データ統合のベスト プラクティス
データを顧客プロファイルに統合するルールを設定する際は、以下のベスト プラクティスを考慮してください:
統一にかかる時間と完全なマッチングのバランス。 考えられるすべての一致をキャプチャしようとすると、多くのルールと統一に時間がかかります。
ルールを段階的に追加し、結果を追跡します。 一致結果を改善しないルールを削除します。
各テーブルを重複排除 して、すべての顧客が 1 行に表示されるようにします。
正規化を使用して、データの入力方法のばらつきを標準化します (例: Street vs. St. vs. St.)。
ファジー マッチング戦略を使って、タイプミスやエラーを修正します (例: bob@contoso.com や bob@contoso.cm)。ファジーマッチは完全一致よりも実行に時間がかかります。 あいまい一致に費やす余分な時間が、追加の一致率に見合う価値があるかどうかを常にテストしてください。
完全一致 で一致の範囲を絞り込みます。 あいまい条件を含むすべてのルールに、少なくとも 1 つの完全一致条件があることを確認してください。
頻繁に繰り返されるデータを含む列とは照合しないでください。 あいまい一致列には、フォームの既定値である "Firstname" など、値が頻繁に繰り返されないようにします。
統一パフォーマンス
各ルールの実行には時間がかかります。 すべてのテーブルを他のすべてのテーブルと比較したり、一致する可能性のあるすべてのレコードをキャプチャしたりするなどのパターンでは、統合処理時間が長くなる可能性があります。 また、各テーブルを基本テーブルと比較するプランよりも、一致するものがあったとしてもほとんど返されません。
最善の方法は、各テーブルをプライマリ テーブルと比較するなど、必要であることがわかっている基本的なルール セットから始めることです。 プライマリ テーブルは、最も完全で正確なデータを持つテーブルである必要があります。 このテーブルは、照合ルールの統合ステップの一番上に配置する必要があります。
いくつかのルールを段階的に追加し、変更の実行にかかる時間と、結果が改善されるかどうかを確認します。 設定>システム>ステータス に移動し、照合 を選択して、各統合の実行にかかった重複排除と照合にかかった時間を確認します。
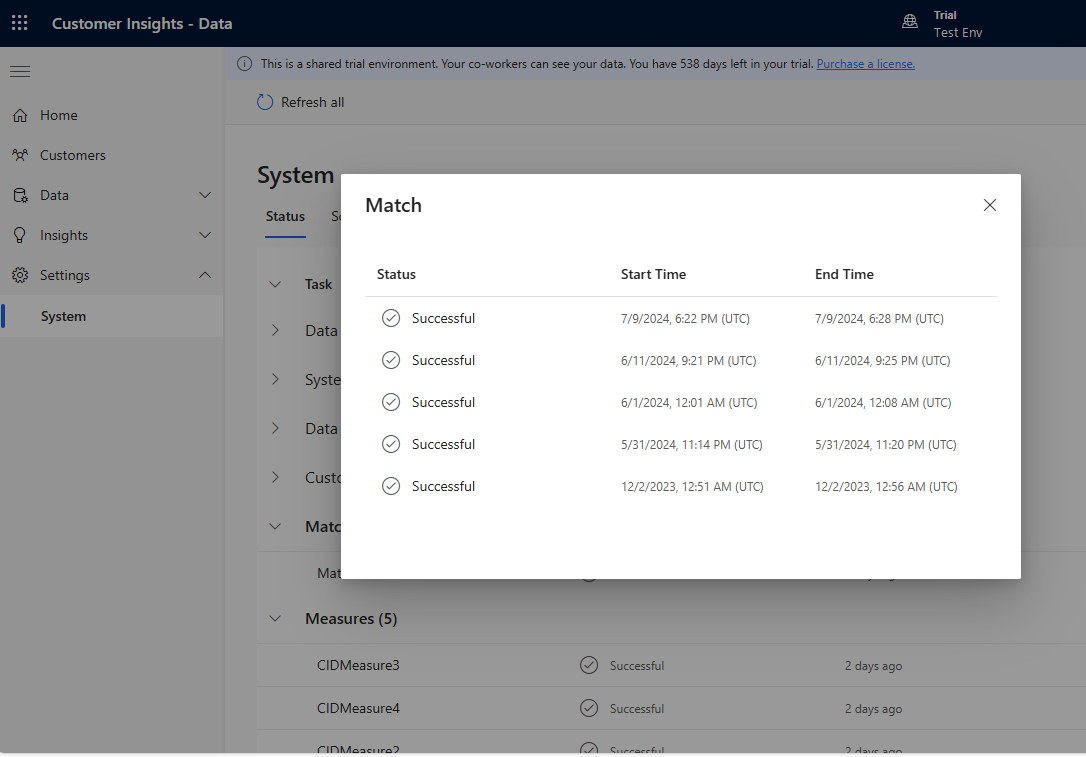
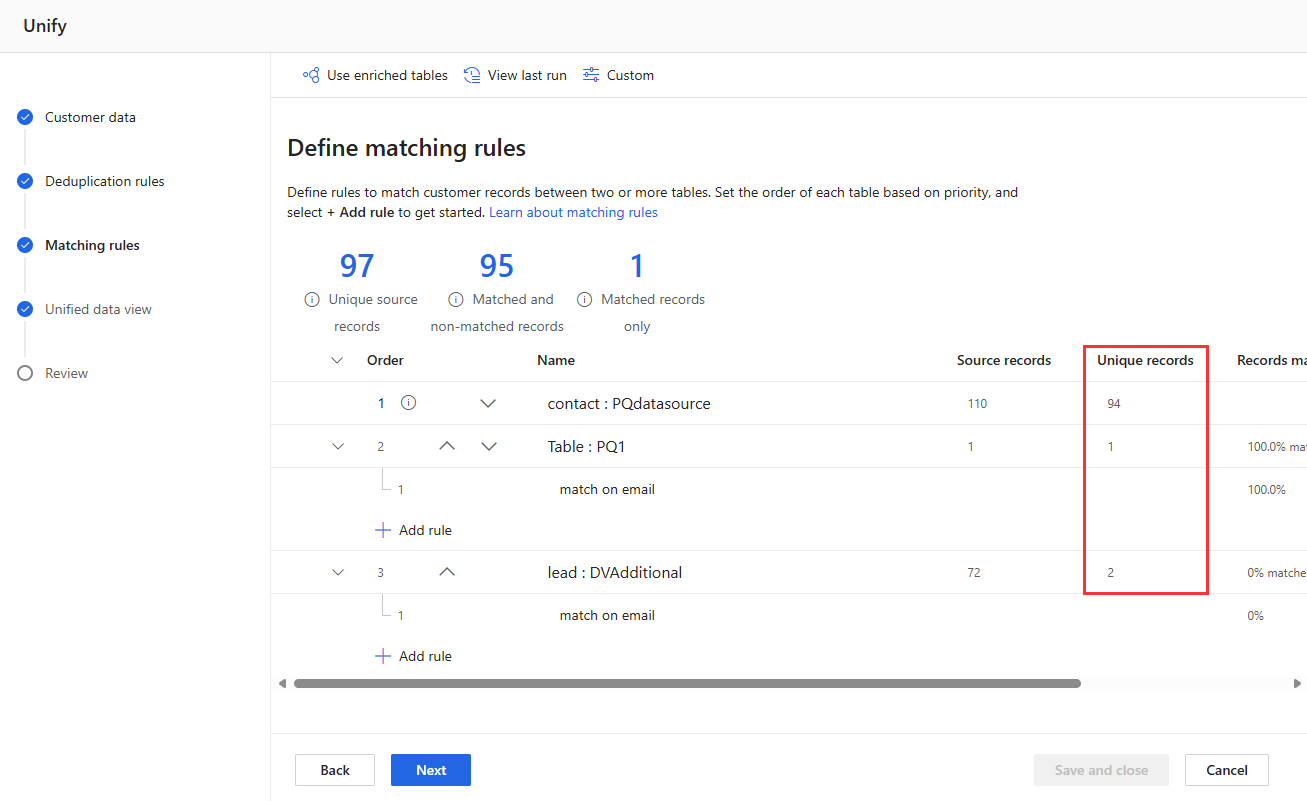
重複排除ルール および 照合ルール ページのルール統計を表示して、一意のレコード の数が変更されたかどうかを確認します。 新しいルールが一部のレコードと一致し、一意のレコード数が変更されない場合、前のルールによってそれらの一致が識別されます。
顧客データ
顧客のデータ ステップで:
一致ルールに必要のない列や、最終顧客プロファイルに含めたくない列を除外します。
インテリジェント マッピングによって選択された列の説明を確認します。
すべての列をマッピングする必要はありません。 メールや住所のような一般的な列をマッピングすることで、Customer Insights はダウンストリームの工程を容易にすることができますが、固有の ID を持つ列やビジネス上の目的を持つ列はマッピングされないままにしておくことができます。
重複排除済み
重複排除ルールを使用して、テーブル内の重複する顧客レコードを削除し、各テーブルの 1 つの行が各顧客を表すようにします。 適切なルールは、固有の顧客を識別します。
この単純な例では、レコード 1、2、3 はメールまたは電話番号を共有し、同一人物を表します。
| ID | 件名 | 電話番号 | メール |
|---|---|---|---|
| 6 | ペルソナ 1 | (425) 555-1111 | AAA@A.com |
| 2 | ペルソナ 1 | (425) 555-1111 | BBB@B.com |
| 3 | ペルソナ 1 | (425) 555-2222 | BBB@B.com |
| 4 | ペルソナ 2 | (206) 555-9999 | Person2@contoso.com |
名前だけで一致させるのは、同じ名前の別の人が一致することになるため、望ましくありません。
レコード 1 と 2 に一致する名前と電話番号を使用してルール 1 を作成します。
レコード 2 と 3 に一致する名前とメールアドレスを使用してルール 2 を作成します。
ルール 1 とルール 2 はレコード 2 を共有するため、これらを組み合わせると単一の一致グループが作成されます。
顧客を一意に識別するルールと条件の数を決定します。 正確なルールは、照合に使用できるデータ、データの品質、重複排除プロセスの網羅性によって異なります。
正規化
正規化を使用してデータを標準化し、照合を改善します。 正規化は、大規模なデータ セットで適切に機能します。
正規化したデータは、顧客レコードをより効果的に照合するための比較目的にのみ使用されます。 最終的な統合顧客プロファイル出力のデータは変更されません。
完全一致
精度を使用して、2 つの文字列が一致と見なされるためにどの程度近づく必要があるかを決定します。 既定の精度設定では、完全一致が必要です。 その他の値を指定すると、その条件のあいまい一致が有効になります。
精度は、低 (30% 一致)、中 (60% 一致)、および高 (80% 一致) に設定できます。 または、カスタマイズして精度を 1% 単位で設定することもできます。
完全一致条件
あいまい一致の値のより小さなセットを取得するために、完全一致条件が最初に実行されます。 効果的に行うために、完全一致の条件には適度な一意性が必要です。 たとえば、すべての顧客が同じ国/地域に住んでいる場合、国/地域が完全に一致していても、範囲を絞り込むことはできません。
氏名、電子メール、電話番号、住所フィールドなどの列は一意性が高く、完全一致として使用するのに最適な列です。
完全一致条件に使用する列に、フォームによってキャプチャされた既定値の "Firstname" など、頻繁に繰り返される値がないことを確認します。 Customer Insights では、データ列をプロファイルして、上位の繰り返し値に関する分析情報を提供できます。 Azure Data Lake (Common Data Model または Delta 形式を使用) 接続と Synapse でデータ プロファイルを有効にすることができます。 データ プロファイルは、データ ソースが次に更新されるときに実行されます。 詳細については、データ プロファイル を参照してください。
あいまい一致
あいまい一致を使用して、類似しているがタイプミスやその他の小さなバリエーションのために正確ではない文字列を照合します。 あいまい一致は完全一致よりも低速であるため、戦略的に使用してください。 あいまいな条件を持つルールには、少なくとも 1 つの完全一致条件があることを確認してください。
あいまい一致は、Suzzie や Suzanne などの名前のバリエーションをキャプチャするためのものではありません。 これらのバリエーションは、正規化パターン タイプ: 名前 またはカスタム エイリアスの一致 で、顧客が一致と見なす名前バリエーションのリストを入力できる場合に、より適切にキャプチャされます。
FirstName と Phone の一致などの条件をルールに追加できます。 特定のルール内の条件は "AND" 条件です。 行が一致するには、すべての条件が一致する必要があります。 個別のルールは "OR" 条件です。 ルール 1 が行と一致しない場合、行はルール 2 と比較されます。
ヒント
あいまい一致を使用できるのは文字列データ型の列のみです。 integer、double、datetime など、他のデータ型の列の場合、精度フィールドは読み取り専用になり、完全一致に設定されます。
あいまい一致計算
あいまい一致は、2 つの文字列間の編集距離スコアを計算することによって決定されます。 スコアが精度のしきい値を満たすか超えると、文字列は一致と見なされます。
編集距離は、文字を追加、削除、または変更することで、ある文字列を別の文字列に変換するために必要な編集回数です。
たとえば、文字列 "robert2020@hotmail.com" と "robrt2020@hotmail.cm" では、e と o の文字を削除すると編集距離は 2 になります。 編集距離スコアを計算するには、(基本文字列の長さ – 編集距離) / 基準文字列の長さの式を使用します。
| ベース文字列 | 比較文字列 | スコア |
|---|---|---|
| robert2020@hotmail.com | robrt2020@hotmail.cm | (20 - 2)/20 = 0.9 |