OneLake と Azure Synapse Analytics との統合
Azure Synapse は、エンタープライズ データ ウェアハウジングとビッグ データ分析を 1 つにまとめた、無限の可能性を持つ分析サービスです。 このチュートリアルでは、Azure Synapse Analytics を使用して OneLake に接続する方法について説明します。
Apache Spark を使用して Synapse からデータを書き込む
Apache Spark を使用して、Azure Synapse Analytics から OneLake にサンプル データを書き込むには、次の手順に従います。
Synapse ワークスペースを開き、任意のパラメーターを使用して Apache Spark プールを作成します。
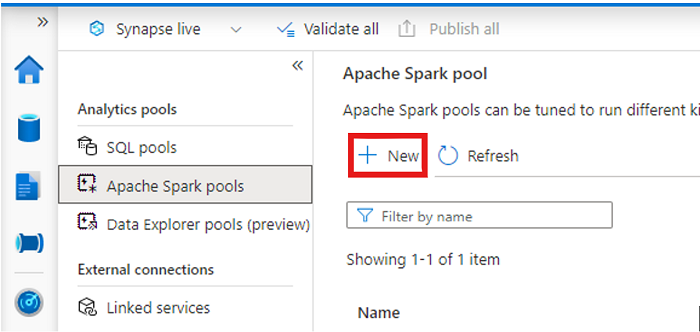
新しい Apache Spark ノートブックを作成します。
ノートブックを開き、言語を PySpark (Python) に設定し、新しく作成した Spark プールに接続します。
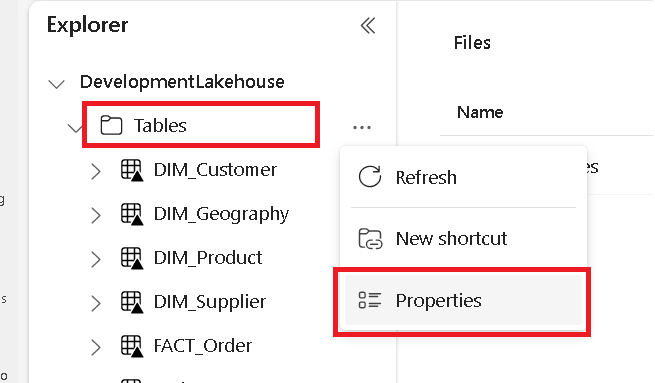
別のタブで、Microsoft Fabric レイクハウスに移動し、最上位の [テーブル] フォルダーを見つけます。
[テーブル] フォルダーを右クリックし、[プロパティ] を選択します。
プロパティ ペインから ABFS パス をコピーします。
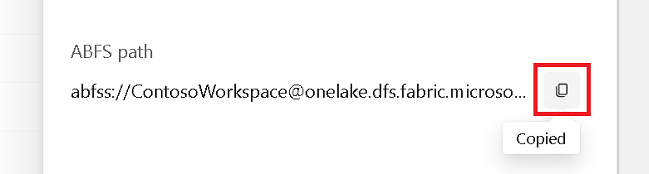
Azure Synapse ノートブックに戻り、最初の新しいコード セルで lakehouse パスを指定します。 このレイクハウスは、後でデータが書き込まれる場所です。 セルを実行します。
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'新しいコード セルで、Azure オープン データセットからデータフレームにデータを読み込みます。 このデータセットは、レイクハウスに読み込むデータセットです。 セルを実行します。
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))新しいコード セルで、データをフィルター処理、変換、または準備します。 このシナリオでは、データセットをトリミングして、読み込みを高速化したり、他のデータセットと結合したり、特定の結果にフィルター処理したりできます。 セルを実行します。
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))新しいコード セルで、OneLake パスを使用して、フィルター処理されたデータフレームを Fabric Lakehouse の新しい Delta-Parquet テーブルに書き込みます。 セルを実行します。
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')最後に、新しいコード セルで、OneLake から新しく読み込まれたファイルを読み取って、データが正常に書き込まれたことをテストします。 セルを実行します。
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
おめでとうございます。 Azure Synapse Analytics の Apache Spark を使用して、OneLake でデータの読み取りと書き込みを行えるようになりました。
SQL を使用して Synapse からデータを読み取る
SQL サーバーレスを使用して、Azure Synapse Analytics の OneLake からデータを読み取る場合は、次の手順に従います。
Fabric レイクハウスを開き、Synapse からクエリを実行するテーブルを特定します。
テーブルを右クリックし、[プロパティ] を選択します。
テーブルの ABFS パス をコピーします。
Synapse Studio で Synapse ワークスペースを開きます。
新しい SQL スクリプトを作成します。
SQL クエリ エディターで、次のクエリを入力し、
ABFS_PATH_HEREを前にコピーしたパスに置き換えます。SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;クエリを実行して、テーブルの上位 10 行を表示します。
おめでとうございます。 Azure Synapse Analytics で SQL サーバーレスを使用して OneLake からデータを読み取ることができるようになりました。