Fabric で Apache Spark ジョブ定義を作成する方法
このチュートリアルでは、Microsoft Fabric で Spark ジョブ定義を作成する方法について説明します。
前提条件
作業を開始する前に、以下を行う必要があります。
- アクティブなサブスクリプションが含まれる Fabric テナント アカウント。 無料でアカウントを作成できます。
ヒント
Spark ジョブ定義項目を実行するには、メイン定義ファイルと既定のレイクハウス コンテキストが必要です。 Lakehouse がない場合は、Lakehouse の作成に関する記事の手順に従って作成できます。
Spark ジョブ定義を作成する
Spark ジョブ定義の作成プロセスは迅速かつ簡単であり、いくつかの開始方法があります。
Spark ジョブ定義を作成するためのオプション
作成プロセスを開始するには、いくつかの方法があります。
Data Engineering ホームページ: Spark ジョブ定義は、ホームページの [新規] セクションにある Spark ジョブ定義カードから簡単に作成できます。
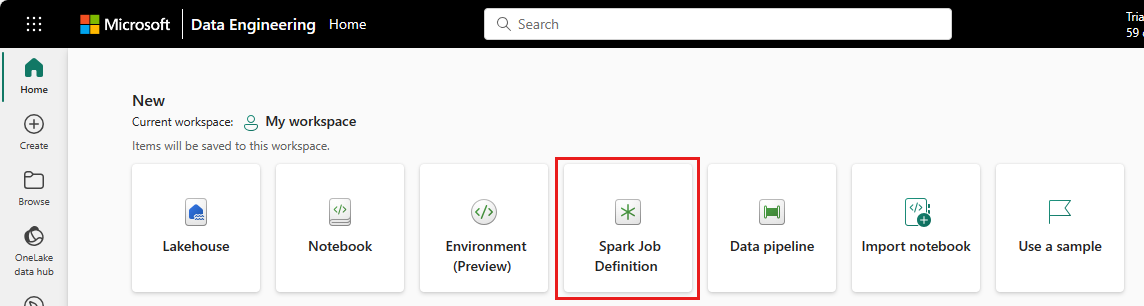
ワークスペース ビュー: [新規] ドロップダウンメニューを使用して、[Data Engineering] のワークスペースから、Spark ジョブ定義を作成することもできます。
![[新規] メニューで Spark ジョブ定義を選択する場所を示すスクリーンショット。](media/create-spark-job-definition/data-engineering-new.png)
ビューの作成: Spark ジョブ定義を作成するためのもう 1 つのエントリ ポイントは、[Data Engineering] の [作成] ページです。
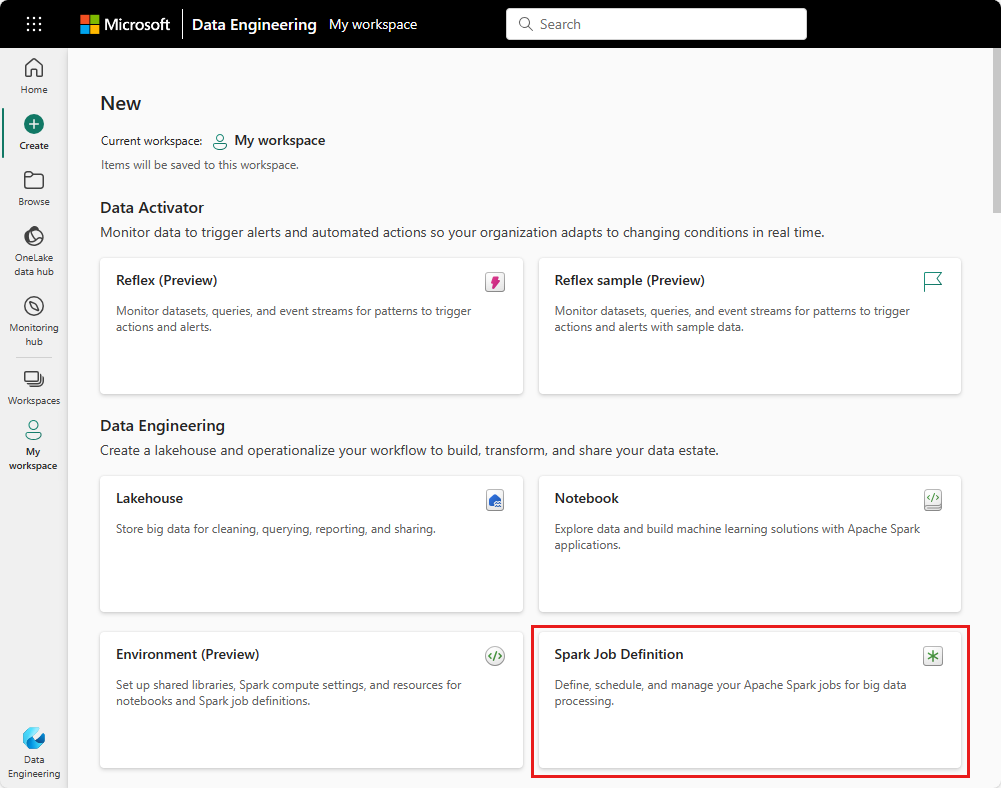
Spark ジョブ定義は、作成時に名前を付ける必要があります。 名前は現在のワークスペース内で一意である必要があります。 新しい Spark ジョブ定義は現在のワークスペースに作成されます。
PySpark (Python) の Spark ジョブ定義を作成する
PySpark の Spark ジョブ定義を作成するには:
サンプルの Parquet ファイル ellow_tripdata_2022-01.parquet をダウンロードし、レイクハウスのファイル セクションにアップロードします。
新しい Spark ジョブ定義を作成します。
[言語] ドロップダウンから [PySpark (Python)] を選択します。
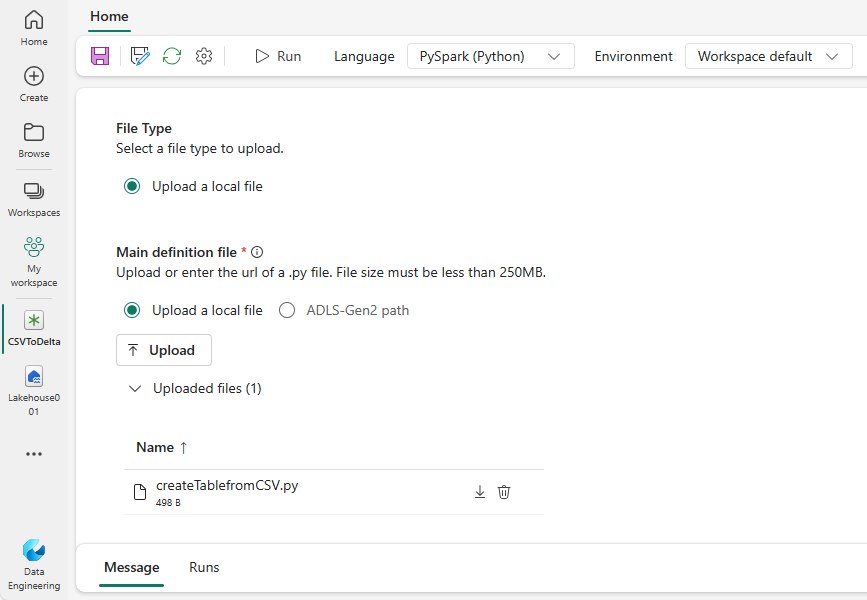
createTablefromParquet.py サンプルをダウンロードし、メイン定義ファイルとしてアップロードします。 メイン定義ファイル (job.Main) は、アプリケーション ロジックを含むファイルであり、Spark ジョブの実行に必須です。 Spark ジョブ定義ごとに、メイン定義ファイルを 1 つだけアップロードできます。
このファイルは、ローカル デスクトップからメイン定義ファイルをアップロードすることも、ファイルの完全な ABFSS パスを指定して既存の Azure Data Lake Storage Gen2 (ADLS) からアップロードすることもできます。 たとえば、
abfss://your-storage-account-name.dfs.core.windows.net/your-file-pathのようにします。参照ファイルを .py ファイルとしてアップロードします。 参照ファイルは、メイン定義ファイルによってインポートされる Python モジュールです。 メイン定義ファイルと同様に、デスクトップまたは既存の ADLS Gen2 からアップロードできます。 複数の参照ファイルがサポートされています。
ヒント
ADLS Gen2 パスを使用する場合、このファイルにアクセスできるように、ジョブを実行するユーザー アカウントに、ストレージ アカウントに対する適切なアクセス許可を付与する必要があります。 これを行うために、2 つの方法があります。
- ユーザー アカウントに、ストレージ アカウントに対する共同作成者ロールを割り当てます。
- ADLS Gen2 アクセス制御リスト (ACL) を介して、ファイルのユーザー アカウントに読み取りおよび実行のアクセス許可を付与します。
手動で実行する場合、現在のログイン ユーザーのアカウントがジョブの実行に使用されます。
必要に応じて、ジョブにコマンド ライン引数を指定します。 引数を区切るにはスペースをスプリッターとして使用します。
レイクハウス参照をジョブに追加します。 少なくとも 1 つのレイクハウス参照をジョブに追加する必要があります。 このレイクハウスは、ジョブの既定のレイクハウス コンテキストです。
複数のレイクハウス参照がサポートされています。 既定以外のレイクハウス名と完全な OneLake URL を [Spark 設定]ページで確認します。
Scala/Java 用の Spark ジョブ定義を作成する
Scala/Java 用の Spark ジョブ定義を作成するには:
新しい Spark ジョブ定義を作成します。
[言語] ドロップダウンから Spark(Scala/Java) を選択します。
メイン定義ファイルを .jar ファイルとしてアップロードします。 メイン定義ファイルは、このジョブのアプリケーション ロジックを含むファイルであり、Spark ジョブの実行に必須です。 Spark ジョブ定義ごとに、メイン定義ファイルを 1 つだけアップロードできます。 Main クラス名を指定します。
参照ファイルを .jar ファイルとしてアップロードします。 参照ファイルは、メイン定義ファイルによって参照/インポートされるファイルです。
必要に応じて、ジョブにコマンド ライン引数を指定します。
レイクハウス参照をジョブに追加します。 少なくとも 1 つのレイクハウス参照をジョブに追加する必要があります。 このレイクハウスは、ジョブの既定のレイクハウス コンテキストです。
R の Spark ジョブ定義を作成する
SparkR(R) 用の Spark ジョブ定義を作成するには:
新しい Spark ジョブ定義を作成します。
[言語] ドロップダウンから [SparkR(R)] を選択します。
メイン定義ファイルを .R ファイルとしてアップロードします。 メイン定義ファイルは、このジョブのアプリケーション ロジックを含むファイルであり、Spark ジョブの実行に必須です。 Spark ジョブ定義ごとに、メイン定義ファイルを 1 つだけアップロードできます。
参照ファイルを .R ファイルとしてアップロードします。 参照ファイルは、メイン定義ファイルによって参照/インポートされるファイルです。
必要に応じて、ジョブにコマンド ライン引数を指定します。
レイクハウス参照をジョブに追加します。 少なくとも 1 つのレイクハウス参照をジョブに追加する必要があります。 このレイクハウスは、ジョブの既定のレイクハウス コンテキストです。
Note
Spark ジョブ定義は現在のワークスペースに作成されます。
Spark ジョブ定義をカスタマイズするオプション
Spark ジョブ定義の実行をさらにカスタマイズするためのオプションがいくつかあります。
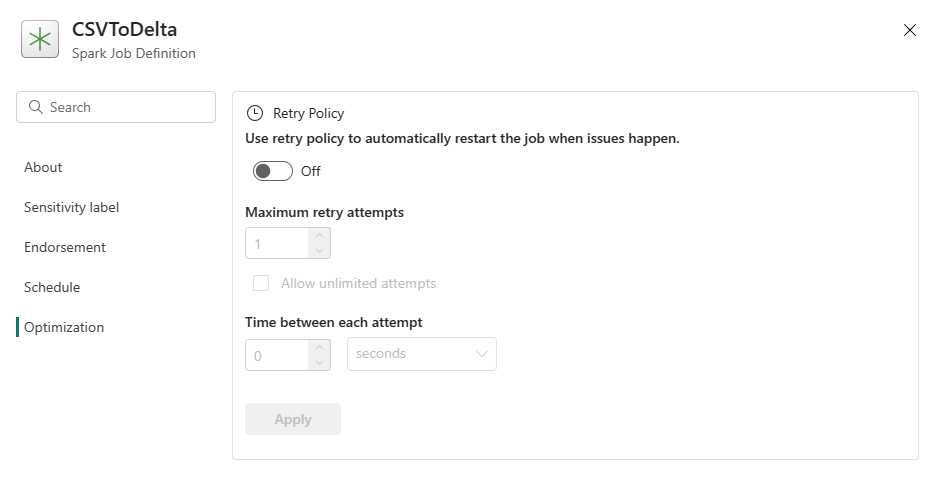
- Spark コンピューティング: [Spark コンピューティング] タブ内で、ジョブの実行に使用される Spark のバージョンであるランタイム バージョンを確認できます。 ジョブの実行に使用される Spark 構成設定も確認できます。 [追加] ボタンをクリックすると、Spark 構成設定をカスタマイズできます。
最適化: [最適化] タブで、ジョブの再試行ポリシーを有効にして設定できます。 有効にすると、ジョブが失敗した場合に再試行されます。 最大再試行回数と再試行間隔を設定することもできます。 再試行するたびに、ジョブが再起動されます。 ジョブがべき等であることを確認します。