以前のバージョンのExchange Serverに対する高可用性とサイトの回復性に対する変更
Exchange Server 2013 以降では、DAG とメールボックス データベース コピー (単一アイテムの回復、アイテム保持ポリシー、遅延データベース コピーなど) を使用して、高可用性、サイトの回復性、Exchange ネイティブ データ保護を提供します。 高可用性プラットフォーム、Exchange Information Store、および拡張ストレージ エンジン (ESE) はすべて、Exchange 2010 以降、可用性と複雑な管理を提供し、コストを削減するために強化されています。 以下のような点が改善されました。
IOPS の削減: これにより、容量と IOPS の観点から、より大きなディスクを可能な限り効率的に使用できます。
マネージド可用性: マネージド可用性により、内部監視と復旧指向の機能が緊密に統合され、障害の防止、サービスの事前復元、サーバーの自動フェールオーバーの開始、または管理者に対してアクションの実行を警告します。 サーバーとコンポーネントの稼動時間だけでなく、エンドユーザー エクスペリエンスの監視および管理に重点を当てることで、サービスを継続的に利用できるようにしています。
マネージド ストア: マネージド ストアは、Exchange 2013 以降で書き換えられた Information Store プロセスの名前です。 マネージド ストアは C# で記述され、Microsoft Exchange レプリケーション サービス (MSExchangeRepl.exe) と緊密に統合され、回復性の向上による可用性の向上を実現します。
ディスクごとに複数のデータベースをサポート: 機能強化により、同じディスク上の複数のデータベース (アクティブ コピーとパッシブ コピーの組み合わせ) をサポートできるため、容量と IOPS の観点からより大きなディスクを可能な限り効率的に使用できます。
AutoReseed: 自動再シード機能を使用すると、ディスク障害後にデータベースの冗長性をすばやく復元できます。 ディスクに障害が発生した場合、そのディスクに格納されているデータベース コピーが、アクティブ データベース コピーから同じサーバー上の予備ディスクにコピーされます。 障害が発生したディスクに複数のデータベース コピーが格納されていた場合は、予備ディスク上に自動的に再シードされます。 この結果、アクティブ データベースが複数のサーバーに存在し、データが並行してコピーされるので、迅速に再シードできます。
ストレージ障害からの自動復旧: この機能は、回復性または冗長性に影響を与える障害からシステムが復旧できるように、Exchange 2010 で導入されたイノベーションを継続します。 Exchange には、長い I/O 時間の回復動作、MSExchangeRepl.exeによる過剰なメモリ消費、およびシステムが不適切な状態でスレッドをスケジュールできない重大なケースが含まれるようになりました。
遅延コピーの機能強化: 自動ログ 再生ダウンを使用して、遅延コピーを一定の範囲で管理できるようになりました。 遅延コピーは、ページの修正プログラムの適用やディスク領域の不足のシナリオなど、さまざまな状況でログ ファイルを自動的に再生します。 遅延コピーにページ修正が必要であることがシステムによって検出された場合、ログは遅延コピーに自動的に再生され、ページ修正が実行されます。 時間差コピーでは、低ディスク容量のしきい値に達した場合、および時間差コピーが特定の時間帯において唯一の利用可能なコピーであると検知された場合にも、この自動再生機能が呼び出されます。 さらに、遅延コピーでは Safety Net を使用できるため、復旧やアクティブ化がはるかに簡単になります。
単一コピー アラートの機能強化: Exchange 2010 で導入された単一コピー アラートは、個別のスケジュールされたスクリプトではなくなりました。 この機能は、システム内の可用性管理コンポーネントに統合され、Exchange のネイティブな機能になりました。
DAG ネットワークの自動構成: DAG ネットワークは、構成設定に基づいてシステムによって自動的に構成できます。 手動構成オプションに加え、DAG で MAPI とレプリケーション ネットワークを区別して DAG ネットワークを自動的に構成することも可能です。
IOPS の削減
Exchange 2010 では、パッシブ データベース コピーのチェックポイントの深さが低く、高速フェールオーバーに必要です。 さらに、パッシブ コピーでは、5 MB (MB) のチェックポイント深度に追いつくために、データの積極的な事前読み取りが行われます。 チェックポイントの深さが低く、これらの積極的な事前読み取り操作を実行した結果、パッシブ データベース コピーの IOPS は、Exchange 2010 のアクティブ コピーの IOPS と等しくなります。
Exchange 2013 以降では、パッシブ コピーで高いチェックポイント深度 (100 MB) を使用しながら、システムは高速フェールオーバーを提供できます。 パッシブ コピーのチェックポイントの深さは 100 MB のため、もはや積極的ではないレベルまで緩和されました。 チェックポイントの深さを増やし、積極的なプリ読み取りをチューニング解除した結果、パッシブ コピーの IOPS はアクティブ コピー IOPS の約 50% になります。
パッシブ コピーのチェックポイントの深さをより高く設定すると、その他の変更も必要になります。 Exchange 2010 のフェールオーバーでは、データベースがパッシブ コピーからアクティブ コピーに変換されると、データベース キャッシュがフラッシュします。 Exchange 2013 以降では、ESE ログが書き換えられ、パッシブからアクティブへの切り替えによってキャッシュが保持されます。 ESE がキャッシュをフラッシュする必要がないので、フェールオーバーは高速になります。
もう 1 つの変更点は、バックグラウンド データベース メンテナンス (BDM) プロセスに対する変更です。 BDM はコピーあたり毎秒約 1 ~ 2 MB を処理するようになりました。
これらの変更の結果、Exchange では Exchange 2010 よりも IOPS が大幅に削減されるようになりました。
可用性管理
マネージド 可用性は、組み込み、アクティブな監視、および Exchange 高可用性プラットフォームの統合です。 Managed Availability を使用すると、システムはサービス正常性に基づいてデータベースをフェールオーバーするタイミングを決定できます。 マネージド可用性は、メールボックス サーバー上のクライアント アクセス (フロントエンド) サービスとバックエンド サービスに展開される内部インフラストラクチャです。 マネージド 可用性には、常に作業を行っている 3 つの主要な非同期コンポーネントが含まれています。
1 つ目のコンポーネントはプローブ エンジンであり、サーバーで測定を行い、データを収集します。 これらの測定値の結果は、2 番目のコンポーネントであるモニターに流れます。
モニターには、収集されたデータで正常と見なされるものに基づいて、システムによって使用されるすべてのビジネス ロジックが含まれています。 モニターは、パターン認識エンジンと同様に、収集したすべての測定値についてさまざまなパターンを探し出し、対象が正常かどうかの決定を下すことができます。
最後に、回復アクションを担当するレスポンダー エンジンがあります。
何かが異常な場合、最初のアクションは、そのコンポーネントの回復を試みすることです。 これには、複数ステージの復旧アクションが含まれる場合があります。例えば:
アプリケーション プールを再起動します。
サービスを再起動します。
サーバーを再起動します。
トラフィックを受け入れなくなったように、サーバーをオフラインにします。
復旧アクションが失敗した場合、システムはイベント ログ通知を通じて問題を人間にエスカレートします。
可用性管理は、次の 2 つのサービスの形で実装されています。
Exchange Health Manager Service (MSExchangeHMHost.exe): これは、ワーカー プロセスの管理に使用されるコントローラー プロセスです。 必要に応じて、ワーカー プロセスの構築、実行、開始、および停止に使用されます。 また、ワーカー プロセスがクラッシュした場合の回復や、ワーカー プロセスが単一障害点になることを防ぐためにも使用されます。
Exchange Health Manager Worker プロセス (MSExchangeHMWorker.exe): これは、ランタイム タスクの実行を担当するワーカー プロセスです。
マネージド可用性では、永続ストレージを使用してその機能を実行します。
XML 構成ファイルを使用して、ワーカー プロセスのスタートアップ中に作業項目の定義を初期化します。
レジストリを使用して、ブックマークなどのランタイム データを格納します。
Crimson Channel イベント ログ インフラストラクチャを使用して、作業項目の結果を格納します。
マネージド可用性の詳細については、「 マネージド可用性」を参照してください。
管理ストア
Exchange 2010 以前のバージョンでは、メールボックス サーバーの役割で Information Store プロセス (Store.exe) の単一インスタンスの実行がサポートされています。 この単一のストア インスタンスは、サーバー上のすべてのデータベース (アクティブ、パッシブ、ラグド、復旧) をホストします。 これらの Exchange アーキテクチャでは、メールボックス サーバーでホストされているさまざまなデータベース間に分離がほとんど存在しない場合があります。 1 つのメールボックス データベースに関する問題は、他のすべてのデータベースに悪影響を与える可能性があり、メールボックスの破損によるクラッシュは、そのサーバーでホストされているすべてのユーザーのサービスに影響する可能性があります。
1 つのストア インスタンスに対するもう 1 つの課題は、拡張ストレージ エンジン (ESE) によるプロセッサのスケーラビリティの欠如です。 ESE は 8 ~ 12 個のプロセッサ コアにスケーリングされますが、それ以外の場合、プロセッサ間通信とキャッシュ同期の問題によってパフォーマンスが低下します。 16 以上のコア システムを使用する現在のサーバーでは、ESE の 8 ~ 12 コアのアフィニティを管理し、他のコアをストア以外のプロセス (アシスタント、Search Foundation、Managed Availability など) に使用するという管理上の課題が課されます。 その上、以前のアーキテクチャは Store プロセスのスケールアップを制限していました。
Store.exeプロセスは、Exchange Server自体が進化するにつれて年を通じてかなり進化してきましたが、単一のプロセスとして、最終的にはスケーラビリティが制限され、単一の障害点を表しています。 これらの制限により、Store.exeは Exchange 2013 で削除され、マネージド ストアに置き換えられました。
詳細については、「管理ストア」を参照してください。
ボリュームごとに複数のデータベース
Exchange のストレージの機能強化は、主に多数のディスク (JBOD) 構成に対して設計されていますが、サポートされているすべてのストレージ構成で使用できます。 そのような機能の 1 つは、同じボリューム上で複数のデータベースをホストできることです。 この機能は、大規模なディスク用の Exchange 最適化に関する機能です。 これらの最適化により、容量、IOPS、再シード時間の観点から大きなディスクをはるかに効率的に使用できます。これは、JBOD ストレージ構成での実行に関連する課題に対処することを目的としています。
データベースのサイズは管理可能である必要があります。
再シード操作は高速かつ信頼性が高くなければなりません。
ストレージの容量は増加しますが、IOPS は増加しません。
パッシブ データベース コピーをホストするディスクは IOPS の面で十分に活用されていません。
時間差コピーには非対称のストレージ要件があります。
ディスクの空き容量が少ない状態から回復する場合、敏捷性は限られています。
ストレージ容量の増加傾向は続いています。 たとえば、8 テラバイト ドライブの最大データベース サイズ (2 テラバイト) に関する Exchange のベスト プラクティス ガイドラインは、5 テラバイトを超えるディスク領域を無駄にすることを意味します。
解決策は、データベースを大きくすることですが、長い再シード時間 (運用上管理できない再シード時間を含む) が発生し、ネットワーク経由でその量のデータをコピーする信頼性が損なわれる可能性があるため、管理が阻害されます。
また、Exchange 2010 モデルでは、パッシブ コピーを格納するディスクは IOPS の観点から十分に活用されていません。 時間差パッシブ コピーの場合、アクティブ コピーおよび時間差でないパッシブ コピーの格納に使用されるディスクと比較して、IOPS の観点からディスクが十分に活用されていないだけでなく、そのサイズの観点から非対称でもあります。
Exchange 2013 以降は、JBOD 構成でより効率的に大きなディスク (8 テラバイト) を使用するように最適化されています。 ディスクごとに複数のデータベースを使用すると、遅延コピーを含む複数のデータベース コピーを格納する同じサイズのディスクを作成できるようになりました。 目標は、存在する複数のボリュームにユーザーを分散し、通常の運用中に、各 DAG メンバーが同じボリューム上にアクティブ、パッシブおよび時間差コピー (オプション) の組み合わせをホストする対称的なデザインを提供することです。
ボリュームごとに複数のデータベースを使用する構成の例を、以下に図示します。
ボリュームごとに複数のデータベースを使用する構成
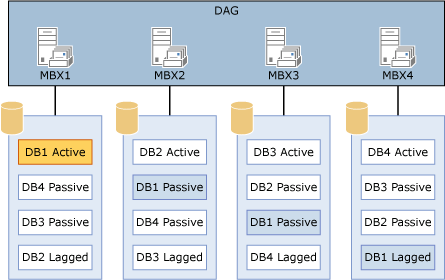
図の構成は、対称的な設計を提供します。 4 つのサーバーはすべて、サーバーごとに 1 つのディスクでホストされている同じ 4 つのデータベースを持ちます。 キーは、持っている各データベースのコピー数が、ディスクあたりのデータベース コピー数と等しい必要があるということです。
この図の構成には、各データベースの 4 つのコピーがあります。1 つのアクティブ コピー、2 つのパッシブ コピー、および 1 つの遅延コピーです。 各データベースには 4 つのコピーがあるため、適切な構成はボリュームごとに 4 つのコピーを持つ 1 つです。
さらに、アクティブ化の基本設定は、DAG と各サーバー間でバランスが取るように構成されます。 以下に例を示します。
アクティブなコピーのアクティブ化優先値は 1 になります。
最初のパッシブ コピーのアクティブ化優先値は 2 になります。
2 番目のパッシブ コピーのアクティブ化優先値は 3 になります。
遅延コピーのアクティブ化優先値は 4 になります。
既存のボリューム間でのユーザーの分散が向上するだけでなく、ディスクごとに複数のデータベースを使用するもう 1 つの利点は、再シードが必要な障害 (ディスク障害など) に対するデータ保護を復元する時間の短縮です。
データベースが大きくなるほど、データベースの再シードに要する時間は長くなります。 たとえば、2TB のデータベースは再シードに 23 時間かかるのに対して、8TB のデータベースは再シードに最長で 93 時間 (ほぼ 4 日間) かかります。 どちらのシードも約 20 MB/秒 で行われます。 これは一般的に、非常に大きなデータベースは運用で許容可能な時間内にシードできないということを意味します。
ディスクごとに 1 つのデータベース コピーのシナリオの場合、シード処理は、常に 1 つのソースからディスクをシード処理するため、実質的にソース バインドされます。
ボリュームを複数のデータベース コピーに分割し、指定されたボリューム上のパッシブ データベースのアクティブ コピーを個別の DAG メンバーに格納することで、システムはディスクの再シードのコンテキストでソース バインドされなくなります。 障害が発生したディスクが置き換えられると、複数のソースから再シードできます。 これにより、システムは、これらのデータベースのデータ保護を大幅に短時間で再シードして復元できます。
ボリュームごとに複数のデータベースを使用する場合は、次のベスト プラクティスと要件に従うことをお勧めします。
物理ディスクごとに 1 つの論理ディスクのパーティションを使用する必要があります。 ディスク上に複数のパーティションを作成しないでください。 各データベース コピーと付随するファイル (トランザクション ログやコンテンツ インデックスなど) は、1 つのパーティションの一意のディレクトリにホストされている必要があります。
1 つのボリュームに構成されたデータベース コピーの数は、各データベースのコピーの数と一致する必要があります。 たとえば、データベースのコピーが 4 つある場合、ボリュームごとに 4 つのデータベース コピーを使用する必要があります。
データベース コピーには、同じネイバーが必要です。 (たとえば、すべてのサーバーで同じディスクを共有する必要があります)。
DAG にまたがるアクティブ化の優先順位をバランス調整し、指定されたディスク上にある各データベース コピーのアクティブ化優先順位の値が一意になるようにする必要があります。
AutoReseed
自動再シード (AutoReseed とも呼ばれます) は、ディスク障害、データベース破損イベント、またはデータベース コピーの再シードを必要とするその他の問題に応答して、通常は管理者主導のアクションに代わるものです。 AutoReseed は、ディスクの障害発生後にシステムでプロビジョニング済みの予備のディスクを使用して、自動的にデータベースの冗長性を復元するように設計されています。
詳細については、「AutoReseed」を参照してください。 AutoReseed の構成手順の詳細については、「データベース可用性グループの AutoReseed の構成」を参照してください。
ストレージ障害からの自動回復
ストレージ障害からの自動復旧により、システムは回復性または冗長性に影響を与える障害から回復できます。 Exchange 2010 で導入されたバグチェック動作に加えて、Exchange には、長い I/O 時間の追加の回復動作、Microsoft Exchange レプリケーション サービスによる過剰なメモリ消費 (MSExchangeRepl.exe)、スレッドをスケジュールできない重大なケースが含まれるようになりました。
JBOD 環境においても、クラッシュやハングといったストレージ アレイ コントローラーの問題が発生する場合があります。 次の表に、強化された回復性を提供するハングした I/O 検出機能と回復機能を提供する機能を示します。
| 名前 | チェック | アクション | しきい値 |
|---|---|---|---|
| ESE データベースのハング IO 検出 | ESE は突出した I/O をチェックします | クリムゾン チャネルで障害項目を生成してサーバーを再起動します | 240 秒 |
| 障害項目チャネルのハートビート | 障害項目がクリムゾン チャネルに対して書き込みと読み取りができることを確認します | レプリケーション サービスはクリムゾン チャネルにハートビートを送信して障害のあるサーバーを再起動します | 30 秒 |
| システム ディスクのハートビート | サーバーのシステム ディスクの状態を確認します | システム ディスクに対して非バッファー I/O を定期的に送信し、ハートビートがタイムアウトするとサーバーを再起動します | 120 秒 |
Exchange 2013 以降では、他の重大な条件に対する動作を含めることで、サーバーとストレージの回復性が強化されます。 次の表で、これらの状況と動作について説明します。
| 名前 | チェック | アクション | しきい値 |
|---|---|---|---|
| 問題があるシステムの状態 | スレッド (非管理スレッドを含む) をスケジュールできない | サーバーを再起動する | 302 秒 |
| 実行時間の長い I/O | I/O 操作の遅延の測定 | サーバーを再起動する | 41 秒 |
| レプリケーション サービスのメモリ使用量 | MSExchangeRepl.exe のワーキング セットの測定 | 1: サービス終了要求を含む真紅のチャネルでイベント 4395 をログに記録する 2: MSExchangeRepl.exeの終了を開始する 3: サービスの終了に失敗した場合は、サーバーを再起動します |
4 ギガバイト (GB) |
| システム イベント 129 (バス リセット) | システム イベント ログでイベント 129 をチェックする | サーバーを再起動する | イベントが発生した場合 |
| クラスター データベースのハングアップ | グローバル更新マネージャーの更新プログラムがブロックされた場合 | サーバーを再起動する | イベントが発生した場合 |
時間差コピーの機能強化
時間差コピーの機能強化には、セーフティ ネットとの統合および特定のシナリオにおけるログ ファイルの自動再生が含まれます。 Exchange 2013 では、トランスポート ダンプと呼ばれる Exchange 2010 機能を置き換えるために、セーフティ ネットが導入されました。 Safety Net は、メールボックス サーバー上のトランスポート サービスに関連付けられている配信キューであるという点で、トランスポート ダンプスターに似ています。 このキューは、メールボックス サーバー上のアクティブなメールボックス データベースに正常に配信されたメッセージのコピーを格納します。 メールボックス サーバー上のそれぞれのアクティブなメールボックス データベースには、配信されたメッセージのコピーを格納する自身のキューがあります。 セーフティ ネットが、正常に配信されたメッセージのコピーを期限切れで自動的に削除するまで保存する期間を指定できます。
セーフティ ネットは、DAG 環境におけるシャドウ冗長性から一部の責任を引き継ぎます。 配信されたメッセージが、DAG の他のメールボックス サーバーにあるメールボックス データベースのパッシブ コピーにレプリケートされるのを待機している間は、DAG 環境では、シャドウ冗長がシャドウ キューの配信されたメッセージの別のコピーを保持する必要はありません。 配信されたメッセージのコピーは既にセーフティ ネットに保存されていますので、必要に応じてシャドウ冗長はメッセージをセーフティ ネットから再配信できます。
Safety Net では、遅延データベース コピーのアクティブ化が容易になります。 たとえば、2 日間の時間差がある時間差コピーがあると仮定します。 その場合、セーフティ ネットを 2 日間で構成します。 遅延コピーを使用する必要がある状況が発生した場合は、次のことができます。
それに対するレプリケーションを一時停止します。
それを 2 回コピーします (データベースの遅延の性質を維持し、必要に応じて追加のコピーを作成します)。
コピーを作成し、必要な範囲のログ ファイルを除くすべてのログ ファイルを破棄します。
コピーをマウントすると、直近 2 日間のメールを再配信するようセーフティ ネットに対して自動要求をトリガーします。
セーフティ ネットでは、破損のポイントが導入された時点以降、これ以上の破損は起こりません。 直近 2 日間のメールを取り戻すことはできますが、当然、損失の大きいフェールオーバーで普通に失われたデータを除きます。
時間差コピーは、自動ログ再生を起動してログ ファイルを再生することで、特定のシナリオで自身を管理できるようになりました。
低ディスク容量のしきい値に達した場合
時間差コピーに物理的な破損があり、ページ パッチが必要な場合
24 時間を超える期間、正常なコピー (アクティブまたはパッシブのみ - 時間差データベース コピーは含まれません) が 3 つ未満の場合
Exchange 2010 では、時間差コピーにはページ パッチは利用できませんでした。 Exchange 2013 以降では、ページ修正プログラムは、この自動再生ダウン機能を通じて遅延コピーに使用できます。 時間差コピーに対してページ パッチが必要であることが検知されると、ログが自動的に時間差コピーに対して再生され、ページ パッチが実行されます。 時間差コピーでは、低ディスク容量のしきい値に達した場合、および時間差コピーが特定の時間帯において唯一の利用可能なコピーであると検知された場合にも、この自動再生機能が呼び出されます。
遅延コピーのログ再生動作は既定では無効で、有効にするには次のコマンドを実行します。
Set-DatabaseAvailabilityGroup <DAGName> -ReplayLagManagerEnabled $true
有効にすると、コピーが 3 つ未満の場合にログ再生が発生します。 次の DWORD レジストリ値を変更することで、既定値の 3 を変更できます。
HKLM\Software\Microsoft\ExchangeServer\v15\Replay\Parameters\ReplayLagManagerNumAvailableCopies
低ディスク容量のしきい値に対するログ再生を有効にするには、次のレジストリ エントリを構成する必要があります。
HKLM\Software\Microsoft\ExchangeServer\v15\Replay\Parameters\ReplayLagLowSpacePlaydownThresholdInMB
これらのレジストリ設定を構成した後、Microsoft Exchange DAG 管理サービスを再開して、変更を有効にします。
たとえば、特定のデータベースに 4 つのコピー (3 つの高可用性コピーと 1 つの遅延コピー) があり、既定の設定が ReplayLagManagerNumAvailableCopies に使用されている環境を考えてみましょう。 何らかの理由 (一時停止など) により時間差でないコピーのサービスが停止していると、自動的に時間差コピーが 24 時間内のログ ファイルを再生します。
単一コピーの警告の機能強化
サーバーが確実に動作していること、およびメールボックス データベースのコピーが正常であることを確認することは、毎日の Exchange メッセージング操作の主な目的です。 ハードウェア、Windows オペレーティング システム、および Exchange サービスをアクティブに監視する必要があります。
ただし、Exchange メールボックスの回復性環境では、DAG とメールボックス データベースのコピーの正常性と状態を監視することが重要です。 データ冗長性のリスク管理を行い、レプリケートされたデータベースがただ 1 つのコピーになった期間を監視することは特に重要です。 これは、独立ディスクの冗長アレイ (RAID) を使用せず、代わりに JBOD 構成をデプロイする環境では重要です。 RAID 環境では、単一のディスクの障害がアクティブ メールボックス データベースのコピーに影響を及ぼすことはありません。 ただし、JBOD 環境では単一ディスクの障害によってデータベースのフェールオーバーがトリガーされます。
CheckDatabaseRedundancy.ps1 スクリプトは Exchange 2010 で導入されました。 その名前が示すように、スクリプトの目的は、少なくとも 2 つの構成済み、正常なコピー、および現在のコピーがあることを検証することで、レプリケートされたメールボックス データベースの冗長性を監視し、レプリケートされたデータベースの正常なコピーが 1 つだけ存在する場合にイベント ログ生成を通じて管理者に警告することでした。 この場合、冗長性を決定するときにアクティブコピーとパッシブコピーの両方がカウントされます。
以下は、コピーが 1 つしかない状態の例の一部です。
アクティブ コピーからパッシブ コピーへのレプリケートの失敗。
すべてのパッシブ コピーの失敗。これには、ログのコピーまたは再生でコピーが背後にある正常な状態に加えて、FailedAndSuspended 状態と Failed 状態が含まれます。 遅延コピーは、ログをラグ期間まで再生するのに 10 分以内であれば、後ろとは見なされません。
アクティブ コピーの現在のログ世代を正確に把握するシステムの障害。
管理者にとって、データベースの正常なコピーが 1 つだけになっている状態を把握することは最優先なため、CheckDatabaseRedundancy.ps1 スクリプトは、可用性管理の DataProtection 正常性セットに含まれる、統合されたネイティブな機能に置き換えられました。
ネイティブ機能は引き続きイベント ログ通知を通じて管理者に警告し、Exchange 2013 以降のアラートを Exchange 2010 と区別するために、Exchange では次のイベント ID が使用されるようになりました。
イベント 4138 (赤色の警告)
イベント 4139 (緑色の警告)
ネイティブ機能が強化され、同じサーバー上の複数のデータベースが 1 つのコピー条件に入ったときに発生するアラート ノイズを軽減しました。 Exchange 2010 では、1 つのコピーの警告はデータベースごとのレベルで生成されていました。 その結果、複数のデータベースと複数のデータベース コピーに影響を与えたサーバー全体の問題により、アラート ストームが発生する可能性があります。 複数の障害がサーバー全体 (コントローラーやメモリの問題など) であるため、サーバー インシデントごとにアラート ストームが発生する可能性が高かったです。
これで、サーバーごとにアラートが生成されるようになりました。 障害がサーバー全体に影響を与え、複数のデータベース コピーでデータ冗長性が危険にさらされると、サーバーごとに 1 つのアラートが生成されます。
DAG ネットワークの自動構成
DAG ネットワークは、レプリケーション トラフィックまたは MAPI トラフィックのいずれかに使用する 1 つまたは複数のサブネットの集合です。 DAG ごとに、最大 1 つの MAPI ネットワークと 0 または 1 つ以上のレプリケーション ネットワークが含まれます。
Exchange 2010 では、クラスター サービスによって列挙されたサブネットに基づいて、最初の DAG ネットワーク (DAGNetwork01 や DAGNetwork02 など) がシステムによって作成されました。 複数のネットワークがあり、指定されたネットワークのインターフェイス (MAPI ネットワークなど) が同じサブネット上に存在する場合は、追加の構成がほとんど必要ありませんでした。 ただし、指定したネットワークのインターフェイスが複数のサブネット上にある場合は、DAG ネットワークの折りたたみと呼ばれるタスクを実行する必要がありました。
Exchange 2013 以降では、DAG ネットワークの折りたたみは不要になります。 Exchange では、MAPI ネットワークとレプリケーション ネットワークを区別するために同じ検出メカニズムが引き続き使用されますが、必要に応じて自動的に DAG ネットワークが折りたたまれるようになりました。
さらに、DAG ネットワークが既定でシステムによって自動的に管理されるようになりました。 Exchange 管理センター (EAC) を使用して DAG ネットワーク プロパティを表示するには、EAC を使用して DAG のプロパティを変更するか、 Set-DatabaseAvailabilityGroup コマンドレットを使用して ManualDagNetworkConfiguration パラメーターを に設定して、手動ネットワーク制御用に DAG を構成する $true必要があります。
最適なコピー選択に対する変更
最適なコピー選択 (BCS) は、個別のデータベースの最適なコピーを見つけてアクティブにするための内部のアルゴリズム処理で、アクティブにする可能性のあるコピーとその正常性および状態の一覧が渡されます。 アクティブ マネージャーは、既存のアクティブなデータベース コピーに障害が発生した場合または管理者がターゲットを指定せずに切り替えを実行した場合に、新しいアクティブなデータベースとなる最適で利用可能な (ブロックされていない) コピーを選択します。 Exchange 2010 では、BCS プロセスが各データベース コピーの複数の側面を評価して、アクティブ化する最良のコピーを判別しました。 これらには次のようなものがあります。
キューの長さをコピー
再生キューの長さ
データベースの状態
コンテンツ インデックスの状態
Exchange 2013 以降では、Active Manager は同じ BCS チェックとフェーズを実行してレプリケーションの正常性を判断しますが、正常性状態の順序を減らす制約の使用も含まれるようになりました。 これらの変更の結果、BCS は最適なコピーおよびサーバーの選択 (BCSS) と呼ばれるようになりました。
BCSS には、Exchange の組み込みのマネージド可用性監視コンポーネントの一部であるいくつかの新しい正常性チェックが含まれています。 Active Manager によって実行される追加のチェックは 4 つあります (実行順に一覧表示されます)。
すべての正常: すべての監視コンポーネントが正常な状態にある影響を受けるデータベースのコピーをホストしているサーバーを確認します。
正常な状態まで: 影響を受けるデータベースのコピーをホストしているサーバーが、正常な状態で標準優先度のすべての監視コンポーネントを持っていることを確認します。
ソースよりすべて: 影響を受けるコピーをホストしている現在のサーバーよりも優れた状態の監視コンポーネントを持つ、影響を受けるデータベースのコピーをホストしているサーバーをチェックします。
ソースと同じ: 影響を受けるコピーをホストしている現在のサーバーと同じ状態の監視コンポーネントを持つ、影響を受けるデータベースのコピーをホストしているサーバーを確認します。
可用性管理の監視コンポーネント (フェールオーバー レスポンダー経由など) によってトリガーされたフェールオーバーの結果、BCSS が起動されると、ターゲット サーバーのコンポーネントの正常性は、フェールオーバーが発生したサーバー以上でなければならないという追加の必須の制約が強制されます。 たとえば、Outlook on the webの障害 (旧称 Outlook Web App) によってフェールオーバー レスポンダー経由のマネージド 可用性フェールオーバーがトリガーされた場合、BCSS は、Outlook on the webが正常である影響を受けるデータベースのコピーをホストするサーバーを選択する必要があります。
DAG Management サービス
Exchange 2013 CU2 以降には、Microsoft Exchange DAG 管理サービス (MSExchangeDAGMgmt) が含まれています。 このサービスには、以前は Microsoft Exchange レプリケーション サービス (MSExchangeRepl) 内にあった内部 DAG 監視機能が含まれています。
クラスター管理アクセス ポイントなしの DAG
Windows Server 2008 R2 または Windows Server 2012 を実行している Exchange サーバー上のすべての DAG には、MAPI ネットワークに含まれるすべてのサブネットに少なくとも 1 つの IP アドレスが必要です。 DAG に割り当てられた IP アドレスは、クラスター名を使用してクラスターへの名前解決および接続 (具体的には、現在クラスター コア リソース グループを所有するクラスター メンバーへの接続) を有効にするために、クラスターの管理アクセス ポイント (クラスター ネットワーク名とも呼ばれます) が設定された DAG のクラスターにより使用されます。
R2 以降Windows Server 2012使用すると、管理アクセス ポイントなしでフェールオーバー クラスターを作成できます。 管理アクセス ポイントを使用しない Windows フェールオーバー クラスターには、次のような特性があります。
クラスターに IP アドレスが割り当てられていないため、クラスター コア リソース グループに IP アドレス リソースはありません。
クラスターにネットワーク名が割り当てられていないため、クラスター コア リソース グループにネットワーク名リソースはありません。
クラスターの名前は DNS に登録されておらず、クラスター名はネットワーク上で解決できません。
クラスター名オブジェクト (CNO) は Active Directory に作成されません。
フェールオーバー クラスター管理ツールを使用して Windows フェールオーバー クラスターを管理することはできません。 代わりに、Windows PowerShellを使用する必要があり、個々のクラスター メンバーに対して PowerShell コマンドレットを実行する必要があります。
Windows Server 2012 R2 以降で Exchange で実行されている Exchange 2013 SP1 以降を使用すると、クラスター管理アクセス ポイントなしで DAG を作成できます。 詳細については、「DAG の作成」および「データベース可用性グループを作成する」を参照してください。