In the usual case, memory is allocated for every cell in the cube, but large cubes may overwhelm memory resources. If we instead allocate space only for cells with positive counts, such operations may often proceed successfully.
As an example, let’s look at the airline data again and construct a case where the cross-tabulation yields many zero entries. As the overwhelming number of flights in the data set were not canceled, by appending the Cancelled predictor in the formula, we would expect a large number of categorical predictor combinations to have zero observations. Because the Cancelled predictor is a logical rather than a factor variable, we need to use the F(.) function to convert it.
bigDataDir <- "C:/MRS/Data"
bigAirData <- file.path(bigDataDir, "AirOnTime87to12/AirOnTime87to12.xdf")
arrDelaySparse <- rxCube(ArrDelay ~ UniqueCarrier:DayOfWeek:F(Cancelled),
data = bigAirData, blocksPerRead = 30, useSparseCube = TRUE)
print(arrDelaySparse)
This gives the following output. We get 210 rows with F_Cancelled = 0. By default, if useSparseCube=TRUE, rows with zero counts are removed from the result.
Call:
rxCube(formula = ArrDelay ~ UniqueCarrier:DayOfWeek:F(Cancelled),
data = bigAirData, useSparseCube = TRUE, blocksPerRead = 30)
Cube Results for: ArrDelay ~ UniqueCarrier:DayOfWeek:F(Cancelled)
File name: C:/data/AirOnTime87to12/AirOnTime87to12.xdf
Dependent variable(s): ArrDelay
Number of valid observations: 145576737
Number of missing observations: 3042918
Statistic: ArrDelay means
UniqueCarrier DayOfWeek F_Cancelled ArrDelay Counts
1 AA Mon 0 6.54609466 2437614
2 US Mon 0 5.20151371 2268064
3 AS Mon 0 6.37231471 493475
4 CO Mon 0 6.49381077 1303473
5 DL Mon 0 6.63422763 2735223
6 EA Mon 0 6.13500730 127482
7 HP Mon 0 6.85447467 521916
8 NW Mon 0 5.09910096 1520066
9 PA (1) Mon 0 4.24550765 45021
10 PI Mon 0 9.32556128 124892
11 PS Mon 0 7.11355016 12391
12 TW Mon 0 6.21971889 539726
13 UA Mon 0 7.51524443 2121168
14 WN Mon 0 4.11051602 3026077
15 ML (1) Mon 0 2.05724774 10079
… [rows omitted] …
201 FL Sun 0 6.91461396 316492
202 OO Sun 0 6.30954516 755053
203 XE Sun 0 7.72464706 457166
204 TZ Sun 0 5.19715263 28658
205 HA Sun 0 -0.28030915 79184
206 OH Sun 0 7.12036827 233093
207 F9 Sun 0 5.61844996 93778
208 YV Sun 0 8.35988986 218992
209 9E Sun 0 4.18506623 140112
210 VX Sun 0 5.06036446 7902
While this particular example will likely run successfully to completion even on a minimally equipped modern computer without setting the useSparseCube flag to TRUE, it illustrates how one can quickly start to see the number of zero entries accumulate in an rxCube computation. With larger data sets and a larger number of categorical variable combinations, however, this setting may allow computations of cubes that would not otherwise fit in memory.
For the rxCrossTabs function, the useSparseCube option works exactly the same internally. However, because rxCrossTabs always returns a table, it may require more memory to format its result than rxCube. If you have an extremely large contingency table, we recommend rxCube with useSparseCube=TRUE for the greatest chance of completing the computation. The useSparseCube flag may also be used with rxSummary.
Tests of Independence on Cross-Tabulated Data
One common use of contingency tables is to test whether the tabulated variables are independent. RevoScaleR includes several tests of independence, all of which expect data in the standard R xtabs format. You can get data in this format from the rxCrossTabs function by using the argument returnXtabs=TRUE:
# Tests of Independence on Cross-Tabulated Data
bigDataDir <- "C:/MRS/Data"
bigAirData <- file.path(bigDataDir, "AirOnTime87to12/AirOnTime87to12.xdf")
arrDelayXTab <- rxCrossTabs(ArrDel15~ UniqueCarrier:DayOfWeek,
data = bigAirData, blocksPerRead = 30, returnXtabs=TRUE)
The
blocksPerReadargument is ignored if run locally using R Client. Learn more...
You can then use this as input to any of the following functions:
- rxChiSquaredTest: performs Pearson’s chi-squared test of independence.
- rxFisherTest: performs Fisher’s exact test of independence.
- rxKendallCor: performs a Kendall tau test of independence. There are three flavors of test, a, b, and c; by default, the b flavor, which accounts for ties, is used.
(In fact, regular rxCrossTabs or rxCube output can be used as input to these functions, but they are converted to xtabs format first, so it is somewhat more efficient to have rxCrossTabs return the xtabs format directly.)
Here we use the arrDelayXTab data created preceding and perform a Pearson’s chi-squared test of independence on it:
rxChiSquaredTest(arrDelayXTab)
Gives the following output:
Chi-squared test of independence between UniqueCarrier and DayOfWeek
X-squared df p-value
105645.8 174 0
For large contingency tables such as this one, the chi-squared test is the tool of choice. For smaller tables, particularly those with cells with expected counts fewer than five, Fisher’s exact test is useful. On a large table, however, Fisher’s exact test may not be an option. For example, if we try it on our airline table, it returns an error:
rxFisherTest(arrDelayXTab)
Error in FUN(tbl[, , i], ...) : FEXACT error 40.
Out of workspace.
To show the Fisher test, we return to the admissions data from the beginning of the article. This time we use rxCrossTabs to return an xtabs object:
UCBADF <- as.data.frame(UCBAdmissions)
admissCTabs <- rxCrossTabs(Freq ~ Gender:Admit, data = UCBADF,
returnXtabs=TRUE)
We then call rxFisherTest on the resulting table:
rxFisherTest(admissCTabs)
Fisher's Exact Test for Count Data
estimate 1 95% CI Lower 95% CI Upper p-value
1.840856 1.621356 2.091246 4.835903e-22
HA: two.sided
H0: odds ratio = 1
The chi-squared test works equally well on this example:
rxChiSquaredTest(admissCTabs)
Chi-squared test of independence between Gender and Admit
X-squared df p-value
91.6096 1 1.055797e-21
In both cases, we are given indisputable evidence of the independence of our two predictor factors. For this example, we could have as easily used the standard R functions chisq.test and fisher.test. The RevoScaleR enhancements, however, permit rxChisSquaredTest and rxFisherTest to work on xtabs objects with multiple tables. For example, if we expand our examination of the admissions data to include the department info, we obtain a multi-way contingency table:
admissCTabs2 <- rxCrossTabs(Freq ~ Gender:Admit:Dept, data = UCBADF,
returnXtabs=TRUE)
The chi-squared and Fisher’s exact test results are shown as follows; notice that they provide a test of independence between Gender and Admit for each level of Dept:
rxChiSquaredTest(admissCTabs2)
Chi-squared test of independence between Gender and Admit
X-squared df p-value
Dept==A 16.37177373 1 5.205468e-05
Dept==B 0.08509801 1 7.705041e-01
Dept==C 0.63322380 1 4.261753e-01
Dept==D 0.22159370 1 6.378283e-01
Dept==E 0.80804765 1 3.686981e-01
Dept==F 0.21824336 1 6.403817e-01
rxFisherTest(admissCTabs2)
Fisher's Exact Test for Count Data
odds ratio 95% CI Lower 95% CI Upper p-value
Dept==A 0.3495628 0.1970420 0.5920417 1.669189e-05
Dept==B 0.8028124 0.2944986 2.0040231 6.770899e-01
Dept==C 1.1329004 0.8452173 1.5162918 3.866166e-01
Dept==D 0.9213798 0.6789572 1.2504742 5.994965e-01
Dept==E 1.2211852 0.8064776 1.8385155 3.603964e-01
Dept==F 0.8280944 0.4332888 1.5756278 5.458408e-01
HA: two.sided
H0: odds ratio = 1
Like Fisher’s exact test, the Kendall tau correlation test works best on smaller contingency tables. Here is an example of what it returns when applied to our admissions data (the results differ from run to run as the underlying algorithm relies on sampling):
rxKendallCor(admissCTabs2)
taub p-value
Dept==A -0.13596550 0.000
Dept==B -0.02082575 0.666
Dept==C 0.02865045 0.380
Dept==D -0.01939676 0.585
Dept==E 0.04140240 0.383
Dept==F -0.02319366 0.530
HA: two.sided
Odds Ratios and Risk Ratios
Another common task associated with 2 x 2 contingency tables is the calculation of odds ratios and risk ratios (also known as relative risk). The two functions rxOddsRatio and rxRiskRatio in RevoScaleR can be used to compute these quantities. The odds ratio and the risk ratio are closely related: the odds ratio computes the relative odds of an event among two or more groups, while the risk ratio computes the relative probabilities of an event. Consider again the contingency table admissCTabs:
# Odds Ratios and Risk Ratios
admissCTabs
Admit
Gender Admitted Rejected
Male 1198 1493
Female 557 1278
In this example, the odds of being admitted as a male are 1198/1493, or about 4 to 5 against. The odds of being admitted as a female are 557/1278, or about 4 to 9 against. The odds ratio is (1198/1493)/(557/1278), or 1.8 greater odds that a male will be admitted as opposed to a woman.
rxOddsRatio(admissCTabs)
data:
Z = 0.6104, p-value < 2.2e-16
alternative hypothesis: two.sided
95 percent confidence interval:
1.624377 2.086693
sample estimates:
oddsRatio
1.84108
The risk ratio, by contrast, compares the probabilities of being rejected, that is, 1493/(1198+1493) for a man versus 1278/(557+1278) for a woman. So here the risk ratio is 0.697 (the probability of a woman being rejected) divided by 0.555 (the probability of a man being rejected), or 1.255:
rxRiskRatio(admissCTabs)
data:
Z.Female = 0.2274, p-value < 2.2e-16
alternative hypothesis: two.sided
95 percent confidence interval:
1.199631 1.313560
sample estimates:
riskRatio.Female
1.255303