Dataflow Gen2 データの格納先とマネージド設定
Dataflow Gen2 を使用してデータをクリーンして準備したら、データを格納先に格納します。 これは、Dataflow Gen2 のデータ格納先機能を使用して行うことができます。 この機能では、Azure SQL、Fabric Lakehouse など、さまざまな格納先から選択できます。 その後、Dataflow Gen2 はデータを格納先に書き込み、そこからデータを使用してさらに分析とレポートを行うことができます。
次の一覧に、サポートされているデータ格納先を示します。
- Azure SQL データベース
- Azure Data Explorer (Kusto)
- Fabric Lakehouse
- Fabric Warehouse
- Fabric KQL データベース
- Fabric SQL データベース
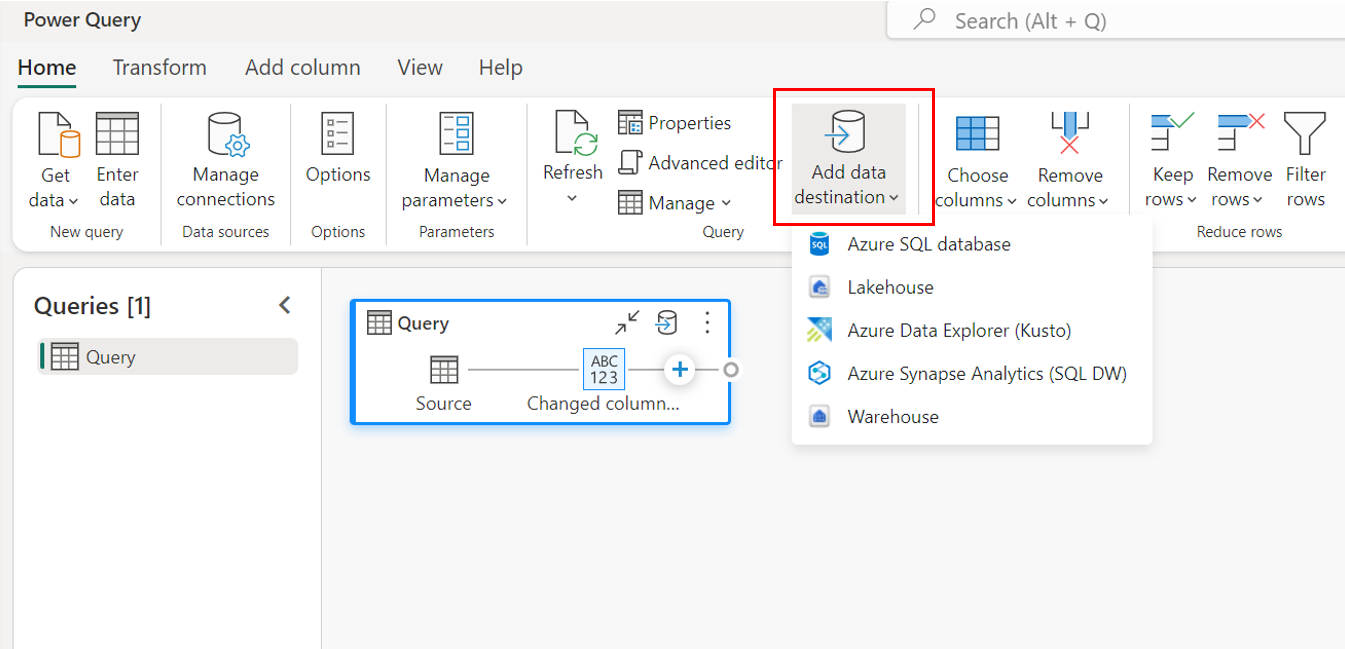
エントリ ポイント
Dataflow Gen2 内のすべてのデータ クエリには、データの格納先を含めることができます。 関数とリストはサポートされていません。表形式クエリにのみ適用できます。 各クエリのデータ格納先を個別に指定でき、データフロー内で複数の異なる格納先を使用できます。
データの格納先を指定する主要なエントリ ポイントには、次の 3 つがあります。
上部のリボンを使用します。
クエリ設定を使用します。
![[データ保存先] ボタンが強調され、保存先のリストが表示されている [クエリ設定] ウィンドウのスクリーンショット。](media/dataflow-gen2-data-destinations-and-managed-settings/query-settings-destination.png)
ダイアグラム ビューを使用します。
![[保存先の追加] アイコンが強調され、保存先のリストが表示されたダイアグラム ビューのクエリのスクリーンショット。](media/dataflow-gen2-data-destinations-and-managed-settings/diagram-view-destination.png)
データ格納先に接続する
データ格納先への接続は、データ ソースへの接続と似ています。 データ ソースに対する適切なアクセス許可がある場合、データの読み取りと書き込みの両方に接続を使用できます。 新しい接続を作成するか、既存の接続を選択した後に、[次へ] を選択する必要があります。
![Lakehouse 保存先の [データ保存先に接続] ウィンドウのスクリーンショット。](media/dataflow-gen2-data-destinations-and-managed-settings/connect-to-data-destination.png)
新しいテーブルを作成するか、既存のテーブルを選択します。
データ格納先に読み込む際、新しいテーブルを作成するか、既存のテーブルを選択できます。
新しいテーブルの作成
新しいテーブルを作成する場合は、Dataflow Gen2 の更新中に、新しいテーブルがデータ格納先に作成されます。 その後格納先に手動で移動することでテーブルが削除された場合、データフローは次回のデータフローの更新中にテーブルを再作成します。
既定では、テーブル名の名前はクエリ名と同じです。 格納先でサポートされていない無効な文字がテーブル名に含まれている場合、テーブル名は自動的に調整されます。 たとえば、多くの格納先では、スペースや特殊文字がサポートされていません。
![[新しいテーブル] ボタンが選択された [保存先ターゲットの選択] ウィンドウのスクリーンショット。](media/dataflow-gen2-data-destinations-and-managed-settings/new-table.png)
次に、格納先コンテナーを選択する必要があります。 いずれかの Fabric データ格納先を選択した場合は、ナビゲーターを使用して、データを読み込む Fabric アーティファクトを選択できます。 Azure の格納先の場合は、接続の作成時にデータベースを指定するか、ナビゲーターでデータベースを選択できます。
既存のテーブルの使用
既存のテーブルを選択するには、ナビゲーターの上部にあるトグルを使用します。 既存のテーブルを選択する場合は、ナビゲーターを使用して Fabric アーティファクト/データベースとテーブルの両方を選択する必要があります。
既存のテーブルを使用する場合、どのシナリオでもテーブルを再作成することはできません。 データ格納先からテーブルを手動で削除した場合、Dataflow Gen2 は次回の更新時にテーブルを再作成しません。
![[既存のテーブル] ボタンが選択された [保存先ターゲットの選択] ウィンドウのスクリーンショット。](media/dataflow-gen2-data-destinations-and-managed-settings/existing-table.png)
新しいテーブルのマネージド設定
新しいテーブルに読み込む場合、自動設定は既定でオンになっています。 自動設定を使用すると、Dataflow Gen2 によってマッピングが自動的に管理されます。 自動設定では、動作は次のようになります。
更新による置換方法: データは、データフローの更新ごとに置き換えられます。 格納先のデータはすべて削除されます。 格納先のデータは、データフローの出力データに置き換えられます。
マネージド マッピング: マッピングは管理されます。 データ/クエリを変更して別の列を追加したり、データ型を変更したりする必要がある場合、データフローを再発行すると、この変更に対応するマッピングが自動的に調整されます。 データフローに変更を加えるたびにデータ格納先エクスペリエンスに移動する必要はありません。これにより、データフローを再発行するときにスキーマを簡単に変更できます。
テーブルを削除して再作成する: これらのスキーマの変更を許可するために、すべてのデータフロー更新でテーブルが削除され、再作成されます。 データフローの更新により、以前にテーブルに追加されたリレーションシップまたはメジャーが削除される可能性があります。
Note
現在、自動設定は、データ格納先が Lakehouse および Azure SQL データベースの場合のみサポートされています。
![[自動設定の使用] オプションが選択された [保存先設定の選択] ウィンドウのスクリーンショット。](media/dataflow-gen2-data-destinations-and-managed-settings/use-automatic-settings.png)
手動設定
[自動設定の使用] をオフにすることで、データをデータ格納先に読み込む方法を完全に制御できます。 列マッピングを変更するには、ソースの種類を変更するか、データ格納先に不要な列を除外します。
![[自動設定オプションの使用] が選択されておらず、さまざまな手動設定が表示された [保存先設定の選択] ウィンドウのスクリーンショット。](media/dataflow-gen2-data-destinations-and-managed-settings/use-manual-settings.png)
更新方法
ほとんどの格納先では、更新方法として追加と置換の両方がサポートされています。 ただし、Fabric KQL データベースと Azure Data エクスプローラーでは、更新方法としての置換はサポートされていません。
置換: すべてのデータフロー更新で、データは格納先から削除され、データフローの出力データに置き換えられます。
追加: すべてのデータフロー更新で、データフローからの出力データがデータ格納先テーブルの既存のデータに追加されます。
発行時のスキーマ オプション
発行時のスキーマ オプションは、更新メソッドが置き換えられる場合にのみ適用されます。 データを追加する場合、スキーマを変更することはできません。
動的スキーマ: 動的スキーマを選択した場合、データフローを再発行するときに、データ格納先でスキーマの変更が可能です。 マネージド マッピングを使用していないため、クエリに変更を加えた場合でも、データフローの格納先フローの列マッピングを更新する必要があります。 データフローが更新されると、テーブルが削除されて再作成されます。 データフローの更新により、以前にテーブルに追加されたリレーションシップまたはメジャーが削除される可能性があります。
固定スキーマ: 固定スキーマを選択した場合、スキーマを変更することはできません。 データフローが更新されると、テーブル内の行のみが削除され、データフローからの出力データに置き換えられます。 テーブル上のリレーションシップやメジャーはいずれも、そのまま残ります。 データフロー内のクエリに変更を加えた場合、クエリ スキーマがデータ格納先スキーマと一致しないことを検出すると、データフローの発行は失敗します。 スキーマを変更したり、リレーションシップまたはメジャーを格納先テーブルに追加したりする予定がない場合は、この設定を使用します。
Note
ウェアハウスにデータを読み込む際、固定スキーマのみがサポートされます。
![[固定スキーマ] が選択された発行オプションの [スキーマ オプション] のスクリーンショット。](media/dataflow-gen2-data-destinations-and-managed-settings/fixed-schema.png)
格納先ごとにサポートされているデータ ソースの種類
| 保存場所別のサポートされるデータ型 | DataflowStagingLakehouse | Azure DB (SQL) アウトプット | Azure Data Explorer アウトプット | Fabric Lakehouse (LH) アウトプット | Fabric Warehouse (WH) アウトプット | Fabric SQL Database (SQL) 出力 |
|---|---|---|---|---|---|---|
| アクション | いいえ | いいえ | いいえ | いいえ | いいえ | いいえ |
| Any | いいえ | いいえ | いいえ | いいえ | いいえ | いいえ |
| Binary | いいえ | いいえ | いいえ | いいえ | いいえ | 無効 |
| 通貨 | はい | イエス | イエス | はい | いいえ | はい |
| DateTimeZone | はい | イエス | はい | いいえ | 番号 | はい |
| Duration | いいえ | 番号 | 有効 | いいえ | いいえ | いいえ |
| 機能 | いいえ | いいえ | いいえ | いいえ | いいえ | 無効 |
| なし | いいえ | いいえ | いいえ | いいえ | いいえ | いいえ |
| Null | いいえ | いいえ | いいえ | いいえ | いいえ | いいえ |
| 時刻 | はい | はい | いいえ | いいえ | 番号 | はい |
| Type | いいえ | いいえ | いいえ | いいえ | いいえ | いいえ |
| 構造化 (リスト、レコード、テーブル) | いいえ | いいえ | いいえ | いいえ | いいえ | いいえ |
高度なトピック
格納先に読み込む前にステージングを使用する
クエリ処理のパフォーマンスを向上させるために、Dataflows Gen2 内でステージングを使用して、Fabric コンピューティングを使用してクエリを実行できます。
クエリでステージングが有効になっている場合 (既定の動作)、データはステージングの場所に読み込まれます。これは、データフロー自体のみがアクセスできる内部 Lakehouse です。
ステージングの場所を使用すると、クエリを SQL 分析エンドポイントにフォールディング処理する方がメモリ処理よりも高速な場合に、パフォーマンスが向上する可能性があります。
Lakehouse またはその他の非倉庫の格納先にデータを読み込む場合、既定ではステージング機能を無効にしてパフォーマンスを向上させます。 データをデータの格納先に読み込むと、データはステージングを使用せずにデータの宛先に直接書き込まれます。 クエリにステージングを使用する場合は、もう一度有効にすることができます。
ステージングを有効にするには、クエリを右クリックし、[ステージングを有効にする] ボタンを選択してステージングを有効にします。 その後、クエリが青に変わります。
![[ステージングを有効にする] が強調された [クエリ] のドロップダウン メニューのスクリーンショット。](media/dataflow-gen2-data-destinations-and-managed-settings/disable-staging.png)
ウェアハウスにデータを読み込む
ウェアハウスにデータを読み込む場合は、データ格納先への書き込み操作の前にステージングが必要です。 この要件により、パフォーマンスが向上します。 現在、データフローと同じワークスペースへの読み込みのみがサポートされています。 ウェアハウスに読み込まれるすべてのクエリに対してステージングが有効になっていることを確認します。
ステージングが無効になっているときに、出力先にウェアハウスを選択すると、データ格納先を構成する前に、まずステージングを有効にするよう警告が表示されます。
![[データ保存先の追加] 警告のスクリーンショット。](media/dataflow-gen2-data-destinations-and-managed-settings/add-data-destination.png)
格納先に既にウェアハウスがあり、ステージングを無効にしようとすると、警告が表示されます。 その場合は格納先のウェアハウスを削除するか、ステージング アクションを無視します。
![[ステージングの有効化] 警告のスクリーンショット。](media/dataflow-gen2-data-destinations-and-managed-settings/enable-staging.png)
Lakehouse データの保存先のバキューム
Microsoft Fabric で Dataflow Gen2 の保存先として Lakehouse を使用する場合、最適なパフォーマンスと効率的なストレージ管理を確保するために定期的なメンテナンスを実行することが重要です。 重要なメンテナンス タスクの 1 つは、データの保存先をバキュームすることです。 このプロセスは、Delta テーブル ログから参照されなくなった古いファイルを削除し、ストレージ コストを最適化し、データの整合性を維持するのに役立ちます。
バキューム処理が重要な理由
- ストレージの最適化: 時間の経過と共に、Delta テーブルには不要になった古いファイルが蓄積されます。 バキューム処理は、これらのファイルをクリーンアップし、ストレージ領域を解放し、コストを削減するのに役立ちます。
- パフォーマンスの向上: 不要なファイルを削除すると、読み取り操作時にスキャンする必要があるファイル数が減り、クエリのパフォーマンスが向上します。
- データ整合性: 関連するファイルのみを保持することで、データ整合性が維持され、閲覧者のエラーやテーブルの破損につながる可能性のある、コミットされていないファイルに関する潜在的な問題を防ぐことができます。
データの保存先をバキュームする方法
Lakehouse で Delta テーブルをバキュームするには、次の手順を実行します。
- レイクハウスに移動する: Microsoft Fabric アカウントから、目的のレイクハウスに移動します。
- テーブルのメンテナンスにアクセスする: Lakehouse エクスプローラーで、保守するテーブルを右クリックするか、省略記号を使用してコンテキスト メニューにアクセスします。
- メンテナンス オプションを選択する: [メンテナンス] メニュー エントリを選択し、[バキューム] オプションを選択します。
- バキューム コマンドを実行する: 保持しきい値 (既定値は 7 日) を設定し、[今すぐ実行] を選択してバキューム コマンドを実行します。
ベスト プラクティス
- 保持期間: 古いスナップショットやコミットされていないファイルが途中で削除され、結果として、同時テーブル リーダーとライターが中断される可能性がありますが、そうならないように、少なくとも 7 日間の保持期間を設定してください。
- 定期メンテナンス: データ メンテナンス ルーチンの一部として定期的なバキューム処理をスケジュールし、Delta テーブルを最適化し、分析の準備を整えます。
データ メンテナンス戦略にバキューム処理を組み込むことで、レイクハウスの保存先の効率性、コスト効率、そしてデータフロー操作の信頼性を確保できます。
Lakehouse でのテーブル メンテナンスの詳細については、Delta テーブル メンテナンスのドキュメントを参照してください。
NULL 値の使用
null 許容列がある場合、Power Query によって null 非許容として検出される可能性があり、データ格納先に書き込むと、列の種類は null 非許容になります。 更新中に、次のエラーが発生します。
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
null 許容列を強制するには、次の手順を試してください。
データ格納先からテーブルを削除します。
データフローからデータ格納先を削除します。
次の Power Query コードを使用して、データフローに移動し、データ型を更新します。
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )データ格納先の追加
データ型の変換とアップスケーリング
データフロー内のデータ型が、以下のデータ変換先でサポートされているものと異なる場合は、データ変換先でデータを取得できるように、以下のいくつかの既定の変換が用意されています。
| 宛先 | データフロー データ型 | 変換先のデータ型 |
|---|---|---|
| Fabric Warehouse | Int8. の種類 | Int16. の種類 |