顧客の生涯価値 (CLV) を予測する
個々のアクティブな顧客が定義済みの将来の期間を通じてビジネスにもたらす潜在的な価値 (収益) を予測します。 この予測は、次のことに役立ちます:
- 価値の高い顧客を特定し、この分析情報を処理します。
- 潜在的な価値に基づいて戦略的な顧客セグメントを作成し、ターゲットを絞った営業、マーケティング、およびサポートの取り組みでパーソナライズされたキャンペーンを実施します。
- 顧客価値を高める機能に焦点を当てて製品開発をガイドします。
- 営業またはマーケティング戦略を最適化し、顧客アウトリーチのためにより正確に予算を割り当てます。
- ロイヤルティ プログラムまたはリワード プログラムを通じて、価値の高い顧客を特定して報酬を提供します。
CLV がビジネスにとって何を意味するかを判断します。 トランザクション ベースの CLV 予測をサポートしています。 顧客の予測値は、ビジネス トランザクションの履歴に基づいています。 さまざまな入力設定で複数のモデルを作成し、モデルの結果を比較して、ビジネス ニーズに最適なモデル シナリオを確認することを検討してください。
チップ
サンプル データを使用して CLV 予測を試してください: 顧客の生涯価値 (CLV) 予測サンプル ガイド。
前提条件
- 少なくとも 共同作成者 のアクセス許可
- 目的の予測ウィンドウ内の少なくとも 1,000 の顧客プロファイル
- 顧客識別子、トランザクションを個々の顧客に照合するための一意識別子
- 少なくとも 1 年間の取引履歴、2 年 から 3 年が望ましい。 理想的には顧客 ID ごとに少なくとも 2 件 から 3 件のトランザクション、複数の日付にわたるトランザクションが望ましい。 取引履歴には以下が含まれている必要があります:
- トランザクション ID: 各トランザクションの一意識別子
- トランザクションの日付: 各トランザクションの日付またはタイム スタンプ
- トランザクション金額: 各トランザクションの金銭的価値 (売上や利益率など)
- 返品に割り当てられたラベル: トランザクションが返品であるかどうかを示すブール値 true/false
- 製品 ID: トランザクションに関係する製品の製品 ID
- 顧客活動に関するデータ:
- 主キー: アクティビティの一意識別子
- タイムスタンプ: 主キーで識別されるイベントの日時
- イベント (活動名): 使用するイベントの名前
- 詳細 (金額または値): 顧客活動に関する詳細
- 以下のような追加データ:
- Web 活動: Web サイトの訪問履歴、またはメール履歴
- ロイヤルティ活動: ロイヤルティ リワード ポイントの発生と引き換え履歴
- 顧客サービス ログ: サービス コール、苦情、または返品履歴
- 顧客プロファイル情報
- 必須フィールドの欠損値が 20 % 未満
注意
構成できるトランザクション履歴テーブルは 1 つだけです。 複数の購入またはトランザクション テーブルがある場合は、データ インジェストの前に Power Query で結合します。
顧客の生涯価値の予測を作成する
いつでも 下書きを保存 を選択して、予測をドラフトとして保存します。 ドラフト予測は 自分の予測 タブに表示されます。
分析情報>予測 に移動します。
作成 タブで 顧客生涯価値 タイルの モデルを使用 を選択します。
開始するを選択します。
他のモデルまたはテーブルと区別するための このモデルに名前を付ける と 出力テーブル名。
次へを選択します。
モデルの基本設定を定義する
予測期間を設定して、CLV を予測する期間を定義します。 既定では、単位は月に設定されています。
チップ
設定した期間の CLV を正確に予測するには、同等の期間の履歴データが必要です。 たとえば、今後 12 か月間の CLV を予測する場合は、少なくとも 18 - 24 か月分の履歴データが必要です。
顧客をアクティブと見なすには、少なくとも 1 件のトランザクションが必要である概算時間を設定します。 このモデルは、アクティブな顧客 の CLV のみを予測します。
- モデルで購入間隔を計算する (推奨): モデルはデータを分析し、過去の購入に基づいて期間を決定します。
- 間隔を手動で設定する: アクティブな顧客と定義する期間。
価値の高い顧客 のパーセンタイルを定義します。
- モデル計算 (推奨): モデルは 80/20 ルールを使用します。 過去の期間にビジネスの累積収益の 80% に貢献した顧客の割合は、価値の高い顧客と見なされます。 通常、30〜40% 未満の顧客は 80% の累積収益に貢献しています。 ただし、この数はビジネスや業界によって異なる場合があります。
- 上位アクティブ顧客の割合: 価値の高い顧客の特定のパーセンタイル。 たとえば、25 を入力して、価値の高い顧客を将来の有料顧客の上位 25% として定義します。
ビジネスが別の方法で価値の高い顧客を定義している場合、ぜひお知らせください。
次へ を選択します。
必須データを追加する
顧客トランザクション履歴 の データの追加 を選択します。
トランザクション履歴を含む、セマンティック活動タイプ (SalesOrder または SalesOrderLine) を選択します。 活動が設定されていない場合は、こちら を選択して作成します。
活動 で、活動の作成時に活動属性がセマンティックにマップされた場合は、計算の対象となる特定の属性またはテーブルを選択します。 セマンティック マッピングが行われなかった場合は、編集 を選択して、データをマップします。
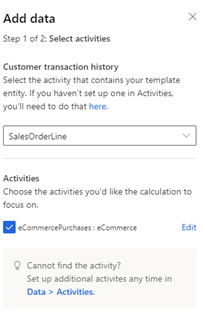
次へ を選択し、このモデルに必要な属性を確認します。
保存 を選択します。
さらに活動を追加するか、次へ を選択します。
オプションの活動データの追加
主要な顧客と対話を反映するデータ (Web、顧客サービス、イベント ログなど) は、トランザクション レコードにコンテキストを追加します。 顧客活動データのパターンが多いほど、予測の精度を向上させることができます。
活動データを追加してモデルによる分析情報の精度を高める で データの追加 選択します。
追加する顧客活動の種類に一致する活動の種類を選択します。 活動が設定されていない場合は、こちら を選択して作成します。
活動 で、活動の作成時に活動属性がマップされた場合は、計算の対象となる特定の属性またはテーブルを選択します。 マッピングが行われなかった場合は、編集 を選択して、データをマップします。
次へ を選択し、このモデルに必要な属性を確認します。
保存 を選択します。
次へ を選択します。
オプションの顧客データを追加 するか、次へ を選択して、スケジュールの更新を設定 に移動します。
オプションの顧客データの追加
モデルへの入力として含める 18 の一般的に使用される顧客プロファイル属性から選択します。 これらの属性は、ビジネス ユース ケースに対して、よりパーソナライズされた、関連性のある実用的なモデル結果につながる可能性があります。
例: Contoso Coffee は、新しいエスプレッソ マシンの発売に関連するパーソナライズされたオファーで、顧客の生涯価値を予測して、価値の高い顧客をターゲットにしたいと考えています。 Contoso は CLV モデルを使用し、18 の顧客プロファイル属性すべてを追加して、最も価値の高い顧客に影響を与える要因を確認します。 同社は、顧客の場所がそれらの顧客にとって最も影響力のある要因であると考えています。 この情報を使用して、エスプレッソ マシンの発売に向けた地元のイベントを開催し、地元のベンダーと提携して、パーソナライズされたオファーやイベントでの特別な体験を提供します。 この情報がなければ、Contoso は一般的なマーケティング メールを送信するだけで、価値の高い顧客のこのローカル セグメント向けにパーソナライズする機会を逃していた可能性があります。
顧客データを追加してモデルによる分析情報の精度をさらに高める で データの追加 を選択します。
テーブル で、顧客 : CustomerInsights を選択して、顧客属性データにマップする統合顧客プロファイルを選択します。 顧客 ID で、System.Customer.CustomerId を選択します。
統合された顧客プロファイルでデータが利用可能な場合は、さらに多くのフィールドをマップします。
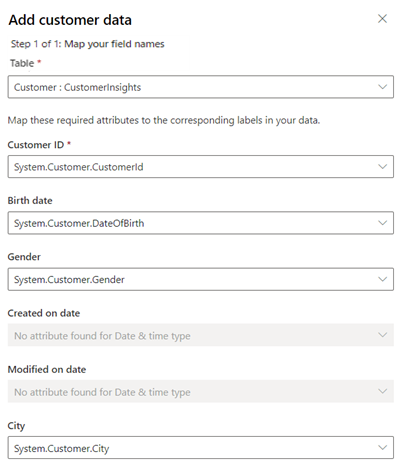
保存 を選択します。
次へ を選択します。
スケジュールの更新を設定する
最新データに基づいてモデルを再トレーニングする頻度を選択します。 この設定は、新しいデータが取り込まれるときに、予測の精度を更新するために重要です。 多くの企業は、月に1度再トレーニングして、予測の精度を高めることができます。
次へ を選択します。
モデル構成を確認して実行します
確認して実行 ステップでは、構成の概要が表示され、予測を作成する前に変更を加えることができます。
確認して変更を加えるには、手順のいずれかで編集 を選択します。
選択内容に問題がなければ、保存して実行 を選択して、モデルの実行を開始します。 完了 を選択します。 自分の予測 タブは、予測の作成中に表示されます。 予測で使用されるデータの量によっては、プロセスの完了までに数時間かかる場合があります。
ヒント
タスクやプロセスの状態 があります。 ほとんどのプロセスは、データ ソースやデータ プロファイル更新 などの他の上流プロセスに依存しています。
状態を選択して プロセス詳細 ペインを開き、タスクの進行状況を表示します。 ジョブをキャンセルするには、ペインの下部のジョブをキャンセルするを選択します
各タスクの下で、処理時間、最終処理日、タスクまたはプロセスに関連する該当エラーや警告など、詳細な進捗情報について 詳細を表示 を選択します。 パネル下部のシステムの状態を見るを選択すると、システム内の他のプロセスを見ることができます。
予測の結果を表示する
分析情報>予測 に移動します。
自分の予測 タブで表示する予測を選択します。
結果ページには、3 つの主要なデータ セクションがあります。
トレーニング モデルのパフォーマンス: グレード A、B、C は、予測のパフォーマンスを示し、出力テーブルに格納された結果を使用するかどうかを決定するのに役立ちます。
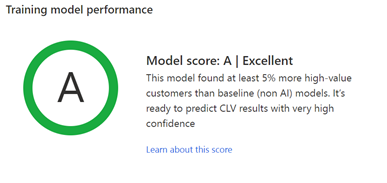
AI モデルがベースライン モデルと比較して、価値の高い顧客を予測する際にどのようなパフォーマンスを達成したかを評価します。
グレードは次のルールに基づいて決定されます。
- モデルが価値の高い顧客を正確に予測した割合が、ベースライン モデルより少なくとも 5% 上回る場合は A。
- モデルが価値の高い顧客を正確に予測した割合が、ベースライン モデルより 0 - 5% 高い場合は B。
- モデルが価値の高い顧客を正確に予測した割合がベースライン モデルより低い場合は C。
このスコアの詳細 を選択して、AI モデルのパフォーマンスとベースライン モデルの詳細を表示する モデル評価 ペインを開きます。 基礎となるモデルのパフォーマンス メトリックと、最終的なモデルのパフォーマンス グレードがどのように導き出されたかをよりよく理解するのに役立ちます。 ベースライン モデルは、非 AI ベースのアプローチを使用して、主に顧客による過去の購入に基づいて顧客生涯価値を計算します。
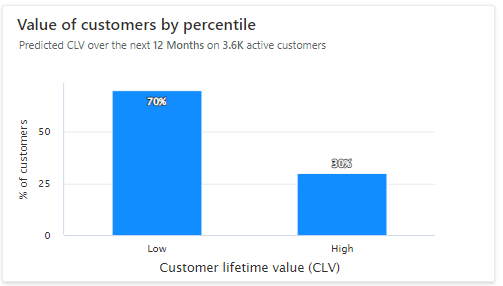
パーセンタイルごとの顧客の値: 価値の低い顧客と価値の高い顧客がグラフに表示されます。 ヒストグラムのバーにカーソルを合わせると、各グループの顧客数とそのグループの平均 CLV が表示されます。 必要に応じて、CLV 予測に基づいて 顧客のセグメントを作成 します。
最も影響力の大きい係数: AI モデルに提供された入力データに基づいて CLV 予測を作成する際には、さまざまな係数が考慮されます。 各要素の重要度は、モデルが作成する集約された予測に対して計算されます。 これらの係数を使用して、予測結果を検証します。 これらの係数が、すべての顧客の CLV の予測に貢献した最も影響の大きい係数について提供するインサイトも増加します。

スコアについて
ベースライン モデルによる CLV の計算に使用される標準式:
各顧客の CLV = アクティブな顧客ウィンドウで顧客が行った平均月間購入 * CLV 予測期間の月数 * すべての顧客の全体的な保持率
AI モデルは、2 つのモデルパフォーマンス メトリックに基づいてベースライン モデルと比較されます。
価値の高い顧客の予測を行う際の成功率
AI モデルを使用して、ベースライン モデルと比較したときの、価値の高い顧客を予測する際の違いを確認してください。 たとえば、成功率 84% は、トレーニング データ内のすべての価値の高い顧客のうち、AI モデルが 84% を正確にキャプチャできたことを意味します。 次に、この成功率をベースライン モデルの成功率と比較して、相対的な変化を報告します。 この値は、モデルにグレードを割り当てるために使用されます。
エラー指標
将来の値を予測する際のエラーの観点からモデルの全体的なパフォーマンスを確認できます。 このエラーを評価するために、全体的な二乗平均平方根誤差 (RMSE) メトリックを使用します。 RMSE は、定量的データを予測する際のモデルの誤差を測定するための標準的な方法です。 AI モデルの RMSE がベースライン モデルの RMSE と比較され、相対的な差異が報告されます。
AI モデルは、顧客がビジネスにもたらす価値に応じて、顧客の正確なランキングを優先します。 したがって、価値の高い顧客を予測する成功率のみを使用して、最終的なモデルのグレードを導き出します。 RMSE メトリックは、外れ値に敏感です。 購入額が非常に高い顧客の割合が少ないシナリオでは、全体的な RMSE メトリックがモデルのパフォーマンスの全体像を示していない可能性があります。