スーパーストア販売の予測モデルを開発、評価、スコア付けする
このチュートリアルでは、Microsoft Fabric の Synapse Data Science ワークフローのエンド ツー エンドの例を示します。 このシナリオでは、過去の売上データを使用してスーパーストアでの製品カテゴリの売上を予測する予測モデルを構築します。
予測は売上の重要な資産です。 履歴データと予測方法を組み合わせて、将来の傾向に関する分析情報を提供します。 予測では、過去の売上を分析してパターンを特定し、消費者の行動から学習して在庫、生産、マーケティング戦略を最適化できます。 このプロアクティブなアプローチにより、動的なマーケットプレースでのビジネスの適応性、応答性、および全体的なパフォーマンスが向上します。
このチュートリアルでは、次の手順について説明します。
- データを読み込む
- 探索的データ分析を使用してデータを理解して処理する
- オープンソース ソフトウェア パッケージを使用して機械学習モデルをトレーニングし、MLflow と Fabric 自動ログ機能を使用して実験を追跡する
- 最終的な機械学習モデルを保存し、予測を行う
- Power BI の視覚エフェクトを使用してモデルのパフォーマンスを表示する
前提 条件
Microsoft Fabric サブスクリプションを取得します。 Microsoft Fabric 試用版に無料で登録するか、をご利用ください。
Microsoft Fabric にサインインします。
ホーム ページの左下にあるエクスペリエンス スイッチャーを使用して、Fabric に切り替えます。
- 必要な場合には、「Microsoft Fabric でのレイクハウスの作成」の説明に従って、Microsoft Fabric レイクハウスを作成します。
ノートブックで作業を進める
ノートブック内で次のオプションから1つを選択できます。
- Synapse Data Science エクスペリエンスで組み込みのノートブックを開いて実行する
- GitHub から Synapse Data Science エクスペリエンスにノートブックをアップロードする
組み込みのノートブックを開く
サンプル セールスフォーキャスティング ノートブックは、このチュートリアルに付属しています。
このチュートリアルのサンプルノートブックを開くには、データサイエンスチュートリアルのためにシステムを準備するの手順に従ってください。
コードの実行を開始する前に、必ずレイクハウスをノートブックにアタッチしてください。
GitHub からノートブックをインポートする
このチュートリアルには、AIsample - Superstore Forecast.ipynb ノートブックが付属しています。
このチュートリアルの付属のノートブックを開くには、「データ サイエンス用にシステムを準備する」の手順に従って、ノートブックをワークスペースにインポート します。
コードをこのページからコピーして貼り付けたい場合は、新しいノートブック を作成できます。
コードの実行を開始する前に、必ずレイクハウスをノートブックにアタッチしてください。
手順 1: データを読み込む
データセットには、さまざまな製品の売上の 9,995 インスタンスが含まれています。 また、21 個の属性も含まれています。 次の表は、このノートブックで使用される Superstore.xlsx ファイルの一覧です。
| 行 ID | 注文識別子 | 注文日 | 発送日 | 発送モード | 顧客 ID | 顧客名 | セグメント | 国 | 市区町村 | 都道府県 | 郵便番号 | 地域 | 製品 ID | カテゴリ | サブカテゴリ | 製品名 | セールス | 量 | 割引 | 利潤 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | Standard クラス | SO-20335 | ショーン・オドネル | 消費者 | 米国 | フォートローダーデール | フロリダ | 33311 | 南 | FUR-TA-10000577 | 家具 | テーブル | ブレトフォードCR4500シリーズスリム長方形テーブル | 957.5775 | 5 | 0.45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Standard クラス | Standard クラス | Brosina Hoffman | 消費者 | 米国 | ロサンゼルス | カリフォルニア州 | 90032 | 西 | FUR-TA-10001539 | 家具 | テーブル | Chromcraft 長方形会議テーブル | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Standard クラス | TB-21520 | Tracy Blumstein | 消費者 | 米国 | フィラデルフィア | ペンシルベニア | 19140 | 東 | OFF-EN-10001509 | Office 用品 | 封筒 | プラスチック製ストリングタイ封筒 | 3.264 | 2 | 0.2 | 1.1016 |
さまざまなデータセットでこのノートブックを使用できるように、これらのパラメーターを定義します。
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
データセットをダウンロードして lakehouse にアップロードする
このコードは、公開されているバージョンのデータセットをダウンロードし、Fabric Lakehouse に格納します。
重要
実行する前に、必ずノートブックにレイクハウスを追加してください。 それ以外の場合は、エラーが発生します。
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
MLflow 実験の追跡を設定する
Microsoft Fabric では、トレーニング時に、機械学習モデルの入力パラメーターと出力メトリックの値が自動的にキャプチャされます。 これにより、MLflow の自動ログ機能が拡張されます。 その後、情報がワークスペースに記録され、MLflow API またはワークスペース内の対応する実験を使用してアクセスして視覚化できます。 自動ログ記録の詳細については、「Microsoft Fabric での自動ログ記録の」を参照してください。
ノートブック セッションで Microsoft Fabric の自動ログ記録を無効にするには、mlflow.autolog() を呼び出して disable=True設定します。
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
レイクハウスから生データを読み取る
レイクハウスの [ファイル] セクションから生データを読み取ります。 日付部分ごとに列を追加します。 パーティション分割されたデルタ テーブルの作成にも同じ情報が使用されます。 生データは Excel ファイルとして格納されるため、pandas を使用して読み取る必要があります。
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
手順 2: 探索的データ分析を実行する
ライブラリのインポート
分析する前に、必要なライブラリをインポートします。
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
生データを表示する
データセット自体について理解を深めるために、データのサブセットを手動で確認し、display 関数を使用して DataFrame を出力します。 さらに、Chart ビューでは、データセットのサブセットを簡単に視覚化できます。
display(df)
このノートブックは主に、Furniture カテゴリの売上予測に重点を置いています。 これにより、計算が高速化され、モデルのパフォーマンスを示すのに役立ちます。 ただし、このノートブックでは適応可能な手法を使用します。 これらの手法を拡張して、他の製品カテゴリの売上を予測できます。
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
データの前処理
実際のビジネス シナリオでは、多くの場合、次の 3 つの異なるカテゴリで売上を予測する必要があります。
- 特定の製品カテゴリ
- 特定の顧客カテゴリ
- 製品カテゴリと顧客カテゴリの特定の組み合わせ
まず、不要な列を削除してデータを前処理します。 一部の列 (Row ID、Order ID、Customer ID、および Customer Name) は、影響がないため不要です。 特定の製品カテゴリ (Furniture) について、州と地域全体の売上全体を予測し、State、Region、Country、City、および Postal Code 列を削除できるようにします。 特定の場所またはカテゴリの売上を予測するには、それに応じて前処理手順を調整することが必要になる場合があります。
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
データセットは毎日構成されます。 月単位で売上を予測するモデルを開発する必要があるため、Order Date列に再サンプリングする必要があります。
まず、Order Dateで Furniture カテゴリをグループ化します。 次に、各グループの Sales 列の合計を計算し、各一意の Order Date 値の売上合計を決定します。 MS 頻度で Sales 列を再サンプリングし、月単位でデータを集計します。 最後に、各月の平均売上値を計算します。
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
Furniture カテゴリの Sales に対する Order Date の影響を示します。
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
統計分析を行う前に、statsmodels Python モジュールをインポートする必要があります。 多くの統計モデルを推定するためのクラスと関数を提供します。 また、統計テストと統計データ探索を実行するためのクラスと関数も提供します。
import statsmodels.api as sm
統計分析を実行する
時系列では、これらのデータ要素を設定された間隔で追跡して、時系列パターン内の要素の変動を判断します。
レベル: 特定の期間の平均値を表す基本的なコンポーネント
傾向: 時系列が時間の経過と同時に減少、一定、または増加するかどうかを示します
季節性: 時系列の定期的な信号について説明し、時系列パターンの増加または減少に影響する循環的な発生を探します。
ノイズ/残差: モデルで説明できない時系列データのランダムな変動と変動を指します。
このコードでは、前処理後にデータセットのこれらの要素を観察します。
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
プロットには、予測データの季節性、傾向、およびノイズが記述されています。 基になるパターンをキャプチャし、ランダムな変動に対して回復性のある正確な予測を行うモデルを開発できます。
手順 3: モデルをトレーニングして追跡する
データが使用可能になったので、予測モデルを定義します。 このノートブックでは、外因性因子 季節的自己回帰統合移動平均 (SARIMAX) と呼ばれる予測モデルを適用します。 SARIMAX は、自動回帰 (AR) と移動平均 (MA) コンポーネント、季節差分、および外部予測子を組み合わせて、時系列データの正確で柔軟な予測を行います。
また、MLflow と Fabric の自動ログ記録を使用して実験を追跡します。 ここでは、レイクハウスからデルタ テーブルを読み込みます。 レイクハウスをソースと見なす他のデルタ テーブルを使用できます。
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
ハイパーパラメーターを調整する
SARIMAX では、通常の自己回帰統合移動平均 (ARIMA) モード (p、d、q) に関連するパラメーターが考慮され、季節性パラメーター (P、D、Q、s) が追加されます。 これらの SARIMAX モデル引数は、それぞれ 次数 (p、d、q) と、季節次数 (P、D、Q、s) と呼ばれます。 そのため、モデルをトレーニングするには、最初に 7 つのパラメーターを調整する必要があります。
注文のパラメーターは以下の通りです。
p: AR コンポーネントの順序。現在の値の予測に使用された時系列内の過去の観測値の数を表します。通常、このパラメーターは負以外の整数にする必要があります。 一般的な値は
0から3の範囲内にありますが、特定のデータ特性に応じて、より高い値が可能です。p値が大きいほど、モデル内の過去の値のメモリが長いことを示します。d: 固定性を実現するために時系列を差し替える必要がある回数を表す差分順序。このパラメーターは負以外の整数にする必要があります。 一般的な値は、
0から2までの範囲内です。0のd値は、時系列が既に固定されていることを意味します。 値が大きいほど、固定するために必要な差分操作の数を示します。q: MA コンポーネントの順序。現在の値を予測するために使用された過去のホワイト ノイズ 誤差項の数を表します。このパラメーターは負以外の整数にする必要があります。 一般的な値は
0から3までの範囲にありますが、特定の時系列にはより大きい値が必要な場合があります。q値が大きいほど、予測を行うために過去のエラー項への依存度が高いことを示します。
季節的な注文パラメーター:
P: AR コンポーネントの季節順。pに似ていますが、季節部分の場合D: 階差の季節次数。dと似ていますが、季節部分の次数ですQ: MA コンポーネントの季節順。qに似ていますが、季節部分の場合s: 季節サイクルあたりの時間ステップ数 (たとえば、年単位の季節性を持つ月次データの場合は 12)。
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX には、他のパラメーターがあります。
enforce_stationarity: SARIMAX モデルを適合させる前に、モデルが時系列データに固定性を適用する必要があるかどうか。enforce_stationarityがTrue(既定値) に設定されている場合は、SARIMAX モデルが時系列データに固定性を適用する必要があることを示します。 その後、SARIMAX モデルは、モデルを適合させる前に、データに差分を自動的に適用して、dおよびD注文で指定されたとおりに固定します。 SARIMAX を含む多くの時系列モデルでは、データが固定されていると仮定するため、これは一般的な方法です。非定常時系列 (傾向や季節性など) の場合は、
enforce_stationarityをTrueに設定し、SARIMAX モデルで差分を処理して固定性を実現することをお勧めします。 固定時系列 (傾向や季節性のない時系列など) の場合は、不要な差分を回避するためにenforce_stationarityをFalseに設定します。enforce_invertibility: 最適化プロセス中に、モデルが推定パラメーターに反転を適用するかどうかを制御します。enforce_invertibilityがTrue(既定値) に設定されている場合は、SARIMAX モデルが推定パラメーターに反転を適用する必要があることを示します。 反転性により、モデルが明確に定義され、推定 AR 係数と MA 係数が静止の範囲内に収まるようにします。反転の適用は、SARIMAX モデルが安定した時系列モデルの理論上の要件に準拠していることを保証するのに役立ちます。 また、モデルの推定と安定性に関する問題を防ぐのにも役立ちます。
既定値は AR(1) モデルです。 これは (1, 0, 0)を指します。 ただし、注文パラメーターと季節順パラメーターのさまざまな組み合わせを試し、データセットのモデル のパフォーマンスを評価するのが一般的です。 適切な値は、時系列によって異なる場合があります。
最適な値の決定には、多くの場合、時系列データの自己相関関数 (ACF) と部分自己相関関数 (PACF) の分析が含まれます。 また、多くの場合、モデルの選択基準 (例: Akaike 情報基準 (AIC) やベイジアン情報基準 (BIC)) の使用が含まれます。
ハイパーパラメーターを調整します。
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
上記の結果を評価した後、注文パラメーターと季節注文パラメーターの両方の値を決定できます。 order=(0, 1, 1) と seasonal_order=(0, 1, 1, 12)を選択すると、最も低い AIC (279.58 など) が提供されます。 これらの値を使用してモデルをトレーニングします。
モデルをトレーニングする
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
このコードは、家具の売上データの時系列予測を視覚化します。 プロットされた結果には、観測されたデータと一歩先の予測の両方が表示され、信頼区間の影付き領域が表示されます。
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
predictions を使用して、モデルのパフォーマンスを実際の値と比較して評価します。 predictions_future 値は、将来の予測を示します。
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
手順 4: モデルをスコア付けして予測を保存する
実際の値を予測値と統合して、Power BI レポートを作成します。 これらの結果をレイクハウス内のテーブルに格納します。
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
手順 5: Power BI で視覚化する
Power BI レポートには、平均絶対パーセンテージ エラー (MAPE) が 16.58 と表示されます。 MAPE メトリックは、予測方法の精度を定義します。 これは、実際の数量と比較して、予測数量の精度を表します。
MAPE は単純なメトリックです。 MAPE% 10 は、偏差が正か負かに関係なく、予測値と実際の値の平均偏差が 10%であることを表します。 望ましい MAPE 値の標準は、業界によって異なります。
このグラフの水色の線は、実際の売上値を表します。 濃い青色の線は、予測売上値を表します。 実際の売上と予測された売上の比較により、このモデルでは、2023 年の最初の 6 か月間の Furniture カテゴリの売上が効果的に予測されます。
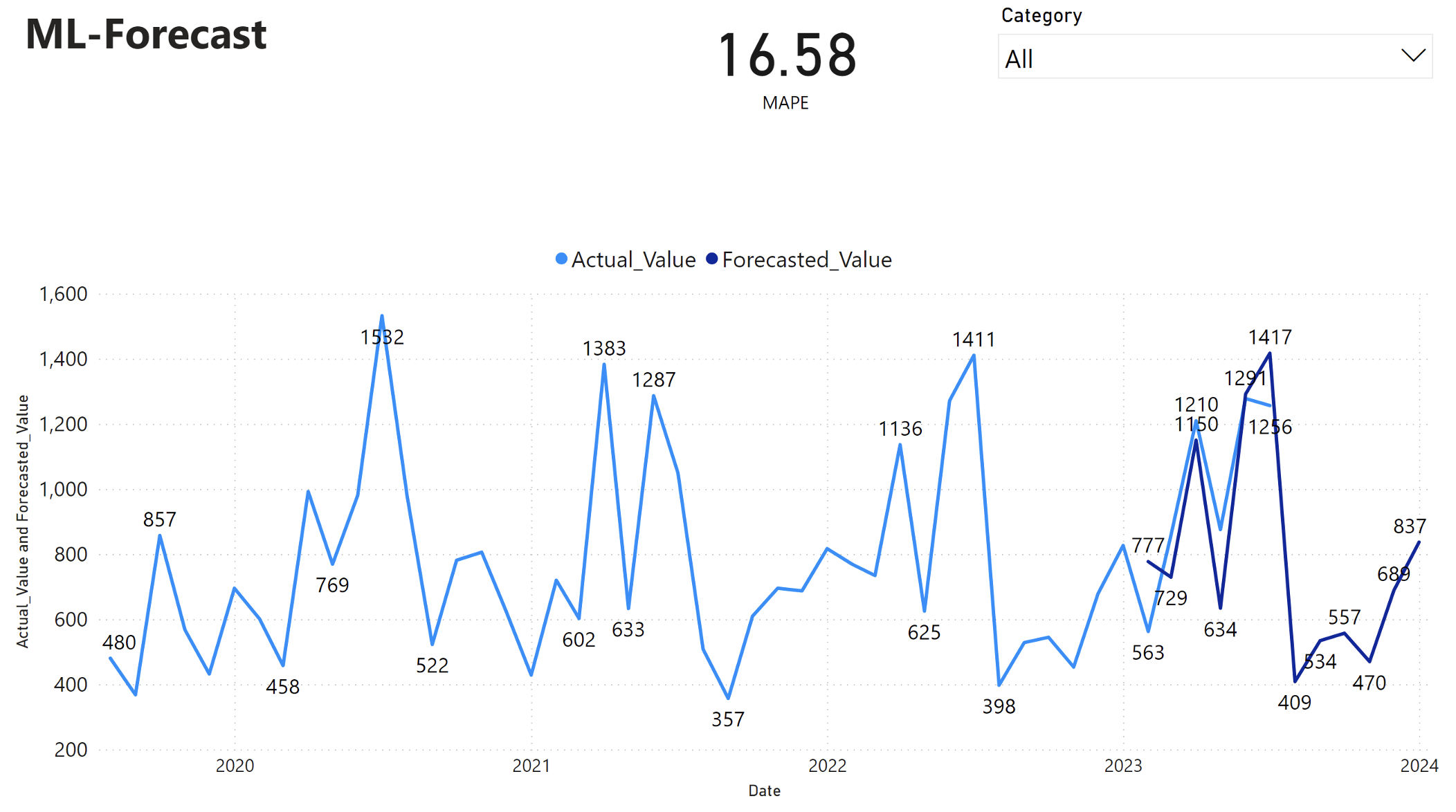
この観測に基づいて、モデルの予測能力、2023 年の過去 6 か月間の売上全体、および 2024 年まで予測能力に自信を持つことができます。 この信頼度は、在庫管理、原材料の調達、およびその他のビジネス関連の考慮事項に関する戦略的決定を通知できます。
関連コンテンツ
- Microsoft Fabric ノートブック を使用する方法
- Microsoft Fabric での機械学習モデル
- 機械学習モデルのトレーニング
- Microsoft Fabric での機械学習実験