バッチ処理とバッチ サーバー
この記事では、バッチ処理とバッチ サーバー、およびその使用を計画する方法について説明します。
バッチ プラットフォームは、Application Object Server (AOS) の複数のインスタンスにわたるタスクを処理できるサーバー ベースの非同期バッチ処理環境を提供します。
バッチ プラットフォームの次のような側面について、よく理解しておく必要があります:
- バッチ ジョブは、特定の目標を達成するために使用されるプロセスです。 バッチ ジョブは、1 つまたは複数のバッチ タスクで構成されます。
- バッチ タスクは、バッチ ジョブによって実行される活動です。 複数の種類の依存関係を持つバッチ タスクをバッチ ジョブに追加することができます。 また、それぞれがタスクを実行する、複数のスレッドを実行するように AOS インスタンスを構成することができます。 実行待ちのバッチ タスクはすべて、バッチサーバーとして構成された利用可能な AOS インスタンス上で選択できます。 スループットを向上させ、全体の実行時間を短縮するには、バッチ ジョブを多数のタスクとして定義し、バッチ サーバーを使用して使用可能なすべての AOS インスタンスに対してタスクを実行します。
- バッチ グループは、バッチ タスクの属性です。 管理者がタスクを実行する AOS インスタンスを決定または指定することを可能にします。 新しいタスクを作成するとき、そのタスクは既定のバッチ グループに配置されます。 すべてのバッチ サーバーは、任意のジョブから既定のバッチ グループおよび待機中のタスクをプロセスするためにコンフィギュレーションされています。 また、名前付きバッチ グループを作成して、そのバッチ グループと特定の AOS インスタンスの間のアフィニティを設定できます。 アフィニティを作成した後は、指定された AOS インスタンスのみが名前付きバッチ グループのタスクを処理することができ、 AOS インスタンスは指定された名前付きバッチ グループからのみタスクを処理することができます。 また、バッチ グループが必要な場合、既定のバッチ グループを構成済みサーバーに追加することができます。
注記
バッチの優先順位に基づくスケジューリングを実装すると、バッチ グループによってバッチ サーバーとの関連が制御されなくなりました。 これらは、バッチ ジョブに優先順位を割り当て、各バッチ ジョブ内でのバッチ タスクの最大同時実行を管理するために使用されます。 詳細については、優先順位にバッチスケジュール設定 を参照してください。
バッチ サーバーのトポロジ計画
バッチ サーバーの能力は、AOS インスタンスで同時に実行できるスレッドの最大数に基づいています。 各スレッドは、1 つのバッチ タスクを実行します。 タスク間またはタスク内に複雑な依存関係を追加することができます。 これらのタスクは、ビジネス ロジックおよび要件に基づき、シリアル ステップまたはパラレル ステップで実行することができます。 依存関係を持っていないすべてのタスクは並列タスクと見なされます。 バッチ サーバーとしてコンフィギュレーションされている AOS インスタンスは、処理を待機しているタスクを定期的に確認します。 バッチ サーバーは、各並列タスクをスレッドに割り当て、そのスレッドの処理を開始します。
複数の AOS インスタンス間で複数のスレッドを実行することができます。 各 AOS インスタンスは、構成設定で定義されているキャパシティに応じて、複数のスレッドを自動的に実行します。 したがって、ジョブからの並列タスクは、複数の AOS インスタンスにわたって複数のスレッドで実行できます。
バッチ サーバーは、1 分間に 1 回使用可能なスレッドをチェックします。 そのため、準備完了のタスクが利用可能なバッチ スレッドが処理するまで、1 分ほど待たなければならない場合があります。
バッチ サーバーの管理計画
すべてのバッチ サーバーは単一の場所から管理することができます。
バッチ サーバーの 1 つの一般的な使用方法は、複数のサーバー間でジョブの負荷分散を行うことです。 バッチ サーバーが処理するスレッド数をセットすることができます。
バッチ サーバーは、クライアントおよびその他の関連付けられたコンポーネントからサービスが要求する有効な AOS インスタンスでもあるため、AOS インスタンスがバッチ処理に利用できるようにする場合は慎重に決定する必要があります。
チュートリアル
次のチュートリアルでは、タスクの処理方法と、バッチ グループを使用してバッチ ジョブをバッチ ・サーバーに関連付ける方法について説明します。
従属タスクのバッチ処理
たとえば、JOB 1という名前のジョブを作成します。 次の図に示すように、職務には 7 つのタスクがあります。タスク 1、タスク 2、タスク 3、タスク 4、タスク 5、タスク 6、およびタスク 7 です。
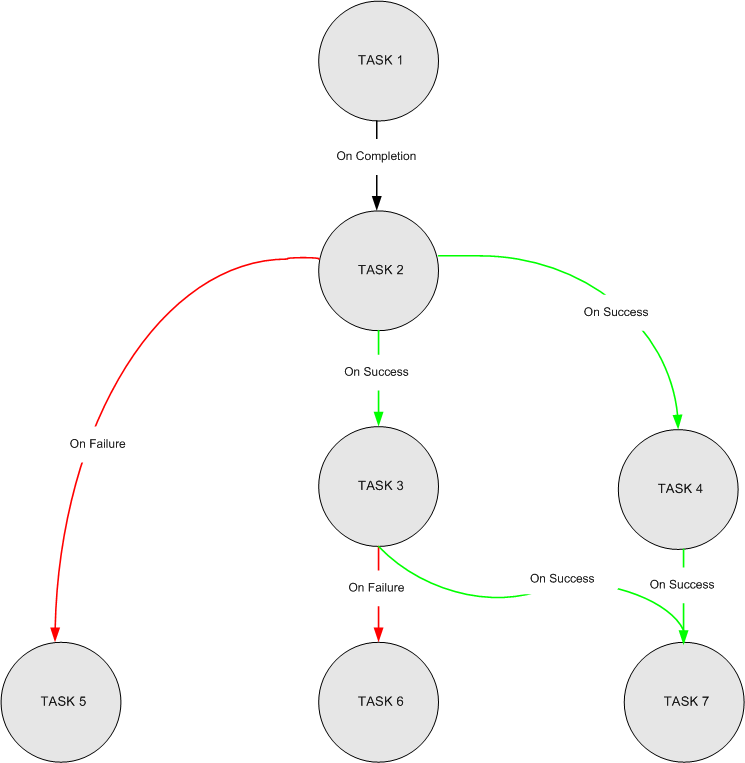
タスクには次の依存関係があります。
- タスク 1 は、最初のタスクです。
- タスク 2 は、タスク 1 が完了すると実行されます (タスク 1 が成功したか失敗したかに関係ありません)。
- タスク 3 は、タスク 2 が正常に行われた場合に実行されます。
- タスク 4 は、タスク 2 が正常に行われた場合に実行されます。
- タスク 5 は、タスク 2 が失敗したときに実行されます。
- タスク 6 は、タスク 3 が失敗したときに実行されます。
- タスク 7 は、タスク 3 とタスク 4 の両方が正常に行われたときに実行されます。
2 つのバッチ サーバー、バッチ 1 と バッチ 2 が構成されています。 各サーバーには、1 つのスレッドの容量があります。
バッチ 1 は待機タスクをチェックし、タスク 1 をそのスレッドに割り当て、タスク 1 の実行を開始します。 バッチ 2 とその単一スレッドも使用可能ですが、タスク 2 はタスク 1 が完了するまで待機し続けます。
タスク 1 が完了するとすぐに、タスク 2 は実行する準備ができています。 バッチ 2 は待機タスクをチェックし、タスク 2 をそのスレッドに割り当て、タスク 2 の実行を開始します。
タスク 2 が正常に行われた場合は、タスク 3 およびタスク 4 の実行準備が整います。 バッチ 2 は待機タスクをチェックし、タスク 3 をそのスレッドに割り当て、タスク 3 の実行を開始します。 バッチ 1 も待機中のタスクをチェックし、そのスレッドにタスク 4 を割り当て、タスク 4 の実行を開始します。
タスク 3 とタスク 4 が成功した場合は、バッチ サーバーのいずれかがタスク 7 を実行します。
タスク 2 が失敗すると、バッチ サーバーのいずれかがタスク 5 を実行します。
タスク 3 が失敗すると、利用可能なバッチ サーバーのいずれかがタスク 6 を実行します。
注記
このチュートリアルの例では、バッチ 1 とバッチ 2 を使用して、概念について説明します。 使用可能なスレッドを持つすべてのバッチ サーバーは、待機中のタスクの実行を開始します。 サーバー上で実行するバッチ ジョブを決定または指定するには、バッチ グループを作成する必要があります。
バッチ グループを使用するバッチ処理
優先度に基づくバッチ スケジューリングを実装することで、ジョブを論理的にグループ化し、その既定のスケジューリング優先度を設定することができます。 さらに、コンカレンシー制御を使用して、そのグループ内の各バッチジョブで同時に実行できるタスクの数を制限することができます。
バッチ サーバーの再起動について
いくつかの理由で、バッチ サーバーが再起動される可能性があります。 以下はその理由の概要です:
定期保守活動 : - パッチ適用などの定期的なメンテナンス作業では、バッチ サービスが一時的に中断する場合があります。 メンテナンス活動の効果やアクセス公知のメンテナンス スケジュールを理解するには、以下の記事をご覧ください:
- オペレーティング システムの保守スケジュール - 計画されたオペレーティング システムの保守スケジュールに関する詳細を表示します。
- nZDT メンテナンス期間中の経験 - nZDT メンテナンス ウィンドウ中のシステム動作に関する分析情報を得ることができます。
バッチ サーバーの不具合 ("動作確認") - バッチ サーバーのバッチ サーバーが失敗した場合は、それぞれのサーバーで現在実行されているバッチ ジョブが原因で発生する場合があります。 失敗の詳細情報は、Microsoft Dynamics Lifecycle Servicesで参照できます。 失敗の情報の監視方法については、Application Insights を使用した監視とテレメトリ を参照してください。
インフラストラクチャ フェールオーバー - インフラストラクチャの問題で内部フェイルオーバーが発生した場合、再起動が発生する場合があります。 環境のパフォーマンスと可用性を最適化するために、自動スケールと能力管理を使用します。
拡張バッチ中止機能の使用 – 実行中のバッチジョブを強制的に停止する必要が生じた場合は、一括中止の強化機能 を使用してください。 このアクションにより、ジョブが実行された特定のバッチ サーバーが再起動します。
信頼性を高するには、部下によって影響されるバッチ タスクを再試行します。 バッチ クラスのロジックに再試行メカニズムを実装について検討します。 再試行ロジックの実装方法については、バッチの再試行を有効にする をご参照ください。
注記
- システムの安定性と互換性を維持するために、サポートされているバージョン を使用していることを確認してください。
- カスタマイズやファイルのアップロードを確認して、バッチ ジョブの実行およびシステム パフォーマンスに与える潜在的な影響を軽減してください。
バッチ調整
バッチ プラットフォームでは、円滑な運用を保証するために 2 種類のバッチ処理を使用します。
バッチ クラスの調整
バッチクラスの調整は、バッチサーバーごとに 1 分あたりの特定のバッチクラスの平均実行数を制限することで、過剰なタスクを防止します。 既定では、上限は 1 分あたり 60 タスクに設定されます。 この制限を超えると、バッチ プラットフォームはシステムリソースを独占しないように、そのバッチ クラスの新しいタスクの実行を一時的にさらに 1 分間中断します。
バッチ リソース ベースの調整
バッチ サーバーに割り当てられた SQL データベース トランザクション ユニット (DTUs)、CPU、メモリなどのシステム リソースの能力上限に近づくと、新しいバッチ タスクの実行が遅延します。 この遅延により、システムはリソースを効率的に管理し、既存のワークロードがシステムを圧迫しないようにします。
実際には、リソース レベルが標準に戻るまで新しいバッチ タスクの実行を遅らせた結果、スプリアロック メカニズムを実装しています。 ガードレールは、あなたの環境のパフォーマンスと安定性を保護する目的で設置されています。 環境の動作は、需要やリソースの制約が高い時期でも最適な動作が保証されます。
この方法の目的は、ワークロード需要と利用可能なリソースの間の残高を維持するために行います。 十分なリソースが利用できるようになるまで、新しいバッチ タスクの開始を一時的に停止することで、システムが過負荷になった場合に発生する可能性があるパフォーマンスの低下やシステムの不安定化を防ぎます。
遅延メカニズムは、リソースの利用を最適化し、厳しい条件下でもお客様の環境が最高のパフォーマンスを維持できるようにするための事前対策として機能します。
Lifecycle Services を使用してパフォーマンスの問題を診断するのに役立つ情報については、SQL パフォーマンスのトラブルシューティングを参照してください。
注意
バッチ プラットフォームは、任意の時間にスケジュールして実行する、調整されていないタスクがない状況を検出できます。 このような状況では、バッチは、リソースがアイドル状態になるのを防ぐために、調整されたクラス キューからバッチタスクを取り込もうとします。