SQL と NoSQL データ
ヒント
このコンテンツは eBook の「Azure 向けクラウド ネイティブ .NET アプリケーションの設計」からの抜粋です。.NET Docs で閲覧できるほか、PDF として無料ダウンロードすると、オンラインで閲覧できます。

リレーショナル (SQL) と非リレーショナル (NoSQL) は、クラウドネイティブ アプリで一般的に実装される 2 種類のデータベース システムです。 これらは異なる方法でビルドされます。また、これらには異なる方法でデータが格納され、アクセスされます。 このセクションでは、これら両方について見ていきます。 この章の後半では、NewSQL という新しいデータベース テクノロジについて確認します。
''リレーショナル データベース'' は、数十年で広まったテクノロジです。 これらは成熟し、実績があり、広く実装されています。 競合するデータベース製品、ツール、専門知識があふれています。 リレーショナル データベースにより、関連データ テーブルのストアが提供されます。 これらのテーブルには固定スキーマがあり、SQL (構造化照会言語) を使用してデータを管理し、ACID (原子性、一貫性、分離性、持続性) 保証をサポートしています。
NoSQL データベースは、ハイパフォーマンスの非リレーショナル データ ストアを意味します。 これらは、使いやすさ、スケーラビリティ、回復性、可用性の特性に優れています。 NoSQL では、正規化されたデータのテーブルを結合するのではなく、非構造化または半構造化データを、多くの場合、キーと値のペアまたは JSON ドキュメントに格納します。 NoSQL データベースでは通常、単一のデータベース パーティションのスコープを超える ACID 保証は提供されません。 1 秒未満の応答時間を必要とする大量のサービスでは、NoSQL データストアが優先されます。
分散型クラウドネイティブ システムの NoSQL テクノロジの影響は、どれだけ誇張してもし過ぎることはありません。 この領域における新しいデータ テクノロジの普及により、かつてはリレーショナル データベースにのみ依存していたソリューションが中断されました。
NoSQL データベースには、データにアクセスして管理するための複数の異なるモデルが含まれており、それぞれ特定のユース ケースに適しています。 図 5-9 には、4 つの一般的なモデルが示されています。
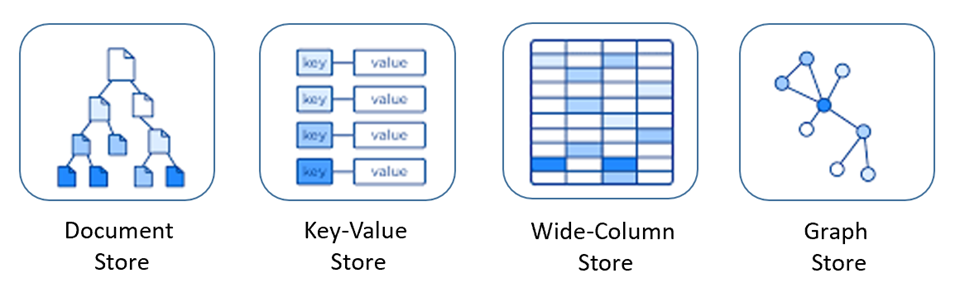
図 5-9: NoSQL データベースのデータ モデル
| モデル | 特性 |
|---|---|
| ドキュメント ストア | データとメタデータは、データベース内の JSON ベース ドキュメントに階層的に格納されます。 |
| キー値ストア | NoSQL データベースの最もシンプルなデータは、キーと値のペアのコレクションとして表されます。 |
| ワイドカラム ストア | 関連データは、1 つの列内に入れ子になったキーと値のペアのセットとして格納されます。 |
| グラフ ストア | データは、ノード、エッジ、およびデータ プロパティとしてグラフ構造体に格納されます。 |
CAP および PACELC 定理
これらの種類のデータベースの違いを理解する手段として、CAP 定理を、状態を格納する分散システムに適用される一連の原則と見なします。 図 5 -10 には、CAP 定理の 3 つのプロパティが示されています。
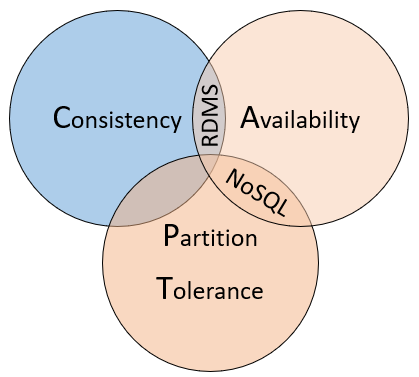
図 5-10 CAP 定理
この定理では、分散データ システムにより、整合性、可用性、およびパーティション トレランスの間でのトレードオフが提供されることが示されています。 また、いずれのデータベースでも保証できるのは、次の 3 つのプロパティのうち ''2 つ'' だけであることが示されています。
一貫性。 すべてのレプリカが更新されるまでシステムで要求をブロックする必要がある場合でも、クラスター内のすべてのノードが最新のデータで応答します。 現在更新中の項目について "整合性のあるシステム" に対してクエリを実行した場合、すべてのレプリカが正常に更新されるまでその応答を待機することになります。 しかし、最新のデータを受け取ることができます。 CAP 定理のコンテキストで使用される "一貫性" という用語は、ACID 保証のコンテキストで定義される "一貫性" とは技術的に意味が異なることを理解する必要があります。
可用性。 システム内の障害が発生していないノードによって受信されたすべての要求には応答が返される必要があります。 単純化すると、"利用可能なシステム" に対して更新中のアイテムのクエリを実行すると、そのサービスがその時点で提供できる応答の中で最善のものが返されます。 ただし、CAP 定理で定義されている "可用性" は、従来知られている分散システムの "高可用性" とは技術的に異なることに注意してください。
''パーティション トレランス。 '' レプリケートされたデータのノードで障害が発生した場合や、他のレプリケートされたデータのノードとの接続が失われた場合でも、システムが引き続き動作することを保証します。
CAP 定理により、ネットワーク パーティション時の整合性と可用性の管理に関連するトレードオフが説明されますが、一貫性とパフォーマンスに関するトレードオフは、ネットワーク パーティションがない場合にも存在します。
Note
一貫性よりも可用性を優先した場合でも、ネットワーク パーティションの発生時には可用性が低下します。 CAP における可用性の高いシステムとは、クライアントの一部にとって可用性が高いという意味であり、必ずしもすべてのクライアントにとって "可用性が高い" とは限りません。
CAP 定理は、トレードオフをより包括的に説明する PACELC にさらに拡張されることがよくあります。 CAP 定理は、モノのインターネット (IoT)、環境監視、モバイル アプリケーションに関連する環境など、断続的に接続された環境で特に関連します。 これらのコンテキストでは、停電などの困難な物理的な状態やエレベーターのような限られたスペースに入ると、デバイスがパーティション分割される可能性があります。 クラウド アプリケーションなどの分散システムの場合は、PACELC 定理を使用する方が適切です。これはより包括的であり、ネットワーク パーティションがない場合でも待機時間や一貫性などのトレードオフを考慮します。
リレーショナル データベースでは通常、整合性と可用性が提供されますが、パーティション トレランスは提供されません。 通常、これらは単一サーバーにプロビジョニングされ、コンピューターにさらにリソースを追加することで垂直方向にスケーリングします。
多くのリレーショナル データベース システムでは、プライマリ データベースを他のセカンダリ サーバー インスタンスにコピーできる組み込みのレプリケーション機能がサポートされています。 書き込み操作は、プライマリ インスタンスに対して行われ、各セカンダリにレプリケートされます。 障害発生時に、プライマリ インスタンスでセカンダリにフェールオーバーして高可用性を実現できます。 セカンダリを使用して、読み取り操作を分散させることもできます。 書き込み操作は常にプライマリ レプリカに対して行われますが、読み取り操作を任意のセカンダリにルーティングしてシステム負荷を減らすことができます。
データは、シャーディングなどによって、複数のノードにわたって水平方向にパーティション分割することもできます。 しかし、シャーディングでは、簡単に通信できない多くの要素にデータを分割することによって、運用上のオーバーヘッドが大幅に増えます。 コストがかかり、管理に時間がかかることがあります。 テーブルの結合、トランザクション、参照整合性を含むリレーショナル機能では、シャード化された展開で、パフォーマンスの急激な低下が避けられません。
レプリケーションの整合性と復旧ポイントの目標は、レプリケーションが同期的に行われるか非同期的に行われるかを構成すると調整できます。 "高い整合性" または同期リレーショナル データベース クラスターにおいて、データ レプリカのネットワーク接続が失われた場合、データベースに書き込むことができなくなります。 書き込み操作は、その変更を他のデータ レプリカにレプリケートできないため、システムによって拒否されます。 トランザクションを完了するには、すべてのデータ レプリカを更新する必要があります。
NoSQL データベースでは通常、高可用性とパーティション トレランスがサポートされます。 これらは多くの場合、汎用的なサーバー間で水平方向にスケールアウトされます。 この手法では、コストを抑えて地理的リージョン内および間の両方で可用性が大幅に向上します。 これらのコンピューターまたはノード間でデータをパーティション分割してレプリケートすることで、冗長性とフォールト トレランスが得られます。 整合性は、通常、コンセンサス プロトコルまたはクォーラム メカニズムで調整されます。 これによって、リレーショナル システムで同期および非同期レプリケーション間を調整する場合のトレードオフを操作するときに、より多くの制御が提供されます。
データ レプリカが "高可用性" NoSQL データベース クラスター内で接続を失った場合でも、データベースに対する書き込み操作を完了できます。 データベース クラスターにより、書き込み操作が許可され、各データ レプリカが使用可能になった時点で更新されます。 書き込み可能な複数のレプリカをサポートする NoSQL データベースでは、目標復旧時間を最適化するときにフェールオーバーを不要にすることで、さらに高可用性が強化されます。
最新の NoSQL データベースには、システム設計の機能として、通常パーティション分割機能が実装されています。 多くの場合、パーティション管理はデータベースに組み込まれており、ルーティングは配置ヒント (パーティション キーと呼ばれることが多い) によって実現されています。 柔軟なデータ モデルを使用すると、NoSQL データベースで、スキーマ管理の負担を軽減したり、データ モデルの変更を必要とするアプリケーションの更新プログラムを展開するときの可用性を向上したりすることができます。
高可用性と大規模なスケーラビリティは、多くの場合、リレーショナル テーブルの結合や参照整合性よりもビジネスにとって重要です。 開発者は、Sagas、CQRS、非同期メッセージングなどの手法やパターンを実装して、最終的な整合性を受け入れることができます。
今日では、CAP 定理の制約を検討する際に注意が必要です。 NewSQL と呼ばれる新しい種類のデータベースが登場しました。これにより、リレーショナル データベース エンジンが拡張され、水平方向のスケーラビリティと NoSQL システムのスケーラブルなパフォーマンスの両方がサポートされます。
リレーショナルおよび NoSQL システムに関する考慮事項
クラウドネイティブベースのマイクロサービスでは、特定のデータ要件に基づいて、リレーショナルまたは NoSQL データストア、あるいはその両方を実装できます。
| 次の場合は、NoSQL データストアを検討してください。 | 次の場合はリレーショナル データベースを検討してください。 |
|---|---|
| 大規模で予測可能な待機時間を必要とする大量のワークロードがある (たとえば、1 秒あたり数百万回のトランザクションが実行される中でミリ秒単位で測定される待機時間など) | ワークロードのボリュームが、通常 1 秒あたり数千トランザクションに収まる |
| データが動的であり、頻繁に変更される | データが高度に構造化されており、参照整合性が必要である |
| リレーションシップが、非正規化されたデータ モデルである場合がある | リレーションシップは、正規化されたデータ モデルでテーブル結合によって表されている |
| データ取得は単純で、テーブル結合なしで表されている | 複雑なクエリとレポートを操作する |
| データは通常、地域を超えてレプリケートされ、整合性、可用性、パフォーマンスが細かく制御される必要がある | データは通常一元化されているか、非同期的にリージョンをレプリケートできる |
| アプリケーションが、パブリック クラウドなどで、汎用的なハードウェアにデプロイされる | アプリケーションが、大規模なハイエンド ハードウェアにデプロイされる |
次のセクションでは、クラウドネイティブ データを格納および管理するために Azure クラウドで利用できるオプションを確認します。
サービスとしてのデータベース
まず、Azure 仮想マシンをプロビジョニングし、サービスごとに任意のデータベースをインストールすることができます。 環境を完全に制御できますが、クラウド プラットフォームの多くの組み込み機能は利用しません。 また、サービスごとに仮想マシンとデータベースの管理を自分で行う必要があります。 この手法では、すぐに時間がかかるようになり、コストが増える可能性があります。
代わりに、クラウドネイティブ アプリケーションでは、サービスとしてのデータベース (DBaaS) として公開されるデータ サービスが優先されます。 クラウド ベンダーによって完全に管理されており、これらのサービスでは組み込みのセキュリティ、スケーラビリティ、および監視機能が提供されます。 サービスを所有するのではなく、単にそれをバッキング サービスとして使用します。 プロバイダーは大規模にリソースを操作し、パフォーマンスとメンテナンスの責任を担います。
高可用性を実現するために、クラウドの可用性ゾーンとリージョン全体に構成することができます。 これらすべてで、Just-In-Time 容量および従量課金制モデルがサポートされます。 Azure には、さまざまな種類のマネージド データ サービス オプションがあり、それぞれに特定の利点があります。
まず、Azure で使用できるリレーショナル DBaaS サービスを見ていきましょう。 Microsoft の主要な SQL Server データベースを、いくつかのオープンソース オプションと共に利用できることがわかります。 その後、Azure の NoSQL データ サービスについて説明します。
Azure リレーショナル データベース
リレーショナル データを必要とするクラウドネイティブ マイクロサービスの場合、図 5-11 に示すように、Azure によって、4 つのマネージドのサービスとしてのリレーショナル データベース (DBaaS) オファリングが提供されます。

図 5-11 Azure で利用可能なマネージド リレーショナル データベース
前の図で、それぞれが共通の DBaaS インフラストラクチャにどのように配置されているかに注目してください。これにより、追加コストなしで主要な機能が提供されます。
これらの機能は、多数のデータベースをプロビジョニングし、それらを管理するためのリソースが限られている組織にとって特に重要です。 処理コア、メモリ、および基になるストレージの量を選択することで、Azure データベースを数分でプロビジョニングすることができます。 データベースをすぐにスケーリングし、ダウンタイムをほとんどまたはまったく発生させることなくリソースを動的に調整できます。
Azure SQL データベース
Microsoft SQL Server の専門知識がある開発チームは、Azure SQL Database について検討する必要があります。 これは、Microsoft SQL Server データベース エンジンに基づくフル マネージドのサービスとしてのリレーショナル データベース (DBaaS) です。 このサービスでは、オンプレミス バージョンの SQL Server で検出された多くの機能を共有し、最新の安定したバージョンの SQL Server データベース エンジンを実行します。
クラウドネイティブ マイクロサービスで使用する場合、Azure SQL Database を次の 3 つのデプロイ オプションで利用できます。
Single Database は、Azure クラウドの Azure SQL Database サーバーで実行されているフル マネージド SQL Database を表します。 このデータベースは、基になるデータベース サーバーに対する構成の依存関係がないため、''包含'' と見なされます。
Managed Instance は、オンプレミスの SQL Server とのほぼ 100% の互換性を提供する Microsoft SQL Server データベース エンジンのフル マネージド インスタンスです。 このオプションでは、分離性を高めるために Azure Virtual Network に配置されている 35 TB までの大規模なデータベースがサポートされます。
Azure SQL Database サーバーレスは、ワークロードの需要に基づいて自動的にスケーリングされる単一データベースのコンピューティング レベルです。 1 秒あたりに使用されたコンピューティングの量に対してのみ課金されます。 このサービスは、断続的で、使用パターンが予測できない、非アクティブの期間が混在するワークロードに適しています。 また、サーバーレス コンピューティング レベルでは、非アクティブ期間中に自動的にデータベースを一時停止して、ストレージの料金のみが課金されるようにします。 アクティブに戻ると自動的に再開されます。
Azure では、従来の Microsoft SQL Server スタックだけでなく、マネージド バージョンの 3 つの一般的なオープンソース データベースも提供します。
Azure のオープンソース データベース
オープンソースのリレーショナル データベースは、クラウドネイティブ アプリケーションで一般的に選ばれるようになりました。 多くの企業では、特にコストを削減するために、商用データベース製品よりもそれらを優先します。 多くの開発チームは、柔軟性、コミュニティによってサポートされる開発、ツールと拡張機能のエコシステムを利用できます。 オープンソース データベースは、複数のクラウド プロバイダーにデプロイできるので、"ベンダー ロックイン" の問題を最小限に抑えるのに役立ちます。
開発者は、任意のオープンソース データベースを Azure VM 上で簡単にセルフホストできます。 この手法の場合、完全に制御できますが、データベースと VM の管理、監視、およびメンテナンスが困難になります。
しかしながら、Microsoft では、いくつかの一般的なオープンソース データベースを ''フル マネージド'' DBaaS サービスとして提供することにより、Azure を "オープン プラットフォーム" のままにしておくというコミットメントを維持しています。
Azure Database for MySQL
MySQL はオープンソースのリレーショナル データベースであり、LAMP ソフトウェア スタック上に構築されたアプリケーションの柱となるものです。 ''読み取り負荷の高い'' ワークロードで幅広く選ばれており、Facebook、Twitter、YouTube などの多くの大規模な組織で使用されています。 Community Edition は無料でご利用いただけますが、Enterprise Edition ではライセンス購入が必要です。 1995 年に最初に作成され、製品は 2008 年に Sun Microsystems によって買い取られました。 2010 年には、Oracle が Sun と MySQL を買収しました。
Azure Database for MySQL は、オープンソースの MySQL Server エンジンに基づいたマネージド リレーショナル データベース サービスです。 MySQL Community Edition が使用されます。 Azure MySQL サーバーは、サービスの管理ポイントです。 これは、オンプレミスのデプロイに使用されるものと同じ MySQL サーバー エンジンです。 このエンジンでは、サーバーごとに単一のデータベース、またはリソースを共有するサーバーごとに複数のデータベースを作成できます。 新しいスキルを習得したり、仮想マシンを管理したりすることなく、同じオープンソース ツールを使用してデータの管理を継続できます。
Azure Database for MariaDB
MariaDB サーバーは、もう 1 つの一般的なオープンソースのデータベース サーバーです。 これは、MySQL を所有していた Sun Microsystems を Oracle が買い取った際に、MySQL の ''フォーク'' として作成されたものです。 その目的は、MariaDB を確実にオープンソースのままにしておくことでした。 MariaDB は MySQL のフォークであるため、データとテーブルの定義に互換性があり、クライアント プロトコル、構造体、および API は緊密に結び付いています。
MariaDB には強力なコミュニティがあり、多くの大企業で使用されています。 Oracle では MySQL を引き続き維持、強化、サポートしますが、MariaDB Foundation で MariaDB が管理されており、これにより製品とドキュメントへの公開投稿が可能になります。
Azure Database for MariaDB は、Azure クラウドにおけるフル マネージドのサービスとしてのリレーショナル データベースです。 このサービスは、MariaDB コミュニティ エディション サーバー エンジンに基づいています。 予測可能なパフォーマンスと動的なスケーラビリティを実現しながら、ミッション クリティカルなワークロードを処理できます。
Azure Database for PostgreSQL
PostgreSQL は、30 年以上アクティブに開発されているオープンソースのリレーショナル データベースです。 PostgreSQL は、信頼性およびデータ整合性について確固たる評判を得ています。 機能豊富で、SQL に準拠しており、MySQL よりもパフォーマンスが高いと見なされます (特に、クエリが複雑で大量の書き込みが発生するワークロードの場合)。 Apple、Red Hat、および富士通を含む多くの大企業は、PostgreSQL を使用して製品を構築してきました。
Azure Database for PostgreSQL は、オープンソースの Postgres データベース エンジンに基づいたフル マネージドのリレーショナル データベース サービスです。 このサービスでは、C++、Java、Python、Node、C#、PHP など、多くの開発プラットフォームがサポートされています。 コマンドライン インターフェイス ツールまたは Azure データ移行サービスを使用して、PostgreSQL データベースをそこに移行することができます。
Azure Database for PostgreSQL は、次の 2 つのデプロイ オプションで使用できます。
Single Server デプロイ オプションは、多くのデータベースをデプロイできる複数のデータベースの中央管理ポイントです。 価格は、コアとストレージに基づいてサーバーごとに構造化されています。
Hyperscale (Citus) オプションでは、Citus Data テクノロジが利用されています。 単一データベースを数百のノードにわたって ''水平方向にスケーリング'' することで高速なパフォーマンスとスケーラビリティを提供し、ハイ パフォーマンスを実現します。 このオプションを使用すると、エンジンではより多くのデータをメモリに格納し、数百のノードにわたってクエリを並列化し、より高速にデータのインデックスを作成できます。
Azure の NoSQL データ
Cosmos DB は、Azure クラウドにおけるフル マネージドのグローバルに分散された NoSQL データベース サービスです。 これは世界中の多くの大企業 (Coca-Cola、Skype、ExxonMobil、Liberty Mutual など) で採用されています。
ご利用のサービスで世界中のあらゆる場所からの高速応答、高可用性、またはエラスティック スケーラビリティが必要な場合は、Cosmos DB が最適です。 図 5-12 には Cosmos DB が示されています。
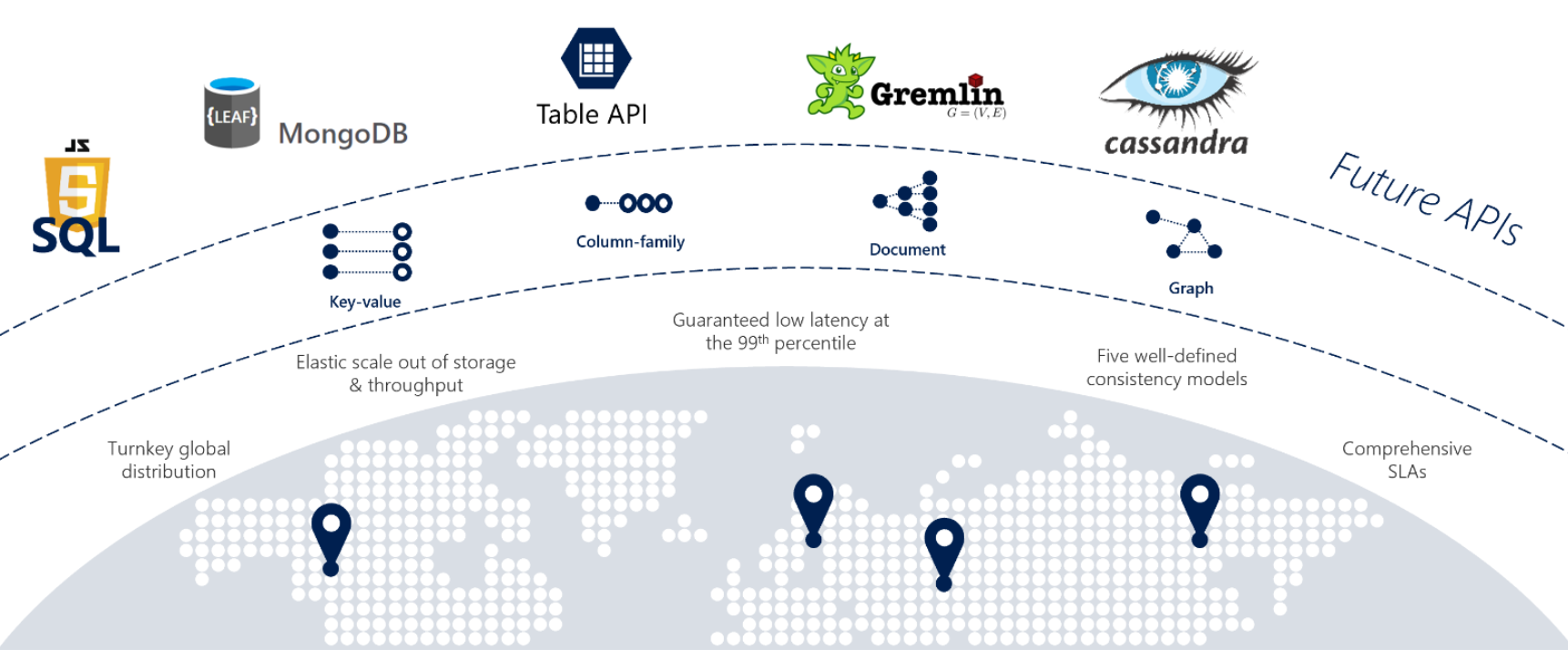
図 5-12: Azure Cosmos DB の概要
前の図には、Cosmos DB で使用できる組み込みのクラウドネイティブ機能の多くが示されています。 このセクションでは、それらを詳しく見ていきます。
グローバル サポート
クラウドネイティブ アプリケーションには多くの場合、グローバル対象ユーザーが存在し、グローバル スケールが必要です。
Cosmos データベースをリージョン間または世界中に分散させ、データをユーザーの近くに配置し、応答時間を改善し、待機時間を短縮することができます。 サービスを一時停止または再デプロイすることなく、リージョンのデータベースを追加または削除できます。 バックグラウンドでは、Cosmos DB によって、構成されている各リージョンにデータが透過的にレプリケートされます。
Cosmos DB では、グローバル レベルでアクティブ/アクティブ クラスタリングがサポートされているため、''書き込みと読み取りの両方'' をサポートするように任意のデータベース リージョンを構成できます。
複数リージョン書き込みプロトコルは、次の機能を有効にする Cosmos DB の重要な機能です。
無制限でエラスティックな書き込みと読み取りのスケーラビリティ。
全世界での 99.999% の読み取りおよび書き込みの可用性。
99 パーセンタイルで 10 ミリ秒未満の処理性能が保証された読み取りと書き込み。
Cosmos DB マルチホーム API を使用すると、マイクロサービスで自動的に最も近い Azure リージョンが認識され、そこに要求が送信されます。 最も近いリージョンは、構成を変更することなく Cosmos DB によって識別されます。 リージョンを利用できなくなった場合、マルチホーム機能により、次に最も近い利用可能なリージョンに自動的に要求がルーティングされます。
マルチモデル サポート
モノリシック アプリケーションをクラウドネイティブ アーキテクチャに再プラットフォーム化する場合、開発チームはオープンソースの NoSQL データ ストアの移行が必要になることがあります。 Cosmos DB は、その ''マルチモデル'' データ プラットフォームを使用して、これらの NoSQL データストアへの投資を維持するのに役立ちます。 次の表には、サポートされている NoSQL の互換性 API が示されています。
| プロバイダー | 説明 |
|---|---|
| NoSQL API | API for NoSQL では、ドキュメント形式でデータが格納されます |
| Mongo DB API | Mongo DB API と JSON ドキュメントをサポートします |
| Gremlin API | グラフベースのノードとエッジ データ表現により Gremlin API をサポートします |
| Cassandra API | ワイドカラムのデータ表現により Casandra API をサポートします |
| Table API | Premium の機能強化により Azure Table Storage をサポートします |
| PostgreSQL API | 任意の規模で PostgreSQL を実行するためのマネージド サービス |
開発チームは、データまたはコードへの変更を最小限に抑えながら、既存の Mongo、Gremlin、または Cassandra データベースを Cosmos DB に移行できます。 新しいアプリの場合、開発チームはオープンソース オプションと組み込みの SQL API モデルのいずれかを選択できます。
内部的に、Cosmos では、プリミティブ データ型で構成されたシンプルな構造体形式でデータを格納します。 要求ごとに、データベース エンジンによって、プリミティブ データが選択されたモデルの表現に変換されます。
前の表の、Table API オプションに注目してください。 この API は、Azure Table Storage が進化したものです。 どちらも基になる同じテーブル モデルを共有しますが、Cosmos DB Table API では、Azure Storage API で利用できない Premium の機能強化が追加されています。 次の表で機能を比較します。
| 特徴量 | Azure Table Storage | Azure Cosmos DB |
|---|---|---|
| 待機時間 | 速い | 世界中のあらゆる場所での読み取りと書き込みの待機時間が 1 桁のミリ秒である |
| スループット | テーブルあたりの操作数が 2 万に制限されている | テーブルあたりの操作数に制限がない |
| グローバル分散 | 単一のセカンダリ読み取りリージョンをオプションで備えた単一リージョン | 自動フェールオーバーを使用するすべてのリージョンへのターンキー ディストリビューション |
| インデックス作成 | パーティションおよび行キーのプロパティでのみ使用可能 | すべてのプロパティの自動インデックス作成 |
| 価格 | コールド ワークロード用に最適化されている (低スループット: ストレージ比率) | ホット ワークロード用に最適化されている (高スループット: ストレージ比率) |
Azure Table Storage を使用するマイクロサービスは、Cosmos DB Table API に簡単に移行できます。 コードに変更を加える必要はありません。
調整可能な一貫性
前述の ''リレーショナルおよび NoSQL'' に関するセクションでは、''データの整合性'' について説明しました。 データの整合性とは、ご利用のデータの ''整合性'' を意味します。 分散データを使用するクラウドネイティブ サービスはレプリケーションに依存しているため、読み取りの整合性、可用性、待機時間の間で基本的なトレードオフを行う必要があります。
ほとんどの分散データベースでは、開発者は 2 つの整合性モデル (厳密な整合性と最終的な整合性) のどちらかを選ぶことができます。 ''厳密な整合性'' モデルは、データ プログラミングの標準基準です。 これにより、すべてのデータベース コピーにわたって更新がレプリケートされるまで待機することでシステムで遅延が生じでも、常に最新のデータが返されることが保証されます。 一方、''最終的な整合性'' 用に構成されたデータベースでは、データが最新のコピーでなくてもそのデータがすぐに返されます。 後者のオプションを使用すると、可用性をより高くし、スケーラビリティを強化し、パフォーマンスを向上させることができます。
Azure Cosmos DB では、図 5-13 に示すように、適切に定義された 5 つの整合性モデルが提供されます。

図 5-13: Cosmos DB の整合性レベル
これらのオプションを使用すると、データの整合性、可用性、およびパフォーマンスについて、正確な選択と詳細なトレードオフを行うことができます。 レベルは次の表に示されています。
| 整合性レベル | 説明 |
|---|---|
| 最終的 | 読み取りの順序は保証されません。 レプリカは最終的に収束されます。 |
| 定数プレフィックス | 読み取りは最終的のままですが、データは書き込まれた順序で返されます。 |
| Session | 現在のセッション中に書き込まれたデータを読み取れることが保証されます。 これが既定の整合性レベルです。 |
| 有界整合性制約 | 読み取りで、指定した間隔で書き込みを追跡します。 |
| Strong | 読み取りでは、項目のコミットされた最新バージョンを返すことが保証されます。 クライアントによって、コミットされていないまたは部分的な読み取りが認識されることはありません。 |
「Getting Behind the 9-Ball: Cosmos DB Consistency Levels Explained」(ナイン ボールの背後: Cosmos DB の一貫性レベルについての説明) の記事では、Microsoft のプログラム マネージャーである Jeremy Likness 氏が 5 つのモデルについて適切に説明しています。
パーティション分割
Azure Cosmos DB では、自動パーティション分割を使用して、データベースをスケーリングし、クラウドネイティブ サービスのパフォーマンス ニーズを満たします。
データベース、コンテナー、および項目を作成することによって、Cosmos DB データ内のデータを管理します。
コンテナーは Cosmos DB データベース内に存在し、スキーマに依存しない項目のグループを表します。 項目は、コンテナーに追加するデータです。 ドキュメント、行、ノード、またはエッジとして表されます。 コンテナーに追加されたすべての項目には、自動的にインデックスが作成されます。
コンテナーをパーティション分割するために、項目が論理パーティションと呼ばれる特定のサブセットに分割されます。 論理パーティションは、コンテナー内の各項目に関連付けられているパーティション キーの値に基づいて設定されます。 図 5-14 には、2 つのコンテナーが示されており、それぞれにパーティション キー値に基づく論理パーティションがあります。
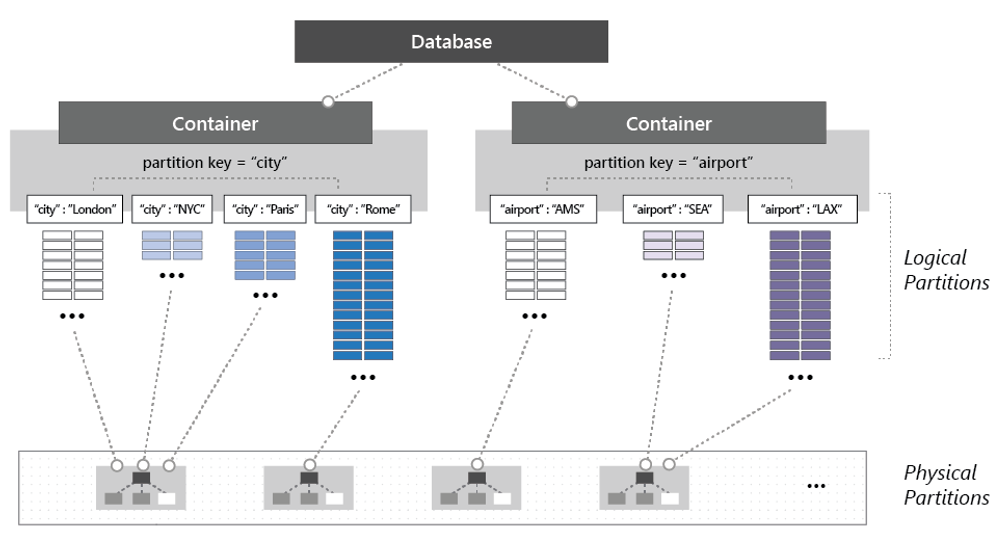
図 5-14: Cosmos DB のパーティション分割のしくみ
上の図で、各項目にどのように ''city'' または ''airport'' のパーティション キーが含まれているかに注目してください。 キーにより、項目の論理パーティションが決定します。 city コードを持つ項目は左側のコンテナーに、airport コードを持つ項目は右側のコンテナーに割り当てられます。 パーティション キー値と ID 値を組み合わせて、項目のインデックスが作成され、これにより項目が一意に識別されます。
内部的に、Cosmos DB によって、論理パーティションの物理パーティションへの配置が自動的に管理され、コンテナーのスケーラビリティとパフォーマンスのニーズが満たされます。 アプリケーションのスループットとストレージの要件が増えると、Azure Cosmos DB によって非常に多くのサーバーにわたって論理パーティションが再分散されます。 再分散操作は Cosmos DB によって管理され、中断やダウンタイムなしで呼び出されます。
NewSQL データベース
NewSQL は、NoSQL の分散型スケーラビリティをリレーショナル データベースの ACID 保証と組み合わせた新しいデータベース テクノロジです。 NewSQL データベースは、完全なトランザクション サポートと ACID コンプライアンスを備えた、分散環境全体で大量のデータを処理する必要があるビジネス システムにとって重要です。 NoSQL データベースでは大規模なスケーラビリティを実現できますが、データの整合性は保証されません。 データの不整合による断続的な問題は、開発チームに負担をかける可能性があります。 開発者は、データの不整合によって発生する問題に対処するために、マイクロサービス コードにセーフガードを構築する必要があります。
Cloud Native Computing Foundation (CNCF) には、いくつかの NewSQL データベース プロジェクトがあります。
| Project | 特性 |
|---|---|
| Cockroach DB | グローバルにスケーリングする ACID 準拠のリレーショナル データベース。 クラスターに新しいノードを追加すると、CockroachDB によってインスタンスや地域間でデータが分散されます。 信頼性を確保するために、レプリカの作成、管理、および分散が行われます。 これはオープン ソースであり、無料で利用できます。 |
| TiDB | Hybrid Transactional and Analytical Processing (HTAP) ワークロードをサポートするオープンソースのデータベース。 MySQL と互換性があり、水平方向のスケーラビリティ、厳密な整合性、高可用性が提供されます。 TiDB は、MySQL サーバーのように機能します。 アプリケーションに広範なコード変更を加える必要はなく、既存の MySQL クライアント ライブラリを引き続き使用することができます。 |
| YugabyteDB | オープンソースのハイパフォーマンスな分散 SQL データベース。 クエリの低待機時間、障害に対する回復力、およびグローバル データ分散がサポートされます。 YugabyteDB は PostgreSQL と互換性があり、スケールアウト RDBMS とインターネット規模の OLTP ワークロードを処理します。 この製品では NoSQL もサポートされ、Cassandra と互換性があります。 |
| Vitess | Vitess は、MySQL インスタンスの大規模なクラスターをデプロイ、スケーリング、および管理するためのデータベース ソリューションです。 パブリックまたはプライベートのクラウド アーキテクチャで実行できます。 Vitess では、多くの重要な MySQL 機能を組み合わせて拡張し、垂直方向と水平方向の両方のシャーディングをサポートします。 YouTube で考案された Vitess により、2011 年以降、すべての YouTube データベース トラフィックが処理されてきました。 |
前の図のオープンソース プロジェクトは、Cloud Native Computing Foundation から入手できます。 オファリングのうち 3 つは、.NET サポートを含む完全なデータベース製品です。 もう 1 つの Vitess はデータベース クラスタリング システムであり、MySQL インスタンスの大規模なクラスターを水平方向にスケーリングします。
NewSQL データベースの主な設計目標は、プラットフォームの回復性とスケーラビリティを利用して、Kubernetes でネイティブに動作することです。
NewSQL データベースは、基になる仮想マシンをすぐに再起動または再スケジュールできる短期クラウド環境で活用するために設計されています。 このデータベースは、ノードで障害が発生しても、データ損失やダウンタイムなしで存続できるように設計されています。 たとえば、CockroachDB は、クラスター内のノードにまたがるデータの整合性のある 3 つのレプリカを維持することによって、コンピューターが損失しても存続できます。
Kubernetes では、''サービス構成体'' を使用して、クライアントで、単一の DNS エントリから同じ NewSQL データベース プロセスのグループに対してアドレス指定できるようにします。 データベース インスタンスと、それが関連付けられているサービスのアドレスを分離することにより、既存のアプリケーション インスタンスを妨げることなくスケーリングできます。 特定の時点で任意のサービスに要求を送信すると、常に同じ結果が得られます。
このシナリオでは、すべてのデータベース インスタンスが同等です。 プライマリやセカンダリのリレーションシップはありません。 CockroachDB で検出された ''コンセンサス レプリケーション'' のような手法では、任意のデータベース ノードで任意の要求を処理できます。 負荷分散要求を受信するノードに、ローカルで必要なデータがある場合は、すぐに応答します。 それ以外の場合、ノードはゲートウェイになり、適切なノードに要求を転送して正しい答えを得ます。 クライアントの観点から見ると、すべてのデータベース ノードは同じです。つまり、数十、さらには数百のノードがバックグラウンドで動作していても、単一の ''論理'' データベースとして示され、単一コンピューター システムの整合性が保証されます。
NewSQL データベースの背後にあるしくみの詳細については、「DASH: Four Properties of Kubernetes-Native Databases」(DASH: Kubernetes ネイティブ データベースの 4 つのプロパティ) の記事を参照してください。
クラウドへのデータ移行
より時間のかかるタスクの 1 つは、データ プラットフォーム間でのデータの移行です。 Azure データ移行サービスは、このような作業を迅速化するのに役立ちます。 最小限のダウンタイムで、複数の外部データベース ソースから Azure データ プラットフォームにデータを移行することができます。 ターゲット プラットフォームには、次のサービスが含まれます。
- Azure SQL データベース
- Azure Database for MySQL
- Azure Database for MariaDB
- Azure Database for PostgreSQL
- Azure Cosmos DB
このサービスでは、小規模と大規模の両方の移行を実行するために必要な変更について説明する推奨事項が提供されます。
.NET