エクスペリエンス固有のディザスター リカバリーのガイダンス
このドキュメントでは、地域的な障害の発生時に Fabric データを復旧するための、エクスペリエンス固有のガイダンスを示します。
シナリオ例
このドキュメントの複数のガイダンス セクションで、説明と図示を目的として次のサンプル シナリオを使用します。 必要に応じて、このシナリオに戻って参照してください。
リージョン A にワークスペース W1 があり、容量は C1 であるとします。 容量 C1 のディザスター リカバリーを有効にしている場合、OneLake データはリージョン B のバックアップにレプリケートされます。リージョン A で中断が発生した場合、C1 の Fabric サービスはリージョン B にフェールオーバーされます。
このシナリオを次の図に示します。 左側のボックスは、中断したリージョンを示しています。 中央のボックスは、フェールオーバー後にデータの可用性が継続されていることを表し、右側のボックスは、顧客がサービスを完全機能状態に復元する操作を行った後の、すべての対応が済んだ状況を示しています。
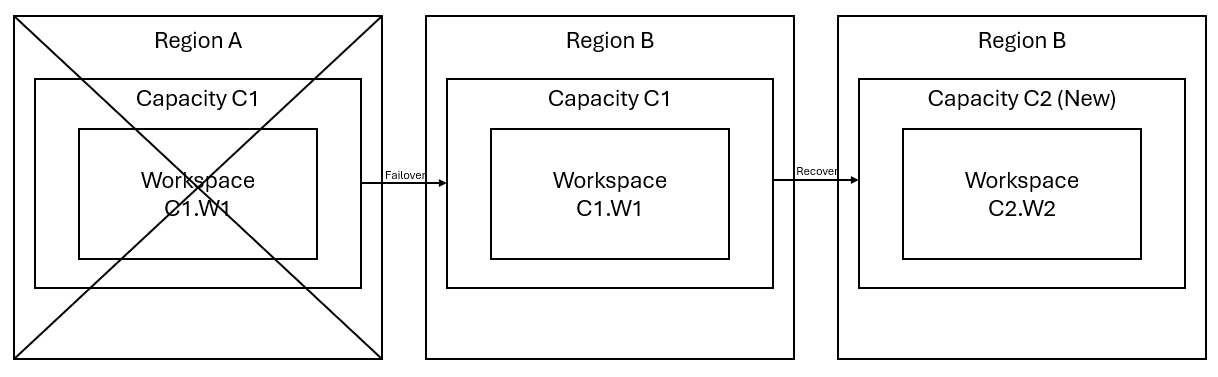
一般的な復旧計画を次に示します。
新しいリージョンに新しい Fabric 容量 C2 を作成します。
C2 に新しい W2 ワークスペースを作成し、C1.W1 のものと同じ名前を付けて、対応する項目を含めます。
中断した C1.W1 から C2.W2 にデータをコピーします。
コンポーネントごとの専用の手順に従って、項目を完全機能状態に復元します。
エクスペリエンス固有の復旧計画
次のセクションでは、顧客が復旧プロセスを進めるのに役立つ、Fabric エクスペリエンスごとのステップバイステップ ガイドを示します。
Data Engineering
このガイドでは、Data Engineering エクスペリエンスでの復旧手順について説明します。 ここでは、レイクハウス、ノートブック、Spark ジョブ定義を取り上げます。
レイクハウス
顧客が、元のリージョンのレイクハウスを使用できないままになっています。 レイクハウスを復旧するために、顧客がワークスペース C2.W2 でそれを再作成できます。 レイクハウスを復旧するためにお勧めする方法は 2 つあります。
方法 1: カスタム スクリプトを使用して、レイクハウスの Delta テーブルとファイルをコピーする
顧客は、カスタム Scala スクリプトを使用してレイクハウスを再作成できます。
新しく作成したワークスペース C2.W2 に、レイクハウス (LH1 など) を作成します。
ワークスペース C2.W2 に新しいノートブックを作成します。
元のレイクハウスのテーブルとファイルを回復するには、abfss などの OneLake パスを使ってデータを参照します (「Microsoft OneLake への接続」を参照してください)。 ノートブックの以下のコード例 (「Microsoft Spark Utilities の概要」を参照) を使用すると、元のレイクハウスのファイルとテーブルの ABFS パスを取得できます。 (C1.W1 は実際のワークスペース名に置き換えます)
mssparkutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')次のコード例を使用して、テーブルとファイルを新しく作成したレイクハウスにコピーします。
Delta テーブルの場合、テーブルを一度に 1 つずつコピーして新しいレイクハウスに復旧する必要があります。 レイクハウス ファイルの場合は、基になるすべてのフォルダーを含むファイル構造全体を 1 回の実行でコピーできます。
スクリプトに必要なフェールオーバーのタイムスタンプについては、サポート チームにお問い合わせください。
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support mssparkutils.fs.cp(source, destination, true) val filesToDelete = mssparkutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelte <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelte.name}" println(s"Deleting file $destFileToDelete") mssparkutils.fs.rm(destFileToDelete, false) } mssparkutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)スクリプトを実行すると、テーブルが新しいレイクハウスに表示されます。
方法 2: Azure Storage Explorer を使用してファイルとテーブルをコピーする
元のレイクハウスから特定のレイクハウス ファイルまたはテーブルのみを復旧するには、Azure Storage Explorer を使用します。 詳細な手順については、「OneLake と Azure Storage Explorer の統合」を参照してください。 データ サイズが大きい場合は、方法 1 を使用します。
Note
上記で説明する 2 つの方法では、Delta 形式のテーブルのメタデータとデータの両方を復旧します。メタデータは OneLake のデータと併置され、保存されているからです。 Spark データ定義言語 (DDL) のスクリプト/コマンドを使用して作成された Delta 形式以外のテーブル (CSV、Parquet など) の場合、それらを復旧するために、ユーザーが Spark DDL スクリプト/コマンドを維持して再実行する必要があります。
ノートブック
顧客がプライマリ リージョンのノートブックを使用できないままになり、ノートブック内のコードはセカンダリ リージョンにレプリケートされません。 新しいリージョンにノートブック コードを復旧する場合、ノートブック コードの内容を復旧する方法は 2 つあります。
方法 1: Git 統合を使用したユーザー管理の冗長性 (パブリック プレビュー段階)
これを簡単かつ迅速に行う最善の方法は、Fabric Git 統合を使用し、ノートブックを ADO リポジトリと同期することです。 サービスを別のリージョンにフェールオーバーした後に、リポジトリを使用して、作成した新しいワークスペースでノートブックを再構築できます。
Git 統合を設定し、ADO リポジトリに接続して同期します。
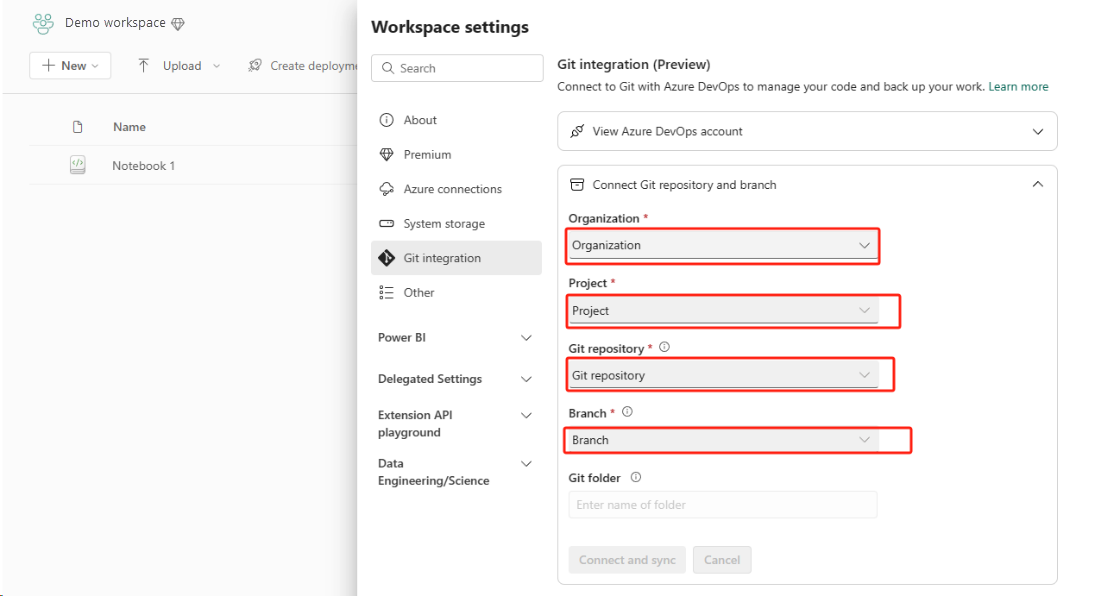
次の図は、同期されたノートブックを示しています。
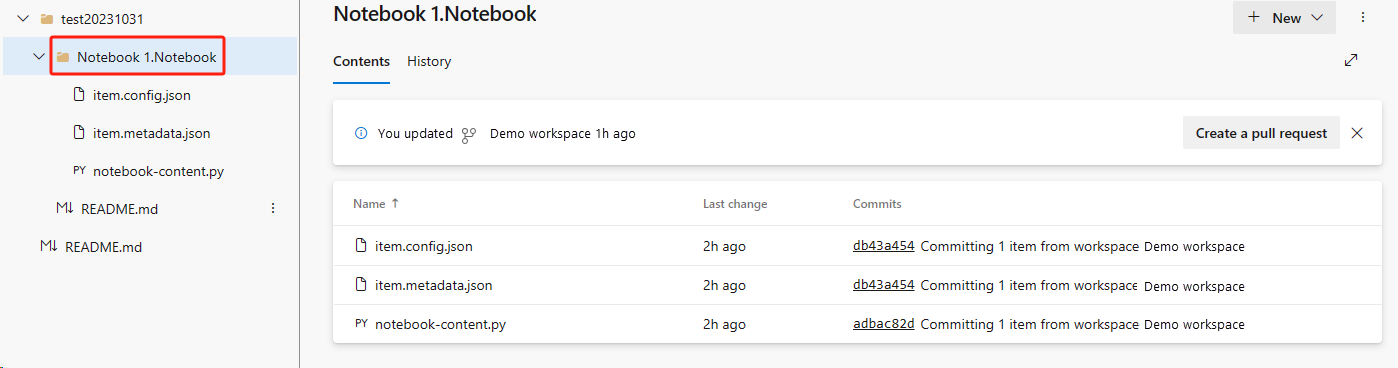
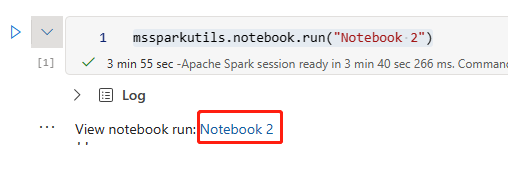
ノートブックを ADO リポジトリから復旧します。
新しく作成したワークスペースで、Azure ADO リポジトリにもう一度接続します。
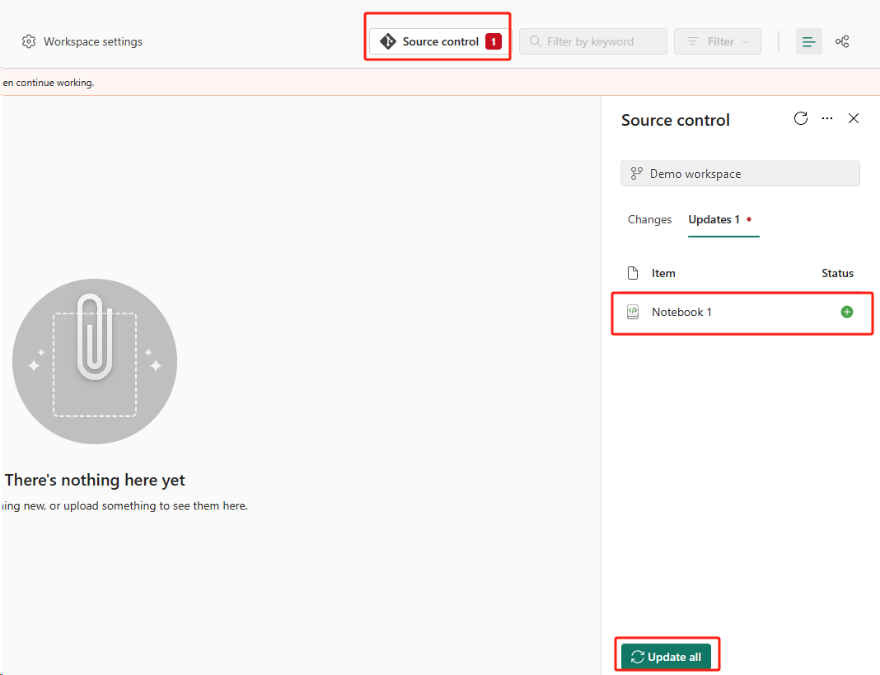
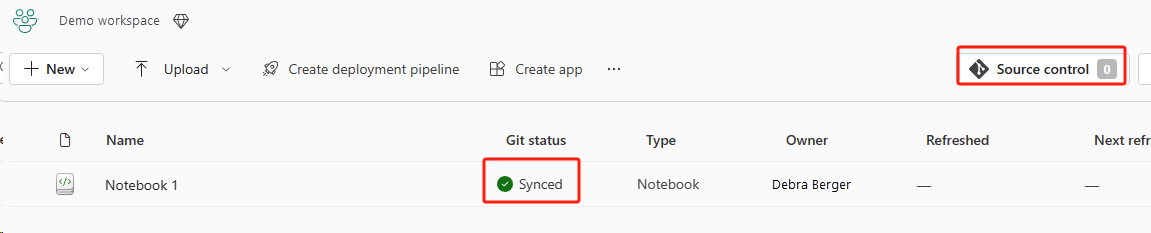
[ソース管理] ボタンを選択します。 次に、リポジトリの関連するブランチを選択します。 次に、[すべて更新] を選択します。 元のノートブックが表示されます。
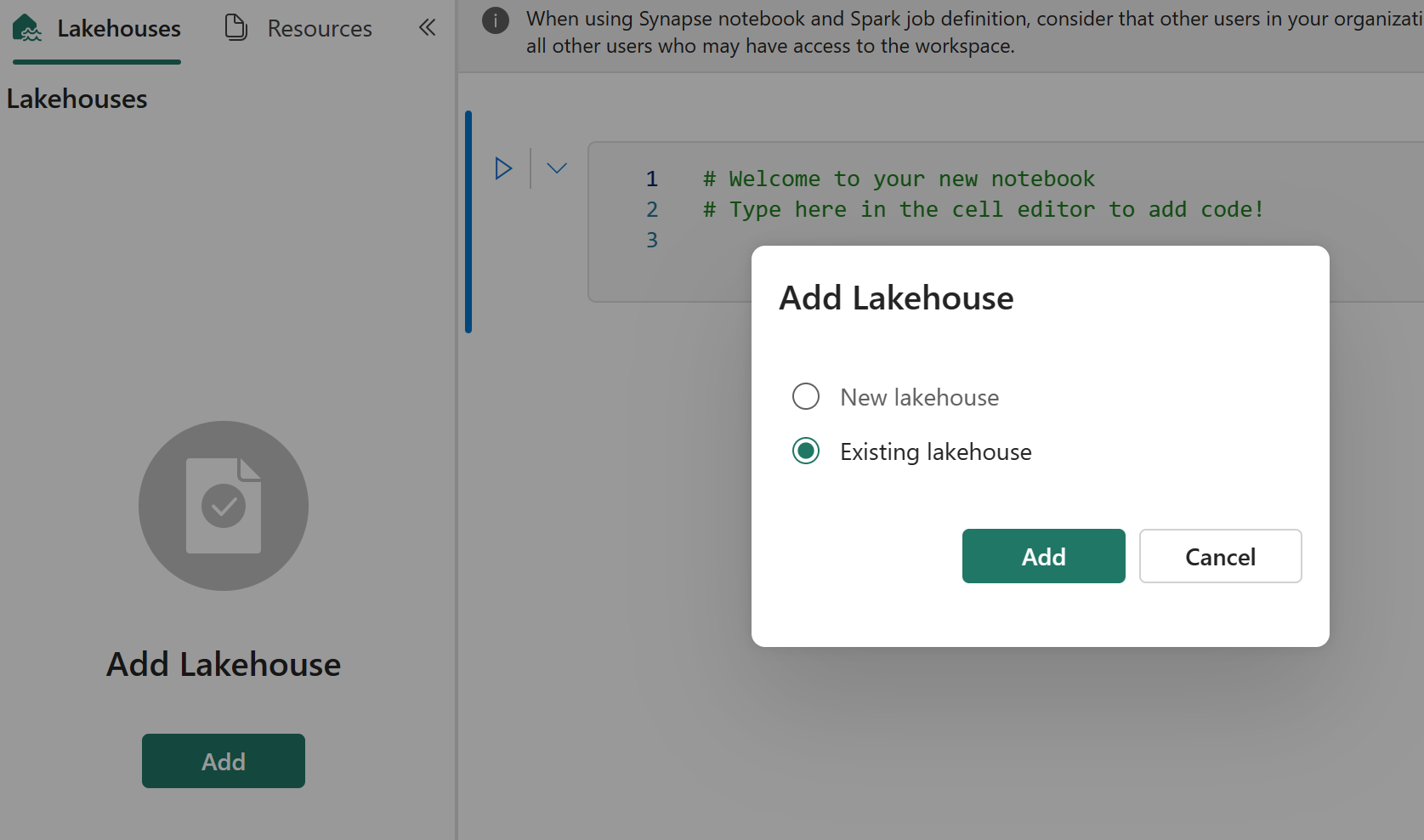
元のノートブックに既定のレイクハウスがある場合、ユーザーは、「レイクハウス」セクションを参照してレイクハウスを復旧し、新しく復旧したレイクハウスを新しく復旧したノートブックに接続できます。
Git 統合では、ノートブック リソース エクスプローラーでのファイル、フォルダー、またはノートブック スナップショットの同期をサポートしていません。
ノートブック リソース エクスプローラーで元のノートブックにファイルがある場合:
ファイルまたはフォルダーは、必ずローカル ディスクまたは他の場所に保存します。
ローカル ディスクまたはクラウド ドライブから、ファイルを、復旧したノートブックに再アップロードします。
元のノートブックにノートブック スナップショットがある場合は、ノートブック スナップショットも独自のバージョン管理システムまたはローカル ディスクに保存します。
Git 統合の詳細については、「Git 統合の概要」を参照してください。
方法 2: 手動でコードの内容をバックアップする方法
Git 統合による方法を使用しない場合は、最新バージョンのコード、リソース エクスプローラー内のファイル、Git などのバージョン管理システム内のノートブック スナップショットを保存し、障害発生後にノートブックの内容を手動で復旧できます。
[ノートブックのインポート] 機能を使用して、復旧するノートブック コードをインポートします。
インポート後、目的のワークスペース ("C2.W2" など) に進んでそこにアクセスします。
元のノートブックに既定のレイクハウスがある場合は、「レイクハウス」セクションを参照してください。 次に、新しく復旧したレイクハウス (元の既定のレイクハウスと同じ内容を含みます) を、新しく復旧したノートブックに接続します。
元のノートブックでリソース エクスプローラーにファイルまたはフォルダーがある場合は、ユーザーのバージョン管理システムに保存されているファイルまたはフォルダーを再アップロードします。
Spark ジョブ定義
顧客が、プライマリ リージョンの Spark ジョブ定義 (SJD) を使用できないままになっていて、ノートブック内のメイン定義ファイルと参照ファイルは、OneLake 経由でセカンダリ リージョンにレプリケートされます。 SJD を新しいリージョンに復旧する場合は、以下で説明する手動の手順に従うと SJD を復旧できます。 SJD の過去の実行は復旧されません。
Azure Storage Explorer を使用して元のリージョンからコードをコピーし、障害発生後にレイクハウスの参照を手動で再接続すると、SJD 項目を復旧できます。
新しい SJD 項目 (SJD1 など) を新しいワークスペース C2.W2 に作成します。設定と構成は、元の SJD 項目 (言語、環境など) と同じにします。
Azure Storage Explorer を使用して、Libs、Main、Snapshots を元の SJD 項目から新しい SJD 項目にコピーします。
コードの内容が、新しく作成した SJD に表示されます。 新しく復旧したレイクハウスの参照は、手動でジョブに追加する必要があります (レイクハウスの復旧手順を参照してください)。 ユーザーは、元のコマンド ライン引数を手動で再入力する必要があります。
これで、新しく復旧した SJD を実行またはスケジュール設定できます。
Azure Storage Explorer の詳細については、「OneLake と Azure Storage Explorer の統合」を参照してください。
データ サイエンス
このガイドでは、Data Science エクスペリエンスでの復旧手順について説明します。 ここでは、ML モデルと実験を取り上げます。
ML モデルと実験
顧客が、プライマリ リージョンの Data Science 項目を使用できないままになっていて、ML モデルと実験の内容とメタデータはセカンダリ リージョンにレプリケートされません。 これらを新しいリージョンで完全に復旧するには、コードの内容をバージョン管理システム (Git など) に保存し、障害発生後にコードの内容を手動で再実行します。
ノートブックを復旧します。 ノートブックの復旧手順を参照してください。
構成、過去に実行されたときのメトリック、メタデータは、ペアになっているリージョンにはレプリケートされません。 障害発生後に ML モデルと実験を完全に復旧するには、データ サイエンス コードの各バージョンを再実行する必要があります。
データ ウェアハウス (data warehouse)
このガイドでは、データ ウェアハウス エクスペリエンスでの復旧手順について説明します。 ここでは、ウェアハウスを取り上げます。
倉庫
顧客は、元のリージョンのウェアハウスを使用できないままになっています。 ウェアハウスを復旧するには、次の 2 つの手順を使用します。
元のウェアハウスからコピーするデータ用に、ワークスペース C2.W2 に新しい中間レイクハウスを作成します。
ウェアハウス エクスプローラーと T-SQL 機能を利用して、ウェアハウスの Delta テーブルを設定します (「Microsoft Fabric のデータ ウェアハウスのテーブル」を参照してください)。
Note
開発手法に従って、ウェアハウス コード (スキーマ、テーブル、ビュー、ストアド プロシージャ、関数定義、セキュリティ コード) を、安全な場所 (Git など) でバージョン管理し、保存しておくことをお勧めします。
レイクハウスと T-SQL コードを使用したデータ インジェスト
新しく作成したワークスペース C2.W2 で:
C2.W2 で中間レイクハウス "LH2" を作成します。
中間レイクハウスに、レイクハウスの復旧手順に従って元のウェアハウスから Delta テーブルを復旧します。
C2.W2 に新しいウェアハウス "WH2" を作成します。
ウェアハウス エクスプローラーで中間レイクハウスを接続します。
データ インポートの前にテーブル定義をどのようにデプロイするかに応じて、インポートに使用される実際の T-SQL は異なる可能性があります。 ウェアハウス テーブルをレイクハウスから復旧する場合、INSERT INTO、SELECT INTO、または CREATE TABLE AS SELECT のいずれかの方法を使用できます。 さらにこの例では、INSERT INTO フレーバーも使用します。 (以下のコードを使用する場合は、サンプルを実際のテーブルと列の名前に置き換えます)
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GO最後に、Fabric ウェアハウスを使用してアプリケーションの接続文字列を変更します。
Note
リージョンをまたがるディザスター リカバリーと完全に自動化されたビジネス継続性を必要とする顧客の場合、Fabric Warehouse の 2 つのセットアップを別々の Fabric リージョンに保持し、両方のサイトに対して定期的なデプロイとデータ インジェストを行って、コードとデータ パリティのメンテナンスを行うことをお勧めします。
ミラー データベース
お客様はプライマリ リージョンのミラー化されたデータベースを使用できないままになり、設定はセカンダリ リージョンにレプリケートされません。 リージョンの障害が発生した場合にそれを回復するには、異なるリージョンの別のワークスペースにミラー化されたデータベースを作り直す必要があります。
Data Factory
顧客が、プライマリ リージョンの Data Factory 項目を使用できないままになっていて、データ パイプラインまたは Dataflows Gen2 項目の設定と構成はセカンダリ リージョンにレプリケートされません。 リージョンの障害が発生した場合にこれらの項目を復旧するには、別のリージョンの別のワークスペースに Data Integration 項目を再作成する必要があります。 以下のセクションで詳細について説明します。
データフロー Gen2
新しいリージョンに Dataflow Gen2 項目を復旧する場合は、PQT ファイルを Git などのバージョン管理システムにエクスポートし、障害発生後に Dataflow Gen2 の内容を手動で復旧する必要があります。
Dataflow Gen2 項目から、Power Query エディターの [ホーム] タブで、[テンプレートのエクスポート] を選択します。
![Power Query エディターを示すスクリーンショット。[テンプレートのエクスポート] オプションが強調されています。](media/experience-specific-guidance/dataflow-gen2-export-template.png)
[テンプレートのエクスポート] ダイアログで、このテンプレートの名前 (必須) と説明 (省略可能) を入力します。 終了したら、OK を選択します。
障害発生後、新しいワークスペース "C2.W2" に新しい Dataflow Gen2 項目を作成します。
Power Query エディターの現在のビュー ペインで、[Power Query テンプレートからインポート] を選択します。
![[Power Query テンプレートからインポート] が強調されている現在のビューを示すスクリーンショット。](media/experience-specific-guidance/dataflow-gen2-import-from-power-query-template.png)
[開く] ダイアログで、既定のダウンロード フォルダーを参照し、前の手順で保存した .pqt ファイルを選択します。 その後、 [開く] を選択します。
その後、テンプレートが新しい Dataflow Gen2 項目にインポートされます。
データ パイプライン
地域的な障害が発生したときに、顧客がデータ パイプラインにアクセスできず、構成はペアになっているリージョンにレプリケートされません。 異なるリージョンにまたがる複数のワークスペースに重要なデータ パイプラインを構築することをお勧めします。
ジョブのコピー
地域障害が発生した場合、お客様はコピー ジョブにアクセスできません。また、構成はペアのリージョンにレプリケートされません。 複数のリージョンにまたがるワークスペースにおいて、クリティカルなコピー ジョブを構築することをお勧めします。
リアルタイム インテリジェンス
このガイドでは、リアルタイムインテリジェンス・エクスペリエンスでの復旧手順について説明します。 ここでは、KQL データベース/クエリセットとイベントストリームを取り上げます。
KQL データベース/クエリセット
KQL データベース/クエリセットのユーザーは、地域的な障害に対する予防的な保護対策を講じる必要があります。 次の方法を講じると、地域的な障害が発生した場合に、KQL データベースのクエリセット内のデータが安全でアクセス可能な状態に維持されます。
次の手順を使用すると、KQL データベースとクエリセットのための効果的なディザスター リカバリー ソリューションが確実に得られます。
独立した KQL データベースの確立: 専用ファブリック容量に対して、2 つ以上の独立した KQL データベース/クエリセットを構成します。 回復性を最大限に高めるために、これらは 2 つの異なる Azure リージョン (できれば Azure でペアになったリージョン) にまたがって設定する必要があります。
管理アクティビティのレプリケート: 1 つの KQL データベースで実行された管理アクションを、もう一方にミラー化する必要があります。 こうすると、両方のデータベースの同期が維持されます。レプリケートする主なアクティビティは次のとおりです。
テーブル: テーブル構造とスキーマ定義がデータベースで整合していることを確認します。
マッピング: 必要なマッピングをすべて複製します。 データ ソースとコピー先が正しく揃っていることを確認します。
ポリシー: 両方のデータベースのデータ保持、アクセス、およびその他の関連ポリシーが同様であることを確認します。
認証と認可の管理: レプリカごとに、必要なアクセス許可を設定します。 適切な認可レベルが確立され、セキュリティ標準を維持しながら、必要な担当者にアクセス権が付与されていることを確認します。
並列データ インジェスト: 複数のリージョンでデータの整合性と準備態勢を維持するには、取り込み時と同じデータセットを同じタイミングで各 KQL データベースに読み込みます。
Eventstream
eventstream は、コードなしのエクスペリエンスでリアルタイム イベントをキャプチャし、変換し、さまざまなコピー先 (レイクハウス、KQL データベース/クエリセットなど) にルーティングするための、Fabric プラットフォーム内の一元的な場所です。 コピー先がディザスター リカバリーに対応している限り、eventstream でデータは失われません。 そのため、顧客は、これらのコピー先システムのディザスター リカバリー機能を使用してデータの可用性を確保する必要があります。
また、顧客は複数サイトのアクティブ/アクティブ戦略の一環として、複数の Azure リージョンに同じ Eventstream ワークロードをデプロイして、geo 冗長性を実現することもできます。 複数サイトのアクティブ/アクティブ手法を使用すると、顧客はデプロイされたすべてのリージョンのワークロードにアクセスできます。 この方法は、ディザスター リカバリーに対する最も複雑でコストの高い方法ですが、ほとんどの状況で復旧時間をほぼゼロに短縮できます。 完全な geo 冗長を実現するために、顧客は以下を行うことができます
複数の異なるリージョンにデータ ソースのレプリカを作成する。
対応するリージョンに Eventstream 項目を作成する。
これらの新しい項目を同じデータ ソースに接続する。
異なるリージョンの eventstream ごとに同じ宛先を追加する。