チュートリアル: 機能依存関係を使用してデータをクリーンアップする
このチュートリアルでは、データクリーニングに機能依存関係を使用します。 機能依存関係は、セマンティック モデル (Power BI データセット) の 1 つの列が別の列の関数である場合に存在します。 たとえば、郵便番号 列によって、市区町村 列の値が決まります。 関数型依存関係は、DataFrame 内の 2 つ以上の列の値間の一対多リレーションシップとして現れます。 このチュートリアルでは、Synthea データセットを使用して、機能関係がデータ品質の問題の検出にどのように役立つかを示します。
このチュートリアルでは、次の方法について説明します。
- ドメイン知識を適用して、セマンティック モデルの機能依存関係に関する仮説を作成します。
- データ品質分析の自動化に役立つセマンティック リンクの Python ライブラリ (SemPy) のコンポーネントについて理解します。 これらのコンポーネントは次のとおりです。
- FabricDataFrame - 追加のセマンティック情報で強化された pandas のような構造体。
- 関数の依存関係に関する仮説の評価を自動化し、セマンティック モデル内のリレーションシップの違反を識別する便利な関数。
前提 条件
Microsoft Fabric サブスクリプションを取得します。 または、無料のMicrosoft Fabric試用版にサインアップします。
Microsoft Fabric にサインインします。
ホーム ページの左下にあるエクスペリエンス スイッチャーを使用して、Fabric に切り替えます。
- 左側のナビゲーション ウィンドウから ワークスペース を選択して、ワークスペースを検索して選択します。 このワークスペースが現在のワークスペースになります。
ノートブックで作業を進める
このチュートリアルには、data_cleaning_functional_dependencies_tutorial.ipynb ノートブックが付属しています。
このチュートリアルの付属のノートブックを開くには、「データ サイエンス用にシステムを準備する」の手順に従って、ノートブックをワークスペースにインポート します。
このページからコードをコピーして貼り付けるほうが良い場合は、新しいノートブックを作成できます。
コードを実行する前に、必ずノートブック にラケハウス をアタッチしてください。
ノートブックを設定する
このセクションでは、必要なモジュールとデータを含むノートブック環境を設定します。
- Spark 3.4 以降では、Fabric を使用する場合、セマンティック リンクは既定のランタイムで使用でき、インストールする必要はありません。 Spark 3.3 以下を使用している場合、またはセマンティック リンクの最新バージョンに更新する場合は、次のコマンドを実行できます。
python %pip install -U semantic-link
後で必要になるモジュールの必要なインポートを実行します。
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_syntheaサンプル データをプルします。 このチュートリアルでは、合成医療記録の Synthea データセットを使用します (わかりやすくするために小さいバージョン)。
download_synthea(which='small')
データを探索する
providers.csv ファイルの内容を使用して
FabricDataFrameを初期化します。providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()自動検出された機能の依存関係のグラフをプロットして、SemPy の
find_dependencies関数でデータ品質の問題を確認します。deps = providers.find_dependencies() plot_dependency_metadata(deps)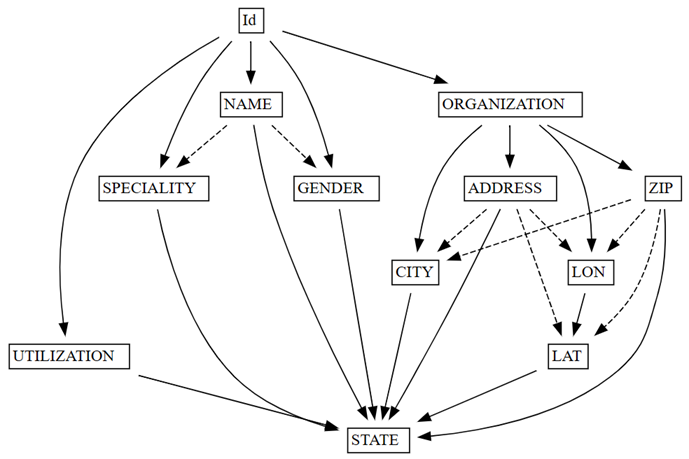
機能依存関係のグラフは、
IdがNAMEとORGANIZATION(実線の矢印で示されます) を決定することを示しています。これは、Idが一意であるためです。Idが一意であることを確認します。providers.Id.is_uniqueコードは
Trueを返して、Idが一意であることを確認します。

機能依存関係を詳細に分析する
また、機能依存関係グラフは、ORGANIZATION が ADDRESS と ZIPを想定どおりに決定することも示しています。 ただし、ZIPCITYも決定することが予想される場合がありますが、破線の矢印は、依存関係が近似であり、データ品質の問題を指していることを示します。
グラフには他にも特殊性があります。 たとえば、NAME は、GENDER、Id、SPECIALITY、または ORGANIZATIONを決定しません。 これらの特殊性のそれぞれは、調査する価値があるかもしれません.
SemPy の
list_dependency_violations関数を使用して違反の表形式の一覧を表示することで、ZIPとCITYの間のおおよその関係を詳しく見てみましょう。providers.list_dependency_violations('ZIP', 'CITY')SemPy の
plot_dependency_violations視覚化関数を使用してグラフを描画します。 このグラフは、違反の数が少ない場合に役立ちます。providers.plot_dependency_violations('ZIP', 'CITY')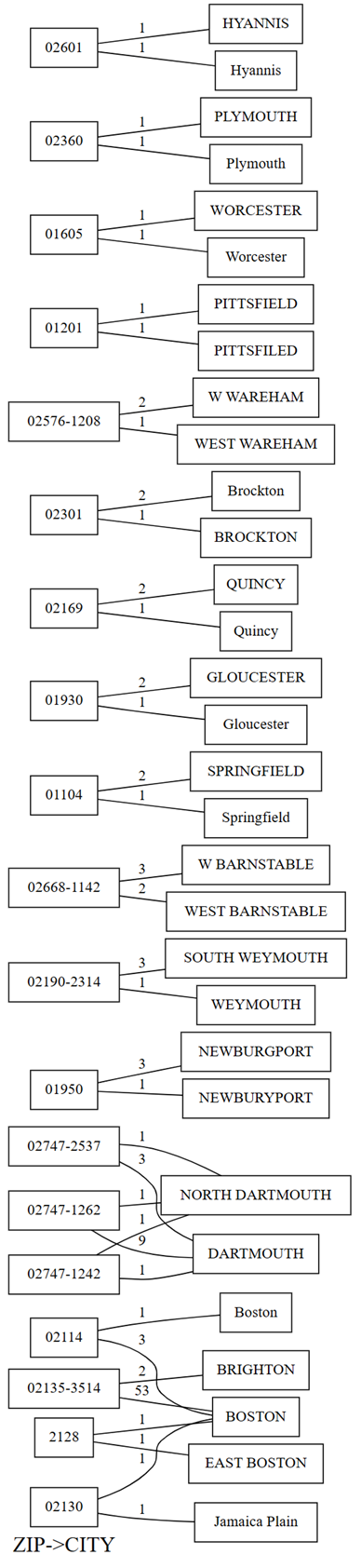
依存関係違反のプロットには、左側の
ZIPの値と、右側のCITYの値が表示されます。 この 2 つの値を含む行がある場合、エッジはプロットの左側の郵便番号を右側の市区町村に接続します。 エッジには、そのような行の数で注釈が付けられます。 たとえば、郵便番号が02747-1242の行が2行あり、1行は市"NORTH DARTHMOUTH"で、もう1行は市"DARTHMOUTH"です。それらは前のプロットと次のコードに示されています。次のコードを実行して、依存関係違反のプロットで行った前の観察を確認します。
providers[providers.ZIP == '02747-1242'].CITY.value_counts()プロットは、"DARTHMOUTH" として
CITY行のうち、9 行のZIPが 02747-1262 であることを示しています。1 行のZIPは 02747-1242 です。1 行のZIPは 02747-2537 です。 次のコードを使用して、これらの観察を確認します。providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()"DARTMOUTH" には他にも郵便番号が関連付けられていますが、これらの郵便番号は、データ品質の問題を示唆していないため、依存関係違反のグラフには表示されません。 たとえば、郵便番号 "02747-4302" は "DARTMOUTH" に一意に関連付けられているため、依存関係違反のグラフには表示されません。 次のコードを実行して確認します。
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
SemPy で検出されたデータ品質の問題を要約する
依存関係違反のグラフに戻ると、このセマンティック モデルには、いくつかの興味深いデータ品質の問題が存在することがわかります。
- 一部の都市名はすべて大文字です。 この問題は、文字列メソッドを使用して簡単に修正できます。
- 一部の都市名には、"North" や "East" などの修飾子 (またはプレフィックス) があります。 たとえば、郵便番号 "2128" は "EAST BOSTON" に 1 回、"BOSTON" に 1 回マップされます。 "NORTH DARTHMOUTH" と "DARTHMOUTH" の間でも同様の問題が発生します。 これらの修飾子を削除したり、最も一般的に発生する郵便番号を市区町村にマップしたりすることができます。
- 一部の都市では、"PITTSFIELD" や "PITTSFILED" や "NEWBURGPORT vs. "NEWBURYPORT" など、入力ミスがあります。 "NEWBURGPORT" の場合、このタイプミスは最も一般的な状況を使用して修正できます。 "PITTSFIELD" の場合、それぞれが 1 回だけ発生すると、外部の知識や言語モデルの使用なしでの自動あいまいさの解消がはるかに困難になります。
- "West" のようなプレフィックスが 1 文字の "W" に省略される場合があります。 この問題は、"W" のすべての出現が "West" を意味する場合、単純な置換で解決できる可能性があります。
- 郵便番号 "02130" は "BOSTON" に 1 回、"ジャマイカ プレーン" に 1 回マップされます。 この問題は簡単に解決できませんが、データが多い場合は、最も一般的な問題へのマッピングが潜在的な解決策になる可能性があります。
データをクリーンアップする
すべてが大文字化されているのをタイトル ケース (先頭文字を大文字) に変更して、大文字の問題を修正します。
providers['CITY'] = providers.CITY.str.title()違反検出をもう一度実行して、あいまいさの一部が失われる (違反の数が少ない) ことを確認します。
providers.list_dependency_violations('ZIP', 'CITY')この時点で、データをより手動で絞り込むことができますが、1 つの潜在的なデータ クリーンアップ タスクは、SemPy の
drop_dependency_violations関数を使用して、データ内の列間の機能上の制約に違反する行を削除することです。決定変数の値ごとに、
drop_dependency_violationsは、従属変数の最も一般的な値を選択し、他の値を持つすべての行を削除することによって機能します。 この統計ヒューリスティックがデータの正しい結果につながると確信している場合にのみ、この操作を適用する必要があります。 それ以外の場合は、必要に応じて検出された違反を処理する独自のコードを記述する必要があります。ZIP列とCITY列でdrop_dependency_violations関数を実行します。providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')ZIPとCITYの間の依存関係違反を一覧表示します。providers_clean.list_dependency_violations('ZIP', 'CITY')このコードは、機能制約 CITY -> ZIPの違反がこれ以上ないことを示すために、空のリストを返します。
関連コンテンツ
セマンティック リンク/SemPy については、他のチュートリアルを参照してください。
- チュートリアル: サンプル セマンティック モデル の機能依存関係を分析する
- チュートリアル: Jupyter ノートブックから Power BI メジャーを抽出して計算する
- チュートリアル: セマンティック リンク を使用してセマンティック モデル内のリレーションシップを検出する
- チュートリアル: セマンティック リンク を使用して、Synthea データセット内のリレーションシップを検出する
- チュートリアル: SemPy と大きな期待 (GX) を使用してデータを検証する