ノートブックを使用してレイクハウスにデータを読み込む
このチュートリアルでは、ノートブックを使用して Fabric レイクハウス内のデータを読み書きする方法について説明します。 この目標を達成するために、Fabric では Spark API と Pandas API がサポートされます。
Apache Spark API を使用してデータを読み込む
ノートブックの [コード] セルで、次のコード例を使用してソースからデータを読み取り、レイクハウスの [ファイル]、[テーブル]、または両方のセクションに読み込みます。
読み取る場所は、データが現在のノートブックの既定のレイクハウスからの場合は相対パスを使用して指定できます。 または、データが別のレイクハウスからの場合は、絶対 Azure BLOB ファイル システム (ABFS) パスを使用できます。 データのコンテキスト メニューからこのパスをコピーします。
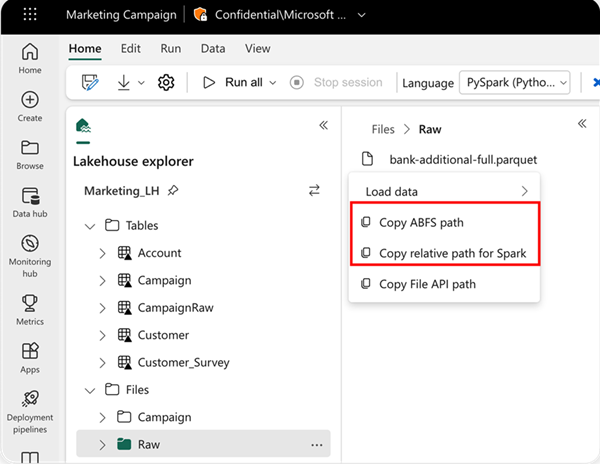
[Copy ABFS path] (ABFS パスのコピー): このオプションは、ファイルの絶対パスを返します。
[Copy relative path for Spark] (Spark の相対パスのコピー): このオプションは、既定のレイクハウス内のファイルの相対パスを返します。
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Pandas API を使用してデータを読み込む
Pandas API をサポートするために、デフォルトのレイクハウスがノートブックに自動的にマウントされます。 マウント ポイントは "/lakehouse/default/" です。 このマウント ポイントを使用して、既定のレイクハウスとの間でデータの読み取り/書き込みを行うことができます。 コンテキスト メニューの [Copy File API Path] (ファイル API パスのコピー) オプションは、そのマウント ポイントからファイル API パスを返します。 [Copy ABFS path] (ABFS パスのコピー) オプションから返されるパスは、Pandas API でも機能します。
![[Copy File API Path] (ファイル API パスのコピー) のメニュー オプションを示すスクリーンショット。](media/lakehouse-notebook-explore/copy-path-menu-file-path.png)
[Copy File API Path] (ファイル API パスのコピー) :このオプションは、 デフォルトのレイクハウスのマウント ポイントの下のパスを返します。
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
ヒント
Spark API の場合は、[Copy ABFS path] (ABFS パスのコピー) または [Copy relative path for Spark] (Spark の相対パスのコピー) オプションを使用してファイルのパスを取得してください。 Pandas API の場合は、[Copy ABFS path] (ABFS パスのコピー) または [Copy File API path] (ファイル API パスのコピー) オプションを使用してファイルのパスを取得してください。
Spark API または Pandas API を操作するコードを使用する最も簡単な方法は、[データの読み込み] オプションを使用し、使用する API を選択することです。 コードは、ノートブックの新しいコード セルに自動的に生成されます。
![[データの読み込み] オプションを選択する場所を示すスクリーンショット。](media/lakehouse-notebook-explore/load-data-menu.png#lightbox)