コピー アクティビティで Azure Database for PostgreSQL を構成する
この記事では、データ パイプラインのコピー アクティビティを使用して、Azure Database for PostgreSQL との間でデータをコピーする方法について説明します。
サポートされている構成
コピー アクティビティの下の各タブの構成については、それぞれ次のセクションを参照してください。
全般
全般 設定 ガイダンスを参照して、全般 設定タブを構成します。
ソース
[ソース] タブに移動して、コピー アクティビティのソースを構成します。 詳細な構成については、次の内容を参照してください。
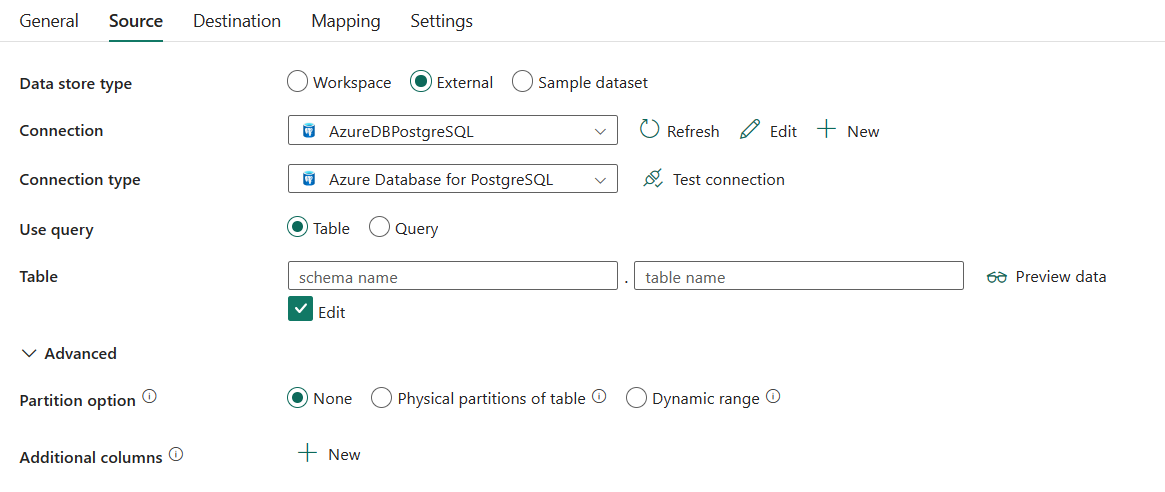
次の 3 つのプロパティが必要です。
- 接続: 接続の一覧から Azure Database for PostgreSQL 接続を選択します。 接続が存在しない場合は、新しい Azure Database for PostgreSQL 接続を作成します。
- 接続の種類: Azure Database for PostgreSQLを選択します。
クエリ を使用する:テーブル を選択して指定したテーブルからデータを読み取るか、クエリ選択してクエリを使用してデータを読み取ります。 テーブル を選択する場合:
[テーブル]: ドロップダウン リストからテーブルを選択するか、[手動で入力] を選択し手動で入力してデータを読み取ります。

クエリを選択した場合:
クエリ: データを読み取るカスタム SQL クエリを指定します。 例:
SELECT * FROM mytableまたはSELECT * FROM "MyTable"。手記
PostgreSQL では、引用符で囲まれていない場合、エンティティ名は大文字と小文字が区別されません。

[詳細設定 で、次のフィールドを指定できます。
クエリタイムアウト (分): コマンドの実行を終了してエラーを生成するまでの待機時間を指定します。既定値は 120 分です。 このプロパティにパラメーターが設定されている場合、使用できる値は"02:00:00" (120 分) などの期間です。 詳細については、「CommandTimeout」を参照してください。
パーティション オプション: Azure Database for PostgreSQL からデータを読み込む際に使用するデータ パーティション分割オプションを指定します。 パーティション オプションが有効になっている場合 (つまり、なしではない場合)、Azure Database for PostgreSQL から同時にデータを読み込む並列処理の次数は、[コピー アクティビティの設定] タブの コピー並列処理の によって制御されます。
[なし]
選択した場合は、パーティションを使用しないことを選択します。 テーブルの物理パーティション
選択した場合: パーティション名: コピーする必要がある物理パーティションの一覧を指定します。
クエリを使用してソース データを取得する場合は、WHERE 句で
?AdfTabularPartitionNameフックします。 例については、「Azure Database for PostgreSQL からの並列コピー 」セクションを参照してください。
[ダイナミック レンジ] を選択した場合:
パーティション列名 : 整数または日付/日時型として、並列コピーの範囲パーティション分割 で使用されるソース列の名前を指定してください ( 、 、 、 、 、 、または )。 指定しない場合、テーブルの主キーが自動検出され、パーティション列として使用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で
?AdfRangePartitionColumnNameフックします。 例については、「Azure Database for PostgreSQL からの並列コピー」セクションを参照してください。 パーティションの上限: データをコピーするパーティション列の最大値を指定します。
クエリを使用してソース データを取得する場合は、WHERE 句で
?AdfRangePartitionUpboundフックします。 例については、「Azure Database for PostgreSQL からの並列コピー」セクションを参照してください。 . パーティション下限: データをコピーするパーティション列の最小値を指定します。
クエリを使用してソース データを取得する場合は、WHERE 句で
?AdfRangePartitionLowboundフックします。 例については、「Azure Database for PostgreSQL からの並列コピー」セクションを参照してください。 
追加の列: ソース ファイルの相対パスまたは静的な値を格納する追加のデータ列を追加します。 後者では式がサポートされています。
行き先
の [コピー先] タブに移動して、コピー アクティビティの宛先を構成します。 詳細な構成については、次の内容を参照してください。
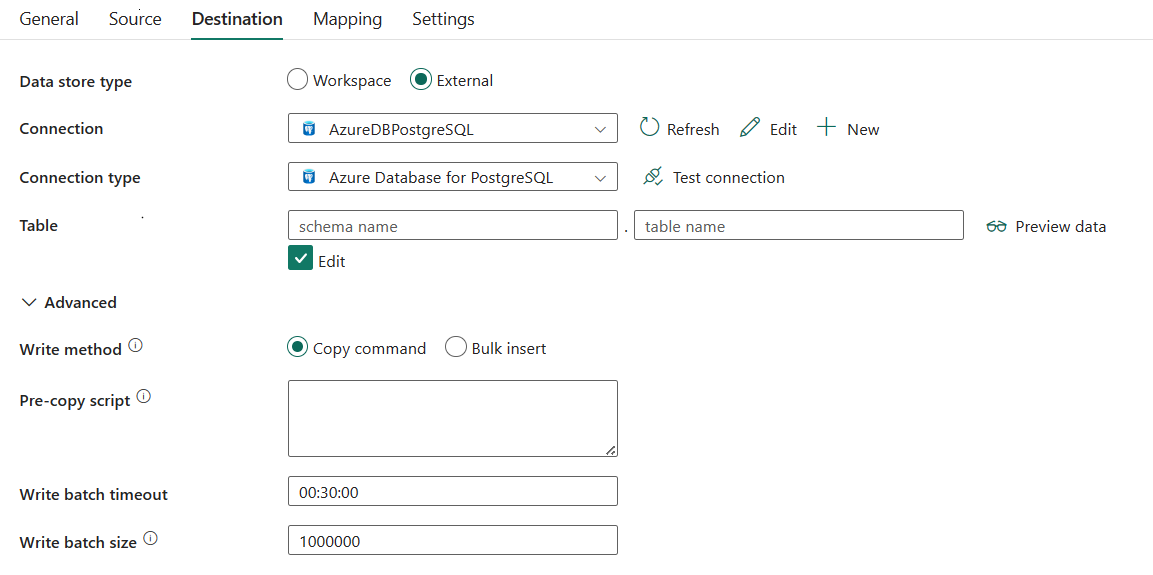
次の 3 つのプロパティが必要です:
- 接続: 接続の一覧から Azure Database for PostgreSQL 接続を選択します。 接続が存在しない場合は、新しい Azure Database for PostgreSQL 接続を作成します。
- 接続の種類: Azure Database for PostgreSQLを選択します。
- テーブル: ドロップダウンリストからテーブルを選択するか、[手動で入力] を選んでデータを書き込むためにエントリーします。
[詳細設定 で、次のフィールドを指定できます。
書き込み方法: Azure Database for PostgreSQL にデータを書き込む方法を選択します。 [コマンドをコピー] (既定。よりパフォーマンスが高い) または [一括挿入] を選択します。
コピー前スクリプトの: 各実行で Azure Database for PostgreSQL にデータを書き込む前に実行するコピー アクティビティの SQL クエリを指定します。 このプロパティを使用して、事前に読み込まれたデータをクリーンアップできます。
バッチの書き込みタイムアウト: バッチ挿入操作がタイムアウトするまでの待機時間を指定します。使用できる値は timespan です。 既定値は 00:30:00 (30 分) です。
書き込みバッチ サイズ: バッチごとに Azure Database for PostgreSQL に読み込まれる行の数を指定します。 使用できる値は、行数を表す整数です。 既定値は 1,000,000 です。
マッピング
[マッピング] タブの構成については、「[マッピング] タブでマッピングを構成する」をご覧ください。
設定
設定 タブの構成については、設定タブのの下で他の設定を構成するに移動します。
Azure Database for PostgreSQL からの並列コピー
コピー アクティビティの Azure Database for PostgreSQL コネクタでは、データを並列にコピーするための組み込みのデータ パーティション分割が提供されます。 データのパーティション分割オプションは、コピー アクティビティの [ソース] タブにあります。
パーティション分割コピーを有効にすると、コピー アクティビティによって Azure Database for PostgreSQL ソースに対して並列クエリが実行され、パーティションごとにデータが読み込まれます。 並列度は、[コピー アクティビティの設定] タブで
特に Azure Database for PostgreSQL から大量のデータを読み込む場合は、データ パーティション分割を使用して並列コピーを有効にすることをお勧めします。 さまざまなシナリオで推奨される構成を次に示します。 ファイル ベースのデータ ストアにデータをコピーする場合は、フォルダーに複数のファイルとして書き込む (フォルダー名のみを指定する) ことをお勧めします。この場合、パフォーマンスは 1 つのファイルに書き込むよりも優れています。
| シナリオ | 推奨される設定 |
|---|---|
| 物理パーティションに分割された大きなテーブル全体から読み込む。 | パーティション オプション: テーブルの物理パーティション。 実行中、サービスは物理パーティションを自動的に検出し、パーティションごとにデータをコピーします。 |
| 物理パーティションがなく、データ パーティション分割用の整数列がある大きなテーブル全体から読み込む。 | パーティションオプション:ダイナミックレンジ。 パーティション列の: データのパーティション分割に使用する列を指定します。 指定しない場合は、主キー列が使用されます。 |
| カスタム クエリを使用して、物理パーティションで大量のデータを読み込みます。 | パーティション オプション: テーブルの物理パーティション。 クエリ: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.パーティション名: データのコピー元のパーティション名を指定します。 指定しない場合、サービスは PostgreSQL データセットで指定したテーブルの物理パーティションを自動的に検出します。 実行中、サービスは ?AdfTabularPartitionName を実際のパーティション名に置き換え、Azure Database for PostgreSQL に送信します。 |
| データパーティション分割用の整数列を使用しながら、物理パーティションを使用せずにカスタム クエリを使用して大量のデータを読み込みます。 | パーティションオプション:ダイナミックレンジ。 クエリ: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>パーティション列の: データのパーティション分割に使用する列を指定します。 整数または日付/日時データ型の列に対してパーティション分割することができます。 パーティションの上限 と パーティションの下限: パーティション列に対してフィルター処理して、下限と上限の範囲の間でのみデータを取得するかどうかを指定します。 実行中、サービスは、 ?AdfRangePartitionColumnName、?AdfRangePartitionUpbound、および ?AdfRangePartitionLowbound を各パーティションの実際の列名と値の範囲に置き換え、Azure Database for PostgreSQL に送信します。 たとえば、パーティション列 "ID" が下限を 1 に、上限が 80 に設定され、並列コピーが 4 に設定されている場合、サービスは 4 つのパーティションでデータを取得します。 ID はそれぞれ[1,20]、[21,40]、[41,60]、[61,80]の間です。 |
パーティション オプションを使用してデータを読み込むベスト プラクティス:
- データスキューを回避するために、パーティション列として固有の列 (主キーや一意キーなど) を選択します。
- テーブルに組み込みのパーティションがある場合は、パフォーマンスを向上させるためにパーティション オプション "テーブルの物理パーティション" を使用します。
テーブルの概要
次の表に、Azure Database for PostgreSQL のコピー アクティビティの詳細を示します。
ソース情報
| 名前 | 説明 | 価値 | 必須 | JSON スクリプト プロパティ |
|---|---|---|---|---|
| 接続 | ソース データ ストアへの接続。 | < ユーザーの Azure Database for PostgreSQL 接続 > | はい | connection |
| 接続の種類 | ソース接続の種類。 | PostgreSQL 用 Azure データベース | はい | / |
| クエリ を使用する | データを読み取る方法。 テーブル を適用して指定したテーブルからデータを読み取るか、クエリ クエリ を適用してクエリを使用してデータを読み取ります。 | • [テーブル] • [クエリ] |
はい | • typeProperties (typeProperties ->source)- スキーマ - テーブル •クエリ |
| クエリタイムアウト時間 (分) | コマンドの実行を終了してエラーを生成するまでの待機時間。既定値は 120 分です。 このプロパティにパラメーターが設定されている場合、使用できる値は"02:00:00" (120 分) などの期間です。 詳細については、「CommandTimeout」を参照してください。 | 時間範囲 | いいえ | queryTimeout |
| パーティション名 | コピーする必要がある物理パーティションの一覧。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfTabularPartitionName フックします。 |
< ユーザーのパーティション名 > | いいえ | partitionNames |
| パーティション列名 | 並列コピーのための範囲パーティション分割に使用される、整数型または日付/日時型の |
< ユーザーのパーティション列名 > | いいえ | partitionColumnName |
| パーティションの上限 | データをコピーするパーティション列の最大値。クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionUpbound フックします。 |
< パーティション上限 > | いいえ | partitionUpperBound |
| パーティションの下限 | データをコピーするパーティション列の最小値。クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionLowbound フックします。 |
< ユーザーのパーティションの下限 > | いいえ | partitionLowerBound |
| 追加の列 | ソース ファイルの相対パスまたは静的値を格納するデータ列を追加します。 後者では式がサポートされています。 | •名前 •価値 |
いいえ | additionalColumns: •名前 •価値 |
宛先情報
| 名前 | 説明 | 価値 | 必須 | JSON スクリプト プロパティ |
|---|---|---|---|---|
| 接続 | コピー先データ ストアへの接続。 | < ユーザーの Azure Database for PostgreSQL 接続 > | はい | connection |
| 接続の種類 | 接続先の種類。 | PostgreSQL 用 Azure データベース | はい | / |
| テーブル | データを書き込む対象のデータ テーブル。 | < 宛先テーブルの名前 > | はい | typeProperties (typeProperties ->sinkの下):- スキーマ - テーブル |
| 書き込み方法 | Azure Database for PostgreSQL にデータを書き込むためのメソッド。 | • コピー コマンド (デフォルト) • 一括挿入 |
いいえ | 書き込みメソッド: • CopyCommand • BulkInsert |
| コピー前スクリプト | 各実行で Azure Database for PostgreSQL にデータを書き込む前に実行するコピー アクティビティの SQL クエリ。 このプロパティを使用して、事前に読み込まれたデータをクリーンアップできます。 | < ユーザーの事前コピー スクリプト > | いいえ | preCopyScript |
| バッチ タイムアウト を書き込む | バッチ挿入操作が終了してからタイムアウトするまでの待機時間。 | timespan (既定値は 00:30:00 - 30 分) |
いいえ | writeBatchTimeout |
| バッチサイズを書き込む | バッチごとに Azure Database for PostgreSQL に読み込まれる行の数。 | 整数 (既定値は 1,000,000) |
いいえ | writeBatchSize |