勘定科目の組み合せ
概要
Microsoft Dynamics AX 2009では、分析コードの数が最小で3、最大10に制限されていました。 また、分析コードは固定された順序で入力されていました。 そのため、コードのカスタマイズとデータベースの同期は、追加されたすべての分析コードに対して必要でした。 その後、Microsoft Dynamics AX 2012 では、分析コードのフレームワークが拡張され、最大 50 まで分析コード数を増やすことができるようになりました (テーブルの合計列数の SQL データベース制限による)。 ユーザーは動的に分析コードを作成し、任意の順序で入力することもできます。 財務と運用では、AX 2012 から動作が維持されます。 当モデルでは制限が取り払われており、リレーショナルデータベースの設計によるメリットと、パフォーマンス要件の最適化によって、従来と比べて複雑なデータモデルを構成することができます。
第1部:勘定科目の組み合わせを作成することで何が起こるか
この記事では、分析コード フレームワークを構成するさまざまな領域と、それらがどのように連携するかについて説明します。 この情報を参照することで、勘定科目の組み合わせによってできることがより分かりやすくなります。
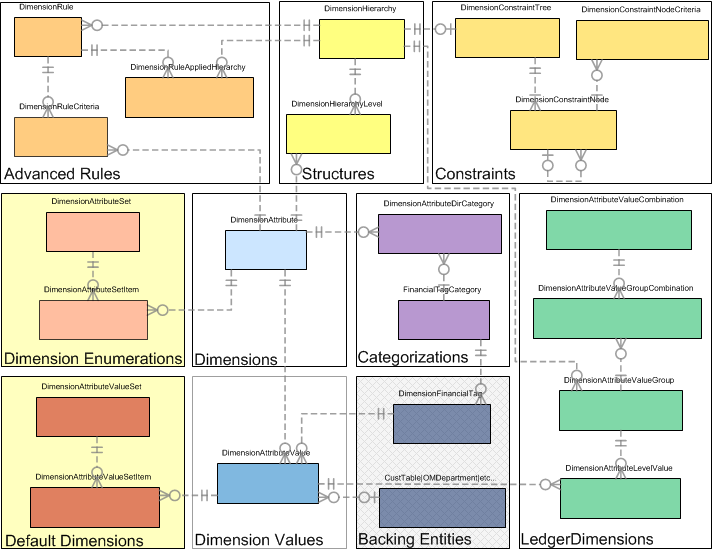
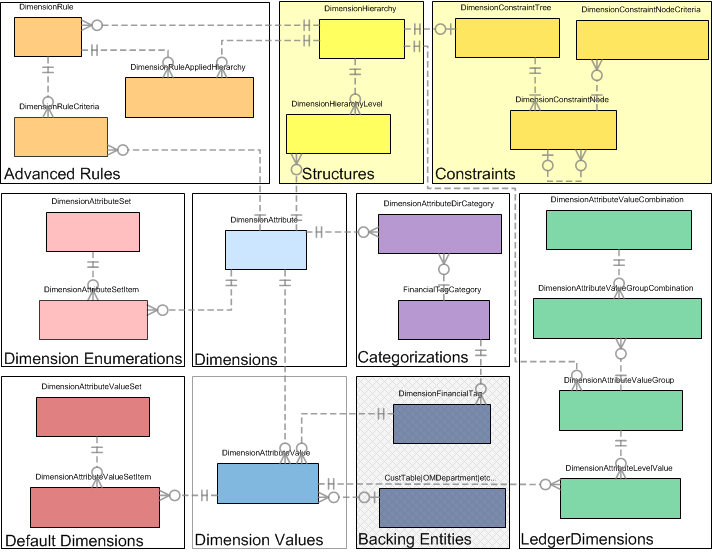
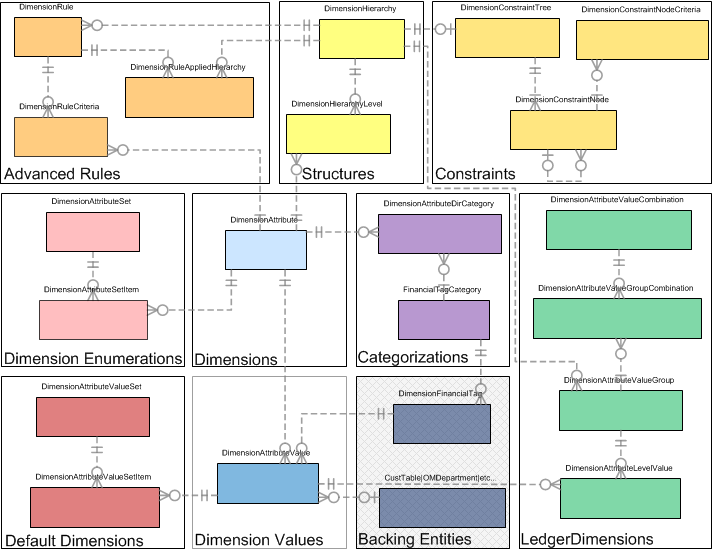
以下の図は、分析コードフレームワークを構成するさまざまな領域を示しています。
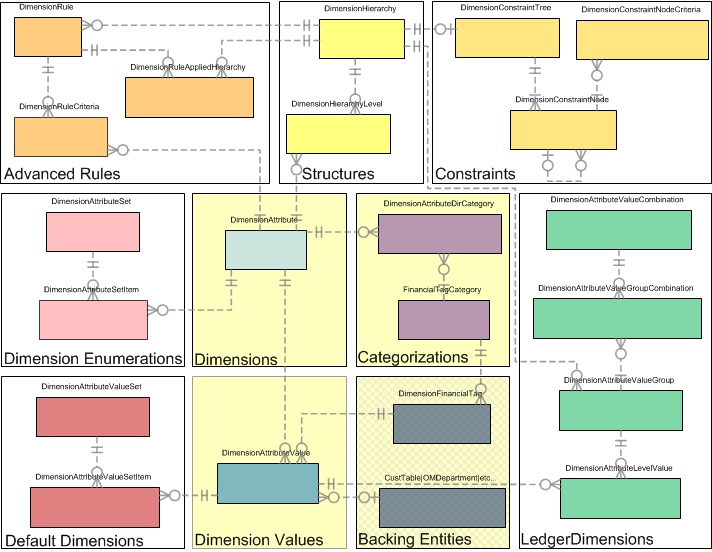
この記事では、上記の図で黄色で強調表示されている箇所「分析コード」、「分析コード値」、「分類」、「バッキング エンティティ」について説明します。
分析コードの属性
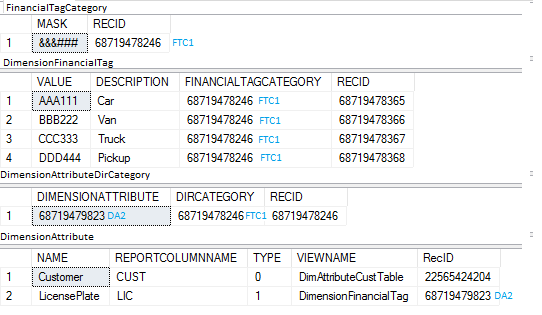
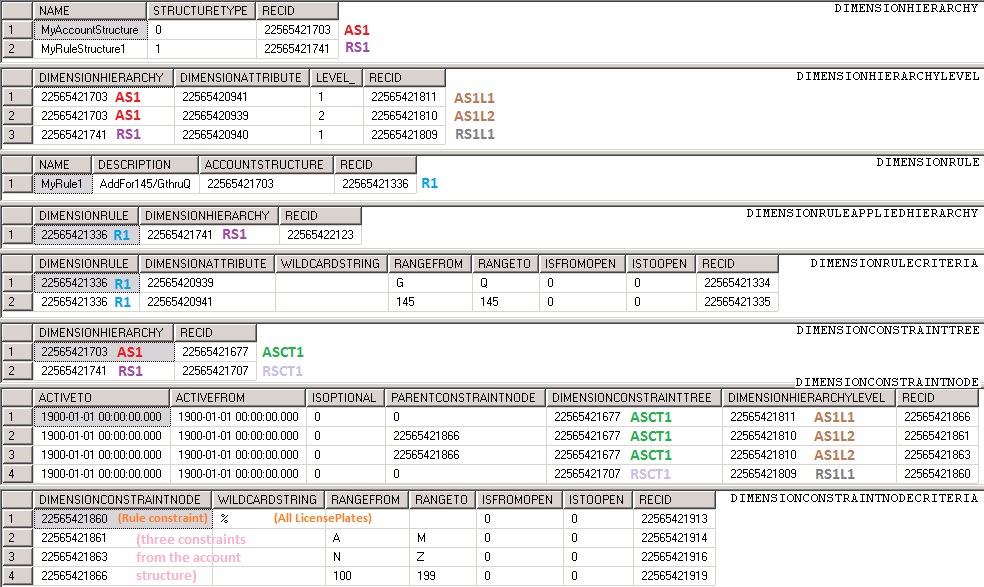
分析コード属性は、単に分析コードとも称され、勘定科目の組み合わせと関連付ける情報を分類する追加要素を意味します。 これは具体的なインスタンスではなく、要素の種類を意味します。 分析コードの作成に使用できる要素は、システム上に存在するエンティティクラス (部門、原価部門、経費の目的、顧客、仕入先、品目など)、または、特定のインストールに特化したカスタムエンティティ (ライセンスプレート番号、イベント名、およびチケット番号など) のいずれかです。
分析コードが作成されると、ユーザーは値の取得元を選択できます。 分析コード値は、顧客または部門エンティティなどのシステム上に存在するエンティティやユーザーが作成したカスタムリストから取得できます。 定義された各分析コードについて、分析コードフレームワークはシステム内のテーブルへの参照を追跡します。 たとえば、既存の顧客エンティティについては、CustTable テーブルへの参照が使用されます。 ユーザーが定義したカスタムエンティティの場合は、DimensionFinancialTagテーブルへの参照が使用されます。 DimensionAttributeテーブルには、各分析コードを表すメタデータが格納されています。
以下の図では、 財務分析コード ページに2つの分析コードが表示されています。 顧客分析コードには、アプリケーションに既に存在する顧客が表示され、LicensePlate分析コードは新しいカスタムリストが表示されます。
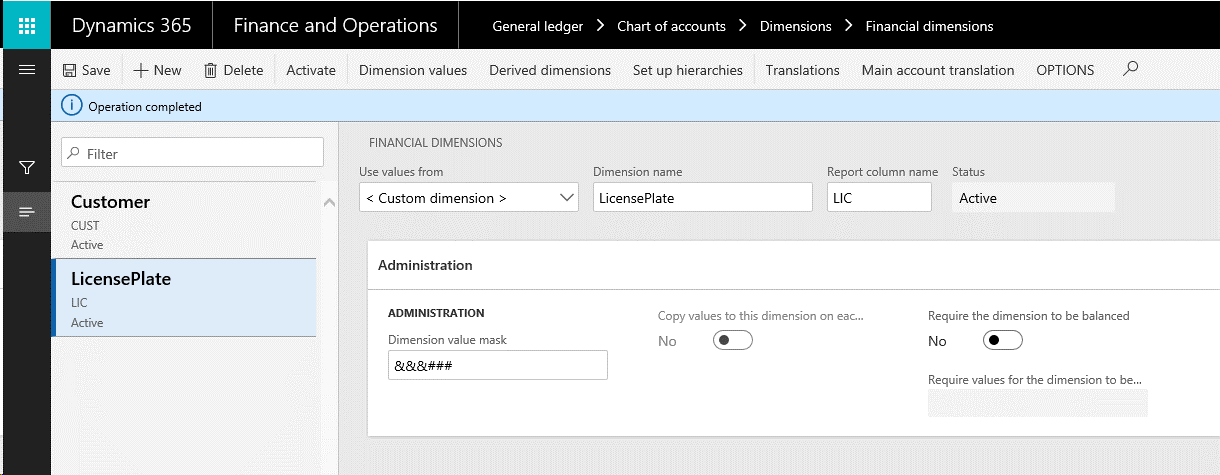
それぞれの分析コードは、DimensionAttributeテーブルに格納されています。 下図のSQLクエリは、各分析コードに関連付けられている基本情報の一部を表示しています。

Type の値は、分析コードがシステム上に存在しているエンティティと結びついているのか、もしくはカスタムリストと結びついているのかを表しています。 ただし、分析コード フレームワークは、CustTable のような既存エンティティのバッキング テーブルに対する直接参照は行いません。 その代わりに、システム上でエンティティを使用できるようにカスタムビューが作成されるため、それを分析コードフレームワークで使用できるるようになります。 初期設定では、36 の既存エンティティを分析コードとして使用できます。
同じエンティティから複数の分析コードを作成することができます。 トランザクションアクティビティがシステム内で分類される場合は、classifiedシステム内のエンティティが複数の目的に使用されることがあります。 この場合、1つのエンティティに対して複数の分析コードを定義できます。 代表的な例としては、原価部門のバッキングエンティティは、主原価部門 (販売など) と売買が行われる原価部門 (購買など) の両方を表します。
内部的には、分析コード フレームワークの主要な機能に対応できるように自動的に作成される特殊な分析コードが存在します。 MainAccount 分析コードが主要な例です。 この機能により、分析コードフレームワークが主勘定を分析コードとして扱うことができます。 ただし、ユーザーが主勘定を使用して分析コードを作成することはできません。 その他のタイプの特殊分析コードは、システムによって生成される分析コードです。これは分析コードフレームワークが内部使用する目的で生成されます。
分析コードの属性値
分析コードの属性値は、分析コードの中でも特殊なインスタンスで、分析コードフレームワークで使用されます。 分析コードの値は、DimensionAttribute レコードにて指定されている ViewName プロパティによって決定されます。 CustTable などの既存エンティティの場合、値はそのテーブル内のレコードで構成されます。 カスタム リストの場合、値は DimensionFinancialTag テーブルの特定のレコード セットで構成されます。 特定の分析コードに使用可能となる値を参照するには、 財務分析コード ページ内の 財務分析コード値 ボタンを選択します。
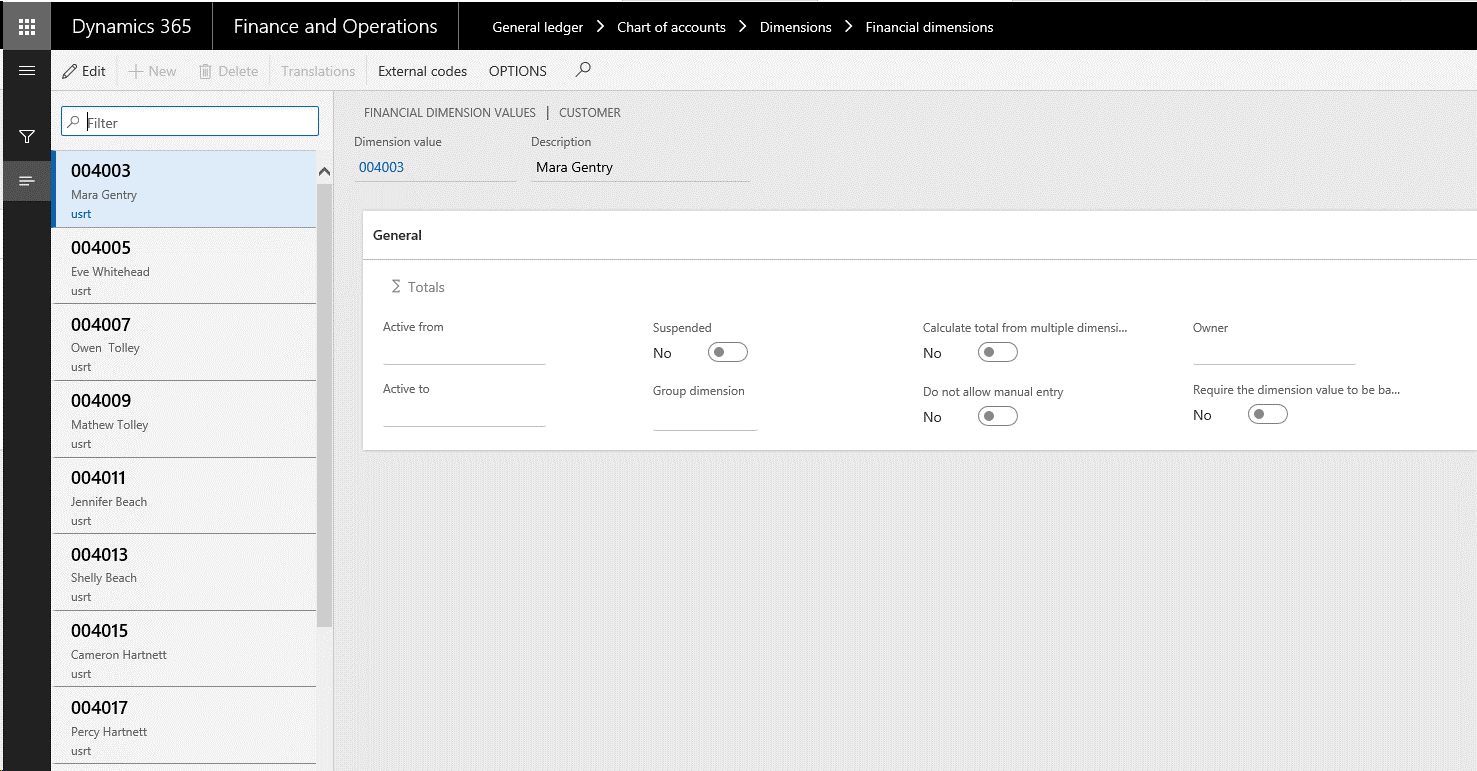
エンティティが複数の値が提示した場合、ユーザーは 財務分析 ページから値を編集することはできません。CustTableなどがこれに該当します。 顧客 メニューで使用する新しい分析コード値を作成するには、 顧客 ページに直接移動して、新しい顧客を作成する必要があります。 新しい顧客を作成すると、分析コードフレームワークで使用できます。 ユーザーが作成したカスタムリストが複数の値が提示した場合、 財務分析 ページにて直接値を編集することができます。
以下の図は、CustTableが表示する値の一覧の例を示しています。 以下例では、分析コードフレームワークには値が格納されていません。
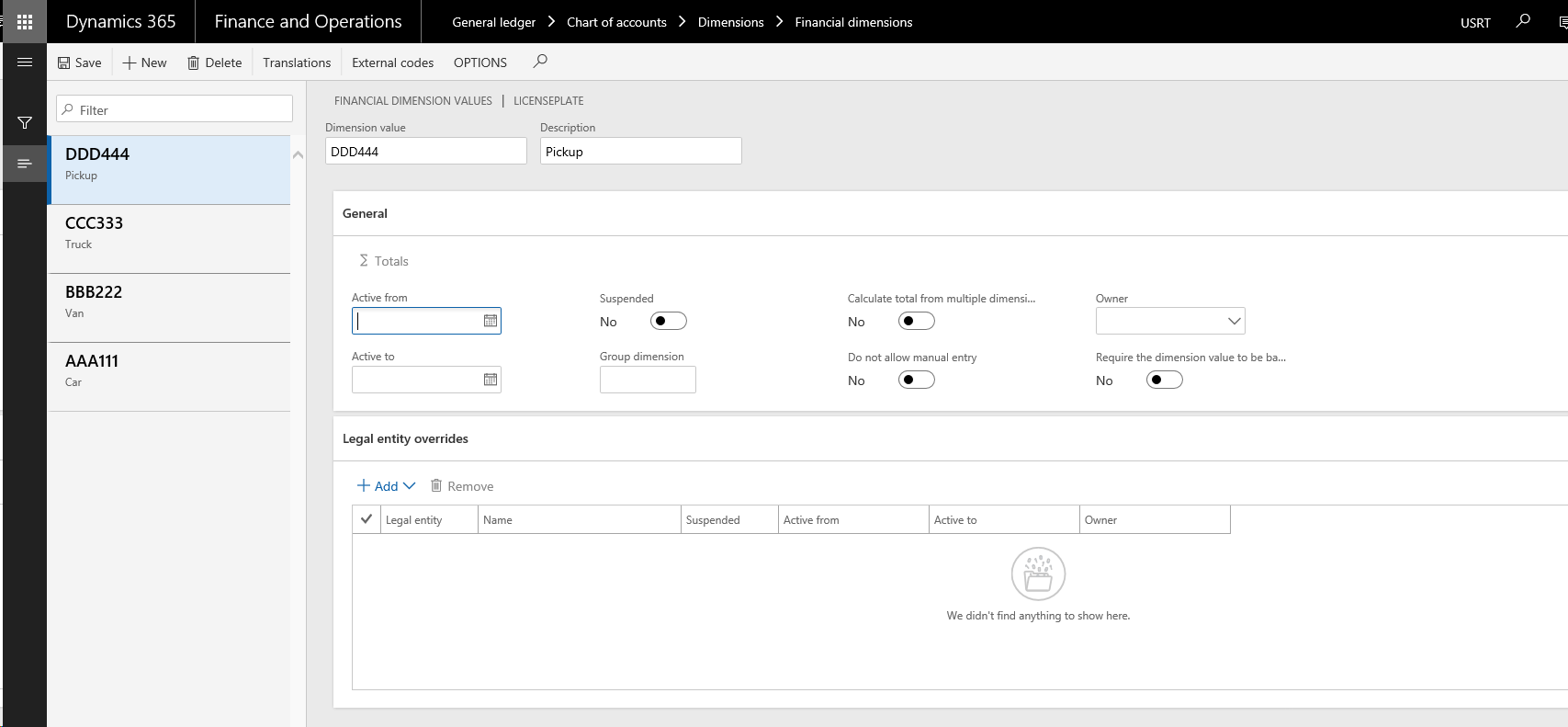
以下の図は、カスタムリストが表示する値の一覧の例を示しています。 以下例では、分析コードフレームワークには値が格納されています。
次の図は、上記図の分析コード設定テーブルから取得されたクエリの結果を示しています。
これらの例で、財務分析コード値ページには、エンティティに存在する値が表示されます。分析コード フレームワークで実際に使用された値ではありません。 これは、フレームワーク上でこれらの値が使用されるまでは分析コード フレームワークの値が作成されないためであり、バッキング値への参照を保持する必要があるためです。 そのため、まだ使用されていない値は削除できます。 この仕様により、ストレージサイズとパフォーマンスを最適化できます。
分析コード値を参照した後、分析コードフレームワークが分析コード値を保存できるようにするには、分析コード値がDimensionAttributeValueテーブルに格納されている必要があります。 DimensionAttributeレコードと、ViewNameビュー内の特定の RecId 値、DimensionAttributeレコードで参照されるテーブルの接点となります。 ユーザーが入力した元の値に復元するためには、DimensionAttributeとDimensionAttributeValueの両方のレコードが必要です。
分析コードフレームワークが何も参照していないシステムでは、DimensionAttributeValueテーブルにレコードが作成されません。
第2部: 分析コードの一覧とデフォルトの分析コード
この記事では、下記の図で黄色で強調表示されている箇所「分析コード一覧」、「既定分析コード」について説明します。
分析コード一覧とデフォルト分析コードは、分析コードまたは分析コード値のいずれかへの参照のセットを格納するために使用されます。 一般的には、両方とも顧客 (CustTable) や仕入先 (VendTable) のようなプライマリ データ ページにある財務分析コード タブに表示されます。
分析コードの一覧
分析コード一覧は、既存の分析コードに対する参照のセットであり、後に使用されることに備えて保存されます。 これらの分析コードには特に順序の制約がありません。また、分析コードフレームワークは、セット上に表示される分析コードに対する制約を課しません。 ただし、多くの場合、消費コードは使用中の元帳コードで使用できる分析コードの組み合わせに制約を加えます。 分析コードの一覧は、DimensionAttributeSetおよびDimensionAttributeSetItemテーブルに格納されます。
各組み合わせには列挙型を指定します。 この列挙型は、それぞれの分析コードに関連付けられている列挙値の元を表す、BaseEnum の列挙 ID を指します。 列挙番号を確認するには、 enumnum () メソッドを使用します。 これはバッキング エンティティを元とするユーザーが入力した値のリストではなく、開発者によって定義された列挙値の一覧です。 例としては、それぞれの主勘定に関連付けられ、固定 (固定値 とラベル)、または固定されていない (非固定 とラベル) 分析コードリストの格納です。
以下の図は、ページ内における分析コード一覧の表示例を示しています。
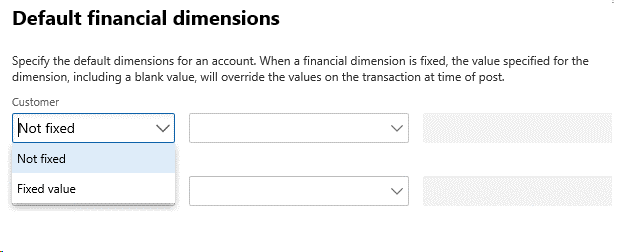
上記例では、 dimensionfixed 一覧を使用して、ドロップダウンリストの値のリストを制約しています。
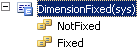
選択された値は EnumerationValue (= DimensionFixed::Fixed) にて 1 と表示され、その他の値は EnumerationValue (= DimensionFixed::NotFixed) にて初期値 0 として表示されます。 以下の図は、DimensionAttributeSetレコードがどのように格納されているかを示しています。
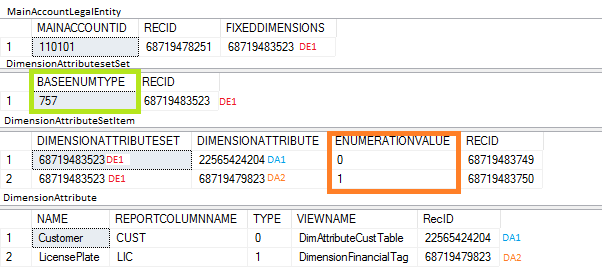
MainAccountLegalEntity のレコードは、 FixedDimensions 列を使用して fielddimensionattributeset のレコードを参照しています。 DimensionAttributeSet に格納されているレコードは、列挙型の分析コードの組み合わせを表しています。 DimensionAttributeSetItem のレコードは、分析コードに結びつくデータの組み合わせと、関連する列挙値を表します。 列挙値は、整数値で表示されます。
既定の分析コード
分析コード一覧は、列挙値と関連付けられている分析コードの組み合わせを保持しているため、初期設定では一定の分析コード値を持つ一連の分析コードを保持しています。 既定の分析コード という用語は、ここに含まれるデータがトランザクションを介さず直接マスタデータレコードに入力され、それらが勘定科目の組み合わせに既定値として入力されることに由来します。 分析コードの一覧に関しては、初期設定の分析コードに一連の構造が関連付けられていないため、多くの場合、消費コードは使用中の元帳で使用できる分析コードの組み合わせに制約を加えます。 既定の分析コードは、DimensionAttributeValueSet および DimensionAttributeValueSetItem テーブルに格納されます。
以下の図は、ページ内における既定の分析コード例を表示しています。
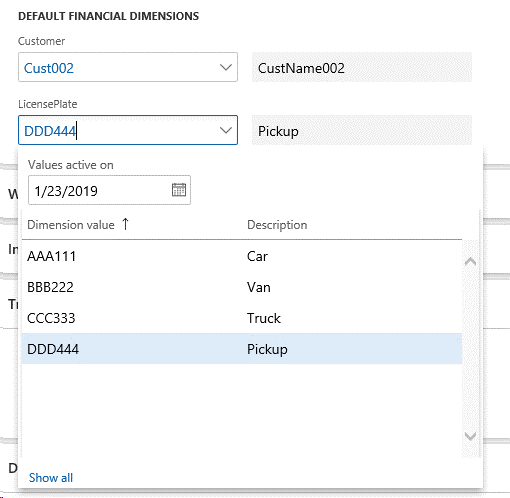
上記の例では、ユーザーは分析コード値を選択し、それぞれの分析コードに関連付けています。 以下の図は、これらの値がDimensionAttributeValueSetとDimensionAttributeValueSetItem テーブルにどのように格納されているかを示しています。
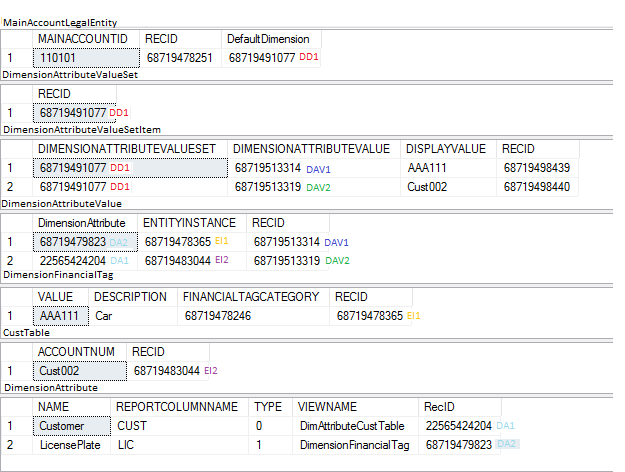
MainAccountLegalEntity のレコードは、入力された値の組み合わせを表す DimensionAttributeValueSet テーブルへの外部キー参照を保持します。 具体的には、このテーブルは DimensionAttributeValueSetItemテーブルに格納されている分析コード値の一連の組み合わせを保持しています。
DimensionAttributeValueSetItem テーブルは、入力された分析コード値にそれぞれに対して1つのレコードを保持しています。 このレコードは、DimensionAttributeValue を参照しています。 入力されていない分析コード (空白のままになっているレコード) は保存されません。 既定の分析コードを入力すると、分析コードの値が分析コードフレームワークで使用されるようにるため、DimensionAttributeValueテーブルに2つのレコードが作成されます。 このように、分析コードのフレームワーク値は、バッキングエンティティと連係されます。 パフォーマンス上の理由から、分析コード値のナチュラルキー (表示される値) は、DimensionAttributeValueSetItemテーブルに格納されています。
値のソースを確認するには、DimensionAttributeValueテーブルの EntityInstance 列に格納されているリンクと、 DimensionAttribute テーブルの ViewName 列を参照し、CustTable (DimAttributeCustTable ビュー経由) の元となっているテーブルのレコードと DimensionFinancialTag を検索します。
第3部: 構造と制約
この記事では、下記の図で黄色で強調表示されている箇所「構造」と「制約」について説明します。
前述のとおり、分析コード フレームワークでは、分析コードの数に制限がありません。 さらに、ユーザーが勘定科目の組み合わせを入力する際に、組み込む分析コードとその順序を指定できます。 また、その勘定科目の組み合わせの各区分に対する入力値に制約を加えることも可能です。
勘定構造
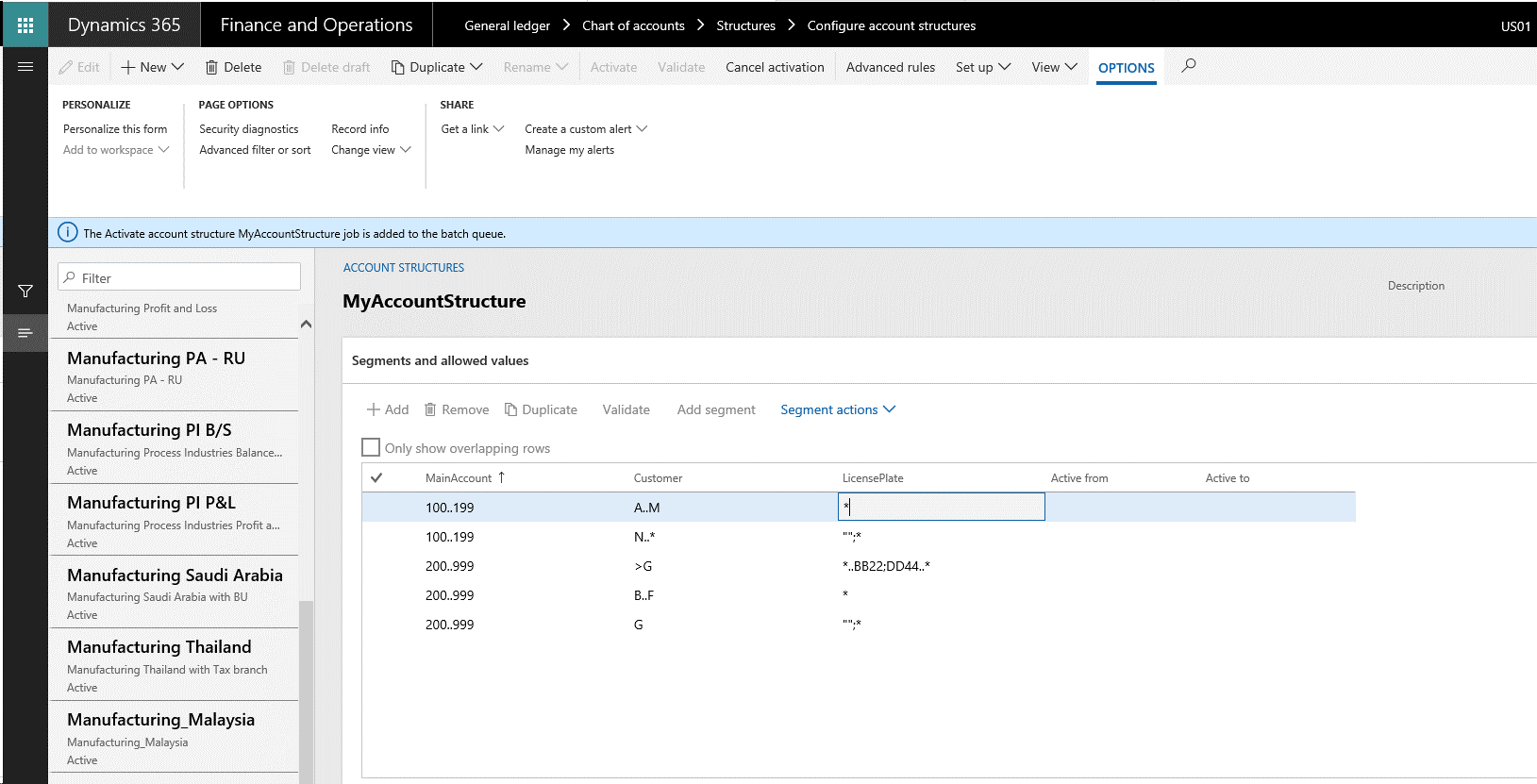
以下の図は、勘定の構造例を示します。
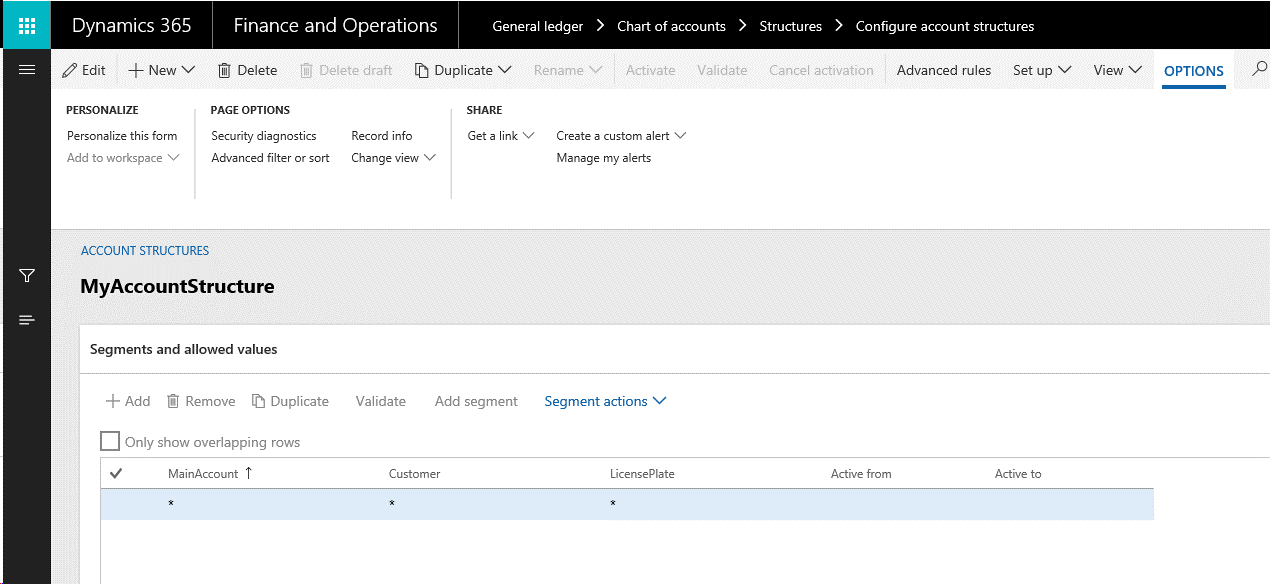
以下の図が示すように、この勘定構造は、データベースの DimensionHierarchy テーブルに格納されています。 ここでは、勘定科目の組み合わせの最初の入力区分として主勘定を入力し、続いて顧客およびライセンスプレート番号を入力するように設定されています。 この設定では、階層の順位を定義します。 この設定はデータベースの DimensionHierarchyLevel テーブルに格納されています。
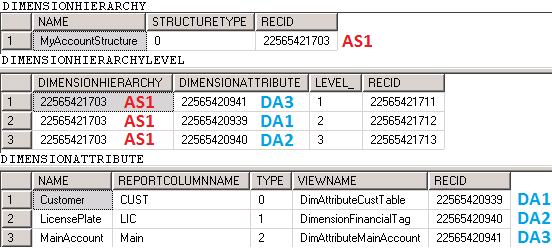
順位の設定に加えて、制約を設定する必要があります。 制約とは、有効な値の組み合わせを定義する条件を意味します。 この例では、すべてのセグメントにて組み合わせの値を指定する必要があります。 この設定を行わない限り、有効とみなされません。 既に存在する値 (つまり、バッキングエンティティに存在するすべての値) を入力でき、有効となる値の組み合わせについて特に制限はありません。 この条件は、DimensionConstraintTree、DimensionConstraintNode、DimensionConstraintNodeCriteria の各テーブルに格納されます。
上記図の例では、必要最低限の制約ツリーが示されています。 アスタリスク (*) のついている制約条件は、3 つの制約ノードにそれぞれ関連付けられています。 この制約条件は、存在するすべての値を意味します。 データベース上はパーセント記号 (%) で保存されており、UI上では "<すべての値>" として表示されます。 これらの制約は、ルックアップを介して各セグメントに入力できる値を表示したり、セグメントに入力された値を検証するために使用されます。 こうした設定の結果、勘定科目の組み合わせに対して誤った値が入力された場合は、制約が検証エラーを返します。
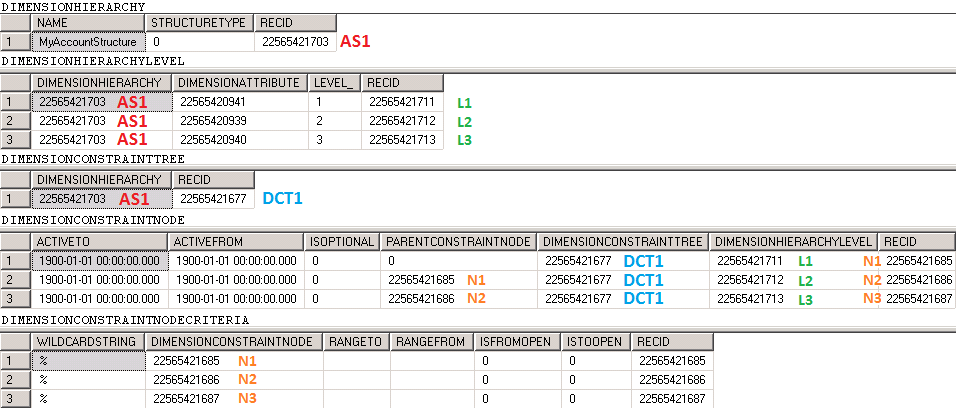
Dimension frameworkでは、より複雑な制約ツリーを設定することが可能となり、最初のセグメントに入力された値によって次の区分に入力可能な値を判断することができます。 以下の図は、この多機能性の一例を表しています。
以下の図では、より複雑な制約ツリーを表しています。
以下の図は、制約定義のクエリ結果を示しています。
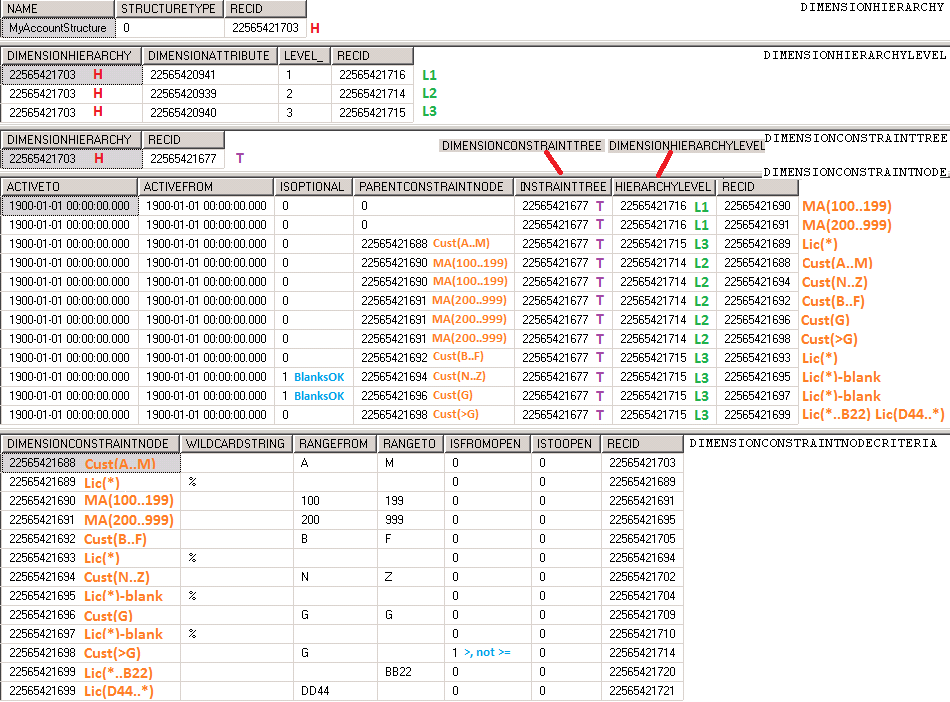
ユーザーが主勘定と顧客に 150-B と入力した場合は、特定のライセンス プレート番号を入力する必要があります。 一方で、 150-W と入力した場合は、ライセンスプレート番号は必要ありません。 どちらの場合も、勘定科目の組み合わせでは常に3つのセグメントが表示されます。このいずれかが空白のままであっても。 勘定科目分析コードが入力された際に、構造、区分、制約が与える影響については、このトピックの第 5 部にある勘定科目の入力と保存についての説明を参照してください。
入力必須となっている後続のセグメントのみを表示するには、詳細ルールと勘定構造の組み合わせることで、さらに柔軟な設定を実現することができます。
第4部: 高度なルール
この記事では、以下の図で黄色で強調表示されている「詳細ルール」について説明します。
勘定構造と制約を使用することで、簡単なものから複雑なものまで有効な組み合わせのツリーを構築することができます。 しかし、常に有効な分析コードの値を制約するのではなく、一定時間のみ勘定科目の組み合わせの一部として分析コードを表示するという業務上の要件があるかもしれません。 高度なルールを使えば、こうした要件にも対応可能です。
詳細ルール
高度なルールは、勘定構造とその制約に追加することが可能です。 高度なルールには汎用性がありますが、使用するタイミングを判断し、最適なユーザビリティ、パフォーマンス、理解を発揮するには、以下のガイドラインを参照してください。
- ルールによって勘定構造を置き換えることはできません。 構造は常に存在する必要があり、主勘定区分は必須項目です。
- 勘定構造に既に存在する他のセグメントの前に分析コードを追加することはできません。
- 主勘定に関係なく、常に必要とされる追加分析コードの勘定科目構造の制約をルールで置き換えることはできません
- ルールは勘定構造内に既に存在するセグメントを複製したり、他のルールを複製したりすることはできません。
- 重複のあるルールは自動的に結合され、最も制限の厳しい制約が使用されます。
- セグメント内に重複したルールがある場合については、同セグメント内の最初に記述された箇所のみに表示されます。
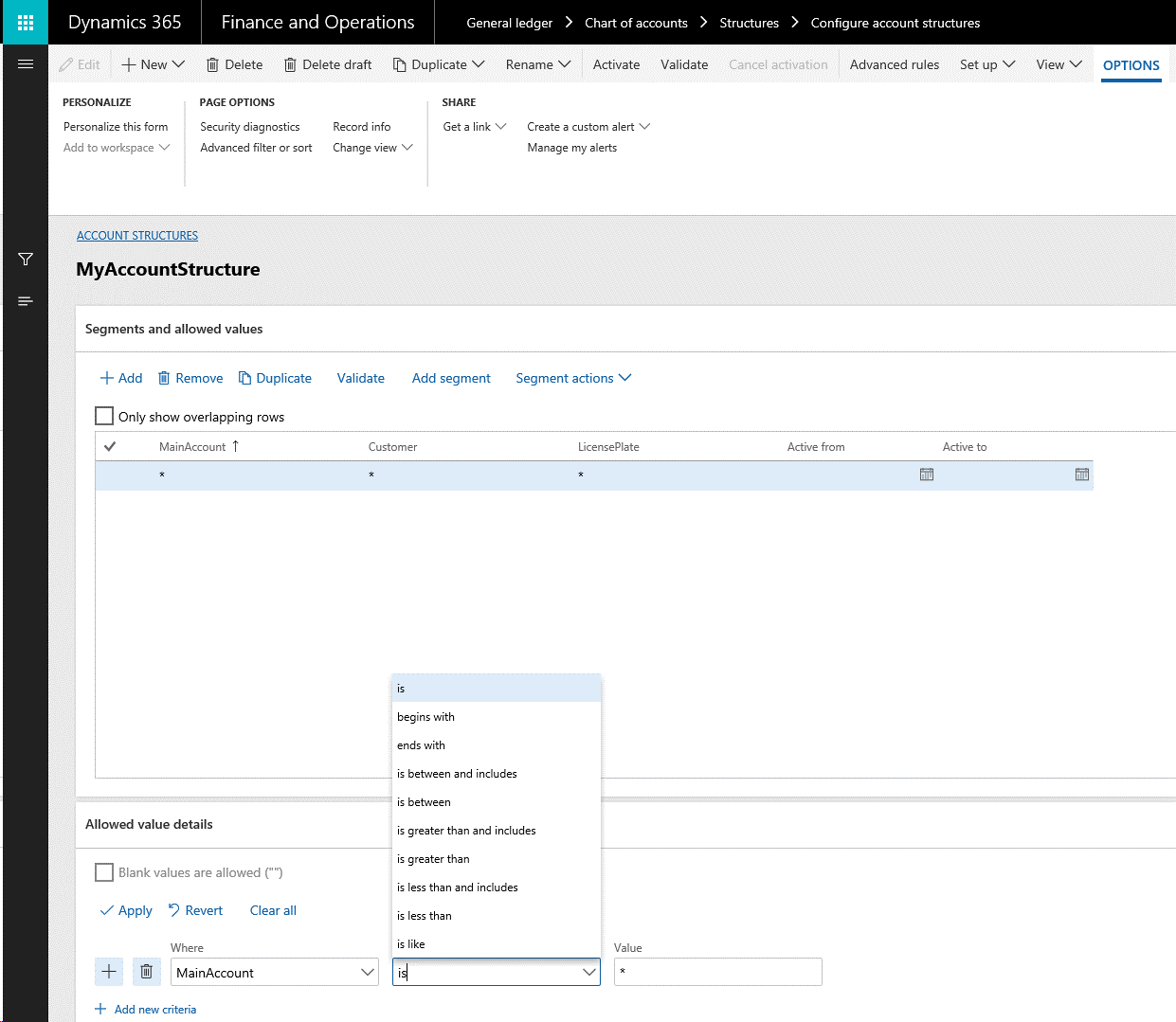
高度なルールを設定するには、勘定科目の組み合わせにセグメントを追加するタイミングを制御するフィルタを定義する必要があります。 次に、追加の必要がある追加セグメント、階層内の順位、およびそれらを制約するルール構造を結びつける必要があります。 (ルールの構造は勘定構造と類似した特徴があります)。
たとえば、以下の勘定構造が設定されているとします。

以下の高度なルールでは、ユーザーが主勘定に 145 を入力し、かつ顧客に G ~ Qを 入力した場合にのみ、1つから2つ以上のセグメントを追加する設定です。
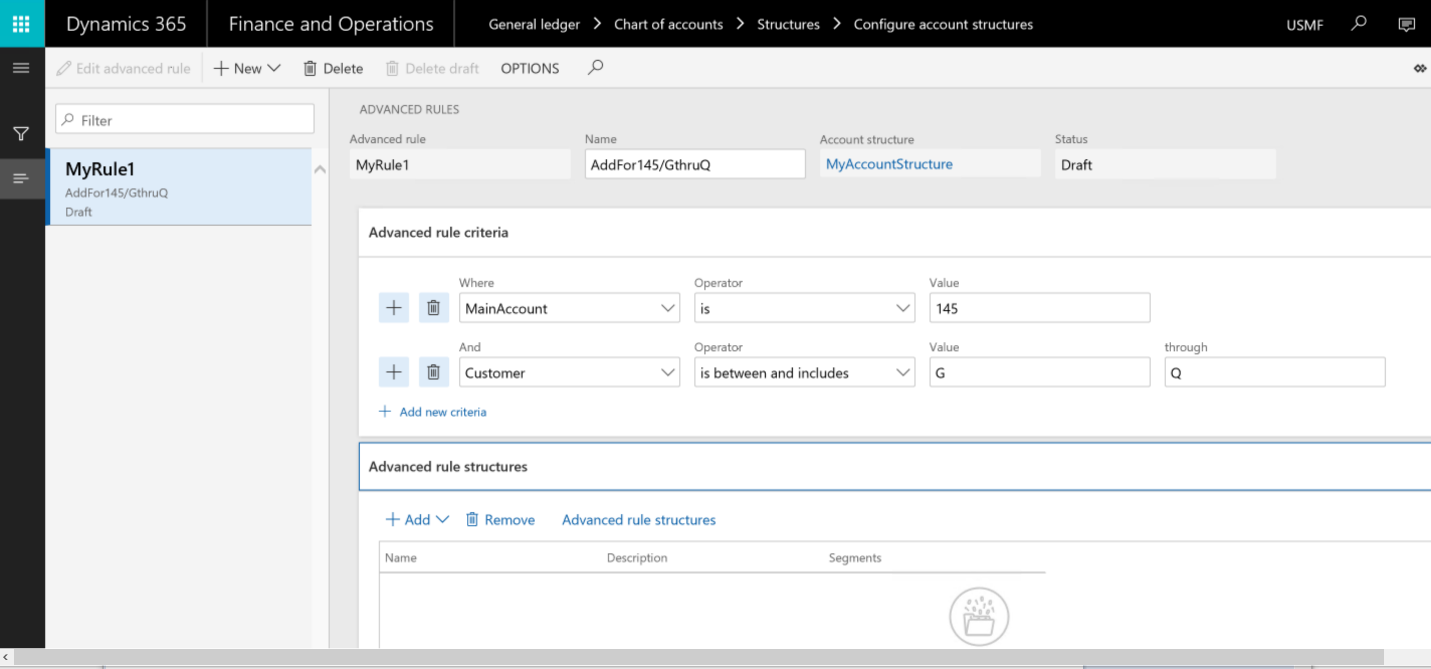
ルールを設定した後で、構造と制約定義を作成して、勘定科目の組み合わせにどのようなセグメントを追加するかの定義を加える必要があります。 この手順を完成させるには、以下のルール構造を作成します。 ルール構造を作成するプロセスは、勘定構造を作成するプロセスと共通しています。 これらの構造には、ただちにルールの適用がされません。 したがって、これらのルールを必要に応じて複数のルール間で共有することができます。
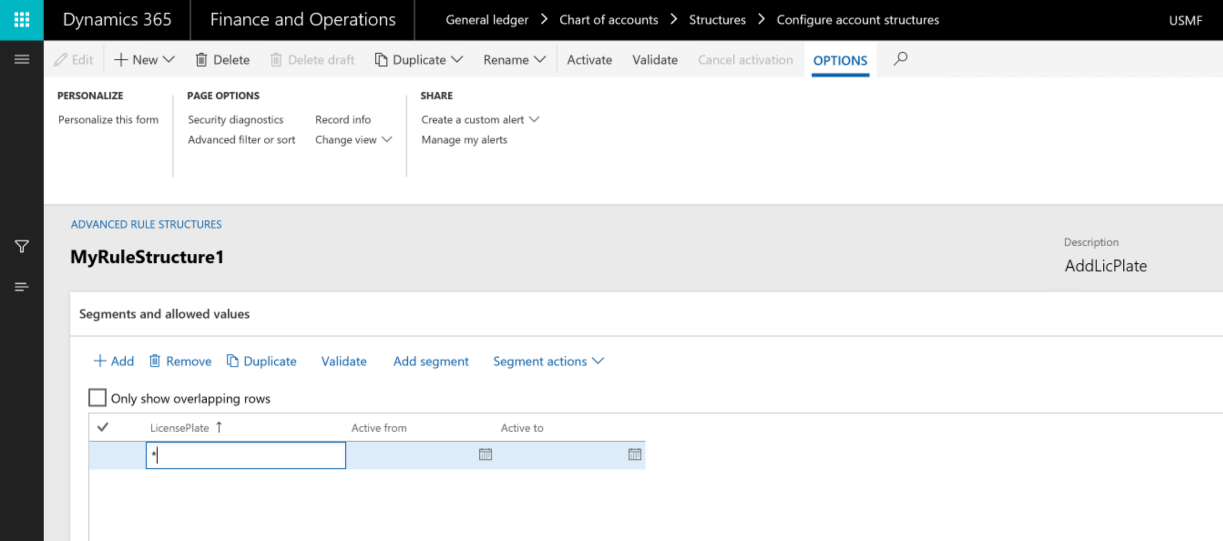
ルール構造を作成した後、分析コードのルールへと追加します。 そうすると、勘定構造がルールと共に有効化されます。

このデータが保存される場所は、勘定構造の保存場所と共通のテーブルが使用されます ( 第3部を参照)。 DimensionRule、DimensionRuleAppliedHierarchy、DimensionRuleCriteria の各テーブルには、ルールの定義に特化したデータが格納されます。 ここにはルール構造の定義へのリンクも保持しています。 そのほか残りのテーブルは、勘定構造の定義と共有されています。
第5部: 勘定分析コード
この記事では、以下の図で黄色で強調表示されている「勘定分析コード」について説明します。
すべての設定データを完了すると、勘定科目の組み合わせを追加、検証、継続使用することができます。 この分析コードフレームワーク領域は、主にアプリケーションが使用しています。
ルールが適用されていない元帳分析コードストレージ
元帳分析コードを理解するには、ユーザーがどのように勘定科目の組み合わせを入力しているかを理解する必要があります。
このセクションでは、この記事の第 4 部にある勘定構造とルール設定を使用し、勘定が入力された場合の勘定入力の制御方法について説明します。 勘定構造は以下のようになります。
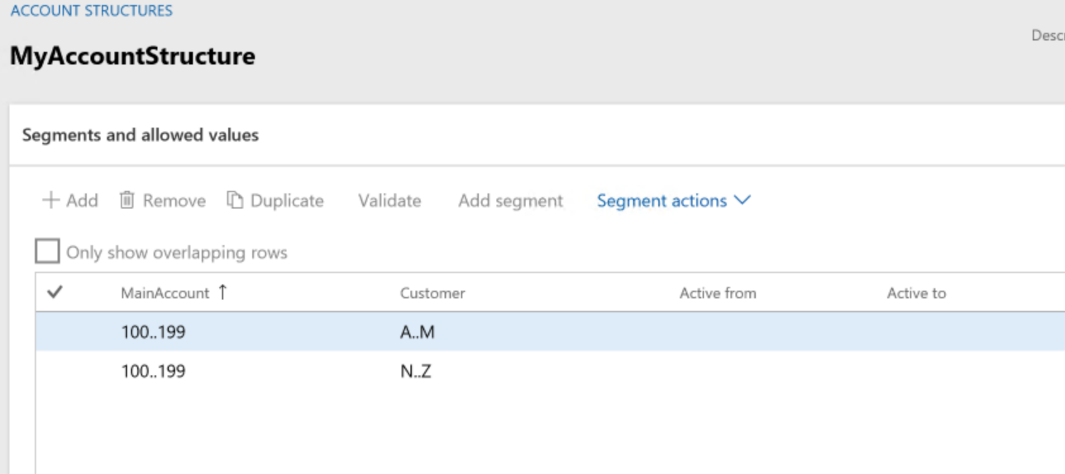
1つの勘定ルールが勘定構造に関連付けられています。
以下の図は、追加された構造を示しています。

以下の図は、ユーザーが最初にページで表示したときに、フォーカスを持たない勘定科目フィールドがどのように表示されるかを示しています。
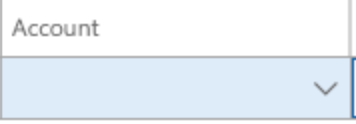
このフィールドをクリックしても、何も変更されません。 ドロップダウンの矢印を選択すると、ルックアップが表示され、使用可能なセグメントが表示されます。 以下の図では、2つのセグメント候補が表示されています。
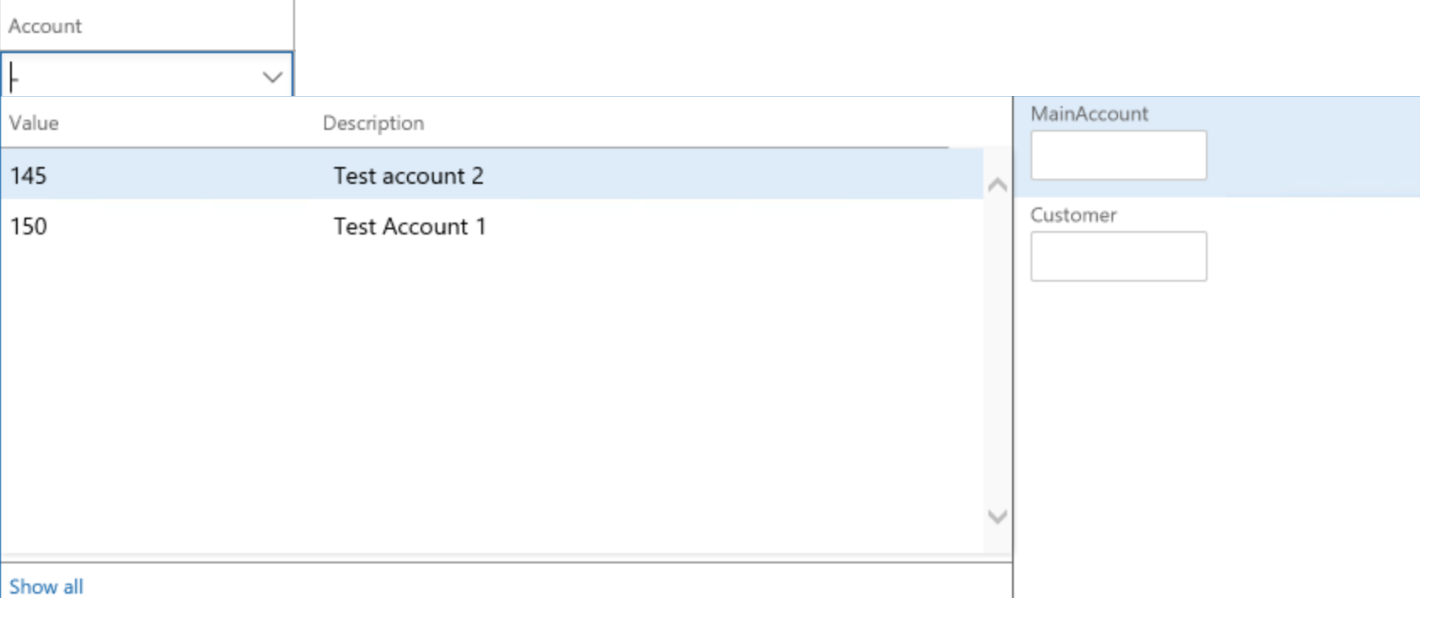
以下の例では、 150-Aの組み合わせが入力されています。

2番目のセグメントが入力し、 Tab を押下して入力欄を移動するとただちに、分析コードフレームワークが制約に基づいた検証を行い、その組み合わせが保存されます。 この例では、入力された組み合わせは有効とみなされています。 ユーザーは、文字を入力するか、あるいはルックアップを使用してセグメントに入力することができます。
この例では、組み合わせについて以下の情報がわかっています。
- 勘定構造は、 myaccountstructure という名称です。
- 最初のセグメントは、MainAccount分析コードです。 コード値は 150 です。
- 2番目のセグメントは、顧客分析コードです。 コード値は A です。
- 値がこの勘定構造に関連付けられている詳細ルールと一致しなかったため、区分が追加されませんでした。
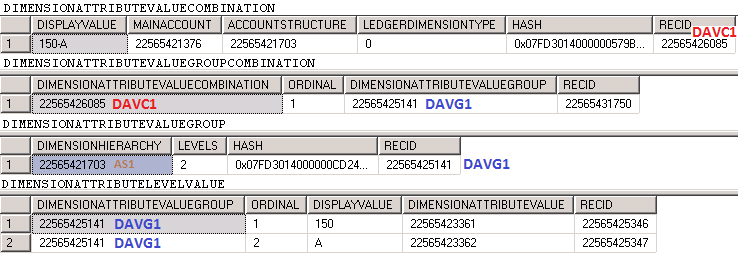
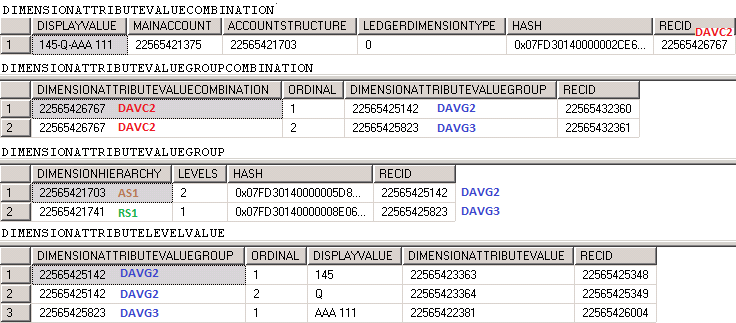
結果として、以下の図に示すように、2つのセグメントの値が4つのテーブルにまたがって格納されます。
 ]
]
1番目のテーブルは DimensionAttributeValueCombination.です。 すべてのマルチセグメントアカウントの組み合わせと、その組み合わせに関する非正規化された情報が格納されます。 このテーブルに格納されている情報の例としては、連結されたセグメントをひとつの文字列として格納し、勘定構造への外部キー参照を格納し、使用された主勘定 (150) に対する外部キーが格納されています。
2番目のテーブルは DimensionAttributeValueGroupCombination です。詳細は後述します。
3番目のテーブルは、 DimensionAttributeValueGroup です。 組み合わせに含まれる各構造に関連付けられた、セグメントのグループが格納されています。 この図では、構造が1つ (勘定構造) しか存在しないため、レコードは1つしか存在しません。
4番目のテーブルは、 DimensionAttributeLevelValue です。 関連するグループまたは構造に存在するセグメントの値がそれぞれ格納されています。 入力されたセグメントごとに1つのレコードが存在します。 セグメントが空の場合は、値が格納されません。 各レコードは対応する DimensionAttributeValue レコードを参照します。 値に対応するレコードが DimensionAttributeValue にて見つかった場合は、そのレコードが参照されます。 値に対応するレコードが DimensionAttributeValue にて見つからなかった場合は、そのレコードが生成されます。 このデータは、DimensionAttribute を実際のバッキング エンティティ レコードに連係します。 この例でDimensionAttributeLevelValue には2つのレコードが表示されており、ひとつは 150 というIDを持つ MainAccount レコードと、もう一方は A というIDを持つ CustTable レコードを表示しています。
勘定構造の値とセグメントの値のグループを DimensionAttributeValueCombination のメインレコードに連係するには、2番目のテーブルである Dimensionattributevaluegroup にレコードが挿入されます。
1つのセグメントを新しい組み合わせで保存するには、最低でも1つのレコードがこれらの4つのテーブルに作成されている必要があります。 入力された追加セグメントごとに、DimensionAttributeLevelValue テーブルにレコードが追加挿入されます。 これら4つのテーブルは、勘定分析コードと呼ばれます。 元帳分析コードは、DimensionAttributeValueCombination テーブルの RecId 値を参照する外部キーとして表されます。
ルールが適用された元帳分析コードストレージ
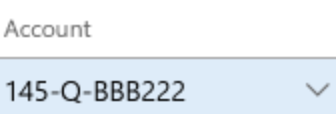
このセクションで扱う内容は、前のセクションでの勘定分析コードストレージ例に基づいています。 ここでは、値を 150-A から 145-Qに変更します。 前段で説明した高度なルールで述べたように、この変更により3番目のセグメントが勘定構造に追加されます。

2番目のセグメントの後にハイフン (-) を入力すると、3番目のセグメントがコントロールに追加され、フォーカスが移ります。

3番目のセグメントにフォーカスがあるときにルックアップを開くと、3番目のセグメントに対応する値が表示されます。
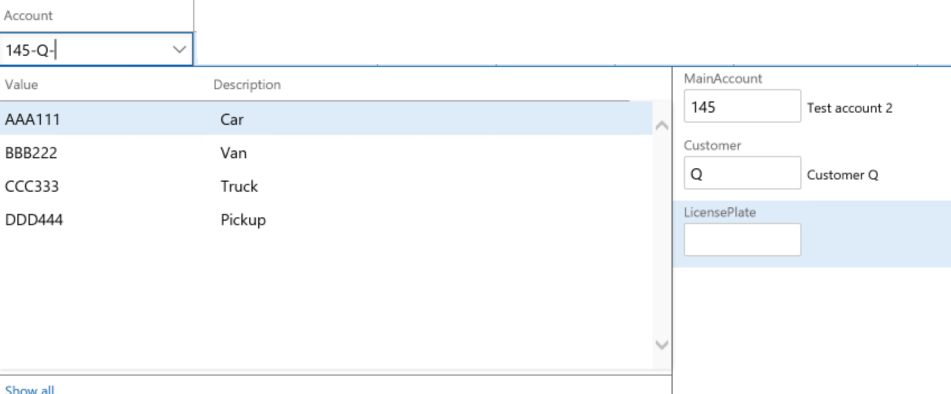
この段階でライセンス番号が入力可能となります。

3番目のフィールドに値を入力し、 Tab を押下してコントロールを移動すると、入力された組み合わせの検証が行われます。 入力された組み合わせが有効な場合は、勘定分析コードとして保存されます。
この例では、新規で入力された組み合わせについて以下の情報がわかっています。
- 勘定構造は、 myaccountstructure という名称です。
- 最初のセグメントは、MainAccount分析コードです。 コード値は 145 です。
- 2番目のセグメントは、顧客分析コードです。 コード値は Q です。
- この値は最初の2つのセグメントのルールと一致するため、 MyRuleStructure1 という名前の勘定科目のルール構造が追加されました。 この結果、1つのセグメントが追加されました。
- 3番目のセグメントは、LicensePlate 分析コードです。 コード値は AAA 111 です。
 ]
]
この組み合わせでは、勘定分析コードを格納する4つのテーブルに合計8個の行が挿入されました。 前段 (第4部) で述べた最初の勘定科目の組み合わせと、この勘定科目の組み合わせとの違いは、この勘定科目を構成する分析コードを活用するために複数の構造が使用される点です。 2つの分析コードは、DimensionAttributeValueGroupCombination および DimensionAttributeValueGroup テーブルに格納されます。 それぞれのレコードは、完全な組み合わせに使用、または結合される構造を表します。
各レコードに新しい RecId 値が割り当てられていることに留意してください。 古い値の組み合わせについては更新されません。 代わりに、新しい組み合わせが作成されます。 結果として、組み合わせの使用に対して参照カウントが保持されなくなるため、元帳分析コードは変更不可能となります。 ユーザーがインスタンスを 145-Q-AAA 111 へと変更する前に、 150-Q と同じ組み合わせがアプリケーション内で複数のテーブルから参照される可能性があります。 そのため、新しい組み合わせを作成する必要があります。勘定科目の組み合わせが変更されたテーブルから、その新規組み合わせに対する参照を変更する必要があります。
セグメントの値を追加する、削除するなどレコードの組み合わせを変更すると、新たな勘定分析コードが作成されるので、参照がなく孤立した元帳分析コードとなってしまいます。 孤立した組み合わせを許可することにより、組み合わせを変更するたびに対象テーブルのレコードの削除の確認をする必要がなくなるため、分析コードフレームワーク全体のパフォーマンスが向上します。 一度使用された組み合わせは、再利用されることがあります。 したがって、最後に残っていた参照が削除された場合でも、再作成されることがあります。 元帳分析コードは孤立した状態であっても構造的には有効であり、構造とルールに関連した値の組み合わせが再度入力された場合は再利用することができます。 この組み合わせが別の時点で入力された場合、レコードは挿入されず、既存の参照が再利用されます。 結果として、パフォーマンスが向上します。
高度なルールを使用する場合は、記憶領域のサイズやデータ挿入のコストに対しても最適化処理が行われます。 たとえば、以下の図では、新しい勘定の組み合わせが入力されています。
この場合、新しい組み合わせと古い組み合わせとの違いは、高度なルール が指定する ライセンスプレート の番号が変更されたことです。 以下の図は、この組み合わせのデータがどのように格納されているかを示しています。 新しいレコードは白で強調表示されます。

新しい組み合わせが作成されると、以下5つのレコードが挿入されます。 (これらのレコードは、上記の図にて白で強調表示されています)。
- DimensionAttributeValueCombination テーブルに格納されている1つのレコード
- DimensionAttributeValueGroupCombination テーブルに格納されている2つのレコード
- DimensionAttributeValueGroup テーブルに格納されている 1つのレコード
- DimensionAttributeLevelValue テーブルに格納されている 1つのレコード
この挙動は勘定構造 グループ の一部として保管されている値が、以前の組み合わせ (DAVC2) と今回の組み合わせ (DAVC3) で同じであるために発生します。 DimensionAttributeValueGroup テーブルと DimensionAttributeLevelValue テーブルのレコードは再作成の必要がありませんでした。 代わりに3つのレコードを再利用し、挿入処理のコストを節約することができます。
勘定科目のルールに関連付けられている構造で、ライセンスプレート番号に空白の値を許可されており、 145-Q の組み合わせだけが作成された場合は、2つの新規レコードのみが挿入されます。
- DimensionAttributeValueCombination テーブルに格納されている1つのレコード
- DimensionAttributeValueGroupCombination テーブルに格納されている1つのレコード
- DimensionAttributeValueGroup テーブルには該当するレコードがありません。
- DimensionAttributeLevelValue テーブルには該当するレコードがありません。
この挙動の仕組みとしては、 DimensionAttributeValueGroup テーブルと DimensionAttributeLevelValue テーブルのすべてのレコードが既に存在しており、新しい組み合わせにて完全に再利用できるためです。 こうした挙動が考えられるため、勘定分析コードのストレージテーブル上でデータを直接変更することは避けてください。 1つのレコードに対する変更は、元帳分析コードに対するすべての参照に影響するだけでなく、その他の複数の勘定分析コードと参照に影響する可能性があります。
このセクションで説明した例では部分的に表示しきれていませんが、DimensionAttributeValueCombination テーブルと DimensionAttributeValueGroup テーブルには ハッシュ コードが割り当てられています。
パート6: 高度なトピック
このパートでは、分析コードフレームワークの機能を強化するにあたって、より詳細な設計および実装の意思決定を行う上で役立つ高度なトピックを扱います。
以下の図では、分析コードフレームワークを構成するさまざまな領域を示しています。
ハッシュ
分析コード フレームワークにおけるデータベース ストレージは、次の機能を目的として設計されています。
- データが挿入されるだけで、更新も削除もしない不変データに対応しています。
- 作成済みの組み合わせを再利用して、挿入処理のコストを削減します。
- 参照カウントの実行と管理の必要性をなくします。
- 再利用可能な既存の組み合わせを検索するにあたって、パフォーマンスの向上が図れます。
勘定科目の組み合わせでは、分析コードの数は無制限で、構造体の数に制限はありません。そのため、1つの大きなクエリまたは複数の小さなクエリを作成して、既存のセットまたは組み合わせを検索することは現実的ではありません。 レコードの数と順序は、組み合わせごとに異なる可能性があるため、ハッシュ ベースのソリューションが実装されています。
ハッシュとは、関連付けられているテーブルのレコードに含まれる固有の情報を意味し、問い合わせ処理の高速化を可能にします。 データの組み合わせに含まれるするデータを一意に識別するために、単一のバイナリコンテナフィールド (160ビット、20バイトのハッシュ列) が保存されます。
分析コードフレームワークはハッシュを使用して、以下テーブルのデータを一意に識別します。
- DimensionAttributeValueComlevelation : 次の表は、DimensionAttributeValueGroupテーブルおよびDimensionAttributeLevelValueテーブル内のすべてのリンク されたレコードのデータで構成されています。
- DimensionAttributeValueGroup : このテーブルは、DimensionAttributeLevelValueテーブルにリンクされたレコードのデータで構成されています。
- DimensionAttributeSet : このテーブルは、関連付けられているDimensionAttributeSetItemレコードのデータで構成されています。
- DimensionAttributeValueSet : このテーブルは、関連付けられているDimensionAttributeValueSetItemレコードのデータで構成されています。
ハッシュ メッセージ
ハッシュを生成するにあたって、セットまたは組み合わせの内容に関する個々の順序付けられた情報を持つメッセージが作成されます。 生成されたハッシュによってメッセージは異なりますが、ハッシュメッセージに基本的に含まれているのは、分析コード、値、構造に関する情報と、組み合わせ内における順序が含まれています。 この情報は、所定の方法で内部的に計算され、ハッシュルーチンに渡されます。 ハッシュ ルーティンは、バイナリ コンテナーを使用してハッシュ キー生成するハッシュを生成します。 これらのメッセージの正確な順序と内容は、分析コード フレームワークのストレージサポートクラスのメソッドによって提供されます。 これらのクラスには、 DimensionAttributeSetStorage、 DimensionAttributeValueSetStorage、 DimensionStorageが含まれます。
メモ
内部ハッシュ関数が Dynamics 365 Finance で更新されました。 詳細については、Dynamics 365 Finance 2020 リリース ウェーブ 2 への更新後にハッシュ関数の変更を確認するを参照してください
ハッシュ キー
ハッシュ メッセージを生成するには、分析コード 、値、組み合わせを構成する構造のそれぞれを一意に識別する要素が必要となります。 RecId 値は、一意の識別子として機能しますが、これはサロゲートとして見なされます。これはたとえば、レコードをエクスポートしてから別のシステムまたはパーティションにインポートすると変わる可能性があるため、不変の値とはみなされません。 RecId 値は、インポートプロセス中に再割り当てすることができます。 もし RecId 値を使用したハッシュメッセージでハッシュが作成された場合は、そのハッシュは作成されたシステムあるいはパーティションの分析コードフレームワークの組み合わせを識別するために使用することはできません。 代わりに、GUID を使用します。 GUIDは、DimensionAttribute、DimensionAttributeValue、Dimensionattribute の各テーブルに存在し、 hashkey 列に格納されています。 新しいレコードが作成されるたびにGUIDが割り当てられるため、レコードを一意に識別することができます。
データを直接変更するリスクについて
アプリケーション フレームワーク (Microsoft SQL Server Management Studio など) の外部でデータを直接変更することは避けてください。 このガイドラインは、テーブルに存在するすべての列が対象となります。この記事で扱う列のみを対象にしているわけではありません。 これはさらに、1つの行から別の行へのデータのレプリケーションにも適用され、分析コードフレームワーク ストレージクラスの外部で "新しい" セットまたは組み合わせを作成する処理も対象となります。
データのバックアップと部分的な復元を検討している場合は、参照とハッシュの整合性に影響を与える可能性のあるこのガイドラインを理解しておくことが重要です。 たとえば、勘定分析コードに関連するレコードのみをバックアップし、それを別の区分にインポートした場合、すべてのバッキングエンティティレコードに加えて、分析コードフレームワーク内の他のすべてのレコードをインポートしない限り、問題が発生する可能性があります。 こうしたテーブルのデータの変更をしたり、GUIDやハッシュを合成することが、データの破損を引き起こし、結果として複雑で時間のかかる原因調査や修復をすることになります。
組み合わせの重複
分析コードフレームワークのテーブルを参照して、保存されているレコードの DisplayValue フィールドのみを表示すると、組み合わせが重複しているように見える場合があります。 しかし、 displayvalue の内容が同じで見かけ上は重複していても、ハッシュまたは結合テーブルのデータが異なることがわかります。 Displayvalue 文字列は、パフォーマンスの向上を目的として格納されているのであって、レコードを一意に識別するために使用されるわけではありません。
たとえば、ある会社の勘定構造に MainAccount-Department があり、別の会社の勘定構造に MainAccount-CostCenter があるとします。 このシナリオでは、勘定構造ごとに1つずつ、2つの組み合わせの DisplayValue 文字列が 145-A と表示されることがあります。 最初の勘定構造では、 A が最初の会社の部門を表します。 しかし、2番目の勘定構造では、2番目の会社の原価部門を表します。 DimensionAttributeValueCombination テーブルには、複数の種類の元帳分析コードが格納されています。 たとえば、 DisplayValue のフィールドを確認すると、予算に関する特別なタイプは他の組み合わせのタイプと同じに見えることがあります。 しかし、内部的には異なる情報を保持し、それぞれ異なる一意のハッシュ値を保持しているのです。
バージョン管理/有効日付データ
分析コードフレームワークでは、バージョン管理データまたは日付効率データに直接対応していません。 このプラットフォームでは、日付が有効なテーブルの最新バージョン行に新しい RecID が割り当てられます。 分析コードフレームワークは、元のエントリの時点で RecId によるバッキング値への参照を取得するため、新しいレコードが導入された場合、日付コンテキストが分析コード データに維持されないので、システムは古いバージョンを使用できなくなります。
同じバッキング エンティティ レコードが使用されている分析コード データを使用して、別の追加したテーブルが所有しているモジュール内の改訂履歴情報を追跡している場合は、分析コードフレームワークではこのバージョン間の差異を特定できません。これはバッキングエンティティに存在する RecId の値が異なるバージョン間であっても同一であるためです。 これにより、分析コード フレームワークは、バージョン管理されていないテーブルと同様に、現在のバージョンを常に効率よく確認できます。
分析コードフレームワーク のテーブル は (分析コード、構造、ルール、制約など)、いすれもバージョン管理情報を内部に保持していません。 古いバージョンは新たなバージョンに置き換えられ、履歴は保持されていません。
構造またはルールが変更された場合、勘定科目の組み合わせが未転記トランザクションに対して保存されていると、分析コードフレームワークが新しい組み合わせが作成し、未転記のトランザクションテーブルの外部キー参照がすべて更新されます。 転記されたトランザクションから参照されている場合があるため、元の組み合わせは変更されません。 この2つの組み合わせは、連係されることがありません。 変更前の構造とルールがどのようなものであったかを判別する方法はありません。 一部の情報は、格納されている組み合わせによって判別できる場合もあります。 ただし、空白の値は保存されておらず、不完全なデータとみなされるため、古いバージョンの再構築に使用することはできません。
分析コードフレームワークでは、分析コード値レベルでの "有効な開始日付" と "有効な終了日付" の両方に対応しています。 これらの日付は、値が "有効" と見なされた時点を示しています。これらは有効日付データとは異なり、値の過去の状態を意味するものではありません。