チーム環境での Code First Migrations
Note
この記事は、読者が基本的なシナリオでの Code First Migrations の使用方法を理解していると想定しています。 それ以外の方は、先に「Code First Migrations」をお読みください。
一定の時間を費やして、この記事全体を読む必要があります
チーム環境における問題は、主として、2 人の開発者がローカル コード ベース内に移行を生成した場合に、複数の移行をマージすることに関連しています。 これらを解決する手順はかなり単純ですが、移行のしくみについて十分に理解している必要があります。 最後までスキップすることなく、時間をかけて記事全体を読み、確実に成功するようにしてください。
一般的ないくつかのガイドライン
複数の開発者によって生成された移行のマージを管理する方法について詳しく説明する前に、成功を収めるための準備となる一般的なガイドラインをいくつか紹介します。
各チーム メンバーにローカル開発データベースが必要
移行では、__MigrationsHistory テーブルを使用して、データベースに適用された移行の内容が格納されます。 複数の開発者が、同じデータベースをターゲットにしている (したがって __MigrationsHistory テーブルを共有している) ときに異なる移行を生成している場合、移行は非常に混乱したものになります。
もちろん、移行を生成していないチーム メンバーがいる場合、彼らに中央の開発データベースを共有させても問題はありません。
自動移行は避ける
肝心なことは、チーム環境において自動移行は、当初は良好に見えますが、実際にはうまくいかないという点です。 その理由を知りたければ、読み進めてください。そうでなければ、次のセクションに進むことができます。
自動移行を使用すると、コード ファイルを生成する (コードベースの移行) ことなく、現在のモデルと一致するようにデータベース スキーマを更新できます。 チーム環境において自動移行がまったく適切に機能するのは、使用したことがあるのは自動移行だけで、コードベースの移行をまったく生成したことがない場合のみです。 問題は、自動移行は限定的であり、プロパティや列の名前変更、別のテーブルへのデータの移動など、いくつかの操作は処理されないことです。これらのシナリオを処理するために、自動移行によって処理される、複数の変更の間に混じり合ったコードベースの移行 (とスキャフォールディング コードの編集) が生成される結果に終わります。 これにより、2 人の開発者が移行をチェックインするときに、変更をマージすることがほとんど不可能になります。
移行のしくみの理解
チーム環境で正しく移行を使用するための鍵は、モデルの変更を検出するために、モデルに関する情報が移行によってどのように追跡され、使用されるかを基礎から理解することです。
最初の移行
プロジェクトに最初の移行を追加するときには、パッケージ マネージャー コンソールで、Add-Migration First のような何かを実行します。 このコマンドによって実行されるステップの概要を、下の図に示します。
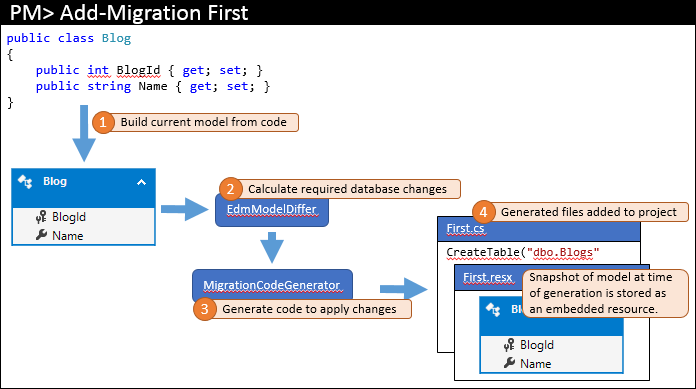
現在のモデルは、お使いのコードから計算されます (1)。 次に model differ によって、必要なデータベース オブジェクトが計算されます (2)。これが最初の移行であるため、モデル差分計算ツールでは、比較のために単に空のモデルが使用されます。 必要な変更がコード ジェネレーターに渡されて、移行コードが作成されます (3)。それが次に、お使いの Visual Studio ソリューションに追加されます (4)。
メイン コード ファイルに格納されている実際の移行コードに加えて、移行によって追加の分離コード ファイルもいくつか生成されます。 これらのファイルは、移行によって使用されるメタデータであり、開発者が編集する必要があるものではありません。 これらのファイルの 1 つは、移行が生成された時点のモデルのスナップショットが含まれるリソース ファイル (.resx) です。 これがどのように使用されるかについては、次のステップで確認します。
この時点で、開発者はおそらく、データベースに変更を適用するために Update-Database を実行し、その後、アプリケーションの他の領域の実装に取り掛かります。
後続の移行
後になって、開発者はモデルに何らかの変更を加えます。この例では、Blog に Url プロパティを追加します。 次に、対応するデータベースの変更を適用するために、Add-Migration AddUrl などのコマンドを発行して移行をスキャフォールディングします。 このコマンドによって実行されるステップの概要を、下の図に示します。
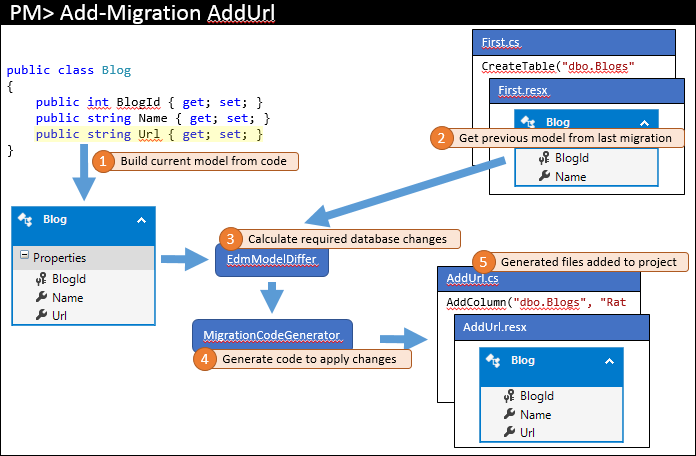
前回と同じように、現在のモデルはコードから計算されます (1)。 ただし今回は、既存の移行が存在しているため、最新の移行から以前のモデルが取得されます (2)。 これら 2 つのモデルは、必要なデータベース変更を見つけるために差分が計算され (3)、その後、前のようにプロセスが完了します。
プロジェクトにさらに移行が追加される場合は、この同じプロセスが使用されます。
モデルのスナップショットが関わる理由
なぜ EF にモデルのスナップショットが関わっているか、不思議に思うかも知れません。データベースを調べるだけではいけないのでしょうか。 そう思う場合は、読み進めてください。 関心がなければ、このセクションをスキップできます。
EF でスナップショットのモデルが保持される理由はいくつかあります。
- それによって、データベースの EF モデルからの逸脱が許容されます。 データベース内にこれらの変更を直接加えることも、移行内のスキャフォールディング コードを変更することで変更を加えることもできます。 以下に、これの実際の例をいくつか示します。
- 1 つ以上のテーブルに対して、列に Inserted や Updated を追加したいが、EF モデルにはこれらの列を含めたくない。 移行によってデータベースが参照されるとすると、移行をスキャフォールディングするたびに、これらの列の削除が継続的に試みられることになります。 モデルのスナップショットを使用すれば、モデルに対する正当な変更のみが EF に検出されるようになります。
- 何らかのログ記録を含めるために、更新で使用するストアド プロシージャの本文を変更したい。 移行によって、データベースにあるこのストアド プロシージャが参照されたとすると、EF で前提とされているストアド プロシージャ定義へのリセットが継続的に試みられることになります。 モデルのスナップショットを使用すれば、EF モデル内のプロシージャの形態を変更する場合、ストアド プロシージャを変更するコードをスキャフォールディングするだけで済むようになります。
- インデックスの追加、データベースへのテーブルの追加、テーブルに対して作成されたデータベース ビューへの EF のマッピングなどに、これらの同じ原則が当てはまります。
- EF モデルに格納されているのは、データベースの形態のみではありません。 モデル全体を用意することで、移行では、モデル内のプロパティとクラスに関する情報と、それらが列やテーブルにどのようにマップされているかを確認できます。 この情報によって、スキャフォールディングするコードにおいて、移行をよりインテリジェントなものにできます。 たとえば、プロパティのマップ先の列名を変更する場合、移行では、それが同じプロパティであることを確認することによって、名前の変更を検出できます。これは、データベース スキーマしかない場合には不可能なことです。
チーム環境で問題を引き起こす原因
前のセクションで説明したワークフローが適切に機能するのは、1 人の開発者がアプリケーションに対する作業を行っている場合です。 あなたが、モデルに変更を加える唯一の開発者であるチーム環境でも、それは適切に機能します。 このシナリオでは、あなたはモデルの変更を行い、移行を生成して、それらをソース管理に送信できます。 他の開発者は、変更を同期し、Update-Database を実行してスキーマの変更が適用されるようにできます。
同時に EF モデルに変更を加えてソース管理への送信を行う開発者が複数いると、問題が起き始めます。 EF に用意されていないのは、ある開発者によるローカルの移行を、最後の同期以後に別の開発者がソース管理に送信した移行とマージするための優れた方法です。
マージ競合の例
まず、このようなマージ競合の具体的な例を見てみましょう。 前に確認した例を使用して説明を続けます。 開始点として、前のセクションで取り上げた変更が、元の開発者によってチェックインされたとします。 コード ベースに変更を加える 2 人の開発者を追跡してゆきます。
いくつかの変更を通じて、EF モデルと移行を追跡します。 開始点については、次の図に示すように、両方の開発者がソース管理リポジトリに同期しています。
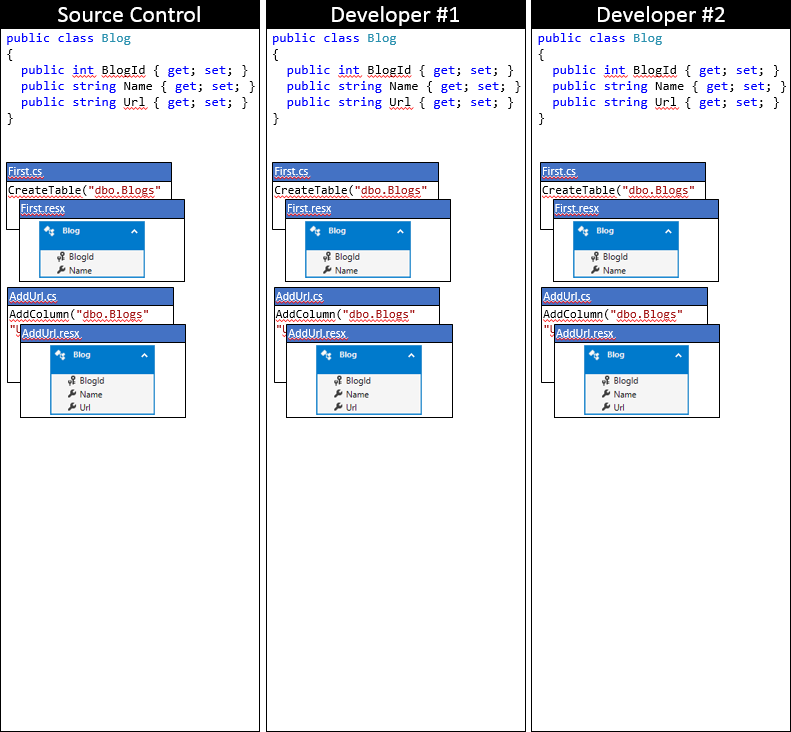
ここで開発者 1 と開発者 2 が、自分のローカル コード ベースの EF モデルにいくつかの変更を加えています。 開発者 1 は、Blog に Rating プロパティを追加して、変更をデータベースに適用するための AddRating 移行を生成しています。 開発者 2 は、Blog に Readers プロパティを追加して、対応する AddReaders 移行を生成しています。 どちらの開発者も Update-Database を実行し、変更を自分のローカル データベースに適用した後、アプリケーションの開発を続けています。
Note
移行にはタイムスタンプでプレフィックスが付けられるため、この図は、開発者 2 からの AddReaders 移行は、開発者 1 からの AddRating 移行の後に行われたことを示しています。 最初に移行を生成したのが開発者 1 であるか 2 であるかは、チームでの作業に関する問題や、次のセクションで説明する移行マージ用のプロセスに関する問題に違いを生じさせません。
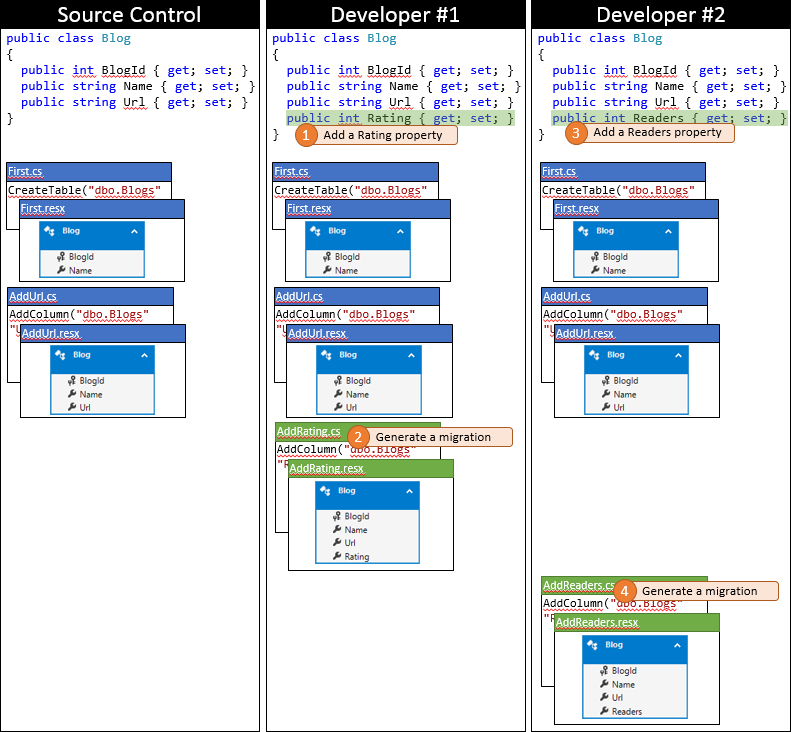
開発者 1 にとっては、たまたま最初に変更を送信したので運がいい日です。 リポジトリを同期して以来、他のどの開発者もチェックインしていないため、マージを実行せずに自分の変更を送信するだけで済みます。
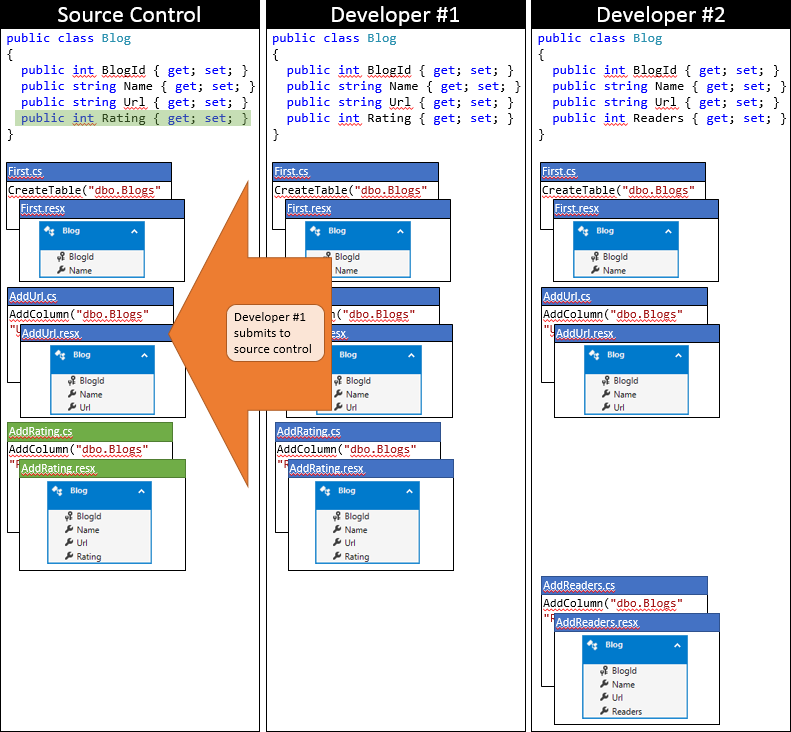
ここで、開発者 2 が送信する順番です。 彼はそれほど幸運ではありません。 同期以降に他の開発者が変更を送信したため、変更をプルしてマージする必要があります。 ソース管理システムではおそらく、コード レベルでの変更は非常に単純であるため、それらを自動的にマージできます。 次の図に、同期後の開発者 2 のローカル リポジトリの状態を示します。
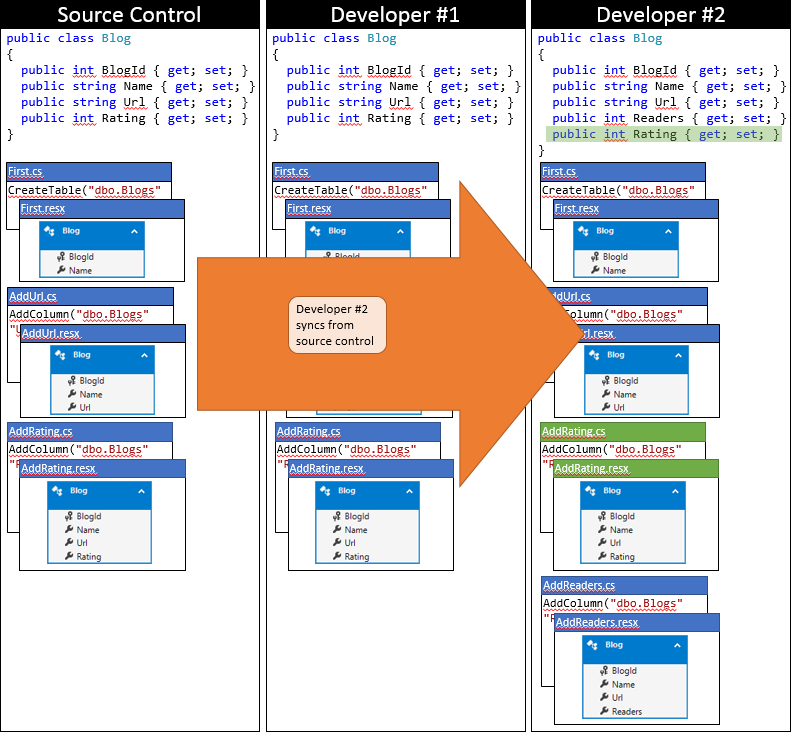
この段階で、開発者 2 は Update-Database を実行できます。これにより、新しい AddRating 移行 (開発者 2 のデータベースには適用されていない) が検出され、それが適用されます。 これで Blogs テーブルに Rating 列が追加され、データベースがモデルと同期した状態になります。
しかし、いくつか問題があります。
- Update-Database によって AddRating 移行が適用されますが、"保留中の変更があり、自動移行が無効になっているため、現在のモデルに一致するようにデータベースを更新できません…" という警告も発生します。問題は、最後の移行 (AddReader) で格納されたモデルのスナップショットに、Blog の Rating プロパティがないことです (移行が生成されたときにモデルの一部になっていなかったため)。 Code First により、最後の移行に含まれるモデルが現在のモデルと一致しないことが検出されて、警告が発生されます。
- アプリケーションを実行すると、"データベースの作成以降に 'BloggingContext' コンテキストの基礎になるモデルが変更されました。Code First Migrations を使用してデータベースを更新することを検討してください..." という InvalidOperationException になります。この場合も問題は、最後の移行で格納されたモデルのスナップショットが現在のモデルと一致しないことです。
- 最後に、ここで Add-Migration を実行すると、空の移行が生成されると予想されます (データベースに適用する変更が存在しないため)。 しかし、移行により、現在のモデルが最後の移行 (これには Rating プロパティがありません) と比較されるため、実際には、Rating 列を追加するための別の AddColumn 呼び出しがスキャフォールディングされます。 もちろん、Rating 列は既に存在するため、この移行は Update-Database の間に失敗することになります。
マージ競合の解決
移行のしくみを理解しているならば、マージを手動で処理することはそれほど困難ではないというのが良いニュースです。 では、このセクションまで前方をスキップした場合は、 残念ですが、前に戻り、まず記事の残りの部分を読む必要があります。
2 つのオプションがあります。より簡単なのは、正しい現在のモデルを持つ空の移行を、スナップショットとして生成することです。 2 つ目のオプションは、正しいモデルのスナップショットを用意するため、最後の移行に含まれるスナップショットを更新することです。 2 つ目のオプションは少し難しく、どのシナリオでも使用できるわけではありませんが、別の移行を追加する必要はないため、よりすっきりとしています。
オプション 1: 空の "マージ" 移行を追加する
このオプションでは、最新の移行に、正しいモデルのスナップショットが格納されるようにすることだけを目的に、空の移行を生成します。
このオプションは、最後の移行をどの開発者が生成したかに関係なく使用できます。 見てきた例では、開発者 2 が、マージの管理を行っていて、たまたま最後の移行を生成しました。 ただし、開発者 1 が最後の移行を生成した場合に、これらの同じ手順を使用できます。 ここでは簡潔さを保つため 2 つの移行で確認してきましたが、この手順は、多数の移行が関係している場合にも適用されます。
ソース管理から同期する必要がある変更が存在すると気付いた時点から、このアプローチのために以下のプロセスを利用できます。
- ローカル コード ベース内の保留中のモデル変更がすべて移行に書き込まれたことを確認します。 この手順により、空の移行を生成するタイミングになったときに、正当な変更を見逃さないようにします。
- ソース管理と同期します。
- Update-Database を実行して、他の開発者がチェックインしたすべての新しい移行を適用します。 注: Update-Database コマンドから何の警告も発生しない場合は、他の開発者からの新しい移行はなかったということであり、それ以上のマージを実行する必要はありません。
- Add-Migration <名前を選択> –IgnoreChanges (例: Add-Migration Merge –IgnoreChanges) を実行します。 これにより、すべてのメタデータを含む移行 (現在のモデルのスナップショットを含む) が生成されますが、現在のモデルと、最後の移行に含まれるスナップショットを比較したときに検出された変更はすべて無視されます (つまり、空の Up および Down メソッドを受け取ります)。
- Update-Database を実行して、更新されたメタデータを含む最新の移行を再適用します。
- 開発を続けるか、ソース管理に送信します (もちろん、単体テストの実行後に)。
次に、このアプローチを使用した後の、開発者 2 のローカル コード ベースの状態を示します。
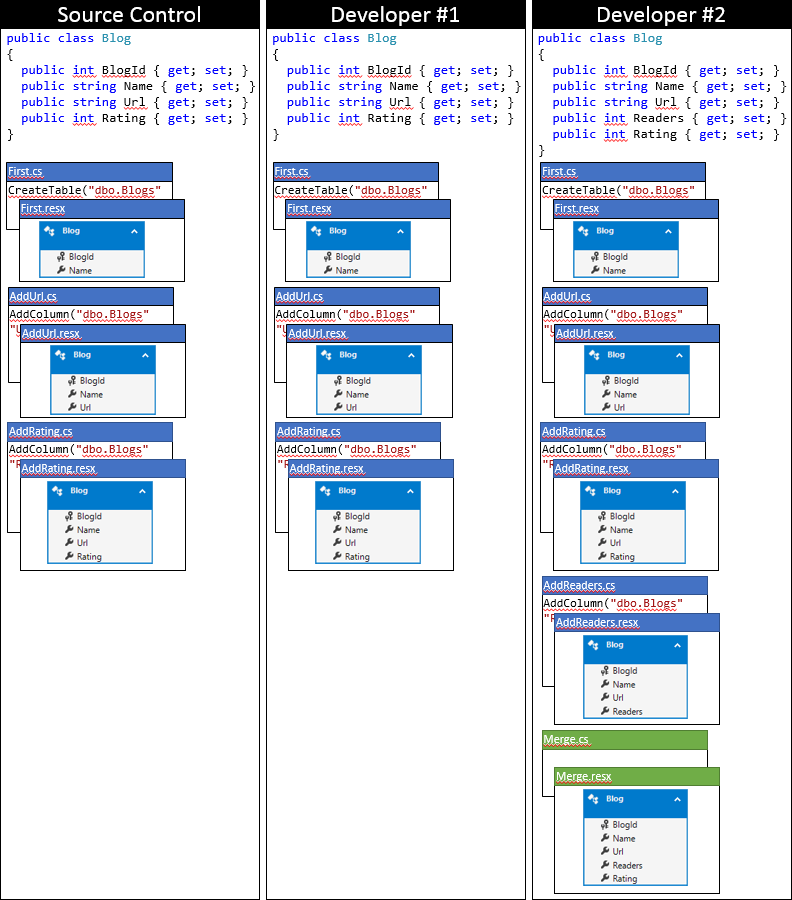
オプション 2: 最後の移行に含まれるモデルのスナップショットを更新する
このオプションはオプション 1 とよく似ていますが、追加の空の移行がなくなります。現実を直視しましょう。ソリューションにコード ファイルを追加したい開発者はいないのです。
このアプローチを実行できるのは、最新の移行がローカル コード ベースにのみ存在していて、ソース管理にはまだ送信されていない場合 (たとえば、マージを行うユーザーによって最後の移行が生成された場合) だけです。 他の開発者が既に、開発データベースに適用した可能性がある移行や、さらに悪いことに、実稼働データベースに適用した可能性がある移行のメタデータを編集すると、予期しない副作用が発生する場合があります。 このプロセス中には、ローカル データベースで最後の移行をロールバックして、更新されたメタデータをそれに再適用することになります。
最後の移行が存在する必要があるのはローカル コード ベース内だけですが、それを進める移行の数や順序に制限はありません。 ここでは簡潔さを保つため 2 つの移行で確認してきましたが、複数の異なる開発者からの移行が複数存在する場合があり、同じ手順が当てはまります。
ソース管理から同期する必要がある変更が存在すると気付いた時点から、このアプローチのために以下のプロセスを利用できます。
- ローカル コード ベース内の保留中のモデル変更がすべて移行に書き込まれたことを確認します。 この手順により、空の移行を生成するタイミングになったときに、正当な変更を見逃さないようにします。
- ソース管理と同期します。
- Update-Database を実行して、他の開発者がチェックインしたすべての新しい移行を適用します。 注: Update-Database コマンドから何の警告も発生しない場合は、他の開発者からの新しい移行はなかったということであり、それ以上のマージを実行する必要はありません。
- Update-Database –TargetMigration <最後から 2 番目の移行> を実行します (見てきた例では、これは Update-Database –TargetMigration AddRating になります)。 これにより、データベースは最後から 2 番目の移行の状態にロールバックされ、最後の移行は事実上、データベースから "適用解除" されます。 注: メタデータはデータベースの __MigrationsHistoryTable にも保存されるため、移行のメタデータ編集を安全なものにするには、この手順が必要です。これが理由で、最後の移行が含まれるのがローカル コード ベースのみの場合に限ってこのオプションを使用する必要があります。他のデータベースに最後の移行を適用済みである場合、それらをロールバックし、最後の移行を再適用してメタデータを更新する必要もあります。
- Add-Migration <最後の移行のタイムスタンプを含む完全な名前> を実行します (見てきた例では、これは Add-Migration 201311062215252_AddReaders のようになります)。 注: あなたが新しい移行をスキャフォールディングするのではなく既存の移行を編集しようとしていることを移行が認識できるようにするために、タイムスタンプを含める必要があります。これで、最後の移行のメタデータが、現在のモデルと一致するように更新されます。 コマンドが完了すると次の警告が表示されますが、必要なのはまさにそれです。 "移行 '201311062215252_AddReaders' のデザイナー コードだけが再スキャフォールディングされました。移行全体を再スキャフォールディングするには、-Force パラメーターを使用してください。"
- Update-Database を実行して、更新されたメタデータを含む最新の移行を再適用します。
- 開発を続けるか、ソース管理に送信します (もちろん、単体テストの実行後に)。
次に、このアプローチを使用した後の、開発者 2 のローカル コード ベースの状態を示します。
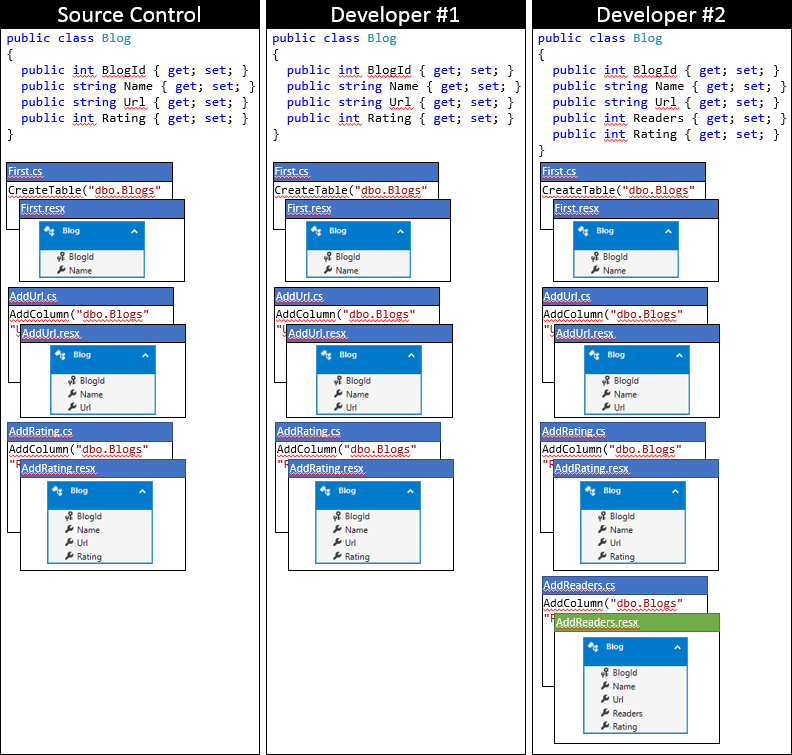
まとめ
チーム環境で Code First Migrations を使用する際にはいくつかの課題があります。 ただしこれらの課題は、移行のしくみに関する基本的な理解と、マージ競合を解決するためのいくつかの簡単なアプローチによって簡単に克服できます。
根本的な問題は、最新の移行に正しくないメタデータが格納されていることです。 これにより、Code First では、現在のモデルとデータベース スキーマが一致しないと誤って検出され、次の移行で正しくないコードがスキャフォールディングされます。 この状況は、正しいモデルを含む空の移行を生成するか、最新の移行の中のメタデータを更新することによって克服できます。
.NET