Microsoft Fabric での Apache Spark の課金と活用レポート
適用対象:✅ Microsoft Fabric でのデータ エンジニアリングとデータ サイエンス
この記事では、ApacheSpark のコンピューティング使用状況とレポートについて説明します。これを使用することで、Microsoft Fabric の Fabric Data Engineering および Science のワークロードを強化できます。 コンピューティング使用率には、テーブルのプレビュー、デルタへの読み込み、インターフェイスからのノートブック実行、スケジュールされた実行、パイプラインでノートブック ステップがトリガーした実行、Apache Spark ジョブ定義実行などのレイクハウス操作が含まれます。
Microsoft Fabric における他のエクスペリエンスと同様、データ エンジニアリングもこれらのジョブを実行するためのワークスペースと、関連するキャパシティを使用します。また、全体的なキャパシティ チャージは Azure ポータルの Microsoft Cost Management サブスクリプションに表示されます。 Fabric の請求について詳しくは、「Fabric キャパシティに関する Azure 請求書を理解する」をご覧ください。
Fabric キャパシティ
ユーザーは Azure サブスクリプションの使用を指定して、Azure から Fabric キャパシティを購入できます。 容量のサイズによって、使用可能な計算能力の量が決定されます。 Fabric 用 Apache Spark では、購入した 1 件の CU が 2 つの Apache Spark VCore に変換されます。 たとえば、Fabric キャパシティ F128 を購入した場合、256 SparkVCore が提供されます。 Fabric キャパシティは追加されたすべてのワークスペース全体で共有され、許可された合計 Apache Spark コンピューティングがキャパシティに関連付けられるすべてのワークスペースから送信されたジョブ全体で共有されます。 Spark でのさまざまな SKU、コアの割り当て、調整を理解するには、「Apache Spark for Microsoft Fabric でのコンカレンシーの制限とキュー」を参照してください。
Spark コンピュート構成と購入したキャパシティ
Fabric 用 Apache Spark コンピューティングには、コンピューティング構成に関する 2 つのオプションが用意されています。
スターター プール: このデフォルトのプールは、Microsoft Fabric プラットフォームで Spark をすぐに使用できる迅速かつ簡単な方法です。 Spark セッションは、Spark によってノードが設定されるのを待機せず、すぐに使用できます。このため、データを使用してより多くの作業を行い、より迅速に分析情報を得ることができます。 請求とキャパシティ消費については、ノートブックの実行、Spark ジョブの定義、レイクハウスの操作を開始したタイミングで請求されます。 クラスターがプール内でアイドル状態になっている間は課金されません。

たとえば、ノートブック ジョブをスターター プールに送信する場合は、ノートブック セッションがアクティブな期間に対してのみ課金されます。 課金される時間には、アイドル時間や、Spark コンテキストでセッションを個人設定するためにかかった時間は含まれません。 購入した Fabric Capacity SKU に基づくスターター プールの構成について詳しくは、「Fabric キャパシティに基づきスターター プールを構成する」をご覧ください
Spark プール: データ分析タスクに必要なリソースの規模に応じてカスタマイズできるカスタム プールです。 Spark プールに名前を付け、ノード (作業を行うマシン) の数とサイズを選択できます。 作業量に応じてノードの数を調整する方法を Spark に指示することもできます。 Spark プールの作成は無料です。課金されるのは、プールで Spark ジョブを実行し、Spark によってノードが設定されたときのみです。
- カスタム Spark プールに含めることができるノードのサイズと数は、Microsoft Fabric の容量によって異なります。 Spark 仮想コアの合計数が 128 を超えない限り、これらの Spark 仮想コアを使用して、カスタム Spark プール用にさまざまなサイズのノードを作成できます。
- Spark プールは、スターター プールと同様に課金されます。ノートブックまたは Spark ジョブ定義を実行するためにアクティブな Spark セッションを作成しない限り、作成したカスタム Spark プールについて支払うことはありません。 ジョブの実行期間中にのみ課金されます。 クラスターの作成やジョブ完了後の割り当て解除などのステージに対しては課金されません。
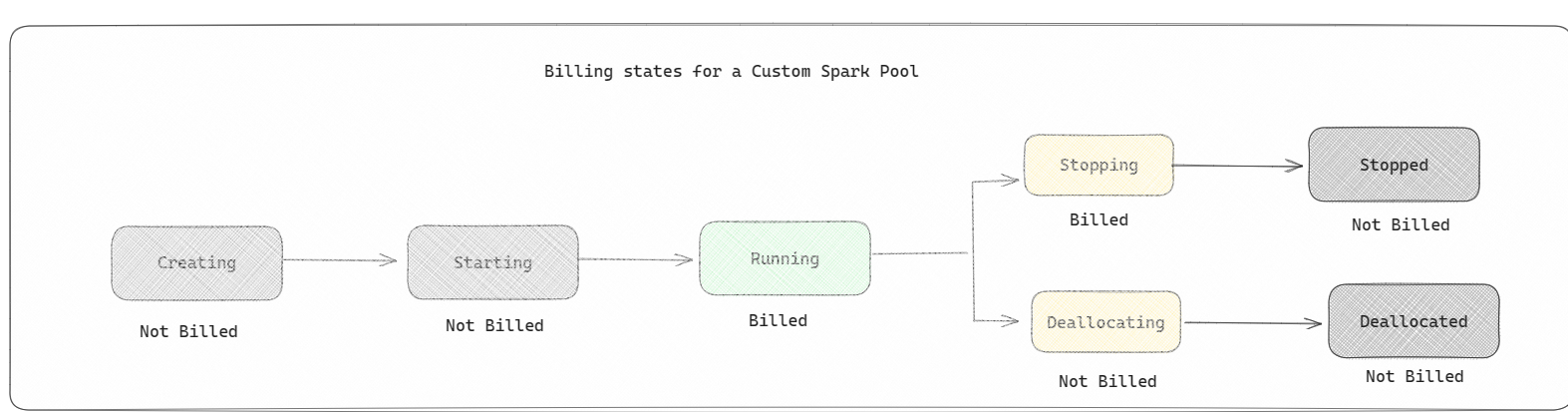
たとえば、ノートブック ジョブをカスタム Spark プールに送信する場合は、セッションがアクティブな期間に対してのみ課金されます。 Spark セッションが停止するか期限切れになると、そのノートブック セッションの課金は停止します。 クラウドからのクラスター インスタンスの取得にかかった時間、または Spark コンテキストの初期化にかかった時間には課金されません。 購入した Fabric Capacity SKU に基づく Spark プールの構成について詳しくは、「Fabric Capacity に基づきプールを構成する」をご覧ください。


Note
作成するスターター プールと Spark プールの既定のセッション有効期限は 20 分に設定されます。 セッションの有効期限が切れた後に Spark プールを 2 分間使用しない場合、Spark プールの割り当ては解除されます。 セッションの有効期限が切れる前にノートブックの実行が完了した後にセッションと課金を停止するには、ノートブックの [ホーム] メニューから [セッションの停止] ボタンをクリックするか、監視ハブ ページに移動してそこでセッションを停止します。
Spark コンピュート使用状況レポート
Microsoft Fabric Capacity Metrics アプリ では、すべての Fabric ワークロードの容量使用状況を 1 か所で可視化できます。 購入したキャパシティに対するワークロードのパフォーマンスと使用状況を監視するために、キャパシティ管理者が使用するレポートです。
アプリをインストールしたら、[アイテムの種類を選択:] ドロップダウン リストでアイテム タイプ [ノートブック]、[レイクハウス]、[Spark ジョブ定義] を選択します。 マルチ メトリック リボン グラフを希望のタイムフレームに合わせて調整し、選択したすべてのアイテムで使用状況を把握できるようになりました。
Spark 関連のすべての操作は、バックグラウンド操作として分類されます。 Spark からの容量消費は、ノートブック、Spark ジョブ定義、またはレイクハウスの下に表示され、操作名と項目によって集計されます。 たとえばノートブック ジョブを実行する場合、ノートブック実行、ノートブックが使用する CU (1 CU あたり 2 Spark VCore が提供されるため、合計 Spark VCore/2)、ジョブにかかった時間をレポートで確認できます。
 Spark 容量の使用状況レポートの詳細については、「Apache Spark 容量の消費を監視する」を参照してください。
Spark 容量の使用状況レポートの詳細については、「Apache Spark 容量の消費を監視する」を参照してください。
課金の例
以下のシナリオについて考えてみます。
Fabric ワークスペース W1 をホストするキャパシティ C1 があり、このワークスペースにはレイクハウス LH1 とノートブック NB1 が含まれるものとします。
- ノートブック (NB1) またはレイクハウス (LH1) が実行するすべての Spark 操作はキャパシティ C1 に対して報告されます。
この例を、Fabric ワークスペース W2 をホストする別のキャパシティ C2 に拡張して、このワークスペースに Spark ジョブ定義 (SJD1) とレイクハウス (LH2) が含まれているものとします。
- ワークスペース (W2) の Spark ジョブ定義 (SJD2) がレイクハウス (LH1) からデータを読み取る場合、使用状況はアイテムをホストしているワークスペース (W2) に関連付けられたキャパシティ C2 に対して報告されます。
- ノートブック (NB1) がレイクハウス (LH2) から読み取り操作を行う場合、キャパシティ消費はノートブック項目をホストするワークスペース W1 を提供するキャパシティ C1 に対して報告されます。