Copy アクティビティで Azure Synapse Analytics を構成する
この記事では、データ パイプラインでコピー アクティビティを使用して、Azure Synapse Analytics との間でデータをコピーする方法について説明します。
サポートされている構成
Copy アクティビティの下の各タブの構成については、それぞれ次のセクションを参照してください。
全般
[全般設定] タブを構成するには、全般設定のガイダンスを参照してください。
ソース
コピー アクティビティの [ソース] タブの Azure Synapse Analytics では、次のプロパティがサポートされています。
![[ソース] タブとプロパティのリストを示すスクリーンショット。](media/connector-azure-synapse-analytics/source.png#lightbox)
次のプロパティは必須です。
[データ ストアの種類]: [外部] を選択します。
[接続]: 接続リストから Azure Synapse Analytics の接続を選択します。 接続が存在しない場合は、[新規] を選択して新しい Azure Synapse Analytics 接続を作成します。
接続の種類: [Azure Synapse Analytics] を選択します。
クエリの使用: [テーブル]、[クエリ]、または [ストアド プロシージャ] を選択して、ソース データを読み取ることができます。 次の一覧で、各設定の構成について説明します。
テーブル: このボタンを選択した場合、上の [テーブル] で指定した表からデータを読み取ります。 ドロップダウン リストからテーブルを選択するか、[編集] を選択してスキーマとテーブル名を手動で入力します。

[クエリ]: カスタムの SQL クエリを使用してデータを読み取ります。 たとえば
select * from MyTableです。 または、鉛筆アイコンを選択してコード エディターで編集します。![[クエリ] が選択されていることを示すスクリーンショット。](media/connector-azure-synapse-analytics/query.png)
[ストアド プロシージャ]: ストアド プロシージャを使用してソース テーブルからデータを読み取ります。 最後の SQL ステートメントはストアド プロシージャの SELECT ステートメントにする必要があります。

- ストアド プロシージャ名: ストアド プロシージャを選択するか、[編集] を選択する場合はストアド プロシージャ名を手動で指定します。
- ストアド プロシージャのパラメーター: [パラメーターのインポート] を選択して、指定したストアド プロシージャにパラメーターをインポートするか、 [+ 新規] を選択してストアド プロシージャのパラメーターを追加します。 使用可能な値は、名前または値のペアです。 パラメーターの名前とその大文字と小文字は、ストアド プロシージャのパラメーターの名前とその大文字小文字と一致する必要があります。

[詳細設定] では、次のフィールドを指定できます。
[クエリ タイムアウト (分)]: クエリ コマンド実行時のタイムアウト時間を指定します。既定値は 120 分です。 このプロパティにパラメーターを設定する場合は、「02:00:00」(120 分) などの期間の値が使用できます。
[分離レベル]: SQL ソースのトランザクション ロック動作を指定します。 許可される値は、None、ReadCommitted、ReadUncommitted、RepeatableRead、Serializable、Snapshot のいずれかです。 指定しない場合は、[None] の分離レベルが使用されます。 詳細については、「IsolationLevel 列挙型」 を参照してください。
パーティション オプション: Azure Synapse Analyticsからのデータの読み込みに使用するデータ パーティション分割オプションを指定します。 使用できる値は、なし (既定値)、テーブルの物理パーティション、および動的範囲です。 パーティション オプションが有効になっている場合 (つまり、[なし] ではない場合)、Azure Synapse Analytics から同時にデータを読み込む並列処理の次数は、コピー アクティビティの [並列コピー] 設定によって制御されます。
[なし]: パーティションを使用しないようにするには、この設定を選択します。
テーブルの物理パーティション: 物理パーティションを使用する場合は、この設定を選択します。 パーティション列とメカニズムは、物理テーブル定義に基づいて自動的に決定されます。
[動的範囲]: 動的範囲パーティションを使用する場合は、この設定を選択します。 並列を有効にしたクエリを使用する場合は、範囲パーティション パラメーター (
?DfDynamicRangePartitionCondition) が必要です。 サンプル クエリ:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition。
- [パーティション列名]: 並列コピーの範囲パーティション分割で使用される整数型または日付/日時型 (
int、smallint、bigint、date、smalldatetime、datetime、datetime2またはdatetimeoffset) のソース列の名前を指定します。 指定しない場合、テーブルのインデックスまたは主キーが自動検出され、パーティション列として使用されます。 - [パーティションの上限]: パーティション範囲の分割に使用するパーティション列の最大値を指定します。 この値は、テーブル内の行のフィルター処理用ではなく、パーティションのストライドを決定するために使用されます。 テーブルまたはクエリ結果に含まれるすべての行がパーティション分割され、コピーされます。
- [パーティションの下限]: パーティション範囲の分割に使用するパーティション列の最小値を指定します。 この値は、テーブル内の行のフィルター処理用ではなく、パーティションのストライドを決定するために使用されます。 テーブルまたはクエリ結果に含まれるすべての行がパーティション分割され、コピーされます。
- [パーティション列名]: 並列コピーの範囲パーティション分割で使用される整数型または日付/日時型 (
[追加の列]: ソース ファイルの相対パスまたは静的な値を格納するための追加のデータ列を追加します。 後者では式がサポートされています。 詳細については、「コピー中に列を追加する」を参照してください。
宛先
コピー アクティビティの [コピー先] タブの Azure Synapse Analytics では、次のプロパティがサポートされています。
![[コピー先] タブを示すスクリーンショット。](media/connector-azure-synapse-analytics/destination.png)
次のプロパティは必須です。
- [データ ストアの種類]: [外部] を選択します。
- [接続]: 接続リストから Azure Synapse Analytics の接続を選択します。 接続が存在しない場合は、[新規] を選択して新しい Azure Synapse Analytics 接続を作成します。
- 接続の種類: [Azure Synapse Analytics] を選択します。
- テーブル オプション: [既存のものを使用する]、[テーブルの自動作成] を選択できます。 次の一覧で、各設定の構成について説明します。
- 既存を使用: ドロップダウン リストからデータベースのテーブルを選択します。 または、[編集] をチェックして、テーブル名を手動で入力します。
- テーブルの自動作成: ソース スキーマにテーブル (存在しない場合) が自動的に作成されます。
[詳細設定] では、次のフィールドを指定できます。
Copy メソッド データのコピーに使用する方法を選択します。 [Copy コマンド]、[PolyBase]、[一括挿入] または [アップサート] を選択できます。 次の一覧で、各設定の構成について説明します。
Copy コマンド: COPY ステートメントを使用して、Azure Storage から Azure Synapse Analytics または SQL プールにデータを読み込みます。
- コピー許可のコマンド: Copy コマンドを選択するときは、このコマンドの選択が必須になります。
- 既定値: Azure Synapse Analytics の各ターゲット列の既定値を指定します。 このプロパティの既定値により、データ ウェアハウスで設定されている DEFAULT 制約が上書きされます。ID 列に既定値を設定することはできません。
- 追加オプション: COPY ステートメントの "With" 句で、Azure Synapse Analytics の COPY ステートメントに直接渡される追加オプション。 COPY ステートメントの要件に合わせて、必要に応じて値を引用符で囲みます。
PolyBase: PolyBase は、高スループットのメカニズムです。 これを使用して、Azure Synapse Analytics または SQL プールに大量のデータを読み込みます。
- PolyBase を許可: PolyBase を選択する場合は、これが必須となります。
- 拒否の型: rejectValue オプションがリテラル値か割合かを指定します。 使用可能な値は、Value (既定値) と Percentage です。
- 拒否値: クエリが失敗するまでに拒否できる行の数または割合を指定します。 PolyBase の拒否オプションの詳細については、「CREATE EXTERNAL TABLE (Transact-SQL)」の「引数」セクションを参照してください。 使用可能な値は、0 (既定値)、1、2 などです。
- 拒否にサンプル値: 拒否された行の割合が PolyBase で再計算されるまでに取得する行数を決定します。 使用可能な値は、1、2 などです。拒否の種類として [パーセンテージ] を選択した場合、このプロパティは必須です。
- 型既定値の使用: PolyBase によってテキスト ファイルからデータが取得されるときに、区切りテキスト ファイル内の不足値を処理する方法を指定します。 このプロパティの詳細については、CREATE EXTERNAL FILE FORMAT (Transact-SQL) Arguments セクションをご覧ください。 使用できる値が選択されている (既定値) か、選択されていません。
一括挿入: 一括挿入を使用して、データをコピー先に一括で挿入します。

- 一括挿入テーブル ロック: これを使用すると、複数のクライアントからのインデックスがないテーブルで一括挿入操作中のコピーのパフォーマンスを向上させることができます。 BULK INSERT (Transact-SQL) に関するページを参照してください。
アップサート: データを宛先にアップサートする場合の書き込み動作の設定のグループを指定します。
キー列: ソースからの行がシンクからの行と一致しているかどうかを判断するために使用する列を選択します。
一括挿入テーブル ロック: これを使用すると、複数のクライアントからのインデックスがないテーブルで一括挿入操作中のコピーのパフォーマンスを向上させることができます。 BULK INSERT (Transact-SQL) に関するページを参照してください。
[事前コピー スクリプト]: 各実行でコピー先テーブルにデータを書き込む前に実行するコピー アクティビティのスクリプトを指定します。 このプロパティを使用して、事前に読み込まれたデータをクリーンアップできます。
[書き込みバッチ タイムアウト]: タイムアウトになるまでに一括挿入操作の完了を待つ時間です。許容される値は期間です。 既定値は「00:30:00」(30 分) です。
[書き込みバッチ サイズ]: SQL テーブルに挿入するバッチあたりの行数を指定します。 使用可能な値は integer (行数) です。 既定では行のサイズに基づいて、サービスにより適切なバッチ サイズが動的に決定されます。
[最大コンカレント接続数]: アクティビティの実行中にデータ ストアに対して確立できるコンカレント接続数の上限を指定します。 コンカレント接続を制限する場合にのみ、値を指定します。
[パフォーマンス メトリック分析を無効にする]: この設定は、コピー パフォーマンスの最適化と推奨事項のために、DTU、DWU、RU などのメトリックを収集するために使用します。 この動作に問題がある場合は、このチェック ボックスをオンにします。 既定では選択されていません。
COPY コマンドを使用した直接コピー
Azure Synapse Analytics の COPY コマンドでは、Azure Blob Storage と Azure Data Lake Storage Gen2 がソース データ ストアとして直接サポートされます。 ソース データがこのセクションで説明する条件を満たしている場合は、COPY ステートメントを使用してソース データ ストアから Azure Synapse Analytics に直接コピーします。
ソース データと形式では、次の種類と認証方法が使用されます。
サポートされるソース データ ストアの種類 サポートされる形式 サポートされる認証の種類 Azure Blob Storage 区切りテキスト
Parquet[匿名認証]
アカウント キー認証
Shared Access Signature 認証Azure Data Lake Storage Gen2 区切りテキスト
Parquetアカウント キー認証
Shared Access Signature 認証次の書式設定を設定できます。
- Parquet の場合: [圧縮の種類] が[なし]、[Snappy]、または [gzip] になります。
- DelimitedText の場合:
- 行区切り記号: 直接 COPY コマンドを介して区切りテキストを Azure Synapse Analytics にコピーする場合は、行区切り記号を明示的に指定します (\r; \n; または \r\n)。 ソース ファイルの行区切り記号が \r\n である場合にのみ、既定値 (\r、\n、または \r\n) が機能します。 それ以外の場合は、シナリオのステージングを有効にします。
- null 値が既定値のままか、空の文字列 ("") に設定されている。
- エンコードが既定値のままか、UTF-8 または UTF-16 に設定されている。
- スキップ行数 が既定値のままか、0 に設定されている。
- 圧縮の種類が [なし] または [gzip] である。
ソースがフォルダーの場合は、[再帰的] チェック ボックスをオンにする必要があります。
[最終更新日時でフィルター処理] の開始時間 (UTC) および終了時間 (UTC) では、[プレフィックス]、[パーティション検出を有効にする]、および [追加の列] は指定されません。
COPY コマンドを使用して Azure Synapse Analytics にデータを取り込む方法については、こちらの記事を参照してください。
ソース データ ストアと形式が、本来は COPY コマンドでサポートされていない形式の場合は、代わりに COPY コマンドを使用したステージング コピーを使います。 データを COPY コマンド互換形式に自動的に変換し、COPY コマンドを呼び出して、データを Azure Synapse Analytics に読み込みます。
マッピング
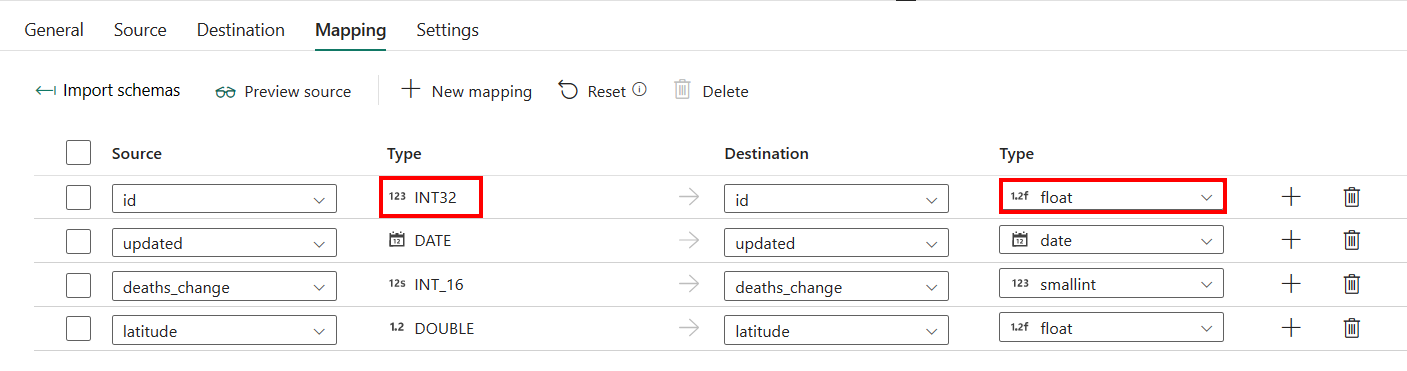
[マッピング] タブの構成で、コピー先として自動作成テーブルで Azure Synapse Analytics を適用しない場合は、[マッピング] に移動します。
[マッピング] の構成を除き、コピー先として自動作成テーブルで Azure Synapse Analytics を適用する場合は、コピー先列の型を編集できます。 [スキーマのインポート] を選択した後、コピー先で列の種類を指定できます。
たとえば、ソースの ID 列の型は int ですが、コピー先列にマッピングするときには float 型に変更できます。
設定
[設定] タブの構成については、「[設定] タブで他の設定を構成する」を参照してください。
Azure Synapse Analytics からの並列コピー
Azure Synapse Analytics コネクタでは、コピー アクティビティの際に、データを並列でコピーするための組み込みのデータ パーティション分割が提供されます。 データ パーティション分割オプションは、コピー アクティビティの [ソース] タブにあります。
パーティション分割されるコピーを有効にすると、コピー アクティビティによって Azure Synapse Analytics ソースに対する並列クエリが実行され、パーティションごとにデータが読み込まれます。 並列処理の次数は、Copy アクティビティの設定タブの [コピーの並列処理] によって制御されます。たとえば、並列処理の次数を 4 に設定した場合、指定したパーティション オプションと設定に基づいて 4 つのクエリが同時に生成され、実行されます。各クエリでは、Azure Synapse Analytics からデータの一部を取得します。
Azure Synapse Analytics から大量のデータを読み込む場合は特に、データ パーティション分割を行う並列コピーを有効にすることが推奨されます。 さまざまなシナリオの推奨構成を以下に示します。 ファイルベースのデータ ストアにデータをコピーする場合は、複数のファイルとしてフォルダーに書き込む (フォルダー名のみを指定する) ことをお勧めします。この場合、1 つのファイルに書き込むよりもパフォーマンスが優れています。
| シナリオ | 推奨設定 |
|---|---|
| 物理パーティションに分割された大きなテーブル全体から読み込む。 | パーティション オプション: テーブルの物理パーティション。 実行中に、サービスによって物理パーティションが自動的に検出され、パーティションごとにデータがコピーされます。 テーブルに物理パーティションがあるかどうかを確認するには、こちらのクエリを参照してください。 |
| 物理パーティションがなく、データ パーティション分割用の整数または日時の列がある大きなテーブル全体から読み込む。 | パーティション オプション: 動的範囲パーティション。 パーティション列 (省略可能):データのパーティション分割に使用される列を指定します。 指定されていない場合は、インデックスまたは主キー列が使用されます。 パーティションの上限とパーティションの下限 (省略可能):パーティションのストライドを決定する場合に指定します。 これは、テーブル内の行のフィルター処理用ではなく、テーブル内のすべての行がパーティション分割されてコピーされます。 指定されていない場合は、Copy アクティビティによって値が自動検出されます。 たとえば、パーティション列「ID」の値の範囲が 1 ~ 100 で、下限を 20 に、上限を 80 に設定し、並列コピーを 4 にした場合、サービスによって 4 つのパーティションでデータが取得されます。ID の範囲は、それぞれ、20 以下、21 ~ 50、51 ~ 80、81 以上となります。 |
| 物理パーティションがなく、データ パーティション分割用の整数列または日付/日時列がある大量のデータを、カスタム クエリを使用して読み込む。 | パーティション オプション: 動的範囲パーティション。 クエリ: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>パーティション列: データのパーティション分割に使用される列を指定します。 パーティションの上限とパーティションの下限 (省略可能):パーティションのストライドを決定する場合に指定します。 これは、テーブル内の行のフィルター処理用ではなく、クエリ結果のすべての行がパーティション分割されてコピーされます。 指定されていない場合は、Copy アクティビティによって値が自動検出されます。 たとえば、パーティション列「ID」の値の範囲が 1 ~ 100 で、下限を 20 に、上限を 80 に設定し、並列コピーを 4 にした場合、サービスによって 4 つのパーティションでデータが取得されます。ID の範囲は、それぞれ、20 以下、21 ~ 50、51 ~ 80、81 以上となります。 さまざまなシナリオのサンプル クエリを次に示します。 • テーブル全体に対してクエリを実行する: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• 列の選択と追加の where 句フィルターが含まれるテーブルからのクエリ: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• サブクエリを使用したクエリ: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• サブクエリにパーティションがあるクエリ: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
パーティション オプションを使用してデータを読み込む場合のベスト プラクティス:
- データ スキューを回避するため、パーティション列 (主キーや一意キーなど) には特徴のある列を選択します。
- テーブルに組み込みパーティションがある場合は、パフォーマンスを向上させるためにパーティション オプションとして "テーブルの物理パーティション" を使用します。
- Azure Synapse Analytics では、最大で 32 個のクエリを実行でき、「コピーの並列度」を高く設定しすぎると、Synapse の調整の問題が発生する可能性があります。
物理パーティションを確認するためのサンプル クエリ
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
テーブルに物理パーティションがある場合、"HasPartition" は "yes" と表示されます。
表の概要
次の表には、Azure Synapse Analytics のコピー アクティビティの詳細が示されています。
ソース
| 名前 | Description | Value | 必須 | JSON スクリプト プロパティ |
|---|---|---|---|---|
| データ ストアの種類 | データ ストアの種類。 | 外部品目番号 | はい | / |
| 接続 | ソース データ ストアへの実際の接続。 | <実際の接続> | はい | つながり |
| 接続の種類 | ソース接続の種類。 | Azure Synapse Analytics | はい | / |
| [クエリの使用] | データを読み取る方法。 | • テーブル • クエリ • ストアド プロシージャ |
はい | • typeProperties (typeProperties ->source)- スキーマ - テーブル • sqlReaderQuery • sqlReaderStoredProcedureName storedProcedureParameters - name - 値 |
| クエリ タイムアウト | クエリ コマンドの実行のタイムアウト (既定値は 120 分)。 | TimeSpan | いいえ | queryTimeout |
| 分離レベル | SQL ソースのトランザクション ロック動作。 | • なし • コミットされたものを読み取る • コミットされていないものを読み取る • 反復可能な読み取り • Serializable • Snapshot |
いいえ | isolationLevel: • ReadCommitted • ReadUncommitted • RepeatableRead • Serializable • Snapshot |
| パーティション オプション | Azure SQL データベースからのデータの読み込みに使用されるデータ パーティション分割オプション。 | • なし • テーブルの物理パーティション • 動的範囲 - パーティション列名 - パーティション上限 - パーティション下限 |
いいえ | partitionOption: • PhysicalPartitionsOfTable • DynamicRange partitionSettings: - partitionColumnName - partitionUpperBound - partitionLowerBound |
| 追加の列 | ソース ファイルの相対パスまたは静的値を格納するための追加のデータ列を追加します。 後者では式がサポートされています。 | • 名前 • 値 |
いいえ | additionalColumns: •名前 • value |
宛先
| 名前 | Description | Value | 必須 | JSON スクリプト プロパティ |
|---|---|---|---|---|
| データ ストアの種類 | データ ストアの種類。 | 外部品目番号 | はい | / |
| 接続 | コピー先データ ストアへの接続。 | <実際の接続> | はい | つながり |
| 接続の種類 | コピー先の接続の種類。 | Azure Synapse Analytics | はい | / |
| テーブル オプション | コピー先のデータ テーブル オプション。 | • 既存のものを使用 • テーブルの自動作成 |
はい | • typeProperties (typeProperties ->sink)- スキーマ - テーブル • tableOption: • autoCreate • typeProperties ( typeProperties ->sink)- スキーマ - テーブル |
| Copy メソッド | データのコピーに使用される メソッド。 | • Copy コマンド • PolyBase • 一括挿入 • [Upsert](アップサート) |
いいえ | / |
| コピー コマンドを選択する場合 | COPY ステートメントを使用して、Azure Storage から Azure Synapse Analytics または SQL プールにデータを読み込みます。 | / | 不正解です。 COPY を使用する場合に適用します。 |
allowCopyCommand: true copyCommandSettings |
| 既定値 | Azure Synapse Analytics の各ターゲット列の既定値を指定します。 このプロパティの既定値により、データ ウェアハウスで設定されている DEFAULT 制約が上書きされます。ID 列に既定値を設定することはできません。 | < 既定値 > | いいえ | defaultValues: - columnName - defaultValue |
| その他のオプション | COPY ステートメントの "With" 句で、Azure Synapse Analytics の COPY ステートメントに直接渡される追加オプション。 COPY ステートメントの要件に合わせて、必要に応じて値を引用符で囲みます。 | < 追加のオプション > | いいえ | additionalOptions - <プロパティ名> : <値> |
| PolyBase を選択する場合 | PolyBase は、高スループットのメカニズムです。 これを使用して、Azure Synapse Analytics または SQL プールに大量のデータを読み込みます。 | / | 不正解です。 PolyBase を使用する場合に適用します。 |
allowPolyBase: true polyBaseSettings |
| 拒否型 | 拒否値の型。 | • 値 • パーセンテージ |
いいえ | rejectType: - 値 - パーセンテージ |
| 拒否値 | クエリが失敗するまでに拒否できる行の数または割合を指定します。 | 0 (既定値), 1, 2, など | いいえ | rejectValue |
| 拒否のサンプル値 | 拒否された行の割合が PolyBase で再計算されるまでに取得する行数を決定します。 | 1、2 など。 | 拒否型として パーセンテージ を指定する場合は Yes | rejectSampleValue |
| 型既定値の使用 | PolyBase によってテキスト ファイルからデータが取得されるときに、区切りテキスト ファイル内の不足値を処理する方法を指定します。 このプロパティの詳細については、CREATE EXTERNAL FILE FORMAT (Transact-SQL) の [引数] のセクションを参照してください | オン (既定値) またはオフ。 | いいえ | useTypeDefault: true (既定値) または false |
| [一括挿入] を選択する場合 | コピー先にデータを一括で挿入します。 | / | いいえ | writeBehavior: Insert |
| 一括挿入テーブル ロック | これを使用すると、複数のクライアントからのインデックスがないテーブルで一括挿入操作中のコピーのパフォーマンスを向上させることができます。 BULK INSERT (Transact-SQL) に関するページを参照してください。 | 選択または非選択 (既定値) | いいえ | sqlWriterUseTableLock: true または false (既定値) |
| [アップサート] を選択する場合 | コピー先にデータをアップサートする場合の書き込み動作の設定のグループを指定します。 | / | いいえ | writeBehavior: Upsert |
| キー列 | ソースの行がコピー先の行と一致するかどうかを判断するために使用される列を示します。 | < 列名> | いいえ | upsertSettings: - キー: < 列名 > - interimSchemaName |
| 一括挿入テーブル ロック | これを使用すると、複数のクライアントからのインデックスがないテーブルで一括挿入操作中のコピーのパフォーマンスを向上させることができます。 BULK INSERT (Transact-SQL) に関するページを参照してください。 | 選択または非選択 (既定値) | いいえ | sqlWriterUseTableLock: true または false (既定値) |
| コピー前スクリプト | 各実行でコピー先テーブルにデータを書き込む前に実行するコピー アクティビティのスクリプト。 このプロパティを使用して、事前に読み込まれたデータをクリーンアップできます。 | <事前コピー スクリプト> (文字列) |
いいえ | preCopyScript |
| [書き込みバッチ タイムアウト] | タイムアウトするまでに一括挿入操作の完了を待つ時間です。許容される値は期間です。 既定値は「00:30:00」(30 分) です。 | TimeSpan | いいえ | writeBatchTimeout |
| [Write batch size](書き込みバッチ サイズ) | SQL テーブルに挿入するバッチあたりの行数。 既定では行のサイズに基づいて、サービスにより適切なバッチ サイズが動的に決定されます。 | <行の数> (整数) |
いいえ | writeBatchSize |
| 最大コンカレント接続数 | アクティビティの実行中にデータ ストアに対して確立されたコンカレント接続数の上限。 コンカレント接続を制限する場合にのみ、値を指定します。 | <コンカレント接続数の上限> (整数) |
いいえ | maxConcurrentConnections |
| パフォーマンス メトリック分析を無効にする | この設定は、コピー パフォーマンスの最適化と推奨事項のために、DTU、DWU、RU などのメトリックを収集するために使用されます。 この動作に問題がある場合は、このチェック ボックスをオンにします。 | オン (既定値) またはオフ | いいえ | disableMetricsCollection: true または false (既定値) |