AdventureWorks データセットを使用した AI スキルの例 (プレビュー)
この記事では、Lakehouse をデータ ソースとして使用して、AI スキルを設定する方法について説明します。 プロセスを説明するために、まずレイクハウスを作成し、次にデータを追加します。 次に、AI スキルを作成し、そのデータ ソースとして lakehouse を構成します。 Power BI セマンティック モデル (必要な読み取り/書き込みアクセス許可を持つ)、ウェアハウス、または KQL データベースが既にある場合は、AI スキルを作成してデータ ソースを追加した後も同じ手順に従うことができます。 ここで示す手順はレイクハウスに焦点を当てていますが、プロセスは他のデータ ソースでも似ています。特定の選択内容に基づいて調整するだけです。
重要
この機能はプレビュー段階にあります。
前提条件
- 有料 F64 以上の Fabric 容量リソース
- AI スキル テナント スイッチが有効にされている。
- Copilot テナント スイッチが有効にされている。
- AI のクロス geo 処理が有効になっています。
- AI のクロスジオ格納が有効になっています。
- データを含むウェアハウス、レイクハウス、Power BI セマンティック モデル、KQL データベース。
- POWER BI セマンティック モデルのデータ ソースに対して、XMLA エンドポイントテナントスイッチ を介して Power BI セマンティック モデルが有効になります。
AdventureWorksLH を使用してレイクハウスを作成する
最初にレイクハウスを作成し、必要なデータを設定します。
AdventureWorksLH のインスタンスが既にレイクハウス (または倉庫) にある場合は、この手順をスキップできます。 そうでない場合は、Fabric ノートブックの次の手順を使用して、Lakehouse にデータを設定できます。
AI スキルを作成するワークスペースに新しいノートブックを作成します。
[エクスプローラー] ペインの左側で [+ データ ソース] を選びます。 このオプションを使用すると、既存のレイクハウスを追加したり、新しいレイクハウスを作成することができます。 わかりやすくするために、新しいレイクハウスを作成し、名前を割り当てます。
先頭のセルに次のコード スニペットを追加します。
import pandas as pd from tqdm.auto import tqdm base = "https://synapseaisolutionsa.blob.core.windows.net/public/AdventureWorks" # load list of tables df_tables = pd.read_csv(f"{base}/adventureworks.csv", names=["table"]) for table in (pbar := tqdm(df_tables['table'].values)): pbar.set_description(f"Uploading {table} to lakehouse") # download df = pd.read_parquet(f"{base}/{table}.parquet") # save as lakehouse table spark.createDataFrame(df).write.mode('overwrite').saveAsTable(table)[すべて実行] を選びます。
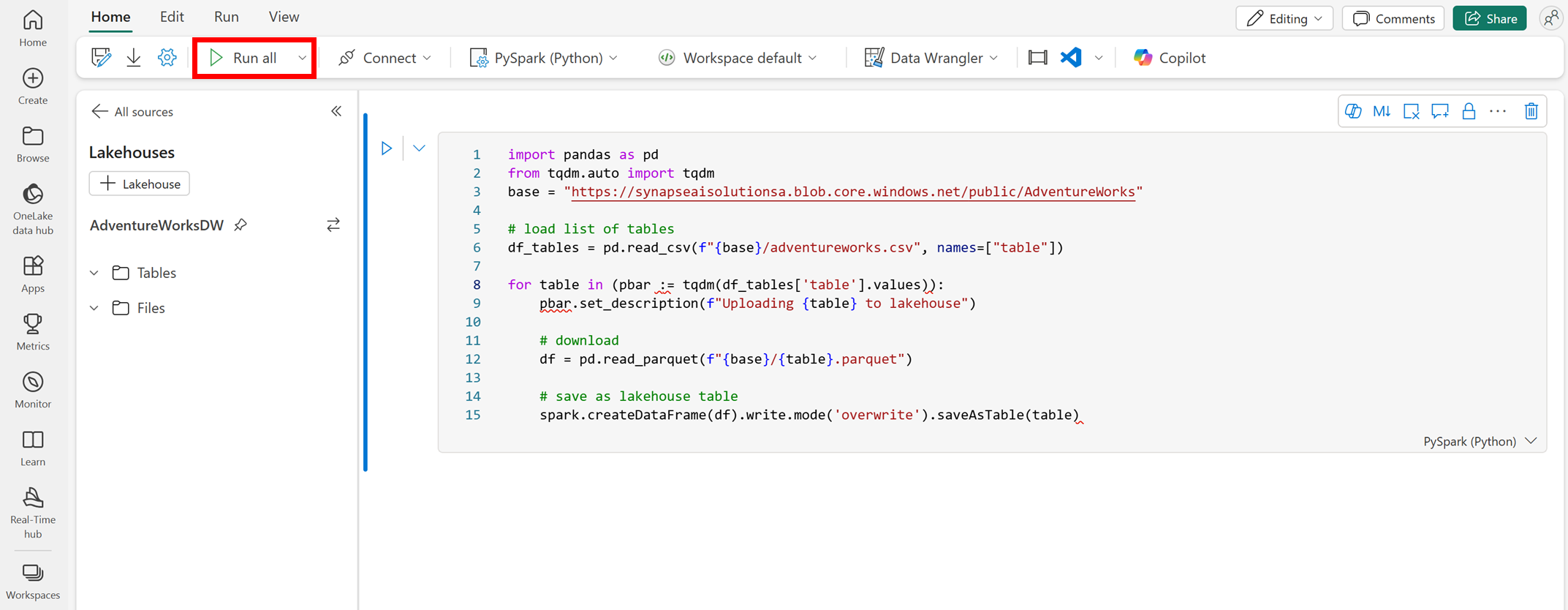

数分後に、レイクハウスに必要なデータが取り込まれます。
AI スキルを作成する
新しい AI スキルを作成するには、ワークスペースに移動し、次のスクリーンショットに示すように、[+ 新しい項目] ボタンを選択します。

[すべての項目] タブで、AI スキル を検索して、適切なオプションを見つけます。 選択すると、次のスクリーンショットに示すように、AI スキルの名前を指定するように求めるプロンプトが表示されます。

名前を入力したら、次の手順に進み、AI スキルを特定の要件に合わせます。
データを選択する
前の手順で作成したレイクハウスを選択し、次に の追加 を選択します。 lakehouse がデータ ソースとして追加されると、AI スキル ページの左側にある Explorer ペインに lakehouse 名が表示されます。 使用可能なすべてのテーブルを表示するには、レイクハウスを選択します。 チェックボックスを使用して、AI で使用できるようにするテーブルを選択します。 このシナリオでは、次のテーブルを選択します。
dimcustomerdimdatedimgeographydimproductdimproductcategorydimpromotiondimresellerdimsalesterritoryfactinternetsalescactresellersales

指示を提供する
AI 命令を追加するには、AI 命令 ボタンを選択して、右側の [AI 命令] ウィンドウを開きます。 次の手順を追加できます。
AdventureWorksLH データ ソースには、次の 3 つのテーブルからの情報が含まれています。
dimcustomer: 詳細な顧客の人口統計と連絡先情報dimdate、日付関連のデータ (カレンダーや会計情報など)dimgeography: 市区町村名や国の地域コードなどの地理的な詳細。
このデータ ソースは、顧客の詳細、時間ベースのイベント、地理的な場所を含むクエリと分析に使用します。

例を提供する
サンプル クエリを追加するには、[クエリの例] ボタンを選択して、右側の [サンプル クエリ] ウィンドウを開きます。 このウィンドウには、サポートされているすべてのデータ ソースのサンプル クエリを追加または編集するためのオプションが用意されています。 次のスクリーンショットに示すように、データ ソースごとに [サンプル クエリの追加または編集] を選択して、関連する例を入力できます。

ここでは、作成した lakehouse データ ソースのサンプル クエリを追加する必要があります。
Question: Calculate the average percentage increase in sales amount for repeat purchases for every zipcode. Repeat purchase is a purchase subsequent to the first purchase (the average should always be computed relative to the first purchase)
SELECT AVG((s.SalesAmount - first_purchase.SalesAmount) / first_purchase.SalesAmount * 100) AS AvgPercentageIncrease
FROM factinternetsales s
INNER JOIN dimcustomer c ON s.CustomerKey = c.CustomerKey
INNER JOIN dimgeography g ON c.GeographyKey = g.GeographyKey
INNER JOIN (
SELECT *
FROM (
SELECT
CustomerKey,
SalesAmount,
OrderDate,
ROW_NUMBER() OVER (PARTITION BY CustomerKey ORDER BY OrderDate) AS RowNumber
FROM factinternetsales
) AS t
WHERE RowNumber = 1
) first_purchase ON s.CustomerKey = first_purchase.CustomerKey
WHERE s.OrderDate > first_purchase.OrderDate
GROUP BY g.PostalCode;
Question: Show the monthly total and year-to-date total sales. Order by year and month.
SELECT
Year,
Month,
MonthlySales,
SUM(MonthlySales) OVER (PARTITION BY Year ORDER BY Year, Month ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS CumulativeTotal
FROM (
SELECT
YEAR(OrderDate) AS Year,
MONTH(OrderDate) AS Month,
SUM(SalesAmount) AS MonthlySales
FROM factinternetsales
GROUP BY YEAR(OrderDate), MONTH(OrderDate)
) AS t

手記
Power BI セマンティック モデルのデータ ソースでは、サンプル クエリと質問のペアの追加は現在サポートされていません。
AI スキルをテストして修正する
これで、AI スキルを構成し、AI 命令を追加し、Lakehouse のクエリ例を提供しました。ここで、質問をして回答を受け取ることで、それを操作できます。 テストを続ける際に、さらに例を追加し、手順を調整して、AI スキルのパフォーマンスをさらに向上させることができます。 同僚と共同作業してフィードバックを収集し、入力に基づいて、提供されているクエリと指示の例が、質問の種類と一致していることを確認します。
プログラムで AI スキルを使用する
Fabric ノートブック内のプログラムで AI スキルを使用できます。 AI スキルに発行済みの URL の値があるかどうかを確認するには、次のスクリーンショットで示すように、[設定] を選びます。

次のスクリーンショットで示すように、AI スキルを発行する前は、発行済みの URL 値はありません。

AI スキルのパフォーマンスを検証したら、それを公開して、Q&A をデータ経由で実行する同僚と共有することができます。 この場合は、次のスクリーンショットで示すように [発行] を選びます。
![[発行] オプションの選択を示すスクリーンショット。](media/ai-skill-scenario/ai-select-publish.png#lightbox)
次のスクリーンショットで示すように、AI スキルの発行済みの URL が表示されます。

発行済み URL をコピーし、Fabric ノートブックで使用できます。 このように、Fabric ノートブックで AI スキル API を呼び出して、AI スキルのクエリを実行できます。 コピーした URL をこのコード スニペットに貼り付けます。 次に、質問を AI スキルに関連するクエリに置き換えます。 この例では、\<generic published URL value\> という URL を使用しています。
%pip install "openai==1.14.1"
%pip install httpx==0.27.2
import requests
import json
import pprint
import typing as t
import time
import uuid
from openai import OpenAI
from openai._exceptions import APIStatusError
from openai._models import FinalRequestOptions
from openai._types import Omit
from openai._utils import is_given
from synapse.ml.mlflow import get_mlflow_env_config
from sempy.fabric._token_provider import SynapseTokenProvider
base_url = "https://<generic published base URL value>"
question = "What datasources do you have access to?"
configs = get_mlflow_env_config()
# Create OpenAI Client
class FabricOpenAI(OpenAI):
def __init__(
self,
api_version: str ="2024-05-01-preview",
**kwargs: t.Any,
) -> None:
self.api_version = api_version
default_query = kwargs.pop("default_query", {})
default_query["api-version"] = self.api_version
super().__init__(
api_key="",
base_url=base_url,
default_query=default_query,
**kwargs,
)
def _prepare_options(self, options: FinalRequestOptions) -> None:
headers: dict[str, str | Omit] = (
{**options.headers} if is_given(options.headers) else {}
)
options.headers = headers
headers["Authorization"] = f"Bearer {configs.driver_aad_token}"
if "Accept" not in headers:
headers["Accept"] = "application/json"
if "ActivityId" not in headers:
correlation_id = str(uuid.uuid4())
headers["ActivityId"] = correlation_id
return super()._prepare_options(options)
# Pretty printing helper
def pretty_print(messages):
print("---Conversation---")
for m in messages:
print(f"{m.role}: {m.content[0].text.value}")
print()
fabric_client = FabricOpenAI()
# Create assistant
assistant = fabric_client.beta.assistants.create(model="not used")
# Create thread
thread = fabric_client.beta.threads.create()
# Create message on thread
message = fabric_client.beta.threads.messages.create(thread_id=thread.id, role="user", content=question)
# Create run
run = fabric_client.beta.threads.runs.create(thread_id=thread.id, assistant_id=assistant.id)
# Wait for run to complete
while run.status == "queued" or run.status == "in_progress":
run = fabric_client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id,
)
print(run.status)
time.sleep(2)
# Print messages
response = fabric_client.beta.threads.messages.list(thread_id=thread.id, order="asc")
pretty_print(response)
# Delete thread
fabric_client.beta.threads.delete(thread_id=thread.id)