回復性のためにアプリケーションのサインインの正常性を監視する
インフラストラクチャの回復性を向上させるには、重要なアプリケーションを対象にアプリケーション サインイン 正常性の監視を設定します。 影響を及ぼすインシデントが発生したときに、アラートを受け取ることができます。 この記事では、ユーザーのサインインへの障害を監視するために、アプリ サインイン正常性ブックを設定する手順について説明します。
アプリ サインイン正常性ブックに基づいてアラートを構成できます。 このブックを使用すると、管理者はテナント内のアプリケーションに対する認証要求を監視できます。 次の主要な機能が用意されています。
- ほぼリアルタイムのデータを使用して、すべてまたは個別のアプリを監視するようにブックを構成します。
- 調査と対応ができるように、認証パターンの変更に対するアラートを構成します。
- 一定期間にわたる傾向を比較します。 週単位がブックの既定の設定です。
注意
「レポートに Azure Monitor ブックを使用する方法」内の使用可能なすべてのブックとそれらを使用するための前提条件を確認してください。
影響を及ぼすイベントが発生すると、2 つのことが発生する可能性があります。
- ユーザーがサインインできない場合、アプリケーションのサインイン回数が急激に減少する可能性があります。
- サインイン失敗の数が増加するおそれがあります。
前提条件
- Microsoft Entra テナント。
- 少なくともセキュリティ管理者ロールが割り当てられているユーザー。
- Azure Monitor ログにログを送信するための、Azure サブスクリプション内の Azure Log Analytics ワークスペース。 Log Analytics ワークスペースの作成方法を確認してください。
- Azure Monitor ログに統合された Microsoft Entra ログ。 Microsoft Entra サインイン ログを Azure Monitor Stream と統合する方法を参照してください。
アプリ サインイン正常性ブックを構成する
Azure portal でブックにアクセスするには、[Microsoft Entra ID] を選択し、[ブック] を選択します。
ブックは、[使用状況]、[条件付きアクセス]、および [トラブルシューティング] の下に表示されます。 アプリ サインイン正常性ブックは、[正常性] セクションに表示されます。 ブックを使用すると、[最近変更されたブック] セクションに表示される場合があります。
アプリ サインイン正常性ブックを使用して、サインインで何が起こっているのかを視覚化できます。次のスクリーンショットに示すように、ブックには 2 つのグラフが表示されます。
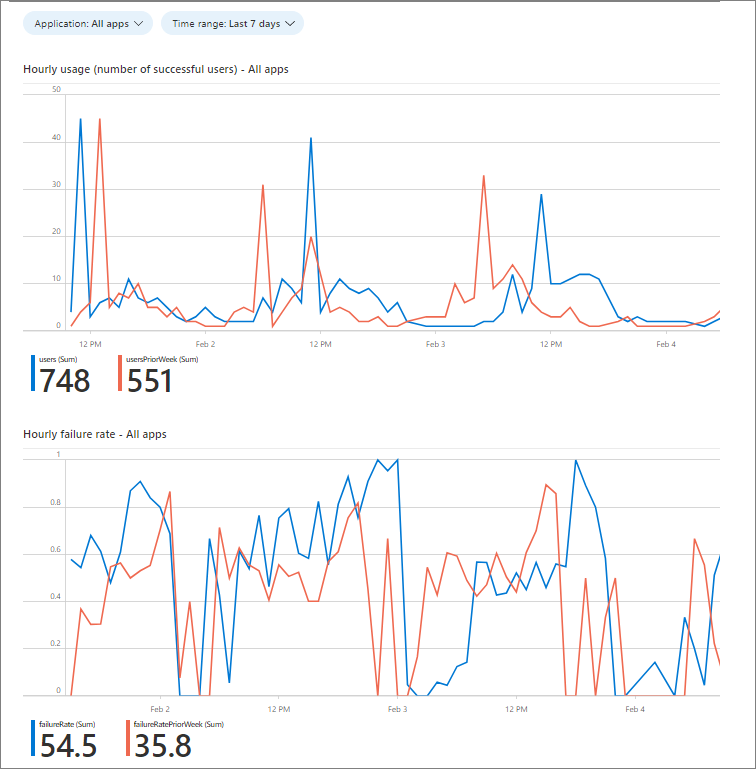
先のスクリーンショットには、次の 2 つのグラフがあります。
- 時間あたり使用量 (成功したユーザーの数)。 現在の成功したユーザーの数を典型的な使用量の期間と比較すると、調査が必要な可能性のある使用量の低下を特定するのに役立ちます。 成功使用率の低下は、失敗率では検出できないパフォーマンスと使用率の問題を検出するのに役立ちます。 たとえば、ユーザーがサインインしようとしてもアプリケーションに到達できない場合、失敗にはならず、使用量が低下するだけです。 この記事の次のセクションで、このデータのためのサンプル クエリを確認してください。
- 時間あたり失敗率。 失敗率の急上昇は、認証メカニズムに問題があることを示している場合があります。 失敗率の測定は、ユーザーが認証を試みることができる場合にのみ行われます。 ユーザーが試行を行うためのアクセスを取得できない場合、失敗にはなりません。
クエリとアラートを構成する
Azure Monitor でアラート ルールを作成し、保存済みのクエリまたはカスタム ログ検索を一定の間隔で自動的に実行できます。 使用量または失敗率が指定したしきい値を超えたときに特定のグループに通知するアラートを構成できます。
次の手順に従って、グラフに反映されたクエリに基づいて電子メール アラートを作成します。 サンプル スクリプトは、次の場合にメール通知を送信します。
- 先の時間あたり使用量のグラフの例のように、成功の使用量が 2 日前の同じ時間から 90% 低下している場合。
- 先の時間あたり失敗率のグラフの例のように、失敗率が 2 日前の同じ時間から 90% 増加している場合。
基になるクエリを構成し、アラートを設定するには、構成の基礎としてサンプル クエリを使用する次の手順を完了してください。 クエリ構造の説明はこのセクションの最後にあります。 「ログ アラートの管理」で、Azure Monitor を使用してログ アラートを作成、表示、管理する方法を確認してください。
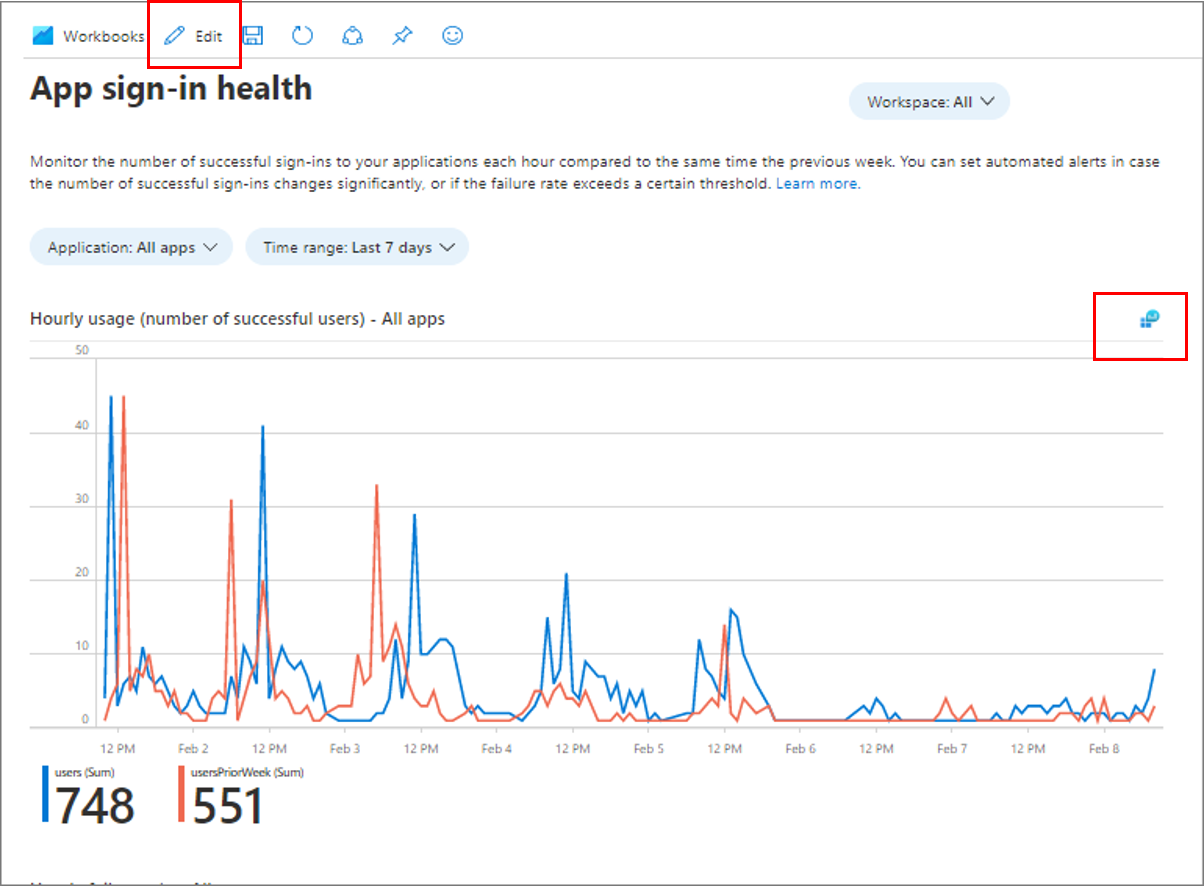
次のスクリーンショットに示すように、ブックで [編集] を選択します。 グラフの右上隅にあるクエリ アイコンを選択します。
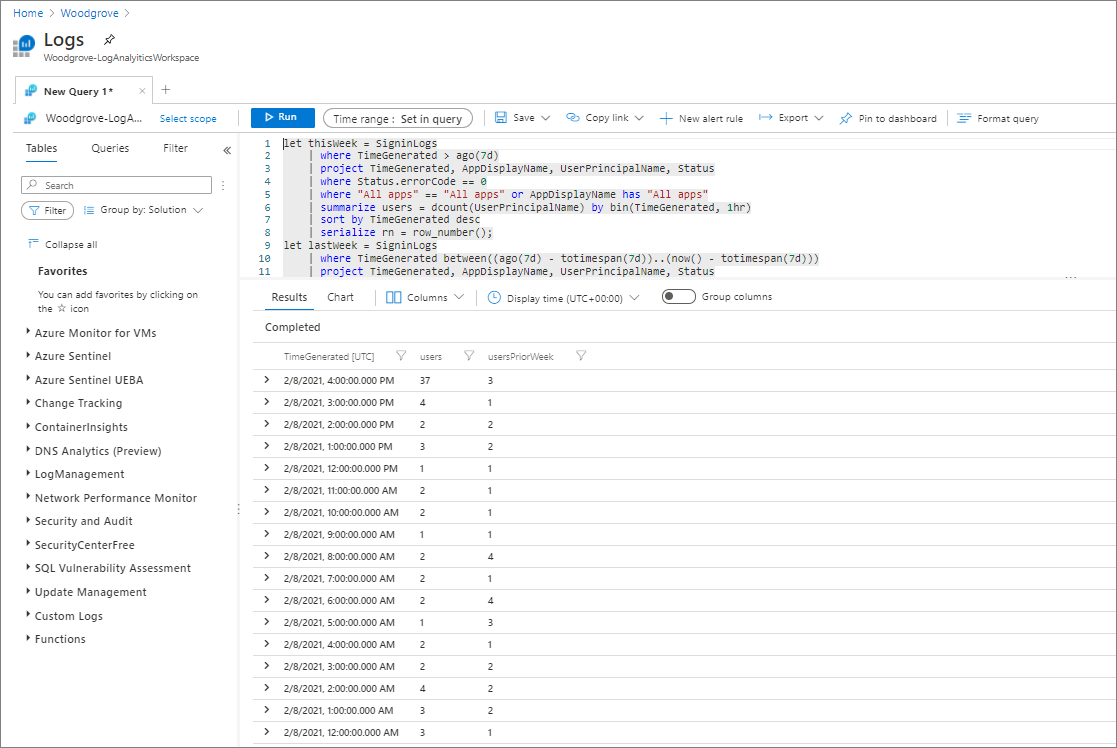
次のスクリーンショットに示すように、クエリ ログを表示します。
新しい Kusto クエリ用に次のいずれかのサンプル スクリプトをコピーします。
ウィンドウにクエリを貼り付けます。 [実行] を選択します。 次のスクリーンショットに示すように、完了メッセージとクエリ結果を探します。
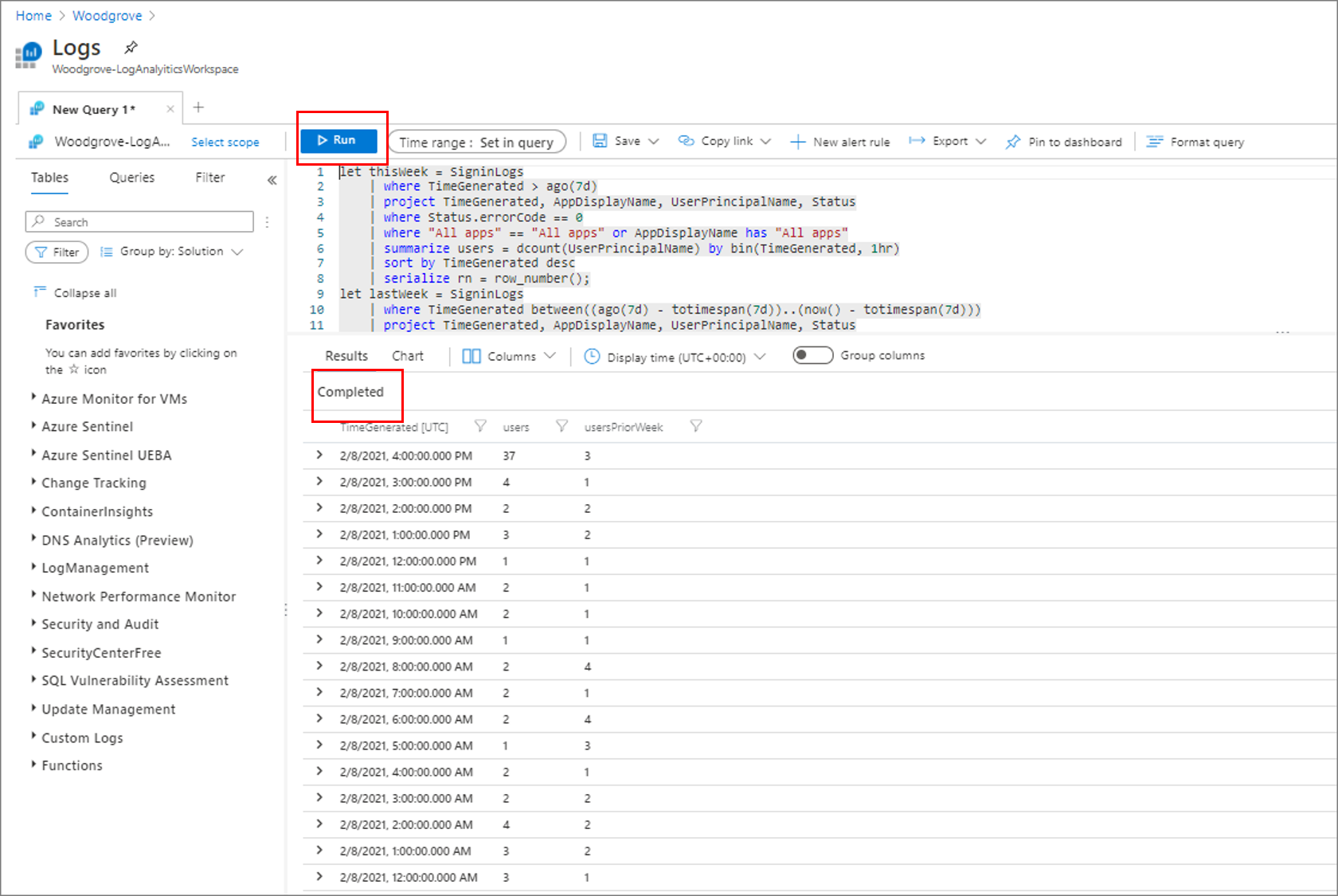
クエリを強調表示する。 [+ 新しいアラート ルール] を選択します。
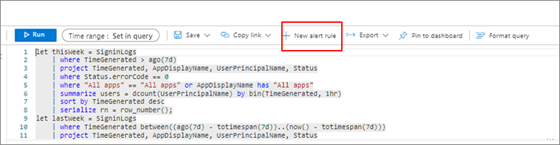
アラートの条件を構成します。 次のスクリーンショットの例に示すように、[条件] セクションの [測定] の下で、[メジャー] として [テーブル行] を選択します。 [集計の種類] は [カウント] を選択します。 [集計の粒度] は [2 日] を選択します。
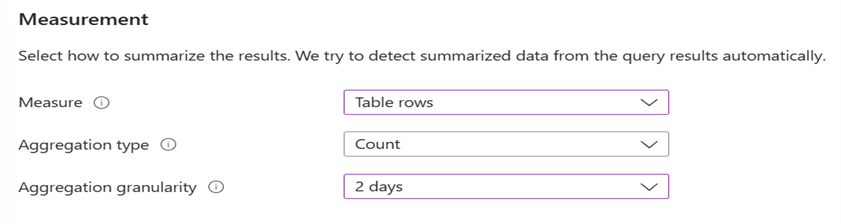
- テーブル行。 返される行の数を使用して、Windows イベント ログ、Syslog、アプリケーション例外などのイベントを処理できます。
- 集計の種類。 "カウント" で適用されたデータ ポイント。
- 集計の粒度。 この値は、評価の頻度で使用される期間を定義します。
アラート ロジックで、スクリーンショットの例に示すようにパラメーターを構成します。
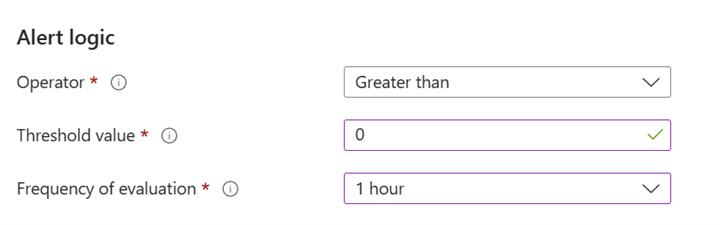
- しきい値: 0。 この値を使用すると、任意の結果に対してアラートが行われます。
- 評価の頻度: 1 時間。 この値を使用して、直前の時間について評価期間を 1 時間に 1 回に設定します。
[アクション] セクションで、スクリーンショットの例に示すように設定を構成します。
![[アラート ルールの作成] 画面を示すスクリーンショット。](media/monitor-sign-in-health-for-resilience/create-alert-rule.png)
- [アクション グループの選択] を選択し、アラート通知の対象となるグループを追加します。
- [アクションのカスタマイズ] で、[メール アラート] を選択します。
- 件名行を追加します。
[詳細] セクションで、スクリーンショットの例に示すように設定を構成します。
![[詳細] セクションを示すスクリーンショット。](media/monitor-sign-in-health-for-resilience/details-section.png)
- サブスクリプションの名前と説明を追加します。
- アラート追加先としたいリソース グループを選択します。
- 既定の重大度を選択します。
- すぐに有効にしたい場合は、[作成時に有効化] を選択します。 それ以外の場合は、[ミュート アクション] を選択します。
[確認と作成] セクションで、スクリーンショットの例に示すように設定を構成します。
![[確認と作成] セクションを示すスクリーンショット。](media/monitor-sign-in-health-for-resilience/review-create.png)
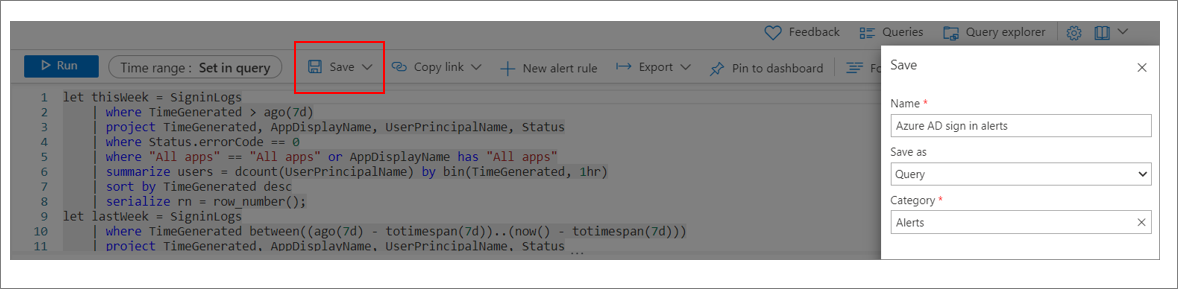
[保存] を選択します。 クエリの名前を入力します。 [名前を付けて保存] では、[クエリ] を選択します。 [カテゴリ] では、[アラート] を選択します。 もう一度、[保存] を選択します。
クエリとアラートを調整する
効果が最大限になるようにクエリとアラートを変更するには:
- 常にアラートをテストします。
- 重要な通知を受け取れるようにアラートの感度と頻度を変更します。 管理者は、受け取る数が多すぎるとアラートに対して鈍感になり、重要なことを見逃すおそれがあります。
- 管理者のメール クライアントで、アラートが送信されてくるメールを許可された送信者の一覧に追加します。 この方法により、メール クライアントのスパム フィルターが原因で通知が見逃されるのを防ぐことができます。
- 設計上、Azure Monitor のアラート クエリには、過去 48 時間の結果しか含めることができません。
サンプルのスクリプト
失敗率の増加に関する Kusto クエリ
次のクエリでは、失敗率の増加を検出します。 必要に応じて、下部の比率を調整できます。 これは、過去 1 時間のトラフィックの比率の変化を、昨日の同時刻のトラフィックと比較して示しています。 0.5 という結果は、トラフィックにおいて 50% の違いがあることを示します。
let today = SigninLogs
| where TimeGenerated > ago(1h) // Query failure rate in the last hour
| project TimeGenerated, UserPrincipalName, AppDisplayName, status = case(Status.errorCode == "0", "success", "failure")
// Optionally filter by a specific application
//| where AppDisplayName == **APP NAME**
| summarize success = countif(status == "success"), failure = countif(status == "failure") by bin(TimeGenerated, 1h) // hourly failure rate
| project TimeGenerated, failureRate = (failure * 1.0) / ((failure + success) * 1.0)
| sort by TimeGenerated desc
| serialize rowNumber = row_number();
let yesterday = SigninLogs
| where TimeGenerated between((ago(1h) – totimespan(1d))..(now() – totimespan(1d))) // Query failure rate at the same time yesterday
| project TimeGenerated, UserPrincipalName, AppDisplayName, status = case(Status.errorCode == "0", "success", "failure")
// Optionally filter by a specific application
//| where AppDisplayName == **APP NAME**
| summarize success = countif(status == "success"), failure = countif(status == "failure") by bin(TimeGenerated, 1h) // hourly failure rate at same time yesterday
| project TimeGenerated, failureRateYesterday = (failure * 1.0) / ((failure + success) * 1.0)
| sort by TimeGenerated desc
| serialize rowNumber = row_number();
today
| join (yesterday) on rowNumber // join data from same time today and yesterday
| project TimeGenerated, failureRate, failureRateYesterday
// Set threshold to be the percent difference in failure rate in the last hour as compared to the same time yesterday
// Day variable is the number of days since the previous Sunday. Optionally ignore results on Sat, Sun, and Mon because large variability in traffic is expected.
| extend day = dayofweek(now())
| where day != time(6.00:00:00) // exclude Sat
| where day != time(0.00:00:00) // exclude Sun
| where day != time(1.00:00:00) // exclude Mon
| where abs(failureRate – failureRateYesterday) > 0.5
使用量の低下に関する Kusto クエリ
次のクエリでは、過去 1 時間のトラフィックを昨日の同時刻のトラフィックと比較します。 前日の同時刻のトラフィックに大きな変動があると予想されるため、土曜日、日曜日、月曜日は除外します。
必要に応じて、下部の比率を調整できます。 これは、過去 1 時間のトラフィックの比率の変化を、昨日の同時刻のトラフィックと比較して示しています。 0.5 という結果は、トラフィックにおいて 50% の違いがあることを示します。 これらの値を、ビジネスの運用モデルに合わせて調整します。
Let today = SigninLogs // Query traffic in the last hour
| where TimeGenerated > ago(1h)
| project TimeGenerated, AppDisplayName, UserPrincipalName
// Optionally filter by AppDisplayName to scope query to a single application
//| where AppDisplayName contains "Office 365 Exchange Online"
| summarize users = dcount(UserPrincipalName) by bin(TimeGenerated, 1hr) // Count distinct users in the last hour
| sort by TimeGenerated desc
| serialize rn = row_number();
let yesterday = SigninLogs // Query traffic at the same hour yesterday
| where TimeGenerated between((ago(1h) – totimespan(1d))..(now() – totimespan(1d))) // Count distinct users in the same hour yesterday
| project TimeGenerated, AppDisplayName, UserPrincipalName
// Optionally filter by AppDisplayName to scope query to a single application
//| where AppDisplayName contains "Office 365 Exchange Online"
| summarize usersYesterday = dcount(UserPrincipalName) by bin(TimeGenerated, 1hr)
| sort by TimeGenerated desc
| serialize rn = row_number();
today
| join // Join data from today and yesterday together
(
yesterday
)
on rn
// Calculate the difference in number of users in the last hour compared to the same time yesterday
| project TimeGenerated, users, usersYesterday, difference = abs(users – usersYesterday), max = max_of(users, usersYesterday)
| extend ratio = (difference * 1.0) / max // Ratio is the percent difference in traffic in the last hour as compared to the same time yesterday
// Day variable is the number of days since the previous Sunday. Optionally ignore results on Sat, Sun, and Mon because large variability in traffic is expected.
| extend day = dayofweek(now())
| where day != time(6.00:00:00) // exclude Sat
| where day != time(0.00:00:00) // exclude Sun
| where day != time(1.00:00:00) // exclude Mon
| where ratio > 0.7 // Threshold percent difference in sign-in traffic as compared to same hour yesterday
アラートを管理するプロセスを作成する
クエリとアラートを設定したら、アラートを管理するビジネス プロセスを作成します。
- だれがブックを監視し、それはいつなのか?
- アラートが発生した場合、誰が調査を行うのか?
- 通信のニーズはどのようなものか? 誰がコミュニケーションを開始し、誰が受け取るのか?
- 障害が発生した場合、どのようなビジネス プロセスが適用されるのか?
次のステップ
ブックの詳細情報