Livy API を使用して Livy バッチ ジョブを送信、実行する
Note
Livy API for Fabric Data Engineering はプレビュー段階です。
適用対象:✅ Microsoft Fabric でのデータ エンジニアリングとデータ サイエンス
Livy API for Fabric Data Engineering を使用して Spark バッチ ジョブを送信します。
前提条件
Jupyter Notebooks、PySpark、Microsoft Authentication Library (MSAL) for Python を備えた Visual Studio Code などのリモート クライアント。
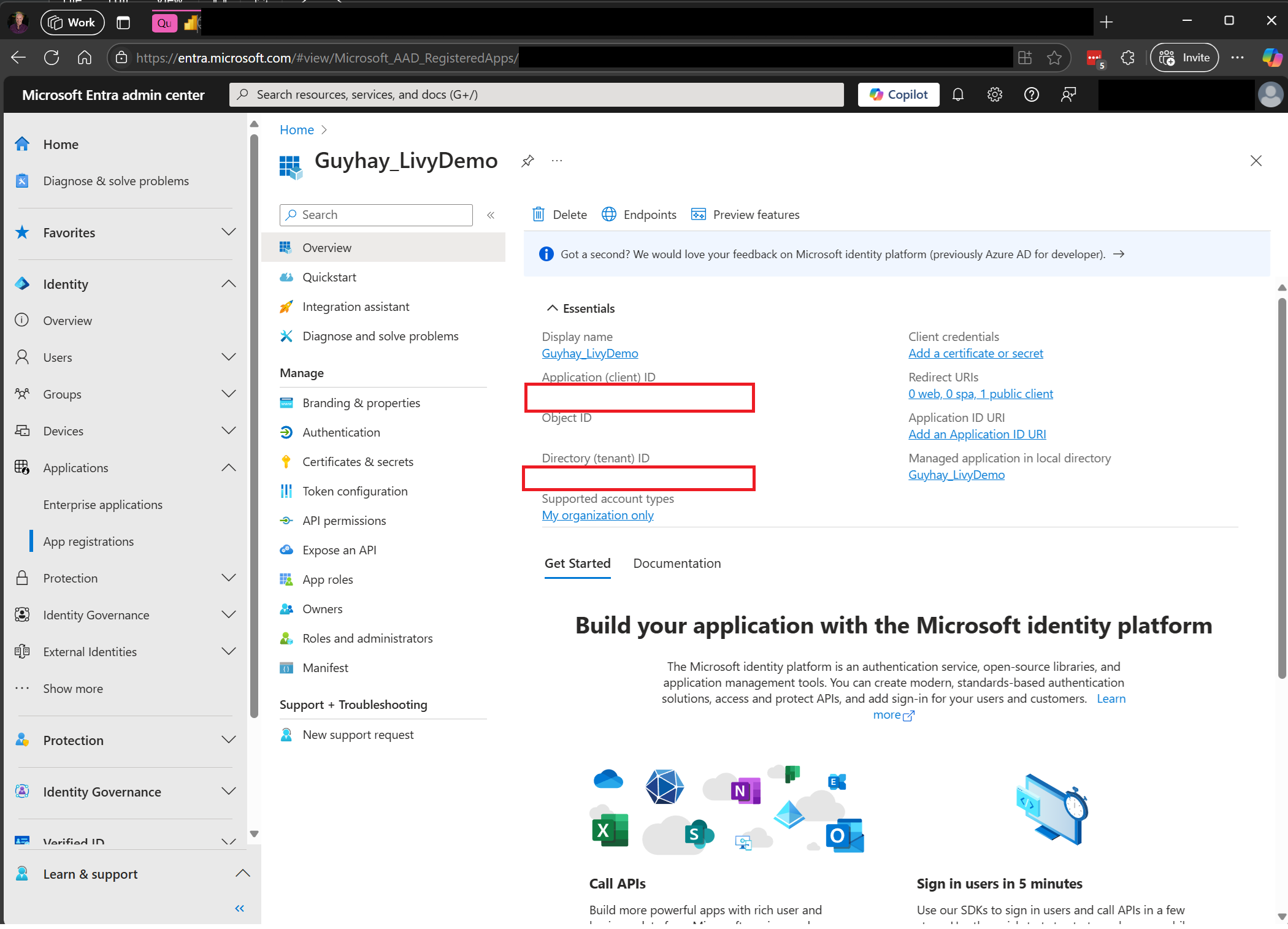
Fabric REST API にアクセスする場合は、Microsoft Entra アプリ トークン。 Microsoft ID プラットフォームにアプリケーションを登録する。
レイクハウス内のデータ。この例では、NYC Taxi & Limousine Commission の green_tripdata_2022_08 (レイクハウスに読み込まれた parquet ファイル) を使用します。
Livy API は、操作用に統合エンドポイントを定義します。 この記事の例に沿って進める際は、プレースホルダー {Entra_TenantID}、{Entra_ClientID}、{Fabric_WorkspaceID}、{Fabric_LakehouseID} を適切な値に置き換えてください。
Livy API バッチの Visual Studio Code を構成する
Fabric Lakehouse で [Lakehouse の設定] を選択します。

[Livy エンドポイント] セクションに移動します。
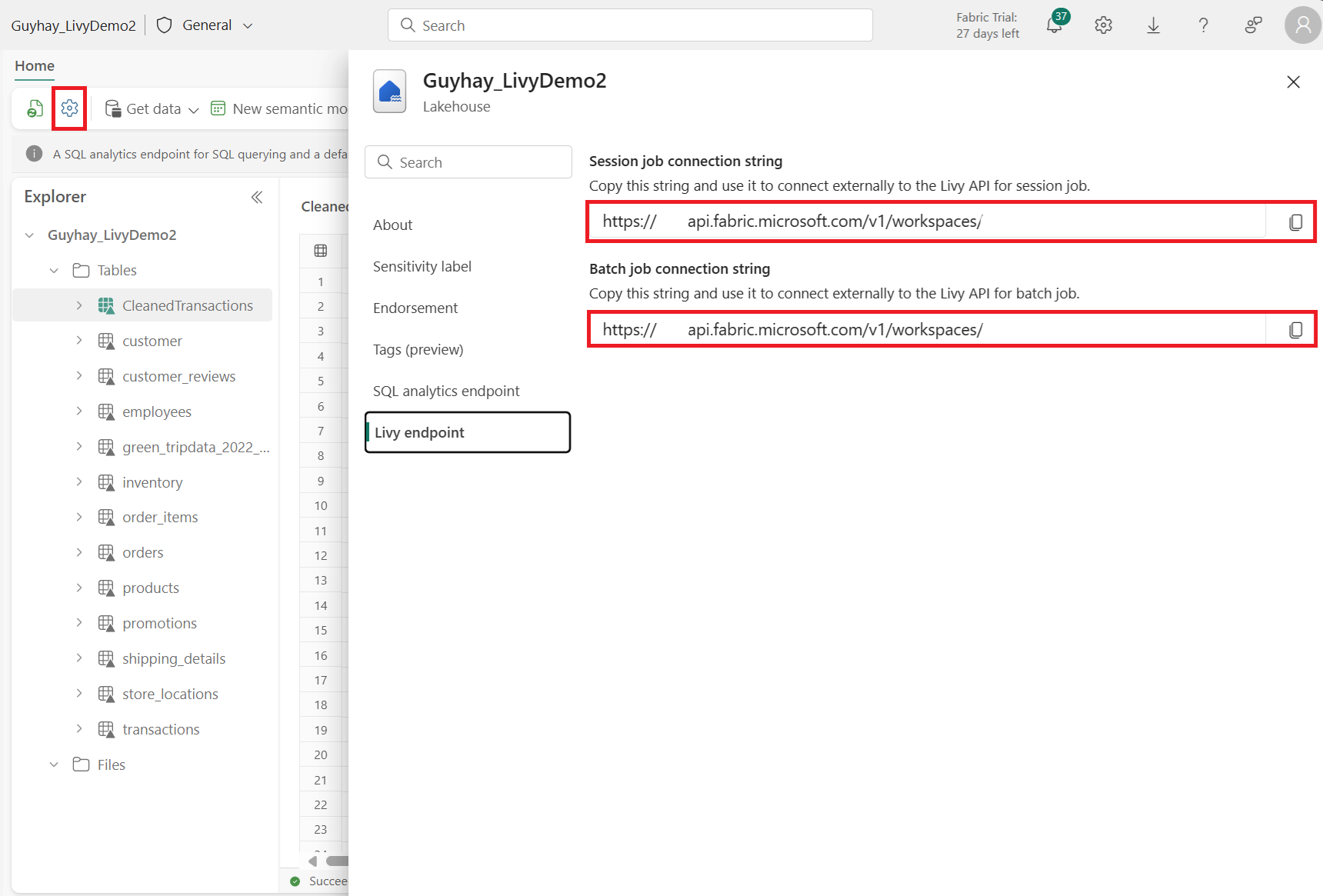
バッチ ジョブ接続文字列 (画像の 2 番目の赤いボックス) をコードにコピーします。
Microsoft Entra 管理センターに移動し、アプリケーション (クライアント) ID とディレクトリ (テナント) ID の両方をコードにコピーします。



Spark ペイロードを作成して Lakehouse にアップロードする
Visual Studio Code で
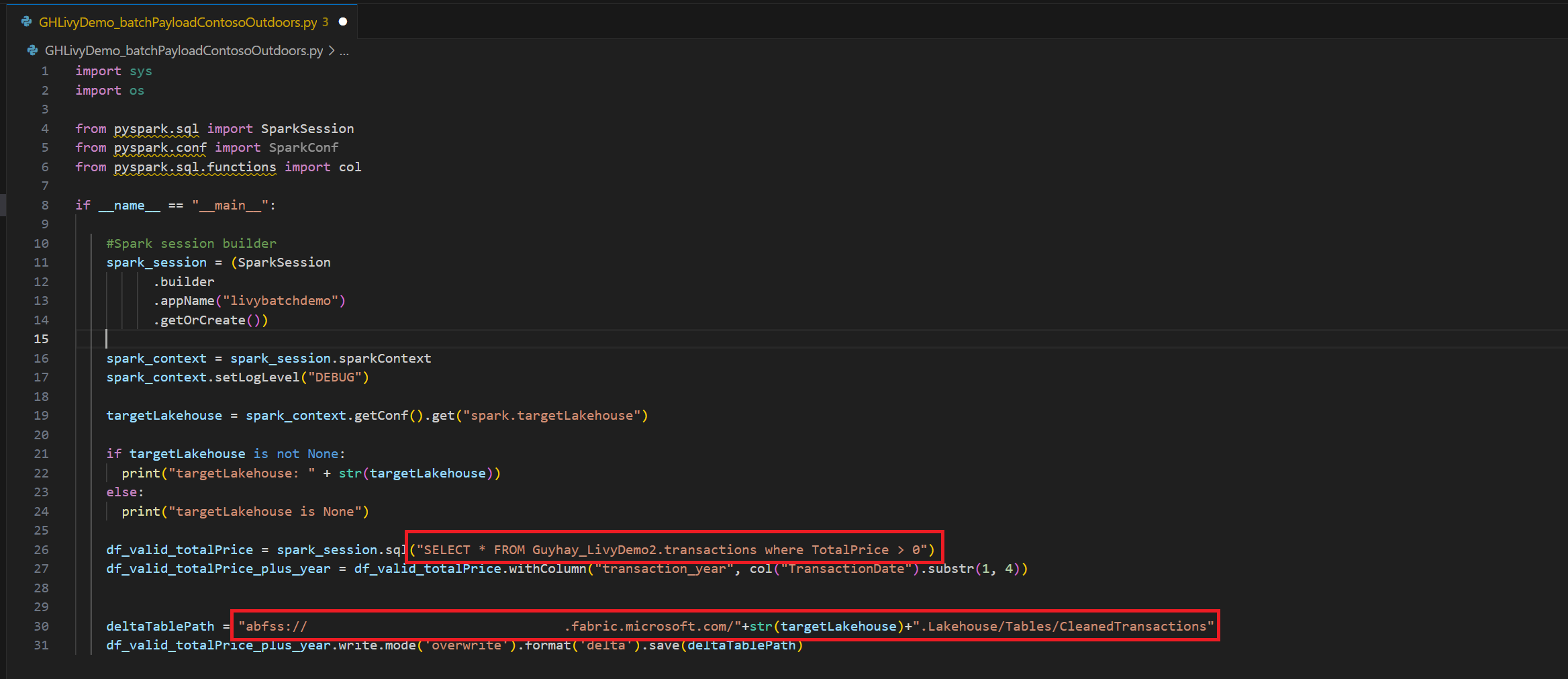
.ipynbノートブックを作成し、次のコードを挿入します。import sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Python ファイルをローカルに保存します。 この Python コード ペイロードには、Lakehouse 内のデータに対して動作し、Lakehouse にアップロードする必要がある 2 つの Spark ステートメントが含まれています。 Visual Studio Code の Livy API バッチ ジョブで参照するペイロードの ABFS パスと、Select SQL ステートメントのレイクハウス テーブル名が必要です。
Python ペイロードを Lakehouse の [ファイル] セクションにアップロードします。 >[データを取得] > [ファイルをアップロード]> の順に選択し、[ファイル] の入力ボックスをクリックします。
![Lakehouse の [ファイル] セクションにあるペイロードを示すスクリーンショット。](media/livy-api/livy-batch-payload-in-lakehouse-files.png)
ファイルが Lakehouse の [ファイル] セクションに表示されたら、ペイロード ファイル名の右側にある 3 つのドットをクリックし、[プロパティ] を選択します。
![Lakehouse の [ファイル] にある [プロパティ] のペイロード ABFS パスを示すスクリーンショット。](media/livy-api/livy-batch-abfs-path.png)
手順 1 で、この ABFS パスをノートブック セルにコピーします。

![Lakehouse の [ファイル] セクションにあるペイロードを示すスクリーンショット。](media/livy-api/livy-batch-payload-in-lakehouse-files.png#lightbox)
![Lakehouse の [ファイル] にある [プロパティ] のペイロード ABFS パスを示すスクリーンショット。](media/livy-api/livy-batch-abfs-path.png#lightbox)
Livy API Spark バッチ セッションを作成する
Visual Studio Code で
.ipynbノートブックを作成し、次のコードを挿入します。from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}ノートブック セルを実行すると、ブラウザーにポップアップが表示され、サインインに使用する ID を選択できます。

サインインに使用する ID を選択すると、Microsoft Entra アプリ登録 API へのアクセス許可の承認も求められます。
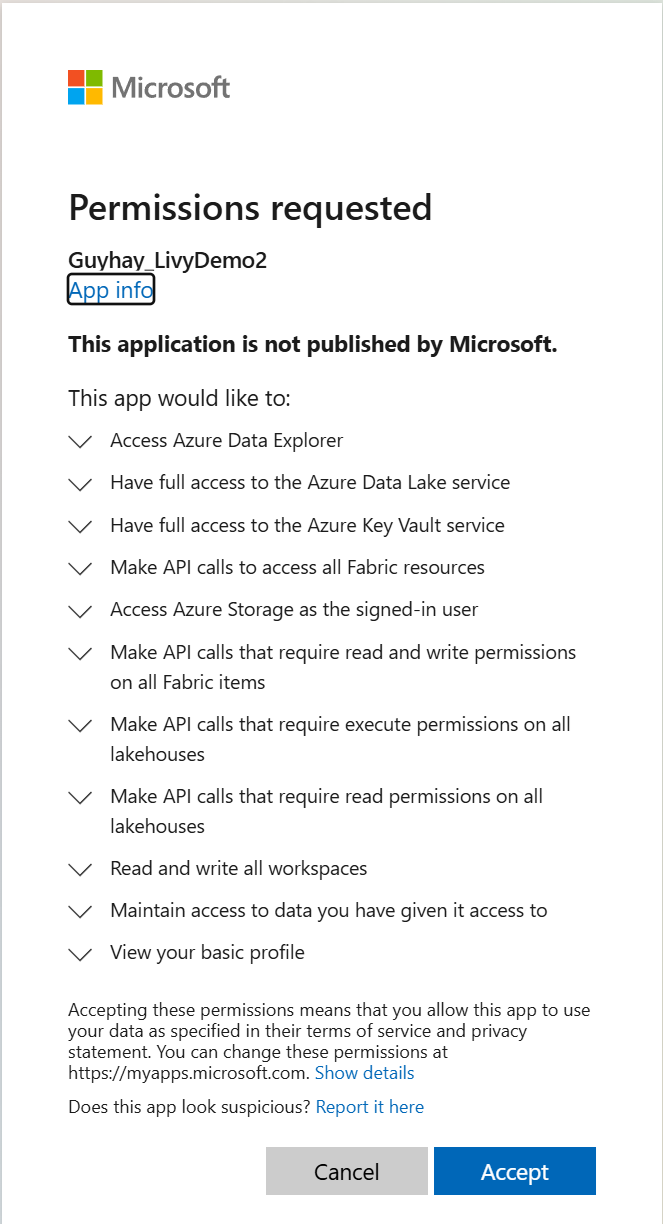
認証が完了したら、ブラウザー ウィンドウを閉じます。

Visual Studio Code で、Microsoft Entra トークンが返されていることがわかります。
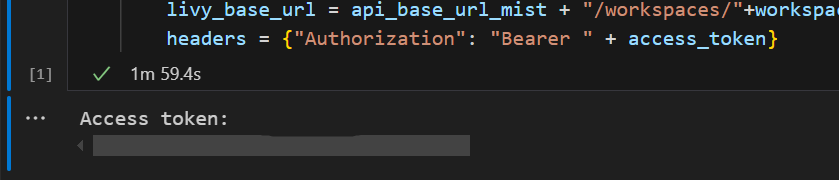
別のノートブック セルを追加し、このコードを挿入します。
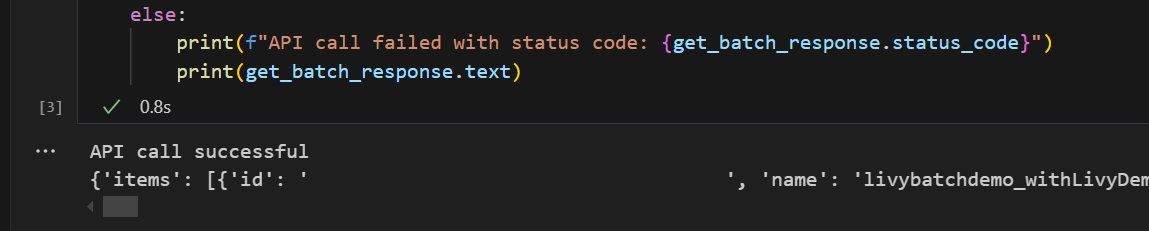
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)ノートブック セルを実行すると、Livy バッチ ジョブが作成されたときに 2 行が印刷されるはずです。





Livy API バッチ セッションを使用して spark.sql ステートメントを送信する
別のノートブック セルを追加し、このコードを挿入します。
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())ノートブック セルを実行すると、Livy バッチ ジョブが作成、実行されたときに数行が印刷されるはずです。

Lakehouse に戻り、変更を確認します。

監視ハブでジョブを表示する
左側のナビゲーション リンクの [監視] を選択して監視ハブにアクセスすると、さまざまな Apache Spark アクティビティを表示できます。
バッチ ジョブが完了の状態になったら、[監視] に移動してセッションの状態を確認できます。
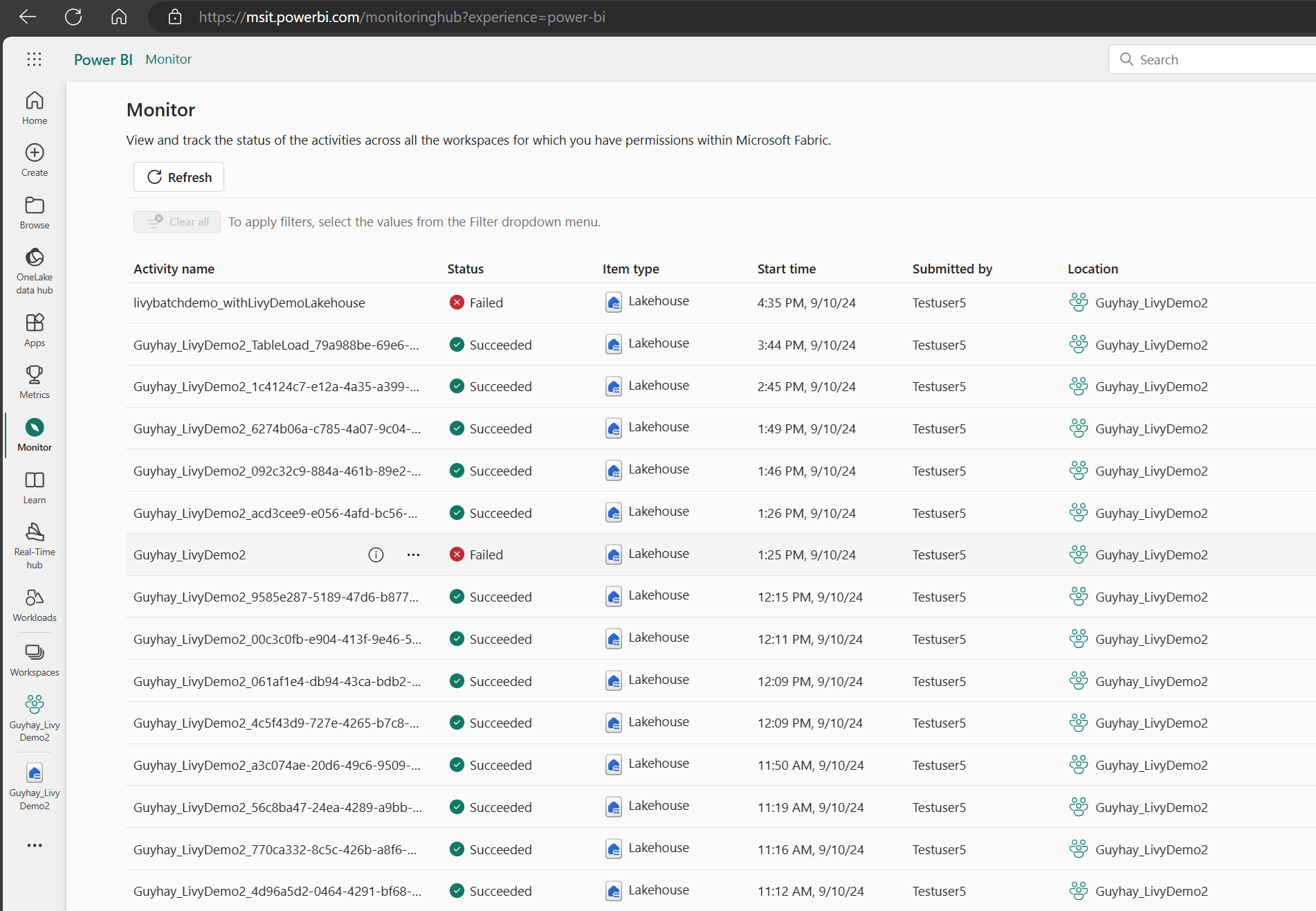
最新のアクティビティ名を選択して開きます。
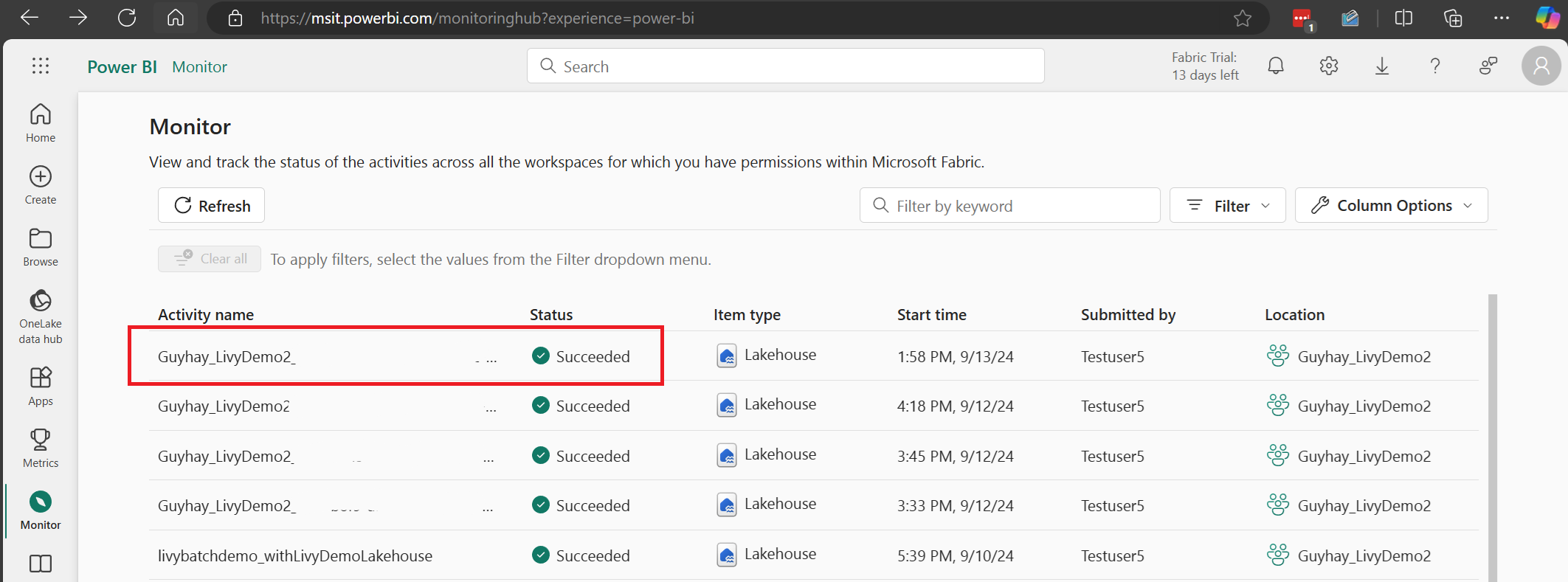
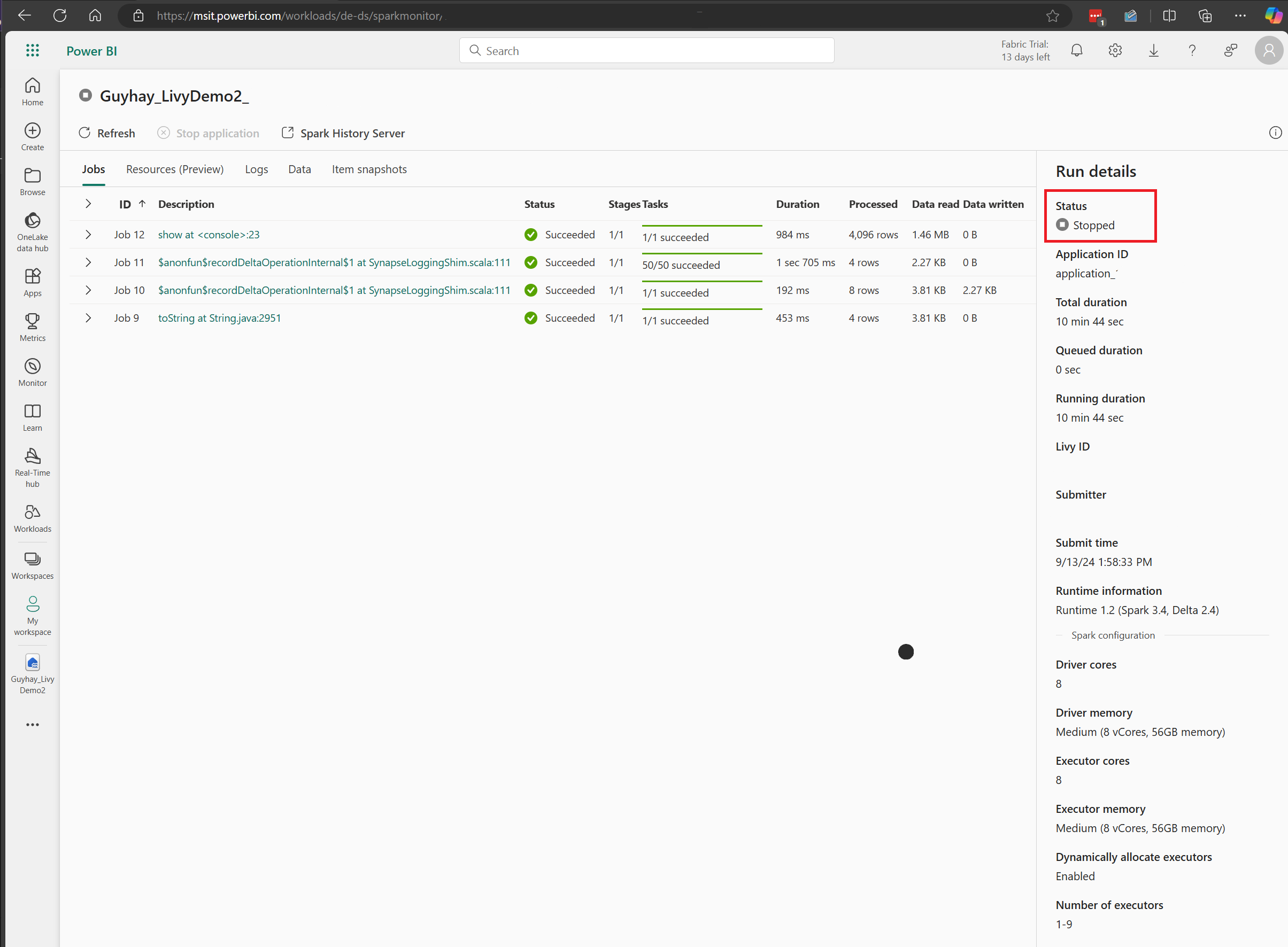
この Livy API セッションのケースでは、以前のバッチ送信、実行の詳細、Spark のバージョン、構成を確認できます。 右上の停止状態に注目してください。



プロセス全体をまとめると、Visual Studio Code などのリモート クライアント、Microsoft Entra アプリ トークン、Livy API エンドポイント URL、Lakehouse に対する認証、Lakehouse の Spark ペイロード、そしてバッチ Livy API セッションが必要です。