Direct Lake 用のレイクハウスを作成する
この記事では、レイクハウスを作成し、Lakehouse に Delta テーブルを作成してから、Microsoft Fabric ワークスペースで lakehouse の基本的なセマンティック モデルを作成する方法について説明します。
Direct Lake 用のレイクハウスの作成を開始する前に、Direct Lake の概要 必ずお読みください。
レイクハウスを作成する
Microsoft Fabric ワークスペースで、[新規]>[その他のオプション] を選択してから、[Data Engineering] で [レイクハウス] タイルを選択します。
![データ エンジニアリングの [Lakehouse] タイルを示すスクリーンショット。](media/direct-lake-create-lakehouse/direct-lake-lakehouse-tile.png)
[新しいレイクハウス] ダイアログ ボックスで名前を入力してから、[作成] を選択します。 名前には、英数字とアンダースコアのみを含めることができます。
![[新しいレイクハウス] ダイアログを示すスクリーンショット。](media/direct-lake-create-lakehouse/direct-lake-new-lakehouse.png)
新しいレイクハウスが作成され、正常に開かれるかどうかを確認します。
レイクハウスに Delta テーブルを作成する
新しいレイクハウスを作成した後、Direct Lake が一部のデータにアクセスできるように、少なくとも 1 つの Delta テーブルを作成する必要があります。 Direct Lake は Parquet 形式のファイルを読み取ることができますが、最適なパフォーマンスを得るために、VORDER 圧縮方法を使用してデータを圧縮することをお勧めします。 VORDER は、Power BI エンジンのネイティブ圧縮アルゴリズムを使用してデータを圧縮します。 これにより、エンジンはできるだけ早くデータをメモリに読み込むことができます。
データ パイプラインやスクリプトなど、レイクハウスにデータを読み込むには複数のオプションがあります。 次の手順では、PySpark を使用して、Azure Open Datasetに基づいて Delta テーブルを lakehouse に追加します。
新しく作成したレイクハウスで、ノートブックを開くを選択して、新しいノートブックを選択する。
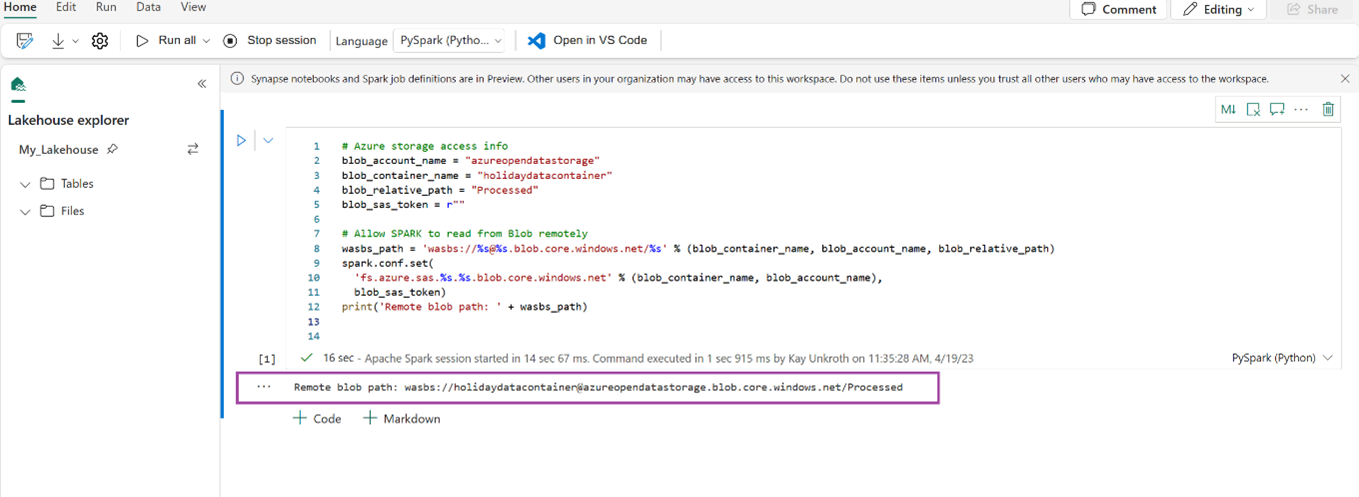
次のコード スニペットをコピーして最初のコード セルに貼り付け、SPARK が開いているモデルにアクセスできるようにしてから、Shift キー 押しながら Enter キーを押 コードを実行します。
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)コードがリモート BLOB パスを正常に出力したことを確認します。
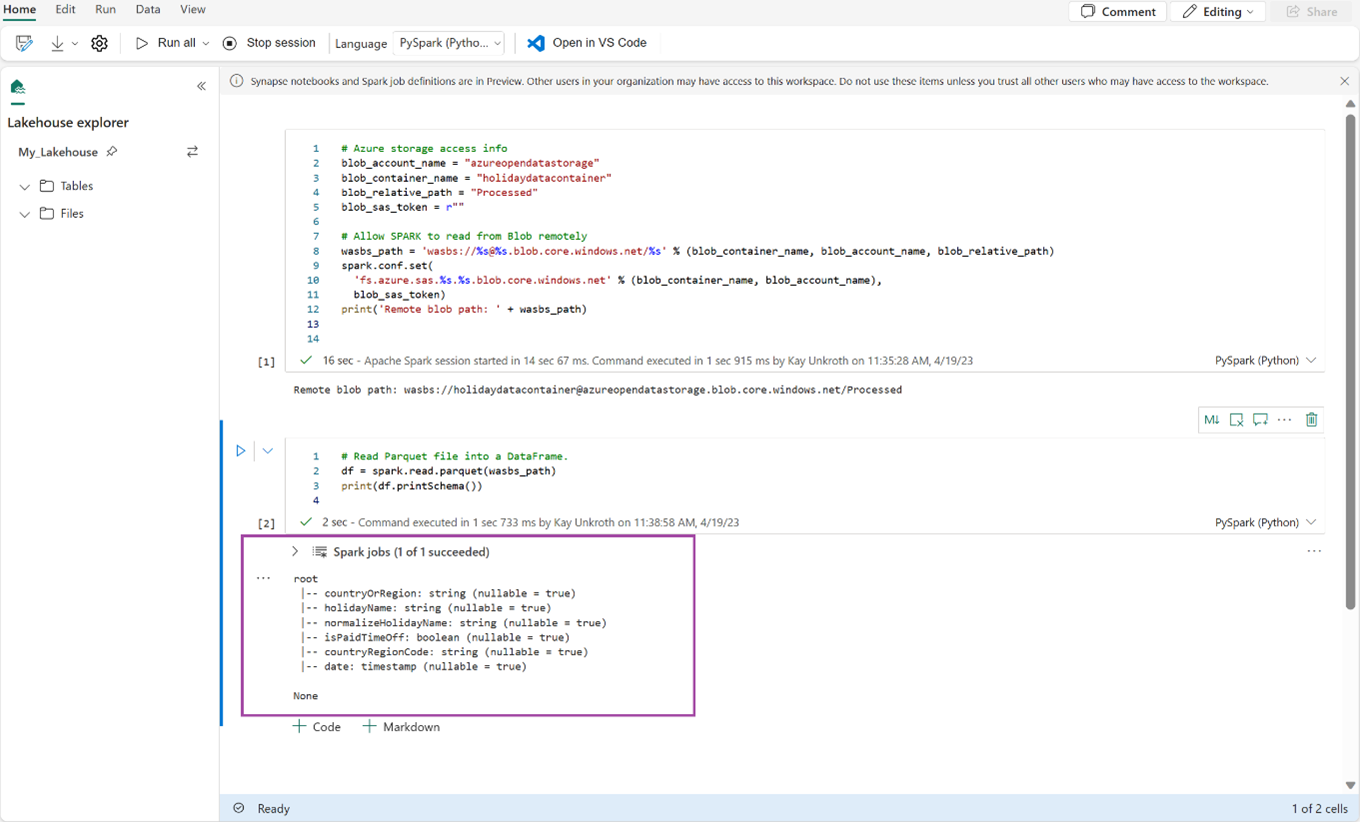
次のコードをコピーして次のセルに貼り付け、Shift キーを押しながら Enter キーを押。
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())コードが DataFrame スキーマを正常に出力したことを確認します。
次の行をコピーして次のセルに貼り付け、Shift キーを押しながら Enter キーを押。 最初の命令では VORDER 圧縮方法が有効になり、次の命令では DataFrame が Lakehouse の Delta テーブルとして保存されます。
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")すべての SPARK ジョブが正常に完了したことを確認します。 SPARK ジョブの一覧を展開して、詳細を表示します。
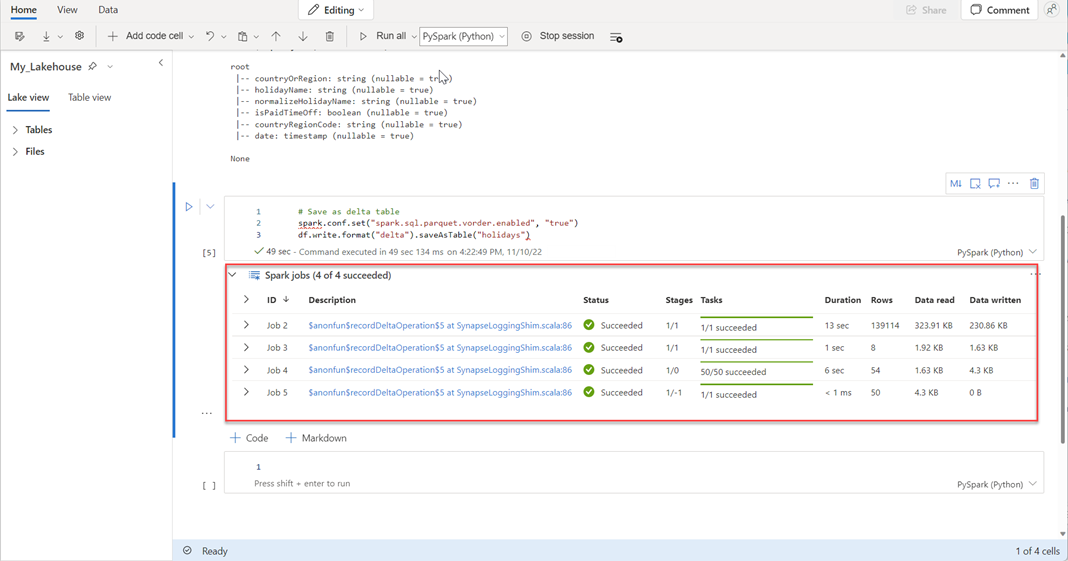
テーブルが正常に作成されたことを確認するには、左上の領域の [テーブル]の横にある省略記号 ([...]) を選択し、[の更新]選択して、テーブル ノードを展開します。
![[テーブル] ノードの近くにある [更新] コマンドを示すスクリーンショット。](media/direct-lake-create-lakehouse/direct-lake-tables-node.png)
上記と同じ方法またはサポートされている他のメソッドを使用して、分析するデータの Delta テーブルを追加します。
レイクハウス用の基本的な Direct Lake モデルを作成する
お使いのレイクハウスで「新しいセマンティックモデル 」を選択し、ダイアログで含めるテーブルを選択します。
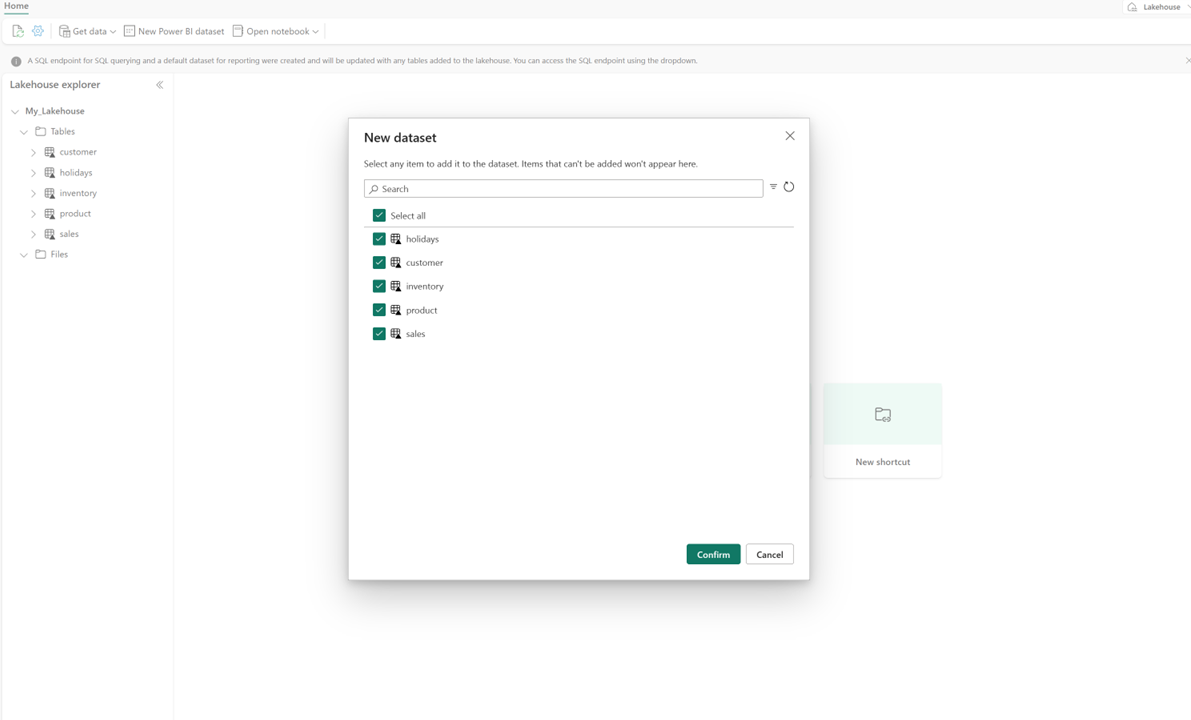
[ 確認] を選択して、Direct Lake モデルを生成します。 モデルは、レイクハウスの名前に基づいてワークスペースに自動的に保存され、その後、自動的に開かれます。
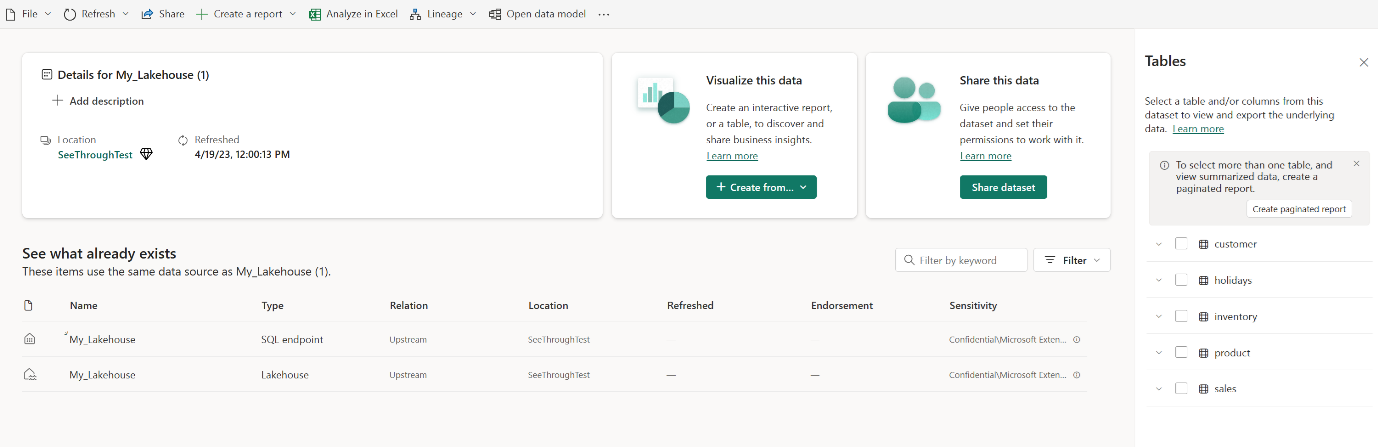
[データ モデル 開く] を選択して、テーブル リレーションシップと DAX メジャーを追加できる Web モデリング エクスペリエンスを開きます。
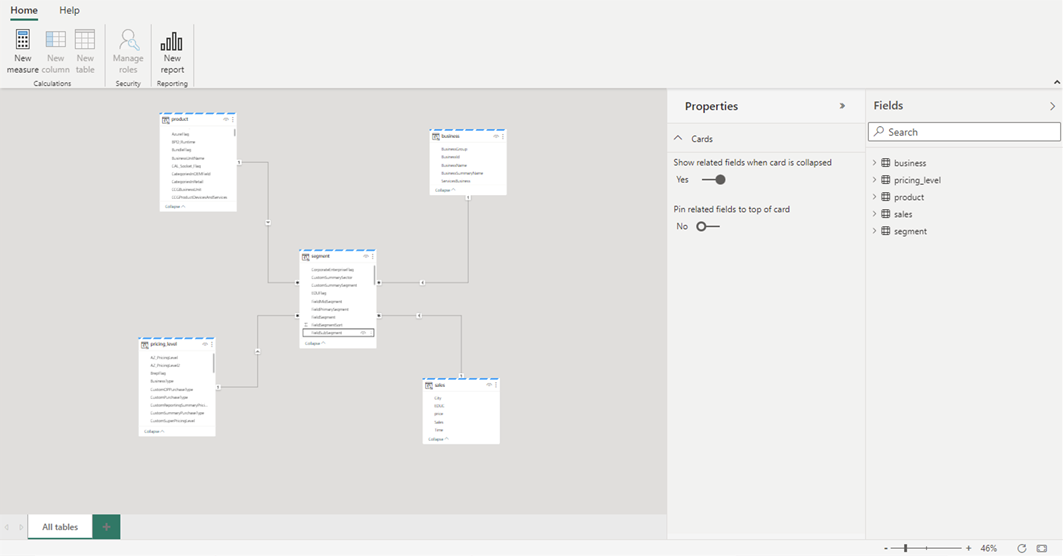
リレーションシップと DAX メジャーの追加が完了したら、他のモデルとほぼ同じ方法で、レポートの作成、複合モデルの構築、XMLA エンドポイントを使用したモデルのクエリを実行できます。