Microsoft Fabric での PREDICT を使用した機械学習モデルのスコアリング
Microsoft Fabric では、ユーザーがスケーラブルな PREDICT 関数を使って機械学習モデルを運用化することができます。 この関数は、任意のコンピューティング エンジンでのバッチ スコアリングをサポートしています。 ユーザーは、Microsoft Fabric ノートブックまたは特定の ML モデルの項目ページから直接バッチ予測を生成できます。
この記事では、自分でコードを記述するか、ガイド付き UI エクスペリエンスを使用してバッチ スコアリングを処理して、PREDICT を適用する方法について説明します。
前提条件
Microsoft Fabric サブスクリプションを取得します。 または、無料の Microsoft Fabric 試用版にサインアップします。
Microsoft Fabric にサインインします。
ホーム ページの左側の下にあるエクスペリエンス スイッチャーを使用して、Fabric に切り替えます。
![[エクスペリエンス スイッチャー メニュー] で Data Science を選択するところを示すスクリーンショット。](media/tutorial-data-science-prepare-system/switch-to-data-science.png)
制限事項
- PREDICT 関数は、現在、ML モデル フレーバーの限られたセットでサポートされています。
- CatBoost
- Keras
- LightGBM
- ONNX
- Prophet
- PyTorch
- Sklearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- PREDICT では、ML モデルを MLflow 形式で保存し、署名を設定する "必要があります"。
- PREDICT では、マルチテンソル入力や出力を持つモデルはサポートされて "いません"
ノートブックから PREDICT を呼び出す
PREDICT では、Microsoft Fabric レジストリで MLflow パッケージ モデルがサポートされています。 既にトレーニングしてワークスペースに登録した ML モデルが存在する場合は、手順 2 までスキップできます。 そうでない場合は、手順 1 でサンプルのロジスティック回帰モデルのトレーニングを導くサンプル コードが提供されます。 このモデルを使用して、手順の最後にバッチ予測を生成できます。
ML モデルをトレーニングして、それを MLflow に登録します。 次のサンプル コードでは、MLflow API を使用して機械学習実験を作成し、scikit-learn ロジスティック回帰モデルの MLflow 実行を開始します。 その後、モデル バージョンが Microsoft Fabric レジストリに格納され、登録されます。 モデルのトレーニングと独自の実験の追跡の詳細については、scikit-learn を使用して ML モデルをトレーニングする方法に関するページを参照してください。
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )テスト データを Spark DataFrame として読み込みます。 前の手順でトレーニングした ML モデルを使用してバッチ予測を生成するには、Spark DataFrame 形式のテスト データが必要です。 次のコードでは、
test変数の値を独自のデータに置き換えます。# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))推論のために ML モデルを読み込む
MLFlowTransformerオブジェクトを作成します。 バッチ予測を生成するためのMLFlowTransformerオブジェクトを作成するには、以下の操作を実行する必要があります。- モデル入力として必要な
testDataFrame 列を指定し (この場合は、それらすべて)、 - 新しい出力列の名前 (この場合は
predictions) を選択し、 - これらの予測を生成するための正しいモデル名とモデル バージョンを提供します。
独自の ML モデルを使用している場合は、入力列、出力列名、モデル名、およびモデル バージョンの値を置き換えます。
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- モデル入力として必要な
PREDICT 関数を使用して予測を生成します。 PREDICT 関数を呼び出すには、Transformer API、Spark SQL API、または PySpark ユーザー定義関数 (UDF) を使用します。 以降のセクションでは、PREDICT 関数を呼び出すためのさまざまなメソッドを使用して、前の手順で定義したテスト データと ML モデルを使用してバッチ予測を生成する方法を示します。
Transformer API を使用した PREDICT
このコードでは、Transformer API を使用して PREDICT 関数を呼び出します。 独自の ML モデルを使用している場合は、モデルとテスト データの値を置き換えます。
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
Spark SQL API を使用した PREDICT
このコードでは、Spark SQL API を使用して PREDICT 関数を呼び出します。 独自の ML モデルを使用している場合は、model_name、model_version、features の値を、モデル名、モデル バージョン、特徴の列に置き換えます。
Note
予測生成に Spark SQL API を使用する場合は、引き続き MLFlowTransformer オブジェクトを作成する必要があります (手順 3 参照)。
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
ユーザー定義関数を使用した PREDICT
このコードでは、PySpark UDF を使用して PREDICT 関数を呼び出します。 独自の ML モデルを使用している場合は、モデルと機能の値を置き換えます。
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
ML モデルの項目ページから PREDICT コードを生成する
どの ML モデルの項目ページからでも、PREDICT 関数を使用して、特定のモデル バージョンのバッチ予測生成を開始するために、次のオプションの 1 つを選択できます。
- コード テンプレートをノートブックにコピーし、パラメーターを自分でカスタマイズする
- ガイド付き UI エクスペリエンスを使用して PREDICT コードを生成する
ガイド付き UI エクスペリエンスを使用する
ガイド付き UI エクスペリエンスでは、以下の手順が示されます。
- スコアリング用のソース データを選択する
- データを ML モデル入力に正しくマップする
- モデル出力先を指定する
- PREDICT を使用して予測結果の生成と格納を行うノートブックを作成する
ガイド付きエクスペリエンスを使用するには、
特定の ML モデル バージョンの項目ページに移動します。
[適用するバージョン] ドロップダウンから [ウィザードでこのモデルを適用する] を選択します。
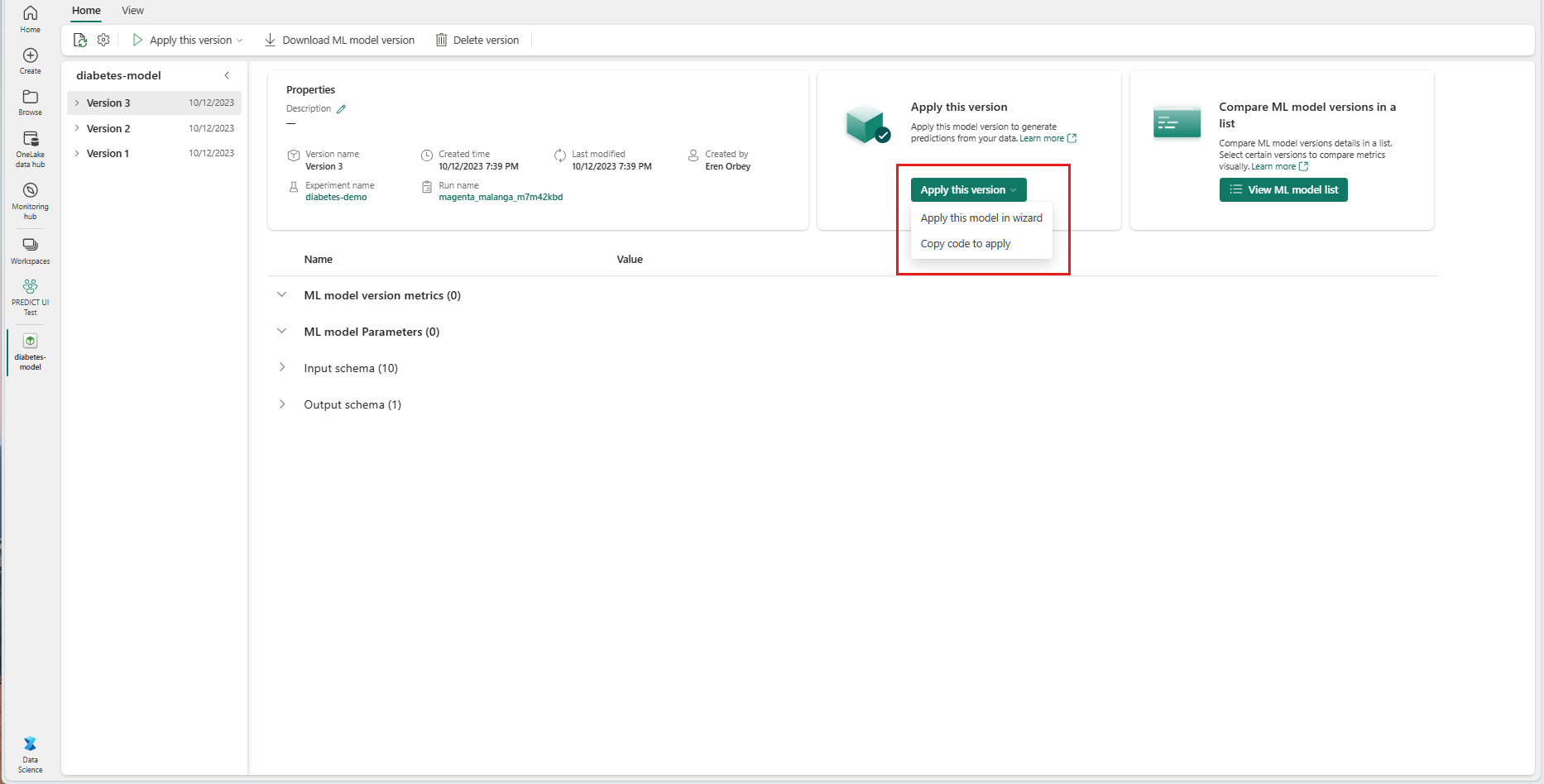
[入力テーブルの選択] ステップで [ML モデル予測の適用] ウィンドウが開きます。
現在のワークスペースの Lakehouses から入力テーブルを選択します。
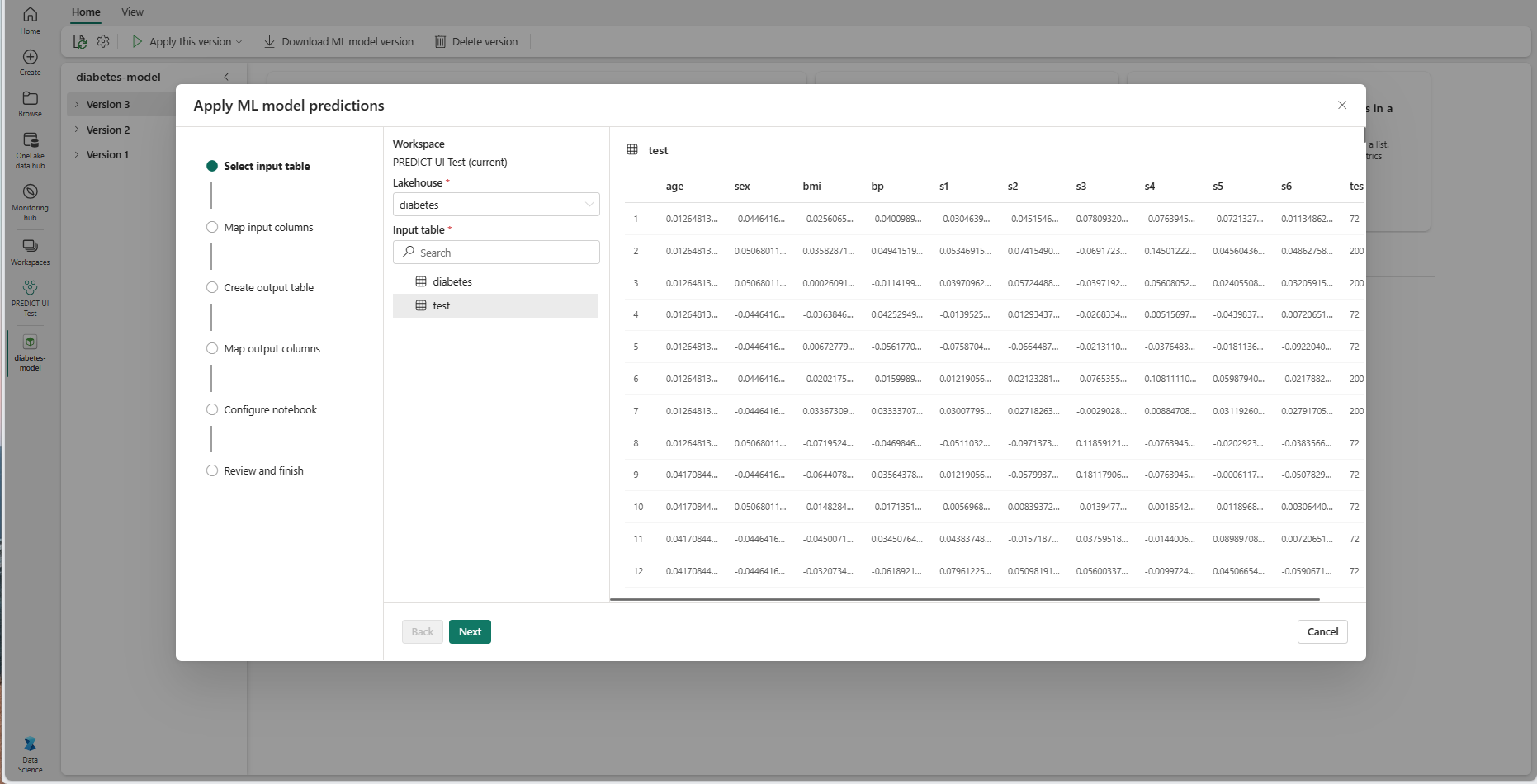
[次へ] を選択して、[入力列のマッピング] ステップに進みます。
ソース テーブルの列名を、ML モデルのシグネチャから取得されたモデルの入力フィールドにマッピングします。 モデルのすべての必須フィールドに入力列を指定する必要があります。 さらに、ソース列のデータ型は、モデルの予想されるデータ型と一致している必要があります。
ヒント
入力テーブルの列の名前が ML モデル署名に記録されている列名と一致する場合、ウィザードはこのマッピングを事前設定します。
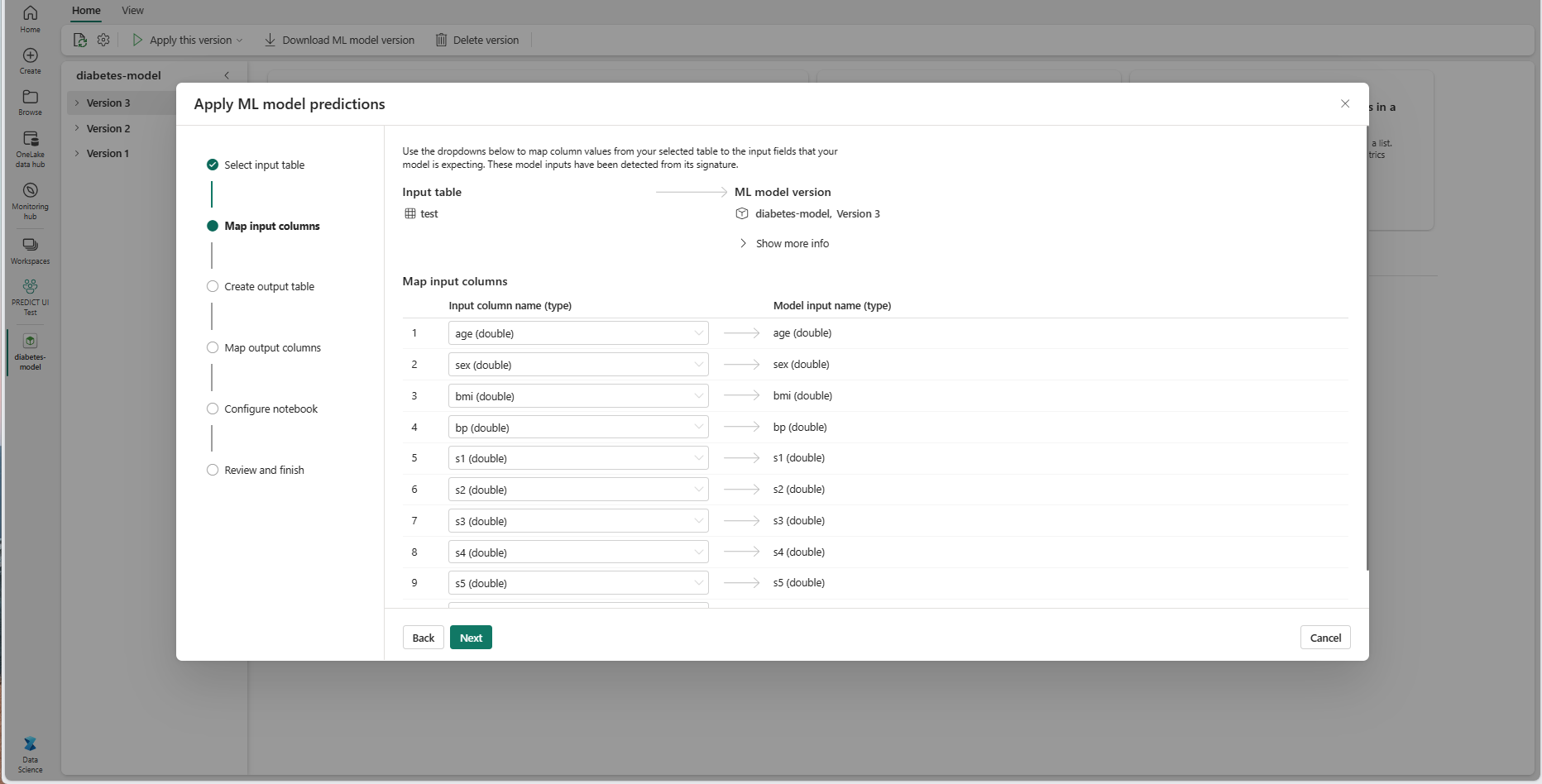
[次へ] を選択して、[出力テーブルの作成] ステップに移動します。
現在のワークスペースの選択したレイクハウス内にある、新しいテーブルの名前を指定します。 この出力テーブルには、ML モデルの入力値が格納され、そのテーブルに予測値が追加されます。 既定では、出力テーブルは入力テーブルと同じレイクハウスに作成されます。 宛先のレイクハウスは変更できます。
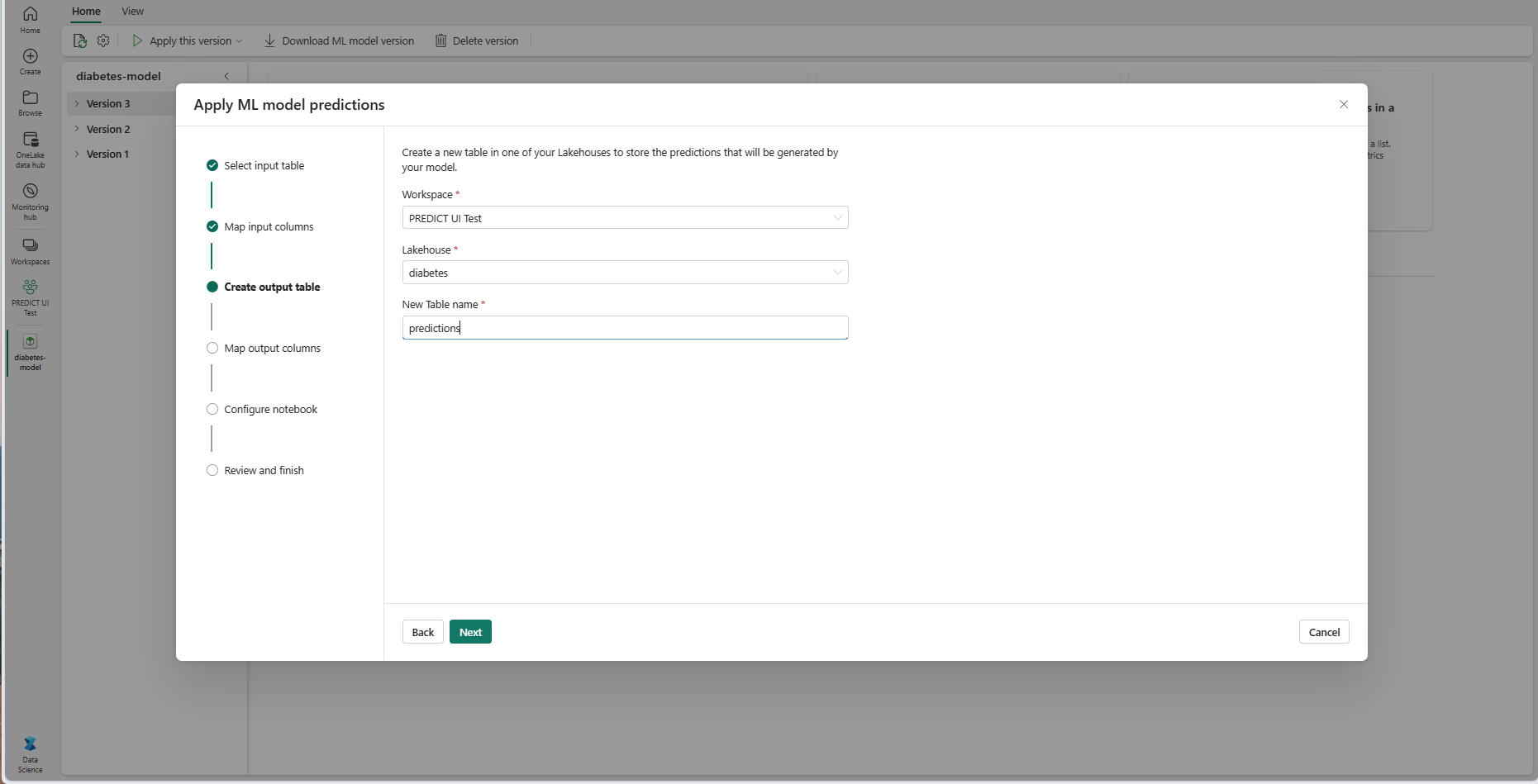
[次へ] を選択して、[出力列のマッピング] ステップに進みます。
指定したテキスト フィールドを使用して、ML モデルの予測を格納する出力テーブルの列に名前を付けます。
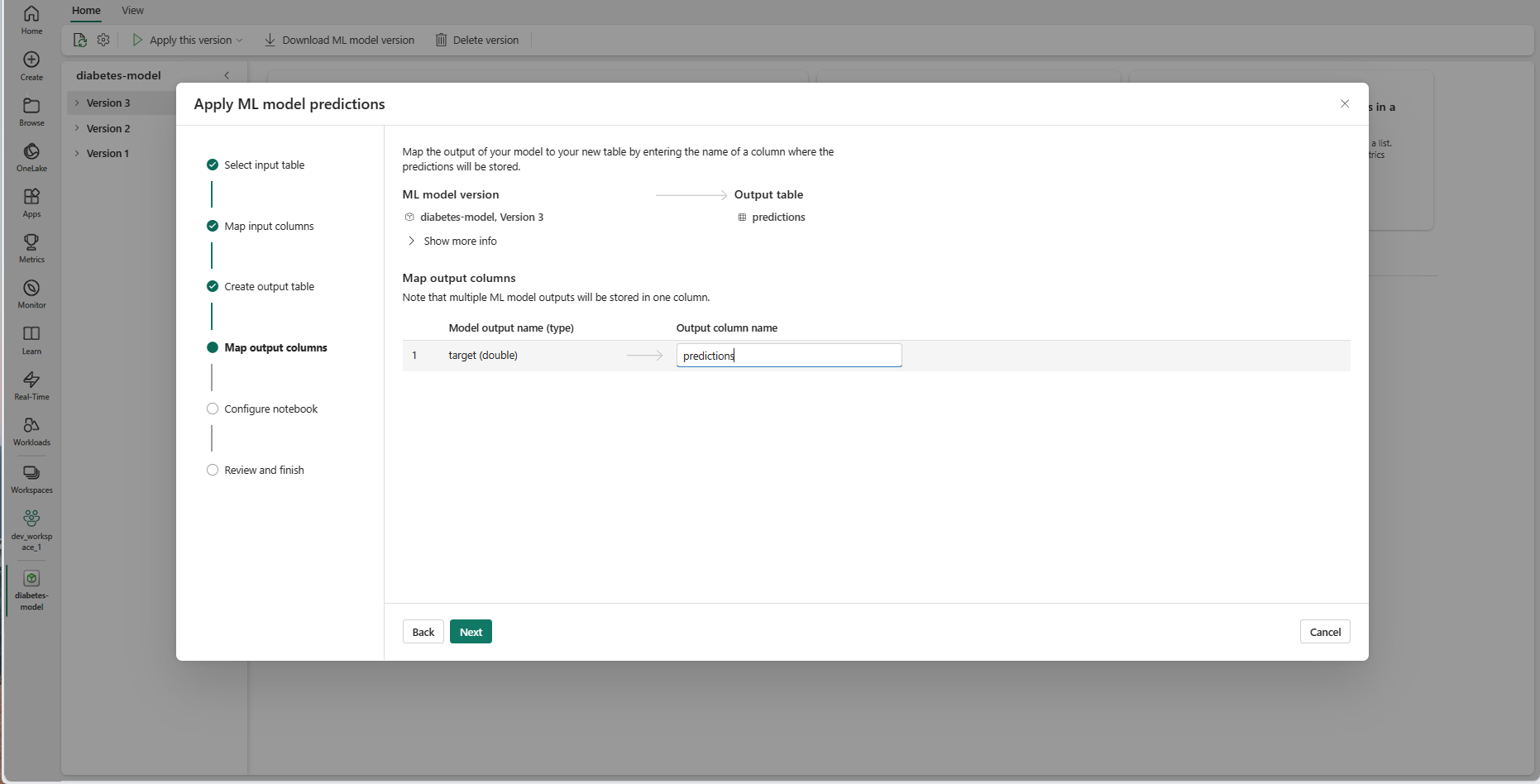
[次へ] を選択して、[ノートブックを設定する] ステップに進みます。
生成された PREDICT コードを実行する新しいノートブックの名前を指定します。 ウィザードには、この手順で生成されたコードのプレビューが表示されます。 必要に応じて、コードをクリップボードにコピーし、既存のノートブックに貼り付けることができます。
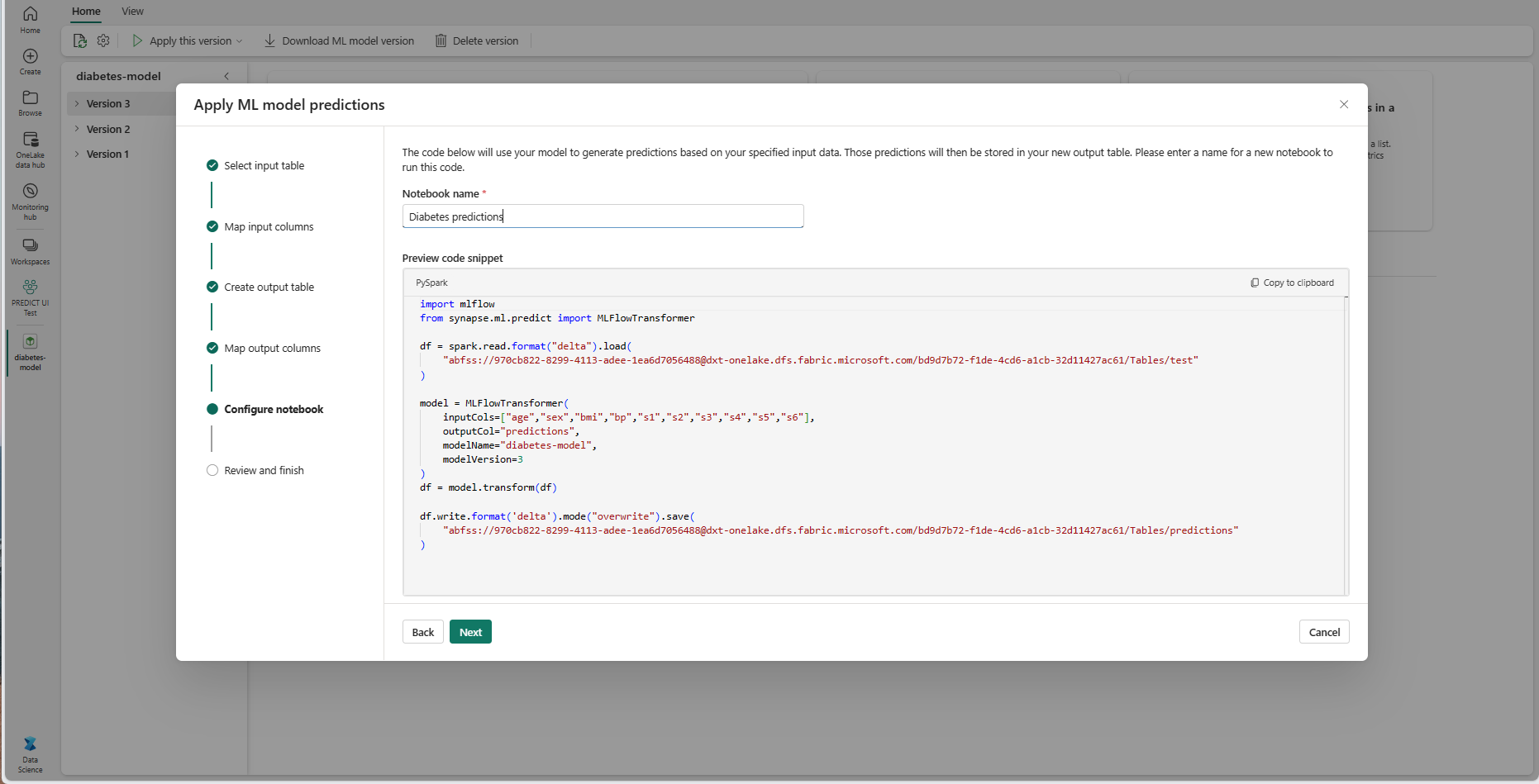
[次へ] を選択して、[確認と完了] ステップに進みます。
概要ページの詳細を確認し、[ノートブックの作成] を選択して、生成されたコードを含む新しいノートブックをワークスペースに追加します。 そのノートブックに直接移動されます。ここで、コードを実行して予測を生成し、格納できます。
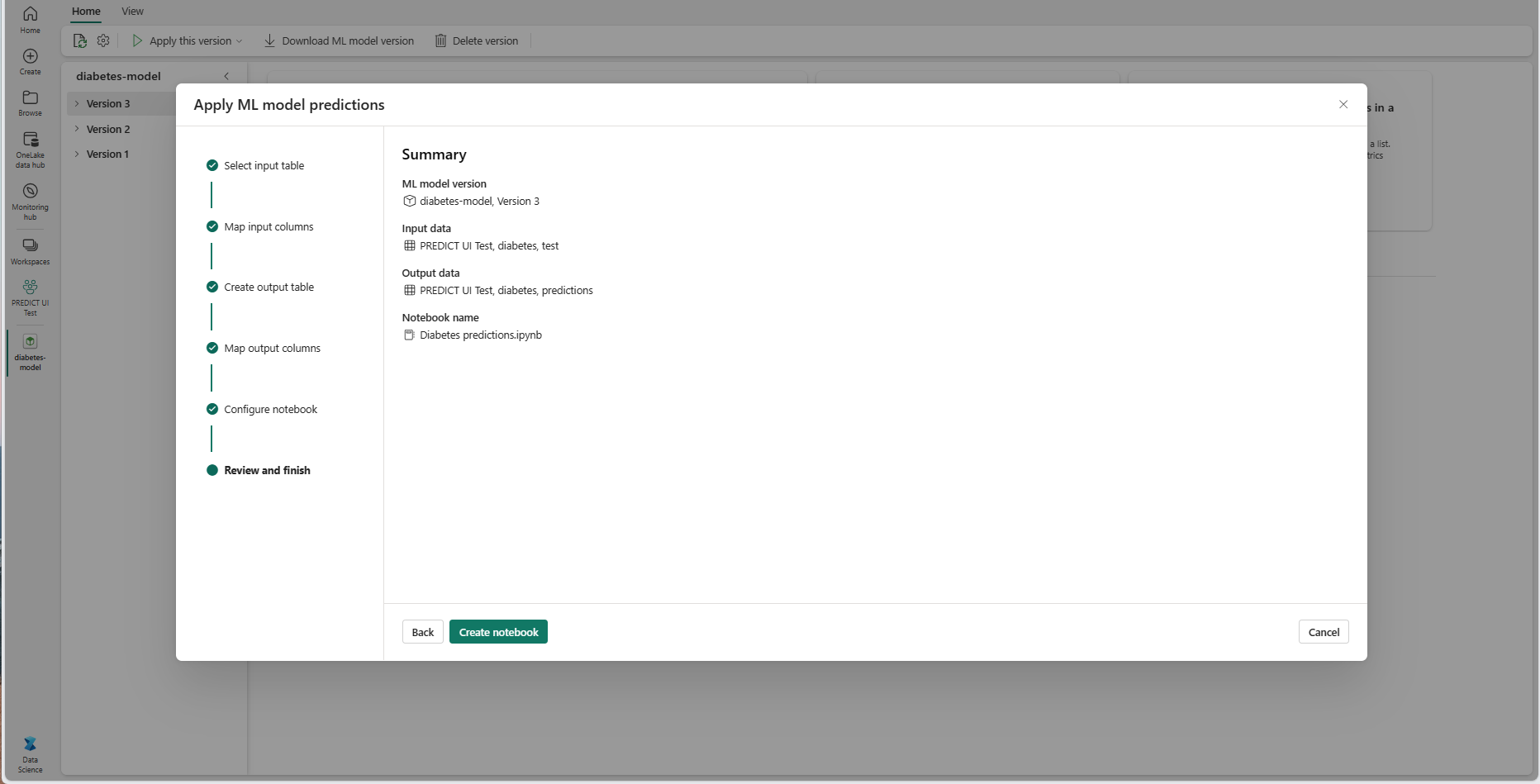







カスタマイズ可能なコード テンプレートを使用する
バッチ予測を生成するためにコード テンプレートを使用するには:
- 特定の ML モデル バージョンの項目ページに移動します。
- [適用するバージョン] ドロップダウンから [適用するコードのコピー] を選択します。 選択すると、カスタマイズ可能なコード テンプレートをコピーできます。
このコード テンプレートをノートブックに貼り付けて、ML モデルでバッチ予測を生成できます。 コード テンプレートを正常に実行するには、次の値を手動で置き換える必要があります。
<INPUT_TABLE>: ML モデルへの入力を提供するテーブルのファイル パス<INPUT_COLS>: ML モデルにフィードする入力テーブルの列名の配列<OUTPUT_COLS>: 予測を格納する出力テーブル内の新しい列の名前<MODEL_NAME>: 予測の生成に使用する ML モデルの名前<MODEL_VERSION>: 予測の生成に使用する ML モデルのバージョン<OUTPUT_TABLE>: 予測を格納するテーブルのファイル パス

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)