ヒント
このコンテンツは eBook の「コンテナー化された .NET アプリケーションの .NET マイクロサービス アーキテクチャ」からの抜粋です。.NET Docs で閲覧できるほか、PDF として無料ダウンロードすると、オンラインで閲覧できます。

課題 #1: 各マイクロサービスの境界を定義する方法
マイクロサービスの境界の定義は、おそらく、すべてのユーザーが直面する最初の課題です。 各マイクロサービスはアプリケーションの一部である必要があり、各マイクロサービスはアプリケーションのすべての利点と課題に関して自律的である必要があります。 しかし、これらの境界をどのようにして識別すればよいのでしょうか。
最初に、アプリケーションの論理ドメイン モデルと関連するデータに注目する必要があります。 同じアプリケーション内で、切り離されて孤立したデータと異なるコンテキストの識別を試みてください。 各コンテキストは、異なるビジネス言語 (異なるビジネス用語) を使っている可能性があります。 コンテキストを独立して定義し、管理する必要があります。 異なるコンテキストで使われている用語やエンティティが同じように聞こえることがあるかもしれませんが、特定のコンテキストでは、同じビジネス概念でもコンテキストによって使用目的が異なることがあり、名前が異なる場合さえあります。 たとえば、ユーザーは、ID またはメンバーシップのコンテキストではユーザー、CRM のコンテキストではお客様、注文のコンテキストでは購入者、などと呼ばれます。
それぞれドメインが異なる複数のアプリケーション コンテキスト間の境界を識別する方法は、まさに、各ビジネス マイクロサービスおよびその関連するドメイン モデルとデータの境界を識別できる方法です。 常に、それらのマイクロサービス間の結び付きを最小限にすることを試みます。 この識別とドメイン モデルの設計については、「マイクロサービスごとにドメイン モデルの境界を識別する」を参照してください。
課題 #2: 複数のマイクロサービスからデータを取得するクエリを作成する方法
2 番目の課題は、リモート クライアント アプリからマイクロサービスへの通信が多くなりすぎるのを防ぎながら、複数のマイクロサービスからデータを取得するクエリを実装する方法です。 たとえば、バスケット、カタログ、ユーザー ID の各マイクロサービスによって所有されているユーザー情報を表示する必要がある、モバイル アプリの 1 つの画面のような場合です。 または、複数のマイクロサービスに存在する多数のテーブルが関係する複雑なレポートもそのような例です。 適切な解決策はクエリの複雑さによって異なります。 ただし、どのような場合でも、システムの通信効率を向上させるには、情報を集計する方法が必要になります。 最も一般的な解決策を以下に示します。
API ゲートウェイ。 異なるデータベースを所有する複数のマイクロサービスから単純にデータを集計する場合の推奨される方法は、API ゲートウェイと呼ばれる集計マイクロサービスです。 ただし、このパターンは、システムのボトルネックになったり、マイクロサービスの自律性の原則に違反する可能性があるため、実装するときに注意する必要があります。 このような可能性を減らすには、システムの垂直方向の "スライス" またはビジネス領域に焦点を当てて細かく調整された複数の API ゲートウェイを使います。 API ゲートウェイ パターンに関する説明は、後述の「API ゲートウェイ」セクションにあります。
GraphQL フェデレーション マイクロサービスで既に GraphQL を使っている場合に検討すべき 1 つのオプションは、GraphQL フェデレーションです。 フェデレーションを使うと、他のサービスから "サブグラフ" を定義し、それらをスタンドアロン スキーマとして機能する集計 "スーパーグラフ" に組み込むことができます。
クエリ/読み取りテーブルを使う CQRS。 複数のマイクロサービスからデータを集計するもう 1 つの解決策は、具体化されたビュー パターンです。 この方法では、複数のマイクロサービスによって所有されているデータを含む読み取り専用テーブルを、事前に (実際のクエリが行われる前に非正規化データを準備します) 生成します。 このテーブルはクライアント アプリのニーズに合った形式にします。
モバイル アプリの画面のようなものを検討します。 データベースが 1 つだけの場合は、複数のテーブルを含む複雑な結合を実行する SQL クエリを使って、その画面のデータをまとめて取得することもできます。 しかし、複数のデータベースがあり、各データベースが異なるマイクロサービスによって所有されている場合は、それらのデータベースに対するクエリを実行して、SQL 結合を作成することはできません。 複雑なクエリは困難になります。 CQRS アプローチを使って、要件に対処することができます。クエリのためだけに使う異なるデータベースに、非正規化されたテーブルを作成します。 テーブルは複雑なクエリに必要なデータ専用に設計でき、アプリケーションの画面で必要なフィールドとクエリ テーブルの列の間が、一対一のリレーションシップになるようにします。 レポート用に使うこともできます。
このアプローチは、元の問題 (複数のマイクロサービス間でクエリと結合を行う方法) を解決するだけでなく、アプリケーションに必要なデータがクエリ テーブルに既にあるため、複雑な結合と比較してパフォーマンスも大幅に向上します。 もちろん、クエリ/読み取りテーブルによる CQRS (Command and Query Responsibility Segregation: コマンド クエリ責務分離) を使うと、開発作業が増えるので、最終的な整合性を採用する必要があります。 それでも、コラボレーション シナリオ (または観点によっては競合シナリオ) でパフォーマンスと高スケーラビリティが必要な場合は、複数データベースでの CQRS を適用する必要があります。
中央データベースの "コールド データ"。 リアルタイムのデータを必要としない複雑なレポートとクエリの場合の一般的な方法は、"ホット データ" (マイクロサービスからのトランザクション データ) を、レポート専用の大きなデータベースに "コールド データ" としてエクスポートすることです。 中央データベース システムとしては、Hadoop のようなビッグ データ ベースのシステムや Azure SQL Data Warehouse に基づくもののようなデータ ウェアハウスを使うことができ、(サイズが問題にならない場合は) レポートだけに使う単一の SQL データベースでもかまいません。
この集中データベースはリアルタイム データを必要としないクエリおよびレポートのみに使うことに注意してください。 真実を語る資料としての元の更新およびトランザクションは、マイクロサービス データ内に存在している必要があります。 データ同期の方法としては、イベント ドリブンの通信 (次のセクションで説明します)、またはデータベース インフラストラクチャの他のインポート/エクスポート ツールを使います。 イベント ドリブンの通信を使う場合、その統合プロセスは、前に説明した CQRS クエリ テーブルでのデータ伝達方法と似たものになります。
ただし、複雑なクエリのために複数のマイクロサービスから頻繁に情報を集計するようなアプリケーションの設計は、悪い設計の兆候である可能性があります。マイクロサービスは、可能な限り他のマイクロサービスから分離する必要があります。 (ここでは、コールドデータ中央データベースを常に使用しなければならないレポートと分析は除外されます) この問題はしばしば、マイクロサービスをマージする理由となることがあります。 各マイクロサービスの発展とデプロイの自律性と、強い依存性、凝集度、データ集計の間のバランスをとる必要があります。
課題 #3: 複数のマイクロサービスとの間で整合性を実現する方法
前に説明したように、各マイクロサービスが所有するデータはそのマイクロサービスにプライベートなものであり、そのマイクロサービスの API を使うことによってのみアクセスできます。 そのため、複数のマイクロサービスの間で整合性を維持しながら、エンド ツー エンドのビジネス プロセスを実装する方法に関する課題があります。
この問題を分析するため、eShopOnContainers 参照アプリケーションの例を見てみます。 Catalog マイクロサービスは、製品価格など、すべての製品に関する情報を保持しています。 Basket マイクロサービスは、利用者が買い物かごに追加する製品品目に関するテンポラル データを管理します。かごに追加された時点における品目の価格などです。 製品の価格がカタログで更新されると、その価格は、同じ製品が入っている有効な買い物かごでも更新されます。また、おそらくは、買い物かごに追加した後に品目の価格が変更されたことが利用者に通知されます。
このアプリケーションが仮説上、一体構造であれば、価格テーブルの価格が変更されたとき、カタログ サブシステムでは単純に ACID トランザクションを利用し、買い物かごテーブルの現在の価格を更新することがあります。
一方、マイクロサービス ベースのアプリケーションでは、Product テーブルと Basket テーブルは対応するマイクロサービスによって所有されています。 どのマイクロサービスのトランザクションにも (直接のクエリでも)、別のマイクロサービスによって所有されるテーブル/ストレージが含まれることはありません (図 4-9 を参照)。
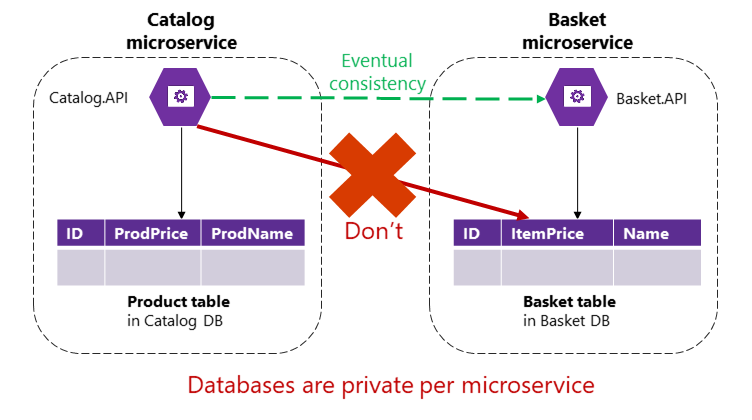
図 4-9 マイクロサービスは、別のマイクロサービスのテーブルに直接アクセスすることはできません。
Basket テーブルは Basket マイクロサービスによって所有されているので、Catalog マイクロサービスが Basket テーブルを直接更新することはできません。 Basket マイクロサービスを更新するには、Catalog マイクロサービスが最終的な整合性を使用する必要があります。この整合性はおそらく、統合イベント (メッセージとイベント ベースの通信) などの非同期通信を基盤とします。 これは、eShopOnContainers 参照アプリケーションがマイクロサービス全体でこの種類の整合性を実行している方法です。
CAP 定理で説明されているように、可用性と ACID の厳密な整合性のどちらかを選ぶ必要があります。 マイクロサービス ベースのほとんどのシナリオでは、厳密な整合性より可用性と高いスケーラビリティが要求されます。 ミッション クリティカルなアプリケーションは稼働状態を維持する必要があり、開発者は弱い整合性または最終的な整合性を操作する手法を使って、厳密な整合性を回避できます。 ほとんどのマイクロサービス ベースのアーキテクチャでは、この方法が採用されています。
さらに、ACID スタイルのトランザクションや 2 フェーズ コミット トランザクションは、マイクロサービスの原則に反しているだけではありません。ほとんどの NoSQL データベース (Azure Cosmos DB、MongoDB など) は、分散型データベースで一般的な 2 フェーズ コミット トランザクションをサポートしていません。 ただし、サービス間およびデータベース間でデータの整合性を維持することは不可欠です。 この課題は、特定のデータを冗長にする必要がある場合に、複数のマイクロサービスの間で変更を反映する方法という質問にも関連します。たとえば、製品の名前や説明を Catalog マイクロサービスと Basket マイクロサービスで保持する必要があるような場合です。
この問題に適した解決策は、イベント ドリブンの通信およびパブリッシュとサブスクライブ システムを通じて統合されたマイクロサービスの間の最終的整合性を使うことです。 これらのトピックについては、「Asynchronous event-driven communication」(非同期のイベント ドリブン通信) を参照してください。
課題 #4: マイクロサービスの境界を越える通信を設計する方法
マイクロサービスの境界をまたいだ通信は、真の課題です。 このコンテキストでは、通信とは使う必要のあるプロトコル (HTTP と REST、AMQP、メッセージングなど) のことではありません。 そうではなくて、使う必要のある通信スタイル、特にマイクロサービス同士を結合する方法のことです。 結合のレベルにより、障害が発生したときのシステムへの影響が大きく異なります。
マイクロサービスに基づくアプリケーションのような分散システムでは、非常に多くのアーティファクトが動き回り、多くのサーバーやホストにサービスが分散しており、コンポーネントが最終的に失敗します。 部分的な障害やさらに大きな停止が発生するので、このタイプの分散システムにおいて一般的なリスクを考慮して、マイクロサービスおよびマイクロサービス間の通信を設計する必要があります。
一般的な方法は、簡単であるという理由から、HTTP (REST) ベースのマイクロサービスを実装することです。 HTTP ベースの方法は何の問題もなく受け入れられます。ここでの問題はその使い方に関係します。 クライアント アプリケーションまたは API ゲートウェイからマイクロサービスとの対話だけに HTTP 要求および応答を使うのであれば、問題はありません。 しかし、複数のマイクロサービスの間に同期 HTTP 呼び出しの長いチェーンを作成する場合は、マイクロサービスがモノリシック アプリケーション内のオブジェクトであるかのように境界をまたがって通信を行い、アプリケーションで最終的に問題が発生します。
たとえば、クライアント アプリケーションが Ordering マイクロサービスのような個別のマイクロサービスに対して HTTP API 呼び出しを行うものとします。 Ordering マイクロサービスが同じ要求/応答サイクル内で HTTP を使ってさらに他のマイクロサービスを呼び出す場合、HTTP 呼び出しのチェーンが作成されます。 最初は問題ないように思うかもしれません。 しかし、この過程では考慮する必要のある重要な点があります。
ブロックと低パフォーマンス。 HTTP の同期特性により、すべての内部 HTTP 呼び出しが終了するまで、最初の要求は応答を受け取りません。 このような呼び出しの数が大幅に増加すると同時に、中間にあるマイクロサービスの HTTP 呼び出しの 1 つがブロックされた場合を考えてみてください。 結果としてパフォーマンスに影響があり、さらに HTTP 要求が増えると全体的なスケーラビリティは指数関数的に影響を受けます。
マイクロサービスと HTTP の結合。 ビジネス マイクロサービスは、他のビジネス マイクロサービスと結合されてはなりません。 他のマイクロサービスの存在について "知らない" ことが理想です。 例のようにアプリケーションが結合しているマイクロサービスに依存している場合、マイクロサービスごとの自律性を実現することはほとんど不可能です。
いずれか 1 つのマイクロサービスにおける障害。 HTTP 呼び出しによってリンクされたマイクロサービスのチェーンを実装した場合、いずれかのマイクロサービスで障害が発生すると (そして最終的に複数のマイクロサービスが障害になると)、マイクロサービスのチェーン全体が障害になります。 マイクロサービス ベースのシステムは、部分的な障害の間も可能な限り動作し続けるように設計する必要があります。 指数バックオフの再試行またはサーキット ブレーカー メカニズムを使うクライアント ロジックを実装する場合でも、HTTP 呼び出しチェーンが複雑になるほど、HTTP に基づく障害戦略の実装も複雑になります。
実際、説明したように HTTP 要求のチェーンを作成することで内部マイクロサービスが通信している場合、プロセス内通信メカニズムではなくプロセス間の HTTP に基づくモノリシック アプリケーションであると言うことができます。
したがって、マイクロサービスの自律性を適用して復元性を向上させるには、マイクロサービス間の要求/応答通信のチェーンの使用を最小限にする必要があります。 非同期メッセージとイベント ベースの通信を使うか、元の HTTP 要求/応答サイクルとは独立して (非同期) HTTP ポーリングを使うことにより、マイクロサービス間の通信には非同期対話のみを使うことをお勧めします。
非同期通信の使用については、「マイクロ サービスの自律性を強制する非同期マイクロ サービスの統合」および「メッセージベースの非同期通信」を参照してください。
その他のリソース
データ整合性入門
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Martin Fowler。 コマンド クエリ責務分離 (CQRS)
https://martinfowler.com/bliki/CQRS.html具体化されたビュー
https://learn.microsoft.com/azure/architecture/patterns/materialized-viewCharles Row。 ACID と BASE: データベース トランザクション処理での pH のシフト
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/補正トランザクション
https://learn.microsoft.com/azure/architecture/patterns/compensating-transactionUdi Dahan。 サービス指向のコンポジション
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/
GitHub で Microsoft と共同作業する
このコンテンツのソースは GitHub にあります。そこで、issue や pull request を作成および確認することもできます。 詳細については、共同作成者ガイドを参照してください。
.NET