チュートリアル: 時系列解析と ML.NET を使用して自転車レンタル サービスの需要を予測する
ML.NET を使用して SQL Server データベースに格納されているデータに対して、一変量時系列解析を使用して自転車レンタル サービスの需要を予測する方法について説明します。
このチュートリアルでは、次の作業を行う方法について説明します。
- 問題を把握する
- データベースからデータを読み込む
- 予測モデルを作成する
- 予測モデルを評価する
- 予測モデルを保存する
- 予測モデルを使用する
必須コンポーネント
- .NET デスクトップ開発ワークロードがインストールされた Visual Studio 2022。
時系列予測のサンプルの概要
このサンプルは、特異スペクトル解析 (Singular Spectrum Analysis) と呼ばれる一変量時系列解析アルゴリズムを使用して、自転車のレンタルの需要を予測する、C# .NET Core コンソール アプリケーションです。 このサンプルのコードについては、GitHub の dotnet/machinelearning-samples リポジトリで見つけることができます。
問題を把握する
効率的に事業を運営するには、在庫管理が重要な役割を果たします。 製品の在庫が多すぎるということは、製品が棚に置かれたままで販売されず、何の収益も生み出さないことを意味します。 製品が少なすぎると、販売機会の損失や顧客が競合他社から購入することにつながります。 そのため、在庫を維持するための最適な量はどのくらいかということを常に問いかけます。 時系列解析では、履歴データ、パターンの識別、およびこの情報を使用して、将来の値を予測することで、この質問に対する回答を得ることができます。
このチュートリアルで使用されているデータを解析するための手法は、一変量時系列解析です。 一変量時系列解析では、月単位の売上など、特定の間隔で一定の期間にわたって 1 つの数値の観測を調べます。
このチュートリアルで使用されているアルゴリズムは、特異スペクトル解析 (SSA: Singular Spectrum Analysis) です。 SSA は、時系列を一連のプリンシパル コンポーネントに分解することによって機能します。 これらのコンポーネントは、傾向、ノイズ、季節性、およびその他の多くの要因に対応するシグナルの部分として解釈することができます。 その後、これらのコンポーネントは再構築され、将来の値の予測に使用されます。
コンソール アプリケーションを作成する
"BikeDemandForecasting" という名前の C# コンソール アプリケーションを作成します。 [次へ] をクリックします。
使用するフレームワークとして [.NET 6] を選択します。 [作成] ボタンをクリックします。
Microsoft.ML バージョン NuGet パッケージをインストールします。
注意
このサンプルでは、特に明記されていない限り、記載されている最新の安定バージョンの NuGet パッケージを使用します。
- ソリューション エクスプローラーで、プロジェクトを右クリックし、 [NuGet パッケージの管理] を選択します。
- [パッケージ ソース] として "nuget.org" を選択し、 [参照] タブを選択し、"Microsoft.ML" を検索します。
- [プレリリースを含める] チェックボックスをオンにします。
- [インストール] ボタンを選択します。
- [変更のプレビュー] ダイアログで [OK] を選択します。表示されているパッケージのライセンス条項に同意する場合は、[ライセンスの同意] ダイアログの [同意する] を選択します。
- System.Data.SqlClient と Microsoft.ML.TimeSeries に対して、この手順を繰り返します。
データを準備して理解する
- Data というディレクトリを作成します。
- DailyDemand.mdf データベース ファイルをダウンロードし、Data ディレクトリに保存します。
注意
このチュートリアルで使用されているデータは、UCI Bike Sharing Dataset から取得したものです。 Fanaee-T, Hadi, and Gama, Joao, 'Event labeling combining ensemble detectors and background knowledge', Progress in Artificial Intelligence (2013): pp. 1-15, Springer Berlin Heidelberg, Web リンク。
元のデータセットには、季節性と天気に対応する複数の列が含まれています。 簡潔にするため、またこのチュートリアルで使用されているアルゴリズムには 1 つの数値列の値しか必要ないため、元のデータセットは次の列のみが含まれるように圧縮されています。
- dteday:観察の日付。
- year:観察のエンコードされた年 (0 = 2011、1 = 2012)。
- cnt:その日にレンタルされた自転車の合計数。
元のデータセットは、SQL Server データベースの次のスキーマを持つデータベース テーブルにマップされます。
CREATE TABLE [Rentals] (
[RentalDate] DATE NOT NULL,
[Year] INT NOT NULL,
[TotalRentals] INT NOT NULL
);
データのサンプルを次に示します。
| RentalDate | Year | TotalRentals |
|---|---|---|
| 1/1/2011 | 0 | 985 |
| 1/2/2011 | 0 | 801 |
| 1/3/2011 | 0 | 1349 |
入力クラスと出力クラスを作成する
Program.cs ファイルを開き、既存の
usingステートメントを次のステートメントに置き換えます。using Microsoft.ML; using Microsoft.ML.Data; using Microsoft.ML.Transforms.TimeSeries; using System.Data.SqlClient;ModelInputクラスを作成します。Programクラスの下に、次のコードを追加します。public class ModelInput { public DateTime RentalDate { get; set; } public float Year { get; set; } public float TotalRentals { get; set; } }ModelInputクラスには、次の列が含まれています。- RentalDate:観察の日付。
- Year:観察のエンコードされた年 (0 = 2011、1 = 2012)。
- TotalRentals:その日にレンタルされた自転車の合計数。
新しく作成された
ModelInputクラスの下にModelOutputクラスを作成します。public class ModelOutput { public float[] ForecastedRentals { get; set; } public float[] LowerBoundRentals { get; set; } public float[] UpperBoundRentals { get; set; } }ModelOutputクラスには、次の列が含まれています。- ForecastedRentals:予測期間の予測値。
- LowerBoundRentals:予測期間の予測される最小値。
- UpperBoundRentals:予測期間の予測される最大値。
パスを定義し、変数を初期化する
using ステートメントの下で、データの場所、接続文字列、およびトレーニング済みのモデルを保存する場所を格納する変数を定義します。
string rootDir = Path.GetFullPath(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "../../../")); string dbFilePath = Path.Combine(rootDir, "Data", "DailyDemand.mdf"); string modelPath = Path.Combine(rootDir, "MLModel.zip"); var connectionString = $"Data Source=(LocalDB)\\MSSQLLocalDB;AttachDbFilename={dbFilePath};Integrated Security=True;Connect Timeout=30;";パスを定義した後に次の行を追加して、
MLContextの新しいインスタンスでmlContext変数を初期化します。MLContext mlContext = new MLContext();MLContextクラスは、すべての ML.NET 操作の開始点で、mlContext を初期化することで、モデル作成ワークフローのオブジェクト間で共有できる新しい ML.NET 環境が作成されます。 これは Entity Framework におけるDBContextと概念的には同じです。
データを読み込む
ModelInput型のレコードを読み込むDatabaseLoaderを作成します。DatabaseLoader loader = mlContext.Data.CreateDatabaseLoader<ModelInput>();データベースからデータを読み込むクエリを定義します。
string query = "SELECT RentalDate, CAST(Year as REAL) as Year, CAST(TotalRentals as REAL) as TotalRentals FROM Rentals";ML.NET アルゴリズムでは、データが
Single型であることが想定されています。 このため、データベースから取得された、Real型の単精度浮動小数点値ではない数値はRealに変換される必要があります。Year列とTotalRental列はどちらもデータベース内では整数型です。CAST組み込み関数を使用すると、どちらもRealにキャストされます。データベースに接続してクエリを実行する
DatabaseSourceを作成します。DatabaseSource dbSource = new DatabaseSource(SqlClientFactory.Instance, connectionString, query);IDataViewにデータを読み込みます。IDataView dataView = loader.Load(dbSource);このデータセットには 2 年分のデータが含まれています。 トレーニングに使用されるのは 1 年目のデータのみで、2 年目のデータは、モデルによって生成された予測と実際の値を比較するために保持されます。
FilterRowsByColumn変換を使用してデータをフィルター処理します。IDataView firstYearData = mlContext.Data.FilterRowsByColumn(dataView, "Year", upperBound: 1); IDataView secondYearData = mlContext.Data.FilterRowsByColumn(dataView, "Year", lowerBound: 1);1 年目に対しては、
upperBoundパラメーターを 1 に設定することによって、Year列の 1 未満の値のみが選択されます。 反対に、2 年目に対しては、lowerBoundパラメーターを 1 に設定することによって、1 以上の値が選択されます。
時系列解析パイプラインを定義する
SsaForecastingEstimator を使用して時系列データセット内の値を予測するパイプラインを定義します。
var forecastingPipeline = mlContext.Forecasting.ForecastBySsa( outputColumnName: "ForecastedRentals", inputColumnName: "TotalRentals", windowSize: 7, seriesLength: 30, trainSize: 365, horizon: 7, confidenceLevel: 0.95f, confidenceLowerBoundColumn: "LowerBoundRentals", confidenceUpperBoundColumn: "UpperBoundRentals");forecastingPipelineでは、1 年目用の 365 のデータ ポイントとサンプルを取得するか、seriesLengthパラメーターで指定された 30 日 (月単位) 間隔に時系列データセットを分割します。 これらの各サンプルは、毎週または 7 日間の期間で解析されます。 次の期間の予測値がどのようになるかを判断する際には、前の 7 日間の値を使用して予測が行われます。 モデルは、horizonパラメーターで定義されているように、7 つの期間を将来まで予測するように設定されています。 予測は情報に基づいた推測であるため、100% 正確であるとは限りません。 したがって、上限と下限によって定義される最善のシナリオと最悪のシナリオにおける値の範囲を把握しておくことをお勧めします。 この場合、下限と上限の信頼レベルは 95% に設定されています。 信頼レベルは、状況に応じて増減できます。 値が大きいほど、望ましい信頼レベルを達成するために上限と下限の範囲が広くなります。Fitメソッドを使用して、モデルをトレーニングし、以前に定義したforecastingPipelineにデータを適合させます。SsaForecastingTransformer forecaster = forecastingPipeline.Fit(firstYearData);
モデルを評価する
来年のデータを予測し、それを実際の値と比較することによって、モデルのパフォーマンスを評価します。
Program.cs ファイルの下部に
Evaluateという新しいユーティリティ メソッドを作成します。Evaluate(IDataView testData, ITransformer model, MLContext mlContext) { }Evaluateメソッド内で、トレーニング済みのモデルでTransformメソッドを使用して、2 年目のデータを予測します。IDataView predictions = model.Transform(testData);CreateEnumerableメソッドを使用して、データから実際の値を取得します。IEnumerable<float> actual = mlContext.Data.CreateEnumerable<ModelInput>(testData, true) .Select(observed => observed.TotalRentals);CreateEnumerableメソッドを使用して、予測値を取得します。IEnumerable<float> forecast = mlContext.Data.CreateEnumerable<ModelOutput>(predictions, true) .Select(prediction => prediction.ForecastedRentals[0]);実際の値と予測値の差を計算します (一般的にエラーと呼ばれます)。
var metrics = actual.Zip(forecast, (actualValue, forecastValue) => actualValue - forecastValue);平均絶対誤差値と二乗平均平方根誤差値を計算して、パフォーマンスを測定します。
var MAE = metrics.Average(error => Math.Abs(error)); // Mean Absolute Error var RMSE = Math.Sqrt(metrics.Average(error => Math.Pow(error, 2))); // Root Mean Squared Errorパフォーマンスを評価するため、次のメトリックが使用されます。
- 平均絶対誤差:予測が実際の値にどれだけ近いかを測定します。 この値の範囲は 0 から無限大です。 0 に近いほど、モデルの品質が高くなります。
- 二乗平均平方根誤差:モデル内のエラーを集約します。 この値の範囲は 0 から無限大です。 0 に近いほど、モデルの品質が高くなります。
メトリックをコンソールに出力します。
Console.WriteLine("Evaluation Metrics"); Console.WriteLine("---------------------"); Console.WriteLine($"Mean Absolute Error: {MAE:F3}"); Console.WriteLine($"Root Mean Squared Error: {RMSE:F3}\n");Fit()メソッドの呼び出しの下で、Evaluateメソッドを呼び出します。Evaluate(secondYearData, forecaster, mlContext);
モデルを保存する
モデルに問題がなければ、後で他のアプリケーションで使用できるように保存します。
Evaluate()メソッドの下に、TimeSeriesPredictionEngineを作成します。TimeSeriesPredictionEngineは、単一の予測を行うための便利な方法です。var forecastEngine = forecaster.CreateTimeSeriesEngine<ModelInput, ModelOutput>(mlContext);以前に定義した
modelPath変数によって指定されたMLModel.zipという名前のファイルにモデルを保存します。Checkpointメソッドを使用してモデルを保存します。forecastEngine.CheckPoint(mlContext, modelPath);
モデルを使用して需要を予測する
Evaluateメソッドの下に、Forecastという新しいユーティリティ メソッドを作成します。void Forecast(IDataView testData, int horizon, TimeSeriesPredictionEngine<ModelInput, ModelOutput> forecaster, MLContext mlContext) { }Forecastメソッド内で、Predictメソッドを使用して、次の 7 日間のレンタルを予測します。ModelOutput forecast = forecaster.Predict();7 つの期間の実際の値と予測値を合わせます。
IEnumerable<string> forecastOutput = mlContext.Data.CreateEnumerable<ModelInput>(testData, reuseRowObject: false) .Take(horizon) .Select((ModelInput rental, int index) => { string rentalDate = rental.RentalDate.ToShortDateString(); float actualRentals = rental.TotalRentals; float lowerEstimate = Math.Max(0, forecast.LowerBoundRentals[index]); float estimate = forecast.ForecastedRentals[index]; float upperEstimate = forecast.UpperBoundRentals[index]; return $"Date: {rentalDate}\n" + $"Actual Rentals: {actualRentals}\n" + $"Lower Estimate: {lowerEstimate}\n" + $"Forecast: {estimate}\n" + $"Upper Estimate: {upperEstimate}\n"; });予測出力を反復処理し、コンソールに表示します。
Console.WriteLine("Rental Forecast"); Console.WriteLine("---------------------"); foreach (var prediction in forecastOutput) { Console.WriteLine(prediction); }
アプリケーションの実行
Checkpoint()メソッド呼び出しの下で、Forecastメソッドを呼び出します。Forecast(secondYearData, 7, forecastEngine, mlContext);アプリケーションを実行します。 次のような出力がコンソールに表示されます。 簡潔にするため、出力は要約されています。
Evaluation Metrics --------------------- Mean Absolute Error: 726.416 Root Mean Squared Error: 987.658 Rental Forecast --------------------- Date: 1/1/2012 Actual Rentals: 2294 Lower Estimate: 1197.842 Forecast: 2334.443 Upper Estimate: 3471.044 Date: 1/2/2012 Actual Rentals: 1951 Lower Estimate: 1148.412 Forecast: 2360.861 Upper Estimate: 3573.309
実際の値と予測値を検査すると、次のリレーションシップが表示されます。
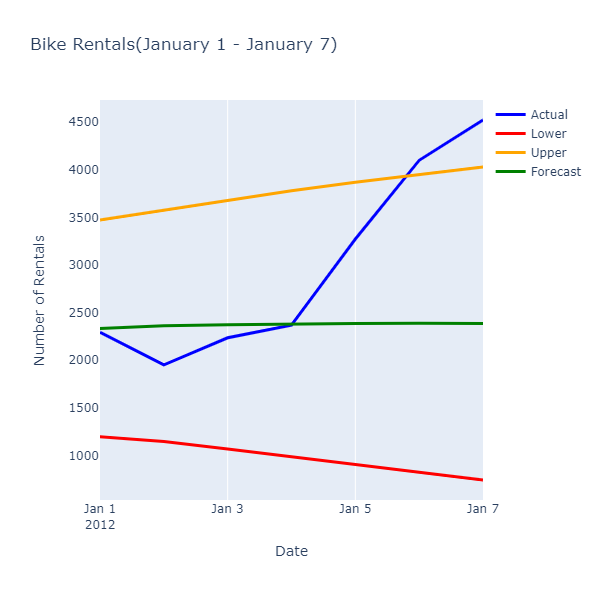
予測値は、レンタルの正確な数を予測するものではありませんが、より絞り込んだ値の範囲が提供されるため、リソースの使用を最適化した事業が可能になります。
おめでとうございます! これで、自転車のレンタル需要を予測するための時系列の機械学習モデルが正常に作成されました。
このチュートリアルのソース コードは、dotnet/machinelearning-samples リポジトリにあります。
次の手順
.NET