Microsoft Entra Conect 同期: アーキテクチャの解釈
このトピックでは、Microsoft Entra Connect Sync の基本的なアーキテクチャについて説明します。以前の ID 同期テクノロジーに慣れているユーザーは、このトピックの内容もすぐに理解できるでしょう。 同期テクノロジについて初めて学ぶ場合は、このトピックを読むことをお勧めします。 ただし、このトピックの内容を隅々まで理解しなくても、(このトピックでは同期エンジンと呼んでいる) Microsoft Entra Connect 同期を問題なくカスタマイズできます。
アーキテクチャ
同期エンジンは、接続された複数のデータ ソースに格納されているオブジェクトの統合ビューを作成し、それらのデータ ソース内の ID 情報を管理します。 統合ビューは、接続されたデータ ソースから取得された ID 情報と、この情報の処理方法を指定する一連のルールによって決まります。
接続されたデータ ソースとコネクタ
同期エンジンは、Active Directory や SQL Server データベースなどのさまざまなデータ リポジトリからの ID 情報を処理します。 データベースのような形式でデータを管理し、標準的なデータ アクセス メソッドを提供するすべてのデータ リポジトリが、同期エンジンのデータ ソースの候補になります。 同期エンジンによって同期されるデータ リポジトリは、接続されたデータ ソースまたは接続されたディレクトリ (CD) と呼ばれます。
同期エンジンは、接続されたデータ ソースとの対話を コネクタと呼ばれるモジュール内にカプセル化します。 接続されたデータ ソースの種類ごとに専用のコネクタがあります。 コネクタは、必要な操作を接続されたデータ ソースが理解する形式に変換します。
コネクタは、API 呼び出しを行って、接続されたデータ ソースと ID 情報を交換します (読み取りと書き込みの両方)。 また、拡張可能な接続フレームワークを使用してカスタム コネクタを追加することもできます。 次の図では、コネクタが接続されたデータ ソースを同期エンジンに接続する方法を示します。
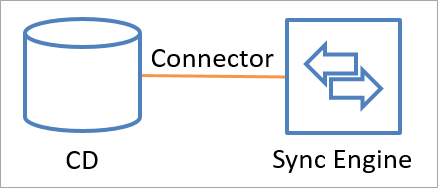
データはどちらの方向にも流れることができますが、同時に双方向に流れることはできません。 つまり、コネクタは、接続されたデータ ソースから同期エンジンへの、または同期エンジンから接続されたデータ ソースへの、データ フローを許可するように構成できますが、1 つのオブジェクトと属性について一度に実行できる操作は 1 つだけです。 方向は、オブジェクトごと、および属性ごとに異なっていてもかまいません。
コネクタを構成するには、同期するオブジェクトの種類を指定します。 オブジェクトの種類を指定することで、同期プロセスに含まれるオブジェクトの範囲を定義します。 次に、同期する属性を選択します。これは、対象属性リストと呼ばれます。 これらの設定は、ビジネス ルールの変化に対応していつでも変更できます。 Microsoft Entra Connect インストール ウィザードを使用すると、これらの設定が自動的に構成されます。
接続されたデータ ソースにオブジェクトをエクスポートするには、対象属性リストに、接続されたデータ ソースで特定のオブジェクトの種類を作成するために必要な最低限の属性が含まれる必要があります。 たとえば、Active Directory にユーザー オブジェクトをエクスポートするには、sAMAccountName 属性が対象属性リストに含まれる必要があります。なぜなら、Active Directory のすべてのユーザー オブジェクトでは、sAMAccountName 属性が定義されている必要があるためです。 繰り返しになりますが、この構成はインストール ウィザードによって自動的に行われます。
接続されたデータ ソースがパーティションやコンテナーなどの構造化されたコンポーネントを使用してオブジェクトを管理している場合、特定のソリューションに使用される接続されたデータ ソースの領域を制限できます。
同期エンジンの名前空間の内部構造
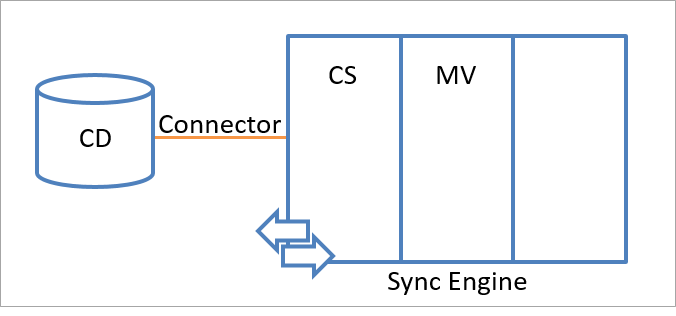
同期エンジンの名前空間全体は、ID 情報を格納する 2 つの名前空間で構成されます。 次の 2 つの名前空間です。
- コネクタ スペース (CS)
- メタバース (MV)
コネクタ スペース は、接続されたデータ ソースの指定されたオブジェクトの表現と、対象属性リストで指定されている属性を含む、ステージング領域です。 同期エンジンはコネクタ スペースを使用して、接続されたデータ ソースの変更内容を確認し、受信した変更をステージングします。 また、同期エンジンは、接続されたデータ ソースへのエクスポート用に送信する変更をステージングするためにも、コネクタ スペースを使用します。 同期エンジンは、各コネクタに対するステージング領域として、個別のコネクタ スペースを保持します。
ステージング領域を使用することにより、同期エンジンは接続されたデータ ソースからの独立を維持し、接続されたデータ ソースの可用性やアクセス可能性による影響を受けません。 その結果、ステージング領域のデータを使用して、いつでも ID 情報を処理できます。 同期エンジンは、最後の通信セッションが終了した後で接続されたデータ ソースの内部で行われた変更のみを要求したり、接続されたデータ ソースがまだ受信していない ID 情報の変更だけをプッシュしたりできるので、同期エンジンと接続されたデータ ソースの間のネットワーク トラフィックが減ります。
さらに、同期エンジンはコネクタ スペースにステージングしているすべてのオブジェクトに関するステータス情報を保持します。 新しいデータを受信すると、同期エンジンはデータが既に同期されているかどうかを常に評価します。
メタバース は、複数の接続されたデータ ソースからの集約された ID 情報を格納するストレージ領域であり、すべての結合されたオブジェクトに関する単一のグローバルな統合ビューを提供します。 メタバース オブジェクトは、接続されたデータ ソースから取得された ID 情報と、同期プロセスをカスタマイズできる一連のルールを基にして作成されます。
次の図では、同期エンジン内のコネクタ スペース名前空間とメタバース名前空間を示します。
同期エンジンの ID オブジェクト
同期エンジンのオブジェクトは、接続されたデータ ソース内のオブジェクト、または同期エンジンが保持するこれらのオブジェクトの統合ビューのいずれかを表現したものです。 すべての同期エンジン オブジェクトは、グローバル一意識別子 (GUID) を持つ必要があります。 GUID により、データの整合性と、オブジェクト間の高速の関係が提供されます。
コネクタ スペース オブジェクト
同期エンジンは、接続されたデータ ソースと通信するとき、接続されたデータ ソース内の ID 情報を読み取り、その情報を使用してコネクタ スペース内に ID オブジェクトの表現を作成します。 これらのオブジェクトを個別に作成または削除することはできません。 ただし、コネクタ スペース内のすべてのオブジェクトを手動で削除することはできます。
コネクタ スペース内のすべてのオブジェクトには 2 つの属性があります。
- グローバル一意識別子 (GUID)
- 識別名 (DN)
接続されたデータ ソースが固有の属性をオブジェクトに割り当てている場合、コネクタ スペース内のオブジェクトはアンカー属性を持つこともできます。 アンカー属性は、接続されたデータ ソース内のオブジェクトを一意に識別します。 同期エンジンは、アンカーを使用して、接続されたデータ ソース内でこのオブジェクトの対応する表現を見つけます。 同期エンジンは、オブジェクトの有効期間全体を通してオブジェクトのアンカーが変化しないものと想定します。
コネクタの多くは、オブジェクトをインポートするときに、既知の一意の識別子を使用して各オブジェクトのアンカーを自動的に生成します。 たとえば、Active Directory コネクタは objectGUID 属性をアンカーに使用します。 接続されたデータ ソースが明確に定義された一意の識別子を提供しない場合は、コネクタ構成の一部としてアンカーの生成を指定できます。
その場合、アンカーは、いずれも変化せず、コネクタ スペース内のオブジェクトを一意に識別する、オブジェクトの種類が備える 1 つ以上の固有の属性から作成されます (たとえば、従業員番号やユーザー ID)。
コネクタ スペース オブジェクトは次のいずれかです。
- ステージング オブジェクト
- プレースホルダー
ステージング オブジェクト
ステージング オブジェクトは、指定されたオブジェクトの種類の接続されたデータ ソースでのインスタンスを表します。 GUID と識別名に加えて、ステージング オブジェクトはオブジェクトの種類を示す値を常に持ちます。
インポートされたステージング オブジェクトは常に、アンカー属性の値を持っています。 同期エンジンによって新しくプロビジョニングされ、接続されたデータ ソースで作成処理中のステージング オブジェクトには、アンカー属性の値はありません。
また、ステージング オブジェクトは、ビジネス属性の現在の値、および同期エンジンが同期プロセスを実行するために必要な運用情報も保持しています。 運用情報には、ステージング オブジェクトでステージングされている更新の種類を示すフラグが含まれます。 ステージング オブジェクトは、まだ処理されていない新しい ID 情報を接続されたデータ ソースから受け取ると、 インポート保留中のフラグを設定されます。 接続されたデータ ソースにまだエクスポートされていない新しい ID 情報を持つステージング オブジェクトには、 エクスポート保留中のフラグが設定されます。
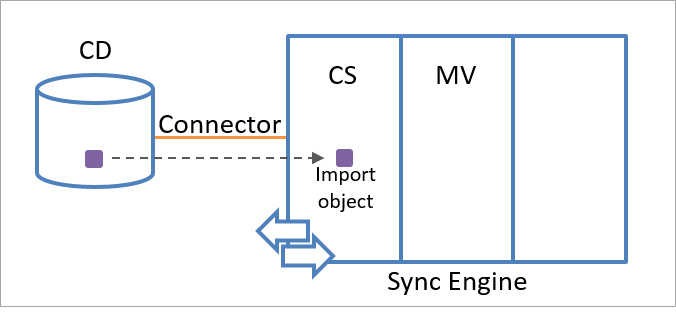
ステージング オブジェクトは、インポート オブジェクトまたはエクスポート オブジェクトです。 同期エンジンは、接続されたデータ ソースから受信したオブジェクト情報を使用して、インポート オブジェクトを作成します。 同期エンジンは、コネクタで選択されたオブジェクトの種類のいずれかに一致する新しいオブジェクトの存在に関する情報を受信すると、接続されたデータ ソース内のオブジェクトの表現として、コネクタ スペースにインポート オブジェクトを作成します。
次の図は、接続されたデータ ソース内のオブジェクトを表すインポート オブジェクトを示したものです。
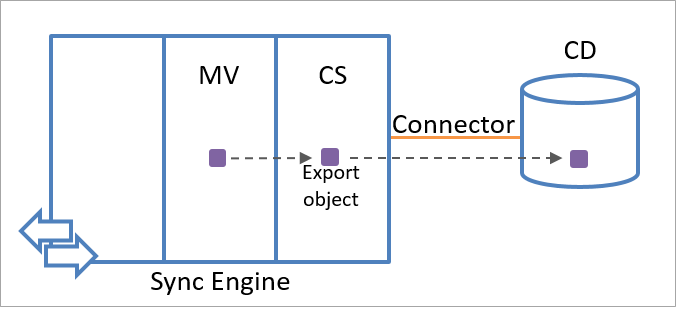
同期エンジンは、メタバースのオブジェクト情報を使用して、エクスポート オブジェクトを作成します。 エクスポート オブジェクトは、次の通信セッションの間に接続されたデータ ソースにエクスポートされます。 同期エンジンから見ると、エクスポート オブジェクトは接続されたデータ ソースにまだ存在していません。 そのため、エクスポート オブジェクトのアンカー属性は使用できません。 接続されたデータ ソースは、同期エンジンからオブジェクトを受信した後、オブジェクトのアンカー属性用に一意の値を作成します。
次の図では、メタバース内の ID 情報を使用してエクスポート オブジェクトが作成される方法を示します。
同期エンジンは、接続されたデータ ソースからオブジェクトを再インポートすることによって、オブジェクトのエクスポートを確認します。 その接続されたデータ ソースからの次のインポート中に同期エンジンがオブジェクトを受信すると、エクスポート オブジェクトはインポート オブジェクトになります。
プレースホルダー
同期エンジンは、フラットな名前空間を使用してオブジェクトを格納します。 ただし、Active Directory などの一部の接続されたデータ ソースは、階層形式の名前空間を使用します。 階層型名前空間からフラットな名前空間に情報を変換するため、同期エンジンはプレースホルダーを使用して階層を維持します。
各プレースホルダーは、同期エンジンにインポートされていないが、階層の名前を作成するために必要な、オブジェクトの階層名のコンポーネントを表します (たとえば、組織単位) 。 プレースホルダーは、コネクタ スペースのステージング オブジェクトではないオブジェクトに対する、接続されたデータ ソース内の参照によって作成されたギャップを埋めます。
また、同期エンジンは、まだインポートされていない参照先オブジェクトの格納にもプレースホルダーを使用します。 たとえば、Abbie Spencer オブジェクトのマネージャー属性を含むように同期が構成されていて、受信した値がまだインポートされていないオブジェクトである場合 (CN=Lee Sperry,CN=Users,DC=fabrikam,DC=com など)、マネージャー情報はプレースホルダーとしてコネクタ スペースに格納されます。 後でマネージャー オブジェクトがインポートされると、プレースホルダー オブジェクトはマネージャーを表すステージング オブジェクトによって上書きされます。
メタバース オブジェクト
メタバース オブジェクトには、同期エンジンが保持する、コネクタ スペース内のステージング オブジェクトの集約されたビューが含まれます。 同期エンジンは、インポート オブジェクトの情報を使用してメタバース オブジェクトを作成します。 複数のコネクタ スペース オブジェクトを 1 つのメタバース オブジェクトにリンクできますが、1 つのコネクタ スペース オブジェクトを複数のメタバース オブジェクトにリンクすることはできません。
メタバース オブジェクトは、手動で作成または削除することはできません。 同期エンジンは、コネクタ スペース内のどのコネクタ スペース オブジェクトにもリンクしなくなったメタバース オブジェクトを自動的に削除します。
接続されたデータ ソースのオブジェクトをメタバース内の対応するオブジェクトの種類にマップするため、同期エンジンは、オブジェクトの種類と関連する属性の定義済みのセットを含む拡張可能なスキーマを提供します。 メタバース オブジェクトに対する新しいオブジェクトの種類と属性を作成できます。 属性は単一値でも複数値でもよく、属性の型は文字列、参照、数値、およびブール値を使用できます。
ステージング オブジェクトとメタバース オブジェクトの間の関係
同期エンジンの名前空間内のデータ フローは、ステージング オブジェクトとメタバース オブジェクトの間のリンク関係によって実現されます。 メタバース オブジェクトにリンクされているステージング オブジェクトは、結合オブジェクト (またはコネクタ オブジェクト) と呼ばれます。 メタバース オブジェクトにリンクされていないステージング オブジェクトは、非結合オブジェクト (または非コネクタ オブジェクト) と呼ばれます。 接続されたディレクトリのデータのインポートとエクスポートを行うコネクタと混乱しないよう、結合および非結合という用語の方を使います。
プレースホルダーがメタバース オブジェクトにリンクされることはありません。
結合オブジェクトは、ステージング オブジェクトと、1 つのメタバース オブジェクトに対するそのリンク関係によって構成されます。 結合オブジェクトは、コネクタ スペース オブジェクトとメタバース オブジェクトの間で属性値を同期するために使用されます。
同期の間にステージング オブジェクトが結合オブジェクトになると、ステージング オブジェクトとメタバース オブジェクトの間を属性がフローできるようになります。 属性フローは双方向であり、インポート属性ルールとエクスポート属性ルールを使用して構成されます。
1 つのコネクタ スペース オブジェクトは、1 つのメタバース オブジェクトだけとリンクできます。 ただし、次の図に示すように、各メタバース オブジェクトは、同じコネクタ スペース内または異なるコネクタ スペース内の複数のコネクタ スペース オブジェクトにリンクできます。
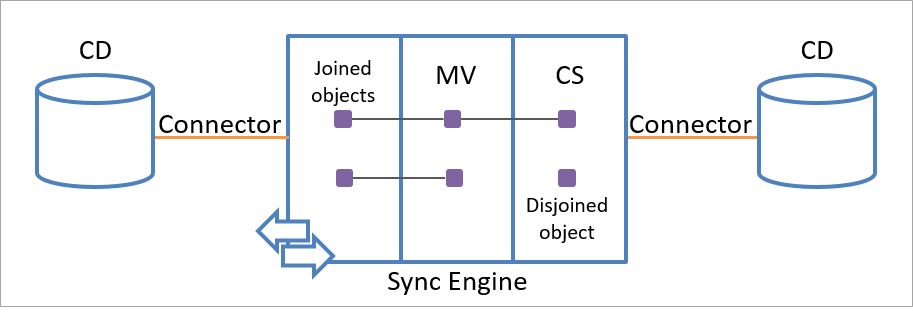
ステージング オブジェクトとメタバース オブジェクトのリンク関係は永続的であり、ルールを指定することによってのみ削除できます。
非結合オブジェクトは、どのメタバース オブジェクトにもリンクされていないステージング オブジェクトです。 非結合オブジェクトの属性値は、メタバース内ではそれ以上処理されません。 接続されたデータ ソース内の対応するオブジェクトの属性値は、同期エンジンによって更新されません。
非結合オブジェクトを使用すると、ID 情報を同期エンジンに保存して、後で処理できます。 コネクタ スペース内に非結合オブジェクトとしてステージング オブジェクトを保持することには、多くの利点があります。 システムはこのオブジェクトに関する必要な情報を既にステージングしてあるため、接続されたデータ ソースからの次のインポート時に再びこのオブジェクトの表現を作成する必要はありません。 これにより、現在は接続されたデータ ソースへの接続がなくても、同期エンジンは接続されたデータ ソースの完全なスナップショットを常に持っています。 ルールを指定することで、非結合オブジェクトを結合オブジェクトに、または結合オブジェクトを非結合オブジェクトに変換できます。
インポート オブジェクトは、非結合オブジェクトとして作成されます。 エクスポート オブジェクトは結合オブジェクトである必要があります。 システムのロジックによりこの規則が適用され、結合オブジェクトではなくなったエクスポート オブジェクトはすべて削除されます。
同期エンジンの ID 管理プロセス
ID 管理プロセスは、異なる接続されたデータ ソース間で ID 情報を更新する方法を制御します。 ID 管理は 3 つのプロセスで行われます。
- [インポート]
- Synchronization
- エクスポート
インポート プロセスの間に、同期エンジンは接続されたデータ ソースから受信した ID 情報を評価します。 変更が検出されると、新しいステージング オブジェクトを作成するか、またはコネクタ スペース内の既存のステージング オブジェクトを同期用に更新します。
同期プロセスでは、同期エンジンは、コネクタ スペース内で発生した変更を反映するようにメタバースを更新し、メタバース内で発生した変更を反映するようにコネクタ スペースを更新します。
エクスポート プロセスでは、同期エンジンは、ステージング オブジェクトにステージングされてエクスポート保留中のフラグが設定された変更をプッシュします。
次の図では、ある接続されたデータ ソースから別の接続されたデータ ソースに ID 情報が流れたときにどこで各プロセスが発生するかを示します。

インポート プロセス
インポート プロセスの間に、同期エンジンは ID 情報に対する更新を評価します。 同期エンジンは、接続されたデータ ソースから受信した ID 情報をステージング オブジェクトについての ID 情報と比較し、ステージング オブジェクトの更新が必要かどうかを判断します。 ステージング オブジェクトを新しいデータで更新する必要がある場合、ステージング オブジェクトにはインポート保留中のフラグが設定されます。
同期の前にコネクタ スペースにオブジェクトをステージングすることで、同期エンジンは変更のあった ID 情報だけを処理できます。 この処理には次のような利点があります。
- 効率的な同期。 同期中に処理されるデータの量を最小限にできます。
- 効率的な再同期。 同期エンジンをデータ ソースに再接続しなくても、同期エンジンによる ID 情報の処理方法を変更できます。
- 同期をプレビューする機会。 同期をプレビューして、ID 管理プロセスに関する仮定が正しいことを確認できます。
コネクタで指定されている各オブジェクトについて、同期エンジンは最初にコネクタのコネクタ スペース内でオブジェクトの表現の検索を試みます。 同期エンジンは、コネクタ スペース内のすべてのステージング オブジェクトを調べ、一致するアンカー属性を持つ対応するステージング オブジェクトを見つけようとします。 一致するアンカー属性を持つ既存のステージング オブジェクトがない場合、同期エンジンは、同じ識別名を持つ対応するステージング オブジェクトを検索します。
識別名だけ一致してアンカーは一致しないステージング オブジェクトが見つかると、次の特別な動作が行われます。
- コネクタ スペース内にあるオブジェクトがアンカーを持っていない場合は、同期エンジンはこのオブジェクトをコネクタ スペースから削除し、それがリンクしているメタバース オブジェクトを、 次の同期実行時にプロビジョニングを再試行とマークします。 その後、新しいインポート オブジェクトを作成します。
- コネクタ スペース内にあるオブジェクトがアンカーを持っている場合は、同期エンジンはこのオブジェクトが接続されたディレクトリで名前を変更されているか削除されているものとみなします。 コネクタ スペース オブジェクトに一時的な新しい識別名を割り当てて、受信したオブジェクトをステージングできるようにします。 古いオブジェクトは 一時的になり、コネクタが名前の変更または削除をインポートして状況を解決するのを待機します。
一時的なオブジェクトは、常に問題であるとは限りません。正常な環境でも発生することがあります。 Microsoft Entra Connect 同期 V2 エンドポイント API を使用すると、一時的なオブジェクトは、後続の差分同期サイクルで自動解決されます。 一時的なオブジェクトが生成される一般的な例の 1 つは、管理者が PowerShell を使用して Microsoft Entra で直接的にオブジェクトを完全に削除し、後でオブジェクトを再び同期する場合に、ステージング モードでインストールされた Microsoft Entra Connect サーバー上で発生します。
コネクタで指定されたオブジェクトに対応するステージング オブジェクトが見つかった場合、同期エンジンは適用する変更の種類を判断します。 たとえば、接続されたデータ ソースのオブジェクトの名前変更や削除、またはオブジェクトの属性値の更新だけなどです。
更新されたデータのあるステージング オブジェクトは、インポート保留中としてマークされます。 さまざまな種類のインポート保留中を利用できます。 インポート プロセスの結果に応じて、コネクタ スペース内のステージング オブジェクトには次のいずれかのインポート保留中種類が設定されます。
- なし。 ステージング オブジェクトのどの属性にも変更はありません。 同期エンジンはこのタイプにはインポート保留中のフラグを設定しません。
- 追加。 ステージング オブジェクトは、コネクタ スペース内の新しいインポート オブジェクトです。 同期エンジンは、メタバース内の追加処理のために、このタイプにインポート保留中のフラグを設定します。
- 更新。 同期エンジンは、コネクタ スペース内で対応するステージング オブジェクトを探し、属性への更新をメタバースで処理できるように、このタイプにインポート保留中フラグを設定します。 更新には、オブジェクトの名前変更が含まれます。
- 削除。 同期エンジンは、コネクタ スペース内で対応するステージング オブジェクトを探し、結合オブジェクトを削除できるように、このタイプにインポート保留中フラグを設定します。
- 削除/追加。 同期エンジンはコネクタ スペースで対応するステージング オブジェクトを検索しますが、オブジェクトの種類が一致しません。 その場合は、削除/追加の変更がステージングされます。 削除/追加の変更は、オブジェクトの種類が変わったときは異なるルール セットがそのオブジェクトに適用されるため、オブジェクトの完全な同期を行う必要があることを、同期エンジンに指示します。
ステージング オブジェクトのインポート保留中ステータスを設定することで、データが更新されたオブジェクトだけを処理できるので、同期中に処理されるデータの量を大幅に減らすことができます。
同期プロセス
同期は、2 つの関連するプロセスで構成されます。
- 受信同期: コネクタ スペース内のデータを使用して、メタバースの内容が更新されます。
- 送信同期: メタバース内のデータを使用して、コネクタ スペースの内容が更新されます。
コネクタ スペース内のステージングされた情報を使用することにより、受信同期プロセスは、接続されたデータ ソースに格納されているメタバースにデータの統合ビューを作成します。 ルールの構成方法に応じて、すべてのステージング オブジェクト、またはインポート保留中の情報があるステージング オブジェクトだけが集約されます。
送信同期プロセスは、メタバース オブジェクトが変化するとエクスポート オブジェクトを更新します。
受信同期は、接続されたデータ ソースから受信した ID 情報の統合ビューをメタバースに作成します。 同期エンジンは、接続されたデータ ソースからの最新の ID 情報を使用して、いつでも ID 情報を処理できます。
受信同期
受信同期には次のプロセスが含まれます。
- プロビジョニング (このプロセスを送信同期のプロビジョニングと区別することが重要な場合は、プロジェクションと呼ぶこともできます)。 同期エンジンは、ステージング オブジェクトに基づいて新しいメタバース オブジェクトを作成し、それらをリンクします。 プロビジョニングはオブジェクト レベルの操作です。
- 結合。 同期エンジンは、ステージング オブジェクトを既存のメタバース オブジェクトにリンクします。 結合はオブジェクト レベルの操作です。
- インポート属性フロー。 同期エンジンは、メタバース内のオブジェクトの属性フローと呼ばれる属性値を更新します。 インポート属性フローは、ステージング オブジェクトとメタバース オブジェクト間のリンクを必要とする属性レベルの操作です。
プロビジョニングは、メタバースにオブジェクトを作成する唯一のプロセスです。 プロビジョニングは、非結合オブジェクトであるインポート オブジェクトのみに影響します。 プロビジョニングの間に、同期エンジンは、インポート オブジェクトの種類に対応するメタバース オブジェクトを作成し、両方のオブジェクト間にリンクを確立することによって、結合オブジェクトを作成します。
結合プロセスも、インポート オブジェクトとメタバース オブジェクトの間にリンクを確立します。 結合とプロビジョニングの違いは、結合プロセスではインポート オブジェクトを既存のメタバース オブジェクトにリンクする必要があるのに対し、プロビジョニング プロセスでは新しいメタバース オブジェクトを作成することです。
同期エンジンは、同期ルールの構成で指定されている条件を使用して、メタバース オブジェクトへのインポート オブジェクトの結合を試みます。
プロビジョニング プロセスと結合プロセスの間に、同期エンジンは、非結合オブジェクトをメタバース オブジェクトにリンクすることによって両者を結合します。 これらのオブジェクト レベルの操作が完了した後、同期エンジンは、関連付けられたメタバース オブジェクトの属性値を更新できます。 このプロセスは、インポート属性フローと呼ばれます。
インポート属性フローは、新しいデータを保持し、メタバース オブジェクトにリンクされている、すべてのインポート オブジェクトで発生します。
送信同期
送信同期は、メタバース オブジェクトが変化しているものの、削除されていない場合に、エクスポート オブジェクトを更新します。 送信同期の目的は、メタバース オブジェクトへの変更によりコネクタ スペースのステージング オブジェクトを更新する必要があるかどうかを評価することです。 場合によっては、全コネクタ スペース内のステージング オブジェクトの更新が必要になります。 変更されたステージング オブジェクトは、エクスポート保留中のフラグが設定され、エクスポート オブジェクトになります。 このようなエクスポート オブジェクトは、その後、エクスポート プロセスの間に接続されたデータ ソースにプッシュされます。
送信同期には 3 つのプロセスがあります。
- プロビジョニング
- プロビジョニング解除
- エクスポート属性フロー
プロビジョニングとプロビジョニング解除は、どちらもオブジェクト レベルの操作です。 プロビジョニング解除を開始できるのはプロビジョニングだけなので、プロビジョニング解除はプロビジョニングに依存します。 プロビジョニングがメタバース オブジェクトとエクスポート オブジェクトの間のリンクを削除すると、プロビジョニング解除がトリガーされます。
プロビジョニングは、メタバース内のオブジェクトに変更が適用されると常にトリガーされます。 メタバース オブジェクトが変更されたとき、同期エンジンはプロビジョニング プロセスの一部として次のどのタスクでも実行できます。
- 結合オブジェクトの作成。新しく作成されたエクスポート オブジェクトにメタバース オブジェクトがリンクされます。
- 結合オブジェクトの名前の変更。
- メタバース オブジェクトとステージング オブジェクトの間のリンクの切断。これにより、非結合オブジェクトが作成されます。
プロビジョニングの間に同期エンジンが新しいコネクタ オブジェクトを作成する必要がある場合、オブジェクトは接続されたデータ ソースにまだ存在しないため、メタバース オブジェクトがリンクされるステージング オブジェクトは常にエクスポート オブジェクトです。
プロビジョニングにおいて同期エンジンが結合オブジェクトを切断することにより、非結合オブジェクトを作成する必要がある場合、プロビジョニング解除がトリガーされます。 プロビジョニング解除プロセスではオブジェクトが削除されます。
プロビジョニング解除では、エクスポート オブジェクトを削除してもオブジェクトが物理的に削除されることはありません。 オブジェクトには 削除のフラグが設定され、削除操作がそのオブジェクトでステージングされていることを示します。
送信同期プロセスではエクスポート属性フローも発生し、これは受信同期での属性フローのインポートと似ています。 エクスポート属性フローは、結合されているメタバース オブジェクトとエクスポート オブジェクトの間でのみ発生します。
エクスポート プロセス
エクスポート プロセスの間に、同期エンジンはコネクタ スペースでエクスポート保留中のフラグが設定されているすべてのエクスポート オブジェクトを調べて、接続されたデータ ソースに更新を送信します。
同期エンジンはエクスポートの成功を判断できますが、ID 管理プロセスが完了したことを十分に判断することはできません。 接続されたデータ ソース内のオブジェクトは、常に他のプロセスによって変更される可能性があります。 同期エンジンは接続されたデータ ソースへの永続的な接続を持たないため、エクスポート成功通知だけでは、接続されたデータ ソース内のオブジェクトのプロパティに関する判断を行うのに不十分です。
たとえば、接続されたデータ ソース内のプロセスがオブジェクトの属性を元の値に戻しているかもしれません (つまり、同期エンジンがデータをプッシュして接続されたデータ ソースに正常に適用した直後に、接続されたデータ ソースが値を上書きしている可能性があります)。
同期エンジンは、各ステージング オブジェクトに関するエクスポートとインポートのステータスの情報を保存しています。 前回のエクスポート以降に対象属性リストで指定されている属性の値が変化した場合、保存されているインポートとエクスポートのステータスにより同期エンジンは適切に対応できます。 同期エンジンは、インポート プロセスを使用して、接続されたデータ ソースにエクスポートされた属性値を確認します。 次の図に示すように、インポートされた情報とエクスポートされた情報を比較することで、同期エンジンは、エクスポートが成功したかどうか、または繰り返す必要があるかどうかを判断できます。
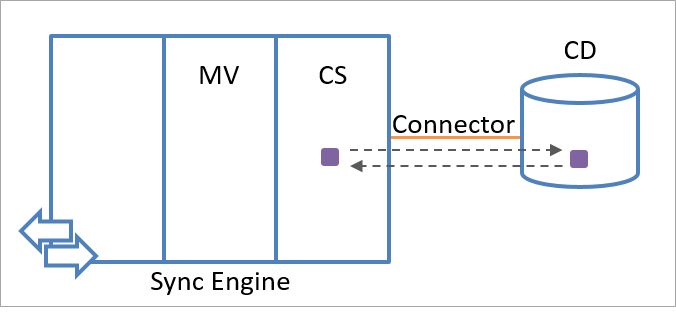
たとえば、同期エンジンが接続されたデータ ソースに対して属性 C をエクスポートし、その値が 5 である場合、同期エンジンはエクスポート ステータス メモリに C = 5 を格納します。 同期エンジンはこの値が永続的にオブジェクトに適用されていないものとみなすので (つまり、接続されたデータ ソースから最近別の値がインポートされていない限り)、このオブジェクトに対する追加の各エクスポートでは、接続されたデータ ソースへの C = 5 のエクスポートが再度試みられます。 オブジェクトのインポート操作で C = 5 を受信すると、エクスポート メモリはクリアされます。
次のステップ
Microsoft Entra Connect Sync の構成の詳細をご確認ください。
オンプレミス ID と Microsoft Entra ID の統合の詳細をご確認ください。