チュートリアル: 機械故障検出モデルの作成、評価、スコア付けを行う
このチュートリアルでは、Microsoft Fabric の Synapse Data Science ワークフローのエンド ツー エンドの例について説明します。 このシナリオでは、より体系的な故障診断方法に対し機械学習を使用して、問題を事前に特定し、機械が実際に故障する前にアクションを実行します。 このゴールは、処理温度、回転速度などに基づいて、機械が故障するかどうかを予測することです。
このチュートリアルに含まれる手順は次のとおりです:
- カスタム ライブラリをインストールする
- データを読み込んで処理する
- 探索的データ分析を通じてデータを理解する
- Scikit-Learn、LightGBM、MLflow を使用して機械学習モデルをトレーニングし、Fabric 自動ログ機能を使用して実験を追跡します
- Fabric
PREDICT機能を使用してトレーニング済みのモデルにスコアを付け、最適なモデルを保存し、予測用のそのモデルを読み込みます - Power BI の視覚化を使用して読み込まれたモデルのパフォーマンスを表示します
前提条件
Microsoft Fabric サブスクリプションを取得します。 または、無料の Microsoft Fabric 試用版にサインアップします。
Microsoft Fabric にサインインします。
ホーム ページの左側にある環境スイッチャーを使って、Synapse Data Science 環境に切り替えます。
- 必要に応じて、「Microsoft Fabric でレイクハウスを作成する」の説明に 従って、Microsoft Fabric レイクハウスを作成します。
ノートブックで作業を進めます
ノートブックでこれらの後続のオプションのうちのいずれかを選択できます
- Data Science 環境のビルトイン ノートブックを開いて実行します
- GitHub から Data Science 環境にノートブックをアップロードする
ビルトインのノートブックを開きます
[機械の故障] サンプル ノートブックは、このチュートリアルに付属しています。
チュートリアルのビルトインのサンプル ノートブックを Synapse Data Science 環境で開くには:
Synapse Data Science のホーム ページに移動します。
[サンプルの使用] を選択してください。
対応するサンプルを選択してください。
- サンプルが Python チュートリアル用の場合は、既定の [エンド ツー エンド ワークフロー (Python)] タブから。
- サンプルが R チュートリアル用の場合は、[エンド ツー エンド ワークフロー (R)] タブから。
- サンプルがクイック チュートリアル用の場合は、[クイック チュートリアル] タブから。
コードの実行を開始する前に、[レイクハウスをノートブックにアタッチします]。
GitHub からノートブックをインポートします
[AISample - 予測メンテナンス] ノートブックは、このチュートリアルに付属しています。
このチュートリアルが付属するノートブックを開く場合は、「データ サイエンス チュートリアル用にシステムを準備する」内の指示に従い、ノートブックを、お使いのワークスペースにインポートします。
このページからコードをコピーして貼り付ける場合は、[新しいノートブックを作成する] ことができます。
コードの実行を開始する前に、必ずレイクハウスをノートブックにアタッチしてください。
手順 1: カスタム ライブラリをインストールする
機械学習モデルの開発またはアドホックなデータ分析には、Apache Spark セッション用のカスタム ライブラリをすばやくインストールすることが必要な場合があります。 ライブラリをインストールするには、2 つのオプションがあります。
- ノートブックのインライン インストール機能 (
%pipまたは%conda) を使って、現在のノートブックにのみライブラリをインストールします - または、Fabric 環境を作成し、パブリック ソースからライブラリをインストールするか、あるいはカスタム ライブラリをそこにアップロードすると、ワークスペース管理者はその環境をワークスペースの既定としてアタッチできます。 その後、環境内のすべてのライブラリが、ワークスペース内のすべてのノートブックと Spark ジョブ定義で使用できるようになります。 環境の詳細については、「Microsoft Fabric で環境を作成、構成、および使用する」を参照してください。
このチュートリアルでは、%pip install を使用して、ノートブックに imblearn ライブラリをインストールします。
Note
PySpark カーネルは、%pip install の実行後に再起動します。 他のセルを実行する前に必要なライブラリをインストールします。
# Use pip to install imblearn
%pip install imblearn
手順 2: データを読み込む
データセットでは、製造機械のパラメーターを時間の関数としてログに記録する作業をシミュレートします。これは、工業環境で一般的なことです。 これは、列としての特徴がある行として格納された 10,000 個のデータ ポイントで構成されます。 次のような機能があります。
1 から 10000 までの一意識別子 (UID)
製品 ID は、製品品質バリアントを示す L (低)、M (中)、または H (高) の文字と、バリアント固有のシリアル番号で構成されます。 低、中、高品質のバリアントはそれぞれ、すべての製品の 60%、30%、および 10% を占めています。
気温、ケルビン単位 (K)
処理温度、ケルビン単位
回転速度、1 分あたりの回転数 (RPM)
トルク、ニュートンメートル (Nm)
工具摩耗、分単位。 品質バリアント H、M、L では、処理で使用されるツールに 5 分、3 分、および 2 分の工具摩耗が追加されます。
特定のデータ ポイントで機械が故障したかどうかを示す機械故障ラベル。 この特定のデータ ポイントには、次の 5 つの独立した故障モードのいずれかを指定できます:
- 工具摩耗故障 (TWF): 200 分から 240 分の間に、ランダムに選択された工具摩耗時間で工具が交換されるか故障します。
- 放熱故障 (HDF): 放熱は、気温と処理温度の差が 8.6 K を下回り、工具の回転速度が 1380 rpm を下回った場合に処理の失敗を引き起こします。
- 停電故障 (PWF): トルクと回転速度の積 (rad/s 単位) は、処理に必要な電力と等しくなります。 この際の電力が 3500 W を下回っているか、9000 W を超える場合、処理は失敗します。
- 超過ストレス故障 (OSF): L 製品バリアント (中品質 12,000、高品質 13,000) の工具摩耗とトルクの積が 11,000 分 Nm を超える場合、超過ストレスが原因で処理が失敗します。
- 偶発故障 (RNF): 各処理は、その処理パラメーターに関係なく、0.1% の確率で失敗します。
Note
上記の故障モードの少なくとも 1 つに当てはまる場合、処理は失敗し、"機械故障" ラベルは 1 に設定されます。 機械学習方法では、プロセスエラーの原因となったエラー モードを特定できません。
データセットをダウンロードしてレイクハウスにアップロードする
Azure Open Datasets コンテナーに接続し、予測メンテナンス データセットを読み込みます。 このコードは、公開されているバージョンのデータセットをダウンロードし、Fabric レイクハウス に格納します:
重要
実行する前に、ノートブックにレイクハウスを追加します。 そうしないと、エラーが表示されます。 レイクハウスの追加については、「レイクハウスとノートブックを接続する」を参照してください。
# Download demo data files into the lakehouse if they don't exist
import os, requests
DATA_FOLDER = "Files/predictive_maintenance/" # Folder that contains the dataset
DATA_FILE = "predictive_maintenance.csv" # Data file name
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/MachineFaultDetection"
file_list = ["predictive_maintenance.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
データセットをレイクハウスにダウンロードしたら、Spark DataFrame として読み込むことができます:
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}raw/{DATA_FILE}")
.cache()
)
df.show(5)
次のテーブルに、データのプレビューを表示します:
| UDI | Product ID | 種類 | 気温 (Air temperature) [K] | 加工温度 (Process temperature) [K] | 回転速度 (Rotational speed) [rpm] | トルク (Torque) [Nm] | 工具摩耗 (Tool wear) [min] | 移行先 | エラーの種類 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | 故障なし |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | 故障なし |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | 故障なし |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | 故障なし |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | 故障なし |
Spark DataFrameをレイクハウス デルタ テーブルに書き込む
以降の手順で Spark 操作を容易にするために、データの書式を設定します (例えば、スペースをアンダースコアに置き換える)。
# Replace the space in the column name with an underscore to avoid an invalid character while saving
df = df.toDF(*(c.replace(' ', '_') for c in df.columns))
table_name = "predictive_maintenance_data"
df.show(5)
この表は、再フォーマットされた列名を持つデータのプレビューを示しています:
| UDI | Product_ID | Type | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | 移行先 | Failure_Type |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | 故障なし |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | 故障なし |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | 故障なし |
| 4 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | 故障なし |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40.0 | 9 | 0 | 故障なし |
# Save data with processed columns to the lakehouse
df.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
手順 3: データを前処理し、探索的データ分析を行う
Spark DataFrameを Pandas DataFrameに変換し、Pandas と互換性のある一般的なプロット ライブラリを使用します。
ヒント
大規模なデータセットの場合は、そのデータセットの一部を読み込む必要がある場合があります。
data = spark.read.format("delta").load("Tables/predictive_maintenance_data")
SEED = 1234
df = data.toPandas()
df.drop(['UDI', 'Product_ID'],axis=1,inplace=True)
# Rename the Target column to IsFail
df = df.rename(columns = {'Target': "IsFail"})
df.info()
データセットの特定の列を必要とされる浮動小数点と整数型に変換し、文字列 ('L'、'M'、'H') を数値 (0、1、2) にマップします:
# Convert temperature, rotational speed, torque, and tool wear columns to float
df['Air_temperature_[K]'] = df['Air_temperature_[K]'].astype(float)
df['Process_temperature_[K]'] = df['Process_temperature_[K]'].astype(float)
df['Rotational_speed_[rpm]'] = df['Rotational_speed_[rpm]'].astype(float)
df['Torque_[Nm]'] = df['Torque_[Nm]'].astype(float)
df['Tool_wear_[min]'] = df['Tool_wear_[min]'].astype(float)
# Convert the 'Target' column to an integer
df['IsFail'] = df['IsFail'].astype(int)
# Map 'L', 'M', 'H' to numerical values
df['Type'] = df['Type'].map({'L': 0, 'M': 1, 'H': 2})
視覚化を使用してデータを探索する
# Import packages and set plotting style
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
sns.set_style('darkgrid')
# Create the correlation matrix
corr_matrix = df.corr(numeric_only=True)
# Plot a heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True)
plt.show()
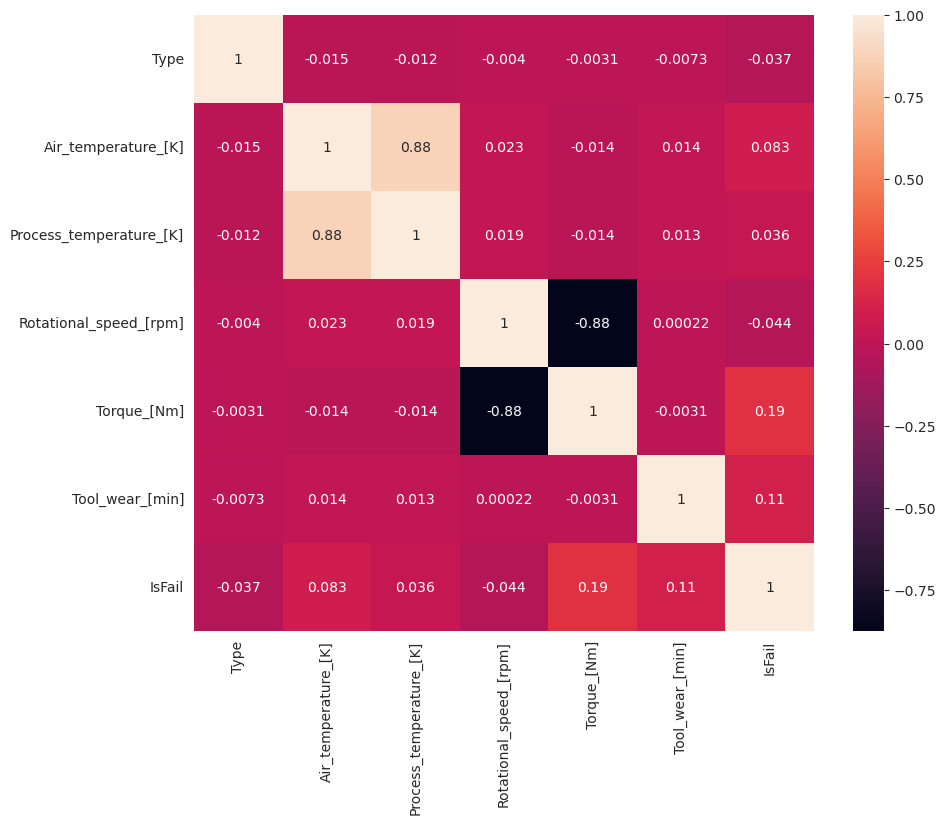
予想どおり、エラー (IsFail) には、選択された特徴量 (列) との相関関係があります。 相関行列は、Air_temperature、Process_temperatureRotational_speed、Torque、および Tool_wear に IsFail 変数との最も高い相関関係があることを示しています。
# Plot histograms of select features
fig, axes = plt.subplots(2, 3, figsize=(18,10))
columns = ['Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']
data=df.copy()
for ind, item in enumerate (columns):
column = columns[ind]
df_column = data[column]
df_column.hist(ax = axes[ind%2][ind//2], bins=32).set_title(item)
fig.supylabel('count')
fig.subplots_adjust(hspace=0.2)
fig.delaxes(axes[1,2])
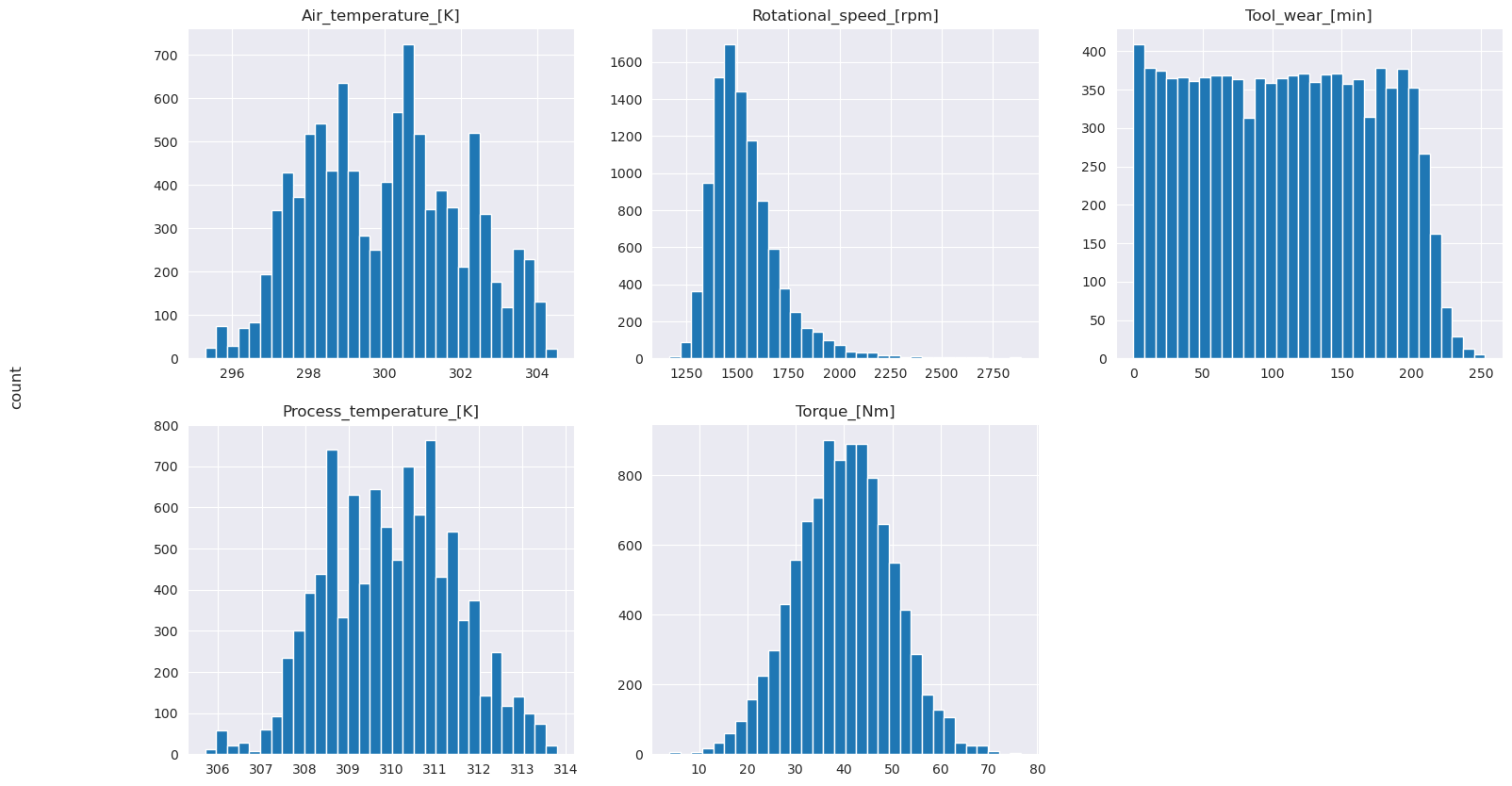
プロットされたグラフが示すように、Air_temperature、Process_temperature、Rotational_speed、Torque、および Tool_wear 変数はでまばらではありません。 特徴量空間で優れた継続性を持っているようです。 これらのプロットは、このデータセットで機械学習モデルをトレーニングすると、新しいデータセットに一般化できる信頼性の高い結果が得られる可能性が高いことを裏付けています。
ターゲット変数でクラスの不均衡を調べる
故障した機械と故障していない機械のサンプルの数をカウントし、各クラスのデータ バランスを調べます (IsFail=0、IsFail=1):
# Plot the counts for no failure and each failure type
plt.figure(figsize=(12, 2))
ax = sns.countplot(x='Failure_Type', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
# Plot the counts for no failure versus the sum of all failure types
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
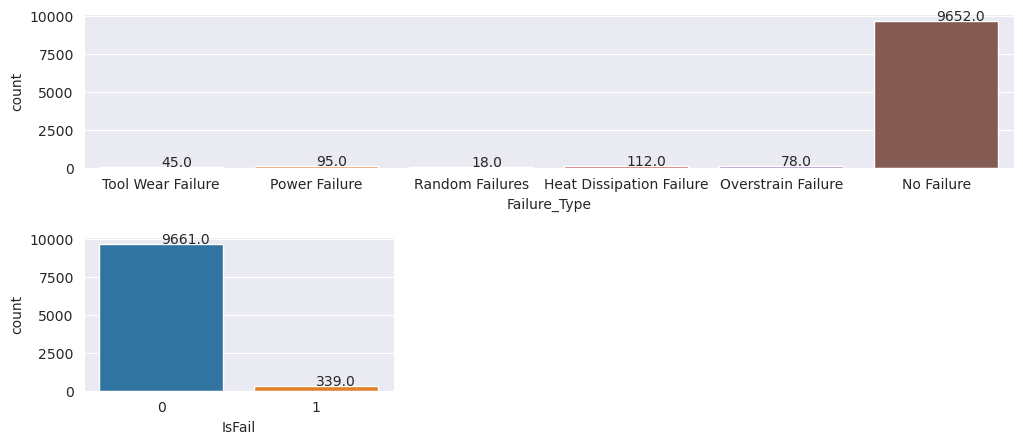
プロットは、(2 番目のプロットで IsFail=0 と示されているように) 故障なしのクラスがほとんどのサンプルを構成していることを示します。 オーバーサンプリング法を使用して、よりバランスの取れたトレーニング データセットを作成します:
# Separate features and target
features = df[['Type', 'Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']]
labels = df['IsFail']
# Split the dataset into the training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Save test data to the lakehouse for use in future sections
table_name = "predictive_maintenance_test_data"
df_test_X = spark.createDataFrame(X_test)
df_test_X.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
トレーニング データセット内のクラスのバランスを取るオーバーサンプリング
前の分析では、データセットが非常に不均衡であることが示されました。 その不均衡が問題となるのは、モデルが決定境界を効果的に学習するには、少数派クラスの例が少なすぎるためです。
SMOTE は問題を解決できます。 SMOTE は、合成例を生成する広く使われているオーバーサンプリング法です。 データポイント間のユークリッド距離に基づき、少数派クラスの例が生成されます。 このメソッドはランダムなオーバーサンプリングとは異なります。これは、少数派クラスをただ複製するのではなく、新しい例を作成するためです。 このメソッドは、不均衡なデータセットを処理するためのより効果的な手法になります。
# Disable MLflow autologging because you don't want to track SMOTE fitting
import mlflow
mlflow.autolog(disable=True)
from imblearn.combine import SMOTETomek
smt = SMOTETomek(random_state=SEED)
X_train_res, y_train_res = smt.fit_resample(X_train, y_train)
# Plot the counts for both classes
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=pd.DataFrame({'IsFail': y_train_res.values}))
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
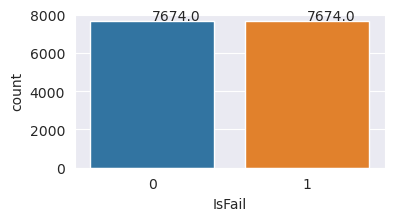
これで、データセットのバランスが正常に調整されました。 モデル トレーニングに移行できるようになりました。
手順 4: モデルをトレーニングして評価する
MLflow は、モデルの登録、さまざまなモデルのトレーニングと比較、予測目的に最適なモデルの選択をします。 モデル トレーニングでは、次の 3 つのモデルを使用できます:
- ランダム フォレスト分類子
- ロジスティック回帰分類子
- XGBoost 分類子
ランダムフォレスト分類子をトレーニングする
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from mlflow.models.signature import infer_signature
from sklearn.metrics import f1_score, accuracy_score, recall_score
mlflow.set_experiment("Machine_Failure_Classification")
mlflow.autolog(exclusive=False) # This is needed to override the preconfigured autologging behavior
with mlflow.start_run() as run:
rfc_id = run.info.run_id
print(f"run_id {rfc_id}, status: {run.info.status}")
rfc = RandomForestClassifier(max_depth=5, n_estimators=50)
rfc.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
rfc,
"machine_failure_model_rf",
signature=signature,
registered_model_name="machine_failure_model_rf"
)
y_pred_train = rfc.predict(X_train)
# Calculate the classification metrics for test data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = rfc.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
# Print the classification metrics
print("F1 score_test:", f1_test)
print("Accuracy_test:", accuracy_test)
print("Recall_test:", recall_test)
出力からは、トレーニングとテスト データセットの両方で、ランダム フォレスト分類子を使用して、F1 スコア、精度、および約 0.9 の再現率が得られます。
ロジスティック回帰分類子をトレーニングする
from sklearn.linear_model import LogisticRegression
with mlflow.start_run() as run:
lr_id = run.info.run_id
print(f"run_id {lr_id}, status: {run.info.status}")
lr = LogisticRegression(random_state=42)
lr.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
lr,
"machine_failure_model_lr",
signature=signature,
registered_model_name="machine_failure_model_lr"
)
y_pred_train = lr.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = lr.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
XGBoost 分類子をトレーニングする
from xgboost import XGBClassifier
with mlflow.start_run() as run:
xgb = XGBClassifier()
xgb_id = run.info.run_id
print(f"run_id {xgb_id}, status: {run.info.status}")
xgb.fit(X_train_res.to_numpy(), y_train_res.to_numpy())
signature = infer_signature(X_train_res, y_train_res)
mlflow.xgboost.log_model(
xgb,
"machine_failure_model_xgb",
signature=signature,
registered_model_name="machine_failure_model_xgb"
)
y_pred_train = xgb.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = xgb.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
手順 5: 最適モデルを選択し、出力を予測する
前のセクションでは、ランダム フォレスト、ロジスティック回帰、XGBoost の 3 つの異なる分類子をトレーニングしました。 プログラムで結果にアクセスするか、ユーザー インターフェイス (UI) を使用するかを選択できるようになりました。
UI パス オプションでは、ワークスペースに移動し、モデルをフィルター処理します。
モデルのパフォーマンスの詳細には、個々のモデルを選択します。
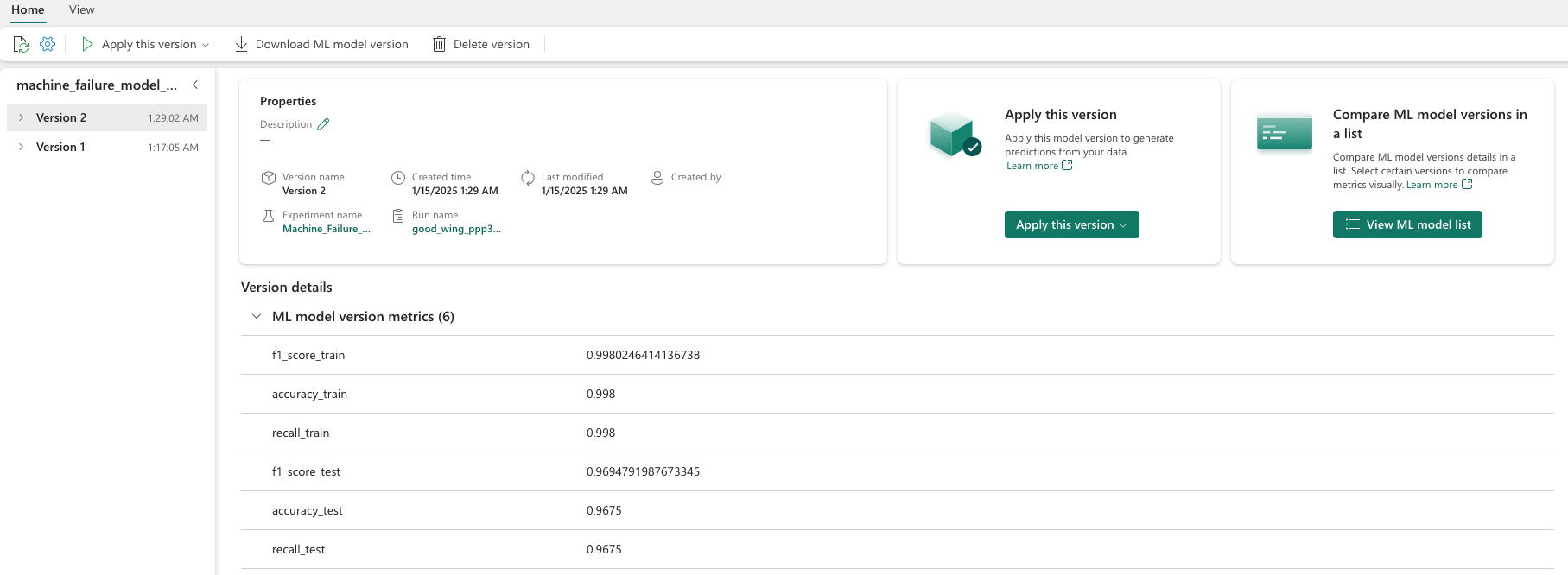
この例は、MLflow を使用してモデルにプログラムでアクセスする方法を示しています。
runs = {'random forest classifier': rfc_id,
'logistic regression classifier': lr_id,
'xgboost classifier': xgb_id}
# Create an empty DataFrame to hold the metrics
df_metrics = pd.DataFrame()
# Loop through the run IDs and retrieve the metrics for each run
for run_name, run_id in runs.items():
metrics = mlflow.get_run(run_id).data.metrics
metrics["run_name"] = run_name
df_metrics = df_metrics.append(metrics, ignore_index=True)
# Print the DataFrame
print(df_metrics)
XGBoost ではトレーニング セットで最適な結果が得られましたが、テスト データ セットではパフォーマンスが低下します。 そのパフォーマンスの低下は、オーバーフィットを示しています。 ロジスティック回帰分類子では、トレーニング データセットとテスト データセットの両方でパフォーマンスが低下します。 概して、ランダム フォレストでは、トレーニング パフォーマンスとオーバーフィットの回避のバランスを取ります。
次のセクションでは、登録済みのランダム フォレスト モデルを選び、PREDICT 機能を使用して予測を行います:
from synapse.ml.predict import MLFlowTransformer
model = MLFlowTransformer(
inputCols=list(X_test.columns),
outputCol='predictions',
modelName='machine_failure_model_rf',
modelVersion=1
)
推論のためにモデルを読み込むように作成した MLFlowTransformer オブジェクトとともに、Transformer API を使用してテスト データセットのモデルにスコアを付けます:
predictions = model.transform(spark.createDataFrame(X_test))
predictions.show()
このテーブルに出力を示します:
| Type | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | 予測 |
|---|---|---|---|---|---|---|
| 0 | 300.6 | 309.7 | 1639.0 | 30.4 | 121.0 | 0 |
| 0 | 303.9 | 313.0 | 1551.0 | 36.8 | 140.0 | 0 |
| 1 | 299.1 | 308.6 | 1491.0 | 38.5 | 166.0 | 0 |
| 0 | 300.9 | 312.1 | 1359.0 | 51.7 | 146.0 | 1 |
| 0 | 303.7 | 312.6 | 1621.0 | 38.8 | 182.0 | 0 |
| 0 | 299.0 | 310.3 | 1868.0 | 24.0 | 221.0 | 1 |
| 2 | 297.8 | 307.5 | 1631.0 | 31.3 | 124.0 | 0 |
| 0 | 297.5 | 308.2 | 1327.0 | 56.5 | 189.0 | 1 |
| 0 | 301.3 | 310.3 | 1460.0 | 41.5 | 197.0 | 0 |
| 2 | 297.6 | 309.0 | 1413.0 | 40.2 | 51.0 | 0 |
| 1 | 300.9 | 309.4 | 1724.0 | 25.6 | 119.0 | 0 |
| 0 | 303.3 | 311.3 | 1389.0 | 53.9 | 39.0 | 0 |
| 0 | 298.4 | 307.9 | 1981.0 | 23.2 | 16.0 | 0 |
| 0 | 299.3 | 308.8 | 1636.0 | 29.9 | 201.0 | 0 |
| 1 | 298.1 | 309.2 | 1460.0 | 45.8 | 80.0 | 0 |
| 0 | 300.0 | 309.5 | 1728.0 | 26.0 | 37.0 | 0 |
| 2 | 299.0 | 308.7 | 1940.0 | 19.9 | 98.0 | 0 |
| 0 | 302.2 | 310.8 | 1383.0 | 46.9 | 45.0 | 0 |
| 0 | 300.2 | 309.2 | 1431.0 | 51.3 | 57.0 | 0 |
| 0 | 299.6 | 310.2 | 1468.0 | 48.0 | 9.0 | 0 |
レイクハウスにデータを保存する。 その後、データは、Power BI ダッシュボードなど、後で使用できるようになります。
# Save test data to the lakehouse for use in the next section.
table_name = "predictive_maintenance_test_with_predictions"
predictions.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
手順 6: Power BI の視覚化によるビジネス インテリジェンスを確認する
Power BI ダッシュボードを使用して、結果をオフライン形式で表示します。
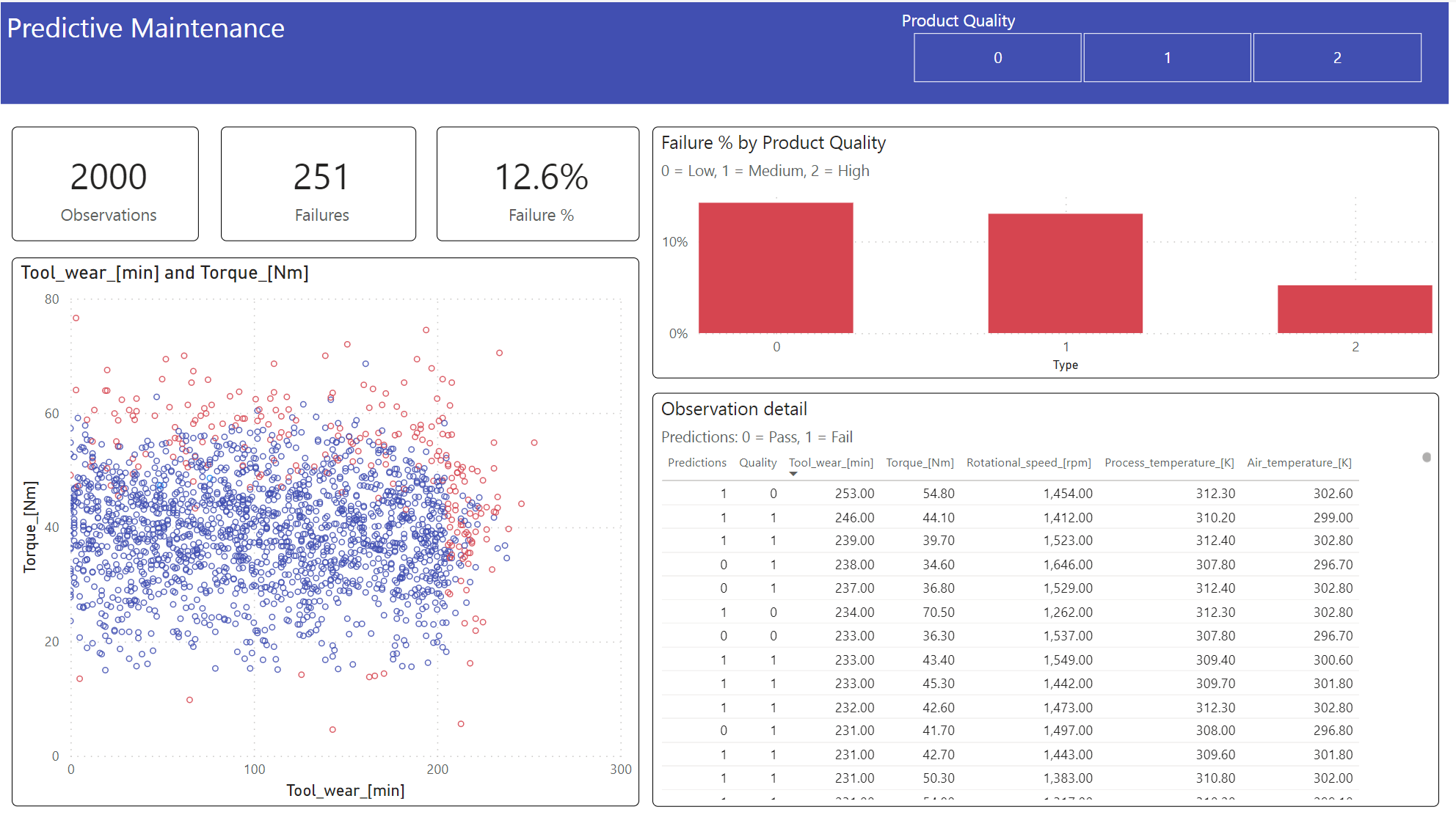
ダッシュボードには、Tool_wear と Torque によって、手順 2 の以前の相関分析で予想されていたように、故障したケースと故障していないケースの間に顕著な境界が生じることが示されています。