Visual Studio Code で Apache Spark ジョブ定義を作成および管理する
Synapse 用 Visual Studio (VS) Code 拡張機能では、Fabric での CURD (作成、更新、読み取り、および削除) Spark ジョブ定義操作が完全にサポートされています。 Spark ジョブ定義を作成したら、参照ライブラリをさらにアップロードし、Spark ジョブ定義を実行する要求を送信し、実行履歴をチェックできます。
Spark ジョブ定義を作成する
新しい Spark ジョブ定義を作成するには、次のようにします。
VS Code エクスプローラーで、[Create Spark Job Definition] (Spark ジョブ定義の作成) オプションを選択します。
![[Create Spark Job Definition] (Spark ジョブ定義の作成) オプションをどこで選択するかを示す、VS Code Explorer のスクリーンショット。](media/vscode/create-sjd.png)
最初の必須フィールド (名前、参照する Lakehouse、既定の Lakehouse) を入力します。
要求プロセスと新しく作成した Spark ジョブ定義の名前は、VS Code Explorer の Spark ジョブ定義ルート ノードの下に表示されます。 Spark ジョブ定義名ノードの下に、次の 3 つのサブノードが表示されます。
- ファイル: メイン定義ファイルとその他の参照先ライブラリの一覧。 このリストから新しいファイルをアップロードできます。
- Lakehouse: この Spark ジョブ定義によって参照されるすべての Lakehouse の一覧。 既定の Lakehouse はリスト内でマークが付けられており、相対パス
Files/…, Tables/…を使用してアクセスできます。 - 実行: この Spark ジョブ定義の実行履歴と、各実行のジョブの状態の一覧。
メイン定義ファイルを参照先ライブラリにアップロードする
メイン定義ファイルをアップロードまたは上書きするには、[Add Main File] (メイン ファイルの追加) オプションを選択します。
![[Add Main File] (メイン ファイルの追加) オプションをどこで選択するかを示す、VS Code Explorer のスクリーンショット。](media/vscode/upload-main-def.png)
メイン定義ファイルが参照するライブラリ ファイルをアップロードするには、[Lib ファイルの追加] オプションを選択します。
ファイルをアップロードした後は、[ファイルの更新] オプションをクリックし新しいファイルをアップロードすることでファイルをオーバーライドするか、[削除] オプションを使用してファイルを削除できます。
![[ファイルの更新] と [削除] オプションがどこにあるかを示す VS Code Explorer のスクリーンショット。](media/vscode/update-file.png)
実行要求を送信する
VS Code から Spark ジョブ定義を実行する要求を送信するには、次のようにします。
実行する Spark ジョブ定義の名前の右側にあるオプションから、[Run Spark Job] (Spark ジョブの実行) オプションを選択します。
![[Run Spark Job] (Spark ジョブの実行) オプションをどこで選択するかを示す、VS Code Explorer のスクリーンショット。](media/vscode/submit-sjd-run.png)
要求を送信すると、エクスプローラー リストの [実行] ノードに新しい Apache Spark アプリケーションが表示されます。 [Cancel Spark Job] (Spark ジョブの取り消し) オプションを選択すると、実行中のジョブを取り消すことができます。
![新しい Spark アプリケーションが実行ノードの下にリストされ、[Cancel Spark Job] (Spark ジョブの取り消し) オプションがどこにあるかを示す VS Code Explorer のスクリーンショット。](media/vscode/cancel-sjd-run.png)
Fabric ポータルで Spark ジョブ定義を開く
Fabric ポータルで [ブラウザーで開く] オプションを選択すると、Spark ジョブ定義の作成ページを開くことができます。
完了した実行の横にある [ブラウザーで開く] を選択して、その実行の詳細モニター ページを表示することもできます。
![[ブラウザーで開く] オプションをどこで選択するかを示す、VS Code Explorer のスクリーンショット。](media/vscode/open-sjd-in-browser.png)
Spark ジョブ定義のソース コードをデバッグする (Python)
Spark ジョブ定義が PySpark (Python) で作成されている場合は、メイン定義ファイルの .py スクリプトと参照ファイルをダウンロードし、VS Code でソース スクリプトをデバッグできます。
ソース コードをダウンロードするには、Spark ジョブ定義の右側にある [Debug Spark Job Definition] (Spark ジョブ定義のデバッグ) オプションを選択します。

ダウンロードが完了すると、ソース コードのフォルダーが自動的に開きます。
ダイアログが表示されたら、[Trust the authors] (作成者を信頼する) オプションを選択します。 (このオプションは、フォルダーを初めて開いたときにのみ表示されます。このオプションを選択しない場合、ソース スクリプトをデバッグまたは実行することはできません。詳細については、「Visual Studio Code のワークスペースの信頼セキュリティ」を参照してください。)
以前にソース コードをダウンロードしたことがある場合は、ローカル バージョンを新しいダウンロードで上書きすることを確認するメッセージが表示されます。
Note
ソース スクリプトのルート フォルダーに、conf という名前のサブフォルダーが作成されます。 このフォルダー内にある lighter-config.json という名前のファイルに、リモート実行に必要なシステム メタデータが含まれています。 これに変更を加えないでください。
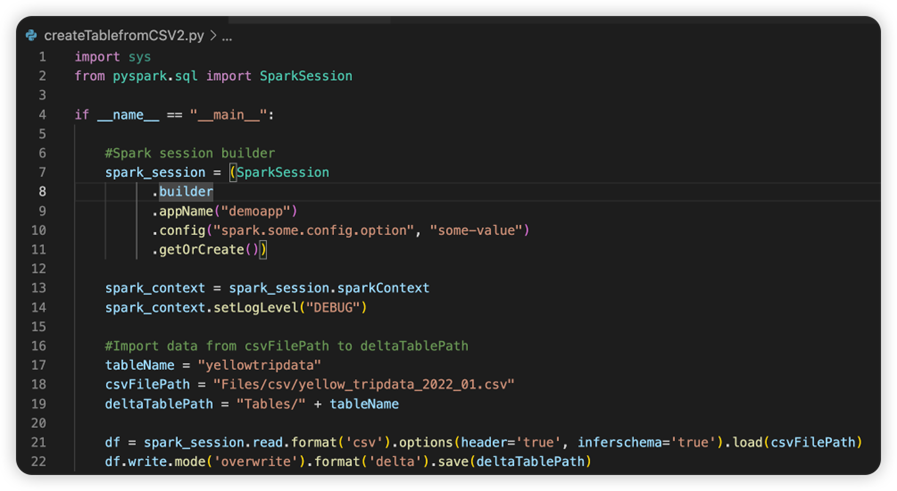
sparkconf.py という名前のファイルには、SparkConf オブジェクトを設定するために追加する必要があるコード スニペットが含まれています。 リモート デバッグを有効にするには、SparkConf オブジェクトが正しく設定されている必要があります。 次の図は、ソース コードの元のバージョンを示しています。
次の画像は、スニペットをコピーして貼り付けた後の更新されたソース コードです。
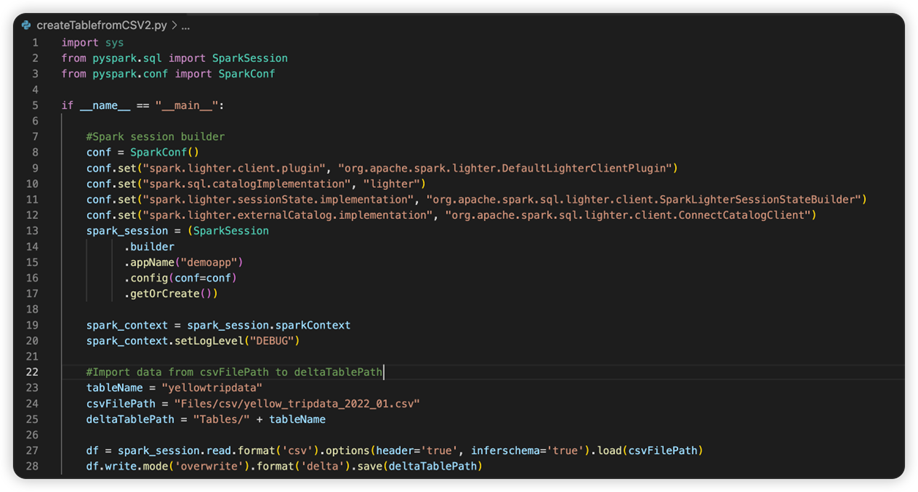
必要な conf でソース コードを更新したら、適切な Python インタープリターを選択する必要があります。 synapse-spark-kernel conda 環境からインストールされたものを必ず選択してください。
Spark ジョブ定義のプロパティを編集する
Spark ジョブ定義の詳細プロパティ (コマンド ライン引数など) を編集できます。
[Update SJD Configuration] (SJD 構成の更新) オプションを選択して、settings.yml ファイルを開きます。 既存のプロパティによって、このファイルの内容が設定されます。
![Spark ジョブ定義の [Update SJD Configuration] (SJD 構成の更新) オプションを選択する場所を示すスクリーンショット。](media/vscode/edit-sjd-property.png)
.yml ファイルを更新して保存します。
右上隅にある [Publish SJD Property] (SJD プロパティの発行) オプションを選択して、変更をリモート ワークスペースに同期させます。
![Spark ジョブ定義の [Publish SJD Property] (SJD プロパティの発行) オプションを選択する場所を示すスクリーンショット。](media/vscode/push-sjd-property.png)