監視パターン
ヒント
このコンテンツは eBook の「Azure 向けクラウド ネイティブ .NET アプリケーションの設計」からの抜粋です。.NET Docs で閲覧できるほか、PDF として無料ダウンロードすると、オンラインで閲覧できます。

アプリケーションのコードのレイアウトを支援するために開発されたパターンと同じように、信頼性の高い方法でアプリケーションを運用するためのパターンがあります。 アプリケーションの管理で、ログ、監視、アラートの 3 つの便利なパターンが登場しました。
ログを使用する場合
どんなに注意しても、運用環境では、アプリケーションが予期外の動作することがほとんどです。 ユーザーがアプリケーションに関する問題を報告する際、問題発生時のアプリの状況を確認できると役に立ちます。 アプリケーションが実行されているときの動作に関する情報をキャプチャする方法として最もよく最も試行され、実際に行われている方法の 1 つが、何をしているのかをアプリケーションに記録させることです。 このプロセスをログと呼びます。 運用環境で障害や問題が発生した場合、障害が発生した状態を非運用環境で再現することが目標となります。 適切なログを記録することで、開発者はテストと実験が可能な環境で問題を再現するためのロードマップが得られます。
クラウドネイティブ アプリケーションでのログに関する課題
従来のアプリケーションでは、通常、ログ ファイルはローカル コンピューターに格納されます。 実際、Unix 系のオペレーティング システムでは、すべてのログを保持するように定義されたフォルダー構造があり、通常は /var/log の下に保持されます。
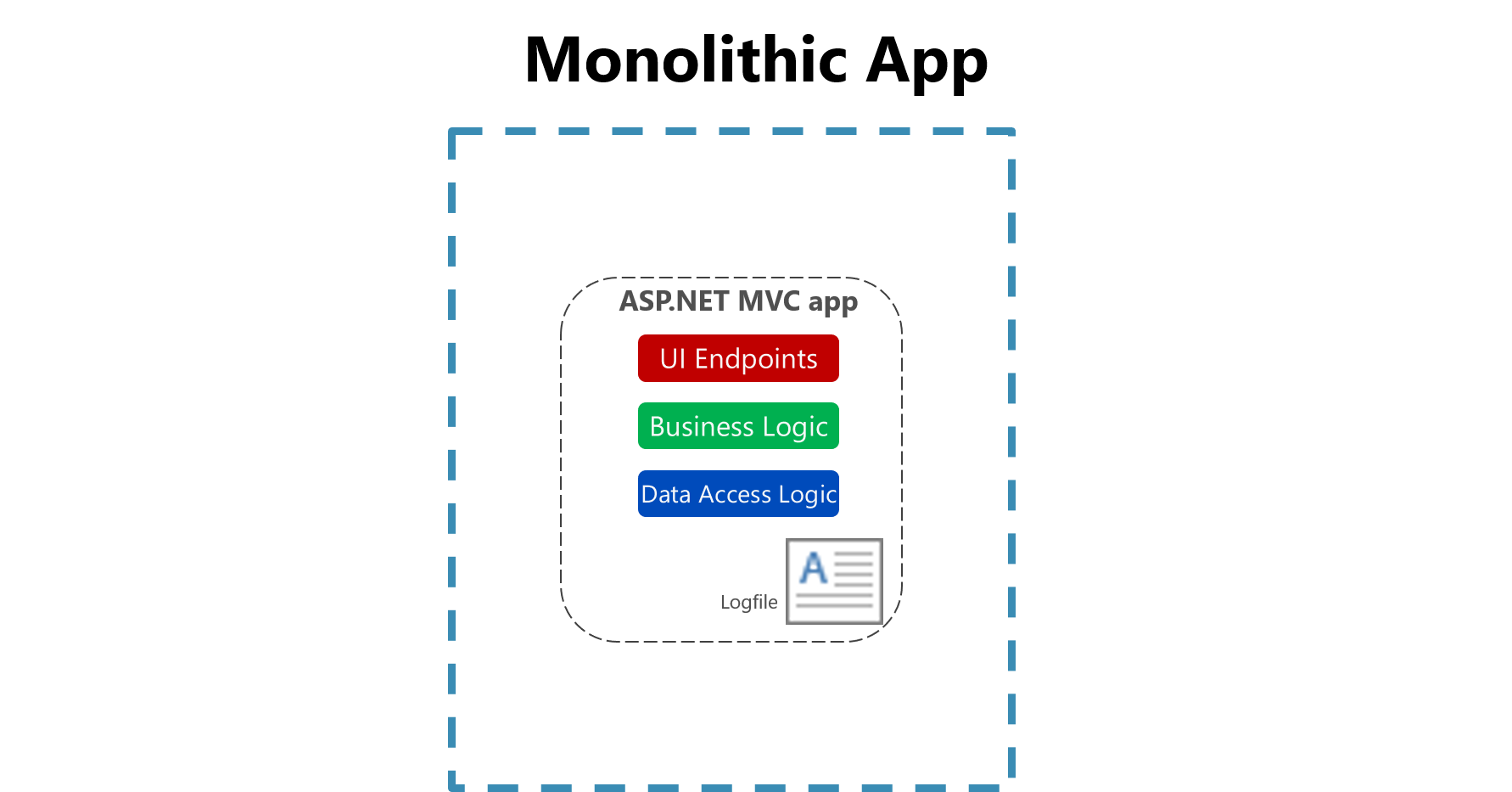 図 7-1。 モノリシック アプリでファイルにログを記録する。
図 7-1。 モノリシック アプリでファイルにログを記録する。
1 台のコンピューター上のフラット ファイルにログを記録することによる有用性は、クラウド環境では大幅に削減されます。 ログを生成するアプリケーションからローカル ディスクにアクセスできなかったり、コンテナーが物理マシン間で移動されることでローカル ディスクが非常に一時的なものになったりすることがあります。 複数のノードにまたがるモノリシック アプリケーションをスケールアップするだけで、該当するファイル ベースのログ ファイルを見つけるのが困難になる可能性があります。
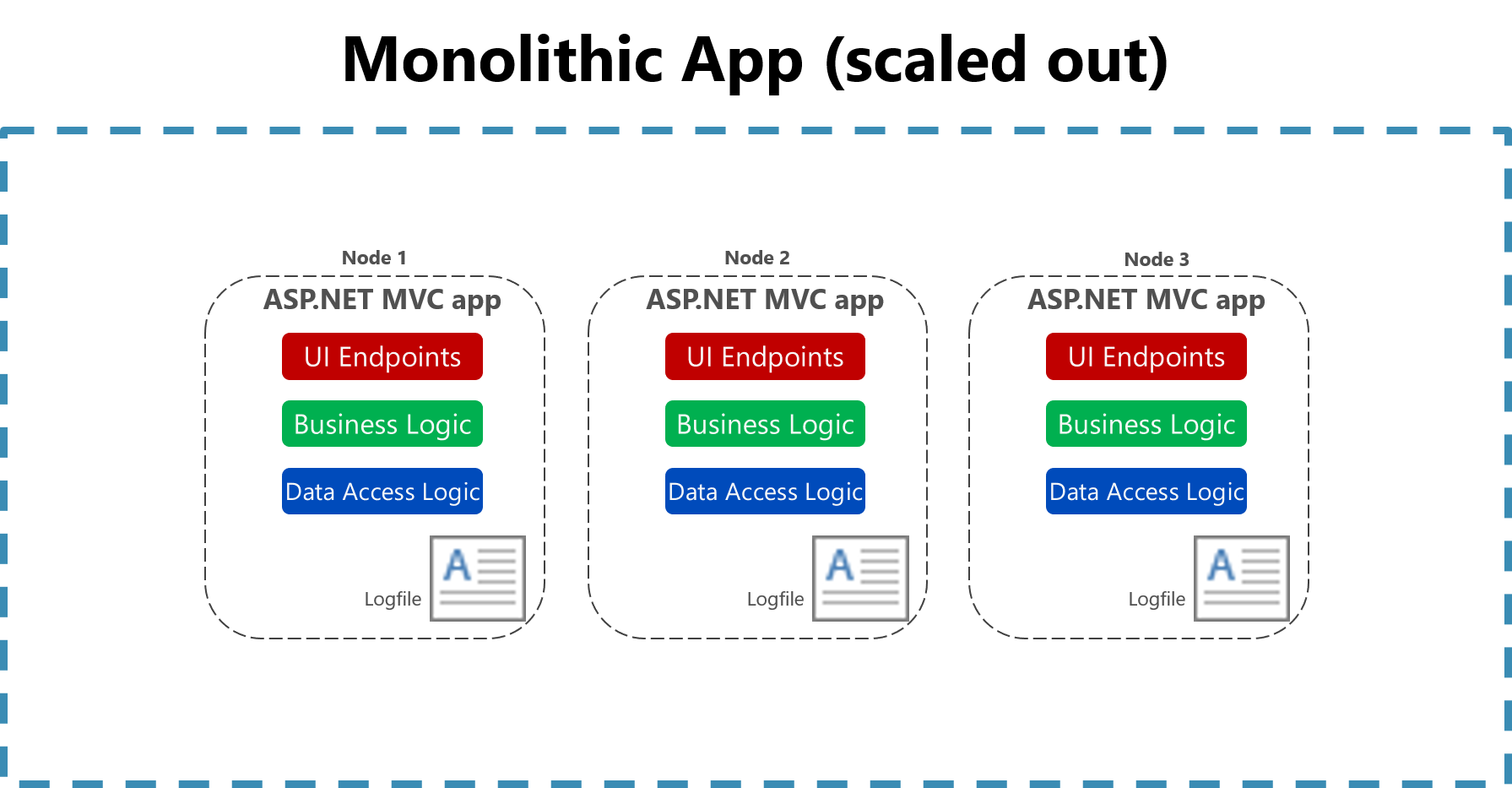 図 7-2。 スケーリングされたモノリシック アプリでファイルにログを記録する。
図 7-2。 スケーリングされたモノリシック アプリでファイルにログを記録する。
マイクロサービス アーキテクチャを使用して開発されたクラウドネイティブ アプリケーションにも、ファイルベースのロガーに関するいくつかの課題があります。 ユーザーの要求が、異なるマシン上で実行される複数のサービスにまたがることがあり、ローカル ファイル システムにまったくアクセスしないサーバーレス機能が含まれることもあります。 このような多くのサービスやマシンで、ユーザーまたはセッションのログを相互に関連付けることは非常に困難です。
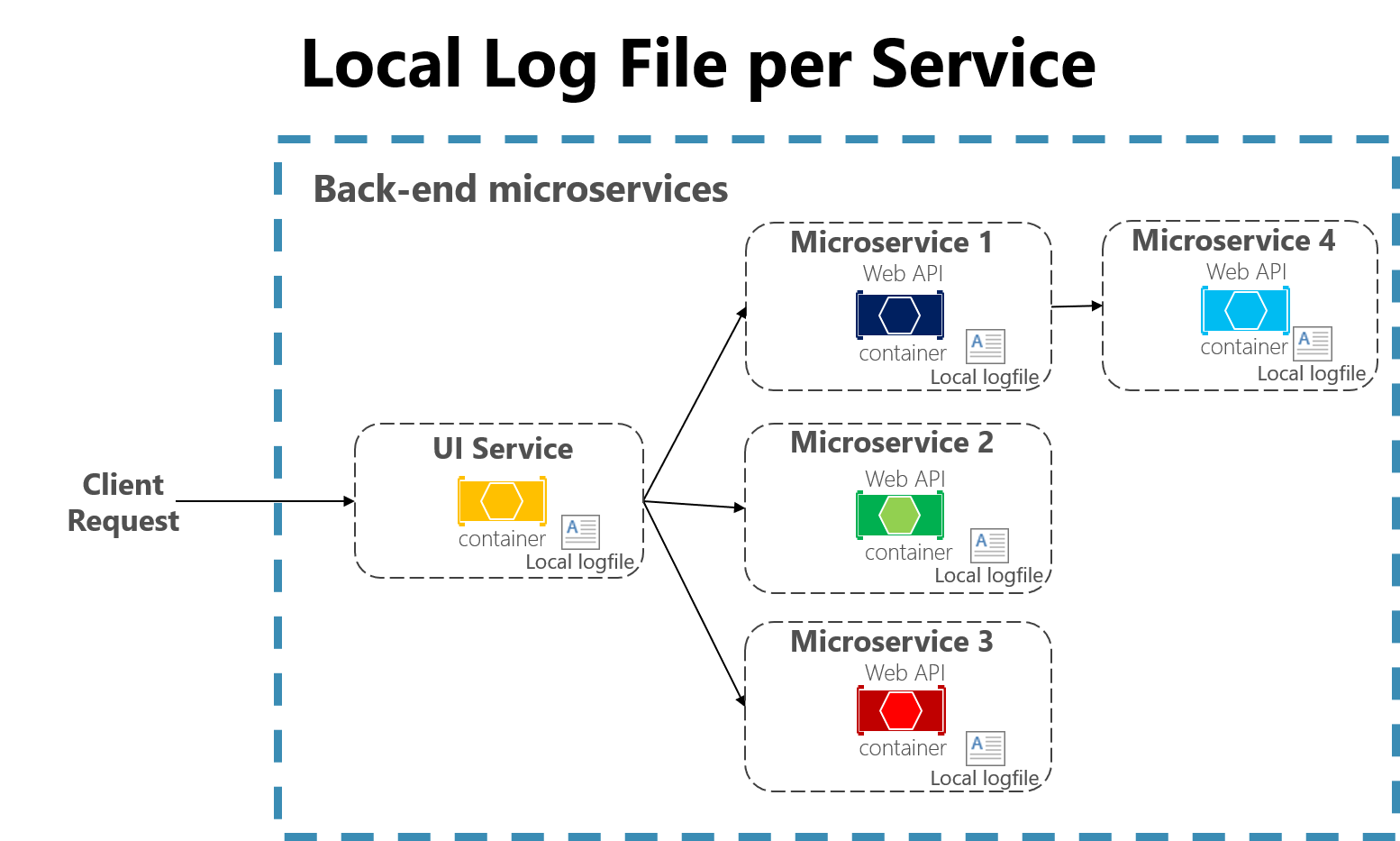 図 7-3。 マイクロサービス アプリでローカル ファイルにログを記録する。
図 7-3。 マイクロサービス アプリでローカル ファイルにログを記録する。
最後に、クラウドネイティブ アプリケーションにはユーザー数が多いものがあります。 アプリケーションにログインするユーザーごとに 100 行のログ メッセージが生成されると想像してください。 単独なら管理は容易ですが、10 万超のユーザー数分生成されることで、ログの量が大きくなり、ログの効果的な使用をサポートするための専用ツールが必要になります。
クラウドネイティブ アプリケーションでログを記録する
すべてのプログラミング言語には、ログの書き込みを可能にするツールが用意されています。通常、これらのログを書き込むためのオーバーヘッドは低く抑えられています。 ログ ライブラリの多くで、重要度が異なるログを記録する機能が提供され、実行時に調整できます。 たとえば、Serilog ライブラリは、.NET 用の人気のある構造化ログ ライブラリで、次のログ レベルが提供されます。
- "詳細"
- デバッグ
- Information
- 警告
- エラー
- 致命的
これらの異なるログ レベルにより、ログの粒度が提供されます。 アプリケーションが運用環境で正常に機能している場合は、重要なメッセージのみをログに記録するように構成できます。 アプリケーションの動作に問題がある場合は、より詳細なログが収集されるようにログ レベルを上げることができます。 これによって、パフォーマンスとデバッグのしやすさがてんびんにかけられます。
ハイ パフォーマンスのログ ツールと詳細レベルのチューニング機能を利用できると、開発者は頻繁にログを記録するようになります。 多くは、各メソッドのエントリと終了をログに記録するパターンを好みます。 このアプローチはやりすぎに聞こえるかもしれませんが、開発者がログを少なくしたいと思うことはめったにありません。 実際、問題のあるメソッドのログ記録を追加することだけを目的としてデプロイを実行することも珍しくありません。 ログは多すぎてもいけませんが、少なすぎるよりはましです。 この種のログを自動的に提供するために使用できるツールもあります。
クラウドネイティブ アプリでファイルベースのログを使用することには問題があるため、一元化したログを使用することをお勧めします。 ログはアプリケーションによって収集され、中央のログを記録するアプリケーションに送られると、ログのインデックスが作成され、格納されます。 このクラスのシステムは、毎日数十ギガバイトのログを取り込むことができます。
また、多くのサービスにまたがるログを作成する際は、いくつかの標準的なプラクティスに従うことをお勧めします。 たとえば、時間のかかる相互作用の開始時に関連付け ID を生成し、その相互作用に関連するメッセージごとにログを記録すると、関連するすべてのメッセージを検索しやすくなります。 1 つのメッセージを見つけ、関連付け ID を抽出するだけで、関連するすべてのメッセージを見つけることができます。 別の例として、使用する言語やログ ライブラリにかかわらず、すべてのサービスでログ形式が同じであるようにします。 この標準化により、ログの読み取りがはるかに簡単になります。 図 7-4 は、マイクロサービス アーキテクチャで、ワークフローの一部として一元化したログを活用する方法を示しています。
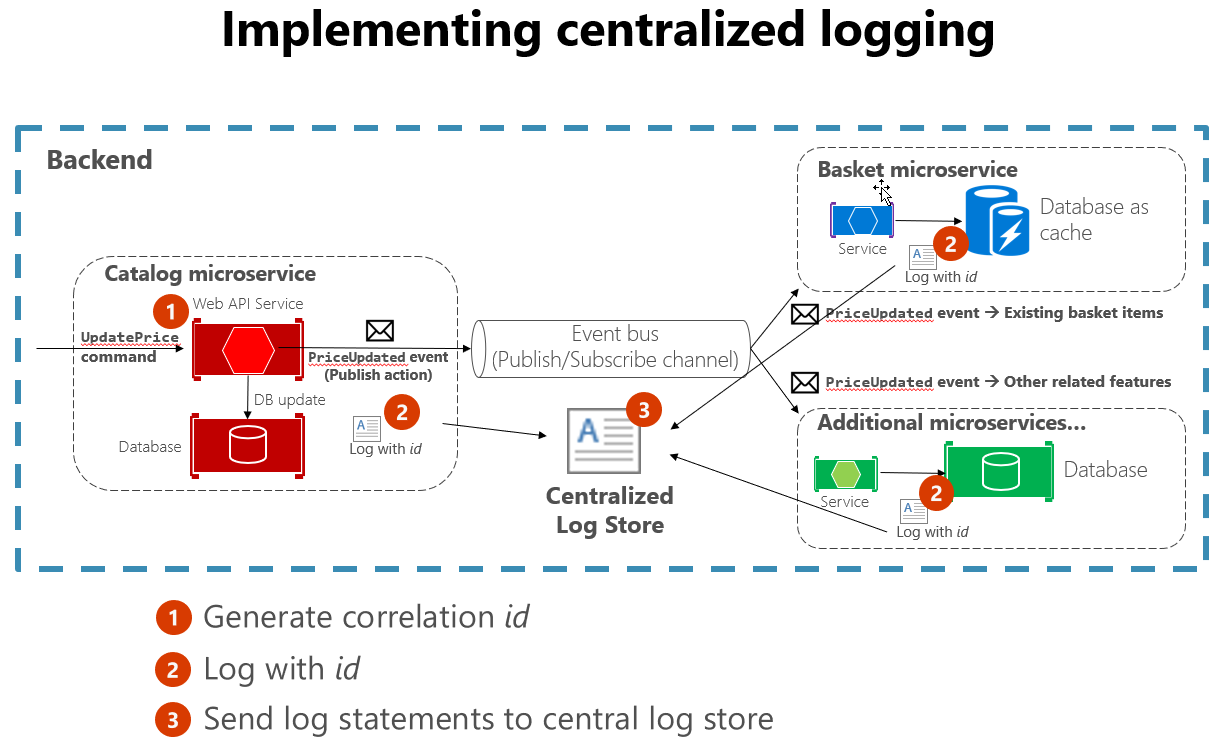 図 7-4。 さまざまなソースのログが一元化したログ ストアに取り込まれる。
図 7-4。 さまざまなソースのログが一元化したログ ストアに取り込まれる。
アプリの正常性に関する潜在的な問題の検出と対応に関する課題
アプリケーションによっては、ミッション クリティカルではないものもあります。 ことによると社内でのみ使用され、問題が発生すると、ユーザーが担当チームに連絡してアプリケーションを再起動できます。 それにひきかえ、顧客は、使用するアプリケーションに対してより高い期待を抱いていることがよくあります。 アプリケーションで問題が発生したとき、ユーザーが問題を見つけるより "前" に、またはユーザーから通知されるより前に把握しておく必要があります。 そうでないと、ご自分のアプリケーションや場合によっては組織を揶揄する怒りの投稿がソーシャル メディアにあふれていることに気付いて初めて問題を知ることになりかねません。
検討が必要になる可能性があるシナリオには、次のものがあります。
- アプリケーションの 1 つのサービスで障害が発生して再起動し続けるため、応答が断続的に遅くなる。
- 1 日のある時間帯にアプリケーションの応答時間が遅くなる。
- 最近のデプロイ後、データベースに対する負荷が 3 倍になった。
適切に実装された監視機能により、問題の原因となる状態について知ることができ、ユーザーに重大な影響を与える前に、基となる状態に対処できます。
クラウドネイティブ アプリを監視する
一元化したログ システムには、純粋なログ以外でテレメトリを収集するための追加の役割を担うものがあります。 データベース クエリの実行時間、Web サーバーの平均応答時間、さらにはオペレーティング システムから報告される CPU 負荷の平均やメモリの負荷などのメトリックを収集できます。 これらのシステムでは、ログと組み合わせて、システム内のノードとアプリケーション全体の正常性を総合的に把握することができます。
監視ツールのメトリック収集機能は、アプリケーション内から手動で行うこともできます。 新規ユーザーのサインアップや発注など、特に関心のあるビジネス フローは、中央監視システムのカウンターをインクリメントするようにインストルメント化することができます。 これにより、監視ツールのロックが解除され、アプリケーションの正常性だけでなく、ビジネスの正常性が監視されます。
特定の統計またはパターンを検索するために、クエリをログ集計ツールで作成して、カスタム ダッシュボードにグラフィカルな形式で表示できます。 チームが大型の壁掛け式ディスプレイに投資して、アプリケーションに関連する統計を順番に表示させることもよくあります。 こうすることで、問題が発生したときに簡単に確認できます。
クラウドネイティブの監視ツールによって、シングルプロセスのモノリシック アプリケーションであるか、分散マイクロサービス アーキテクチャであるかに関係なく、アプリに対するリアルタイムのテレメトリと洞察が提供されます。 これには、アプリからのデータ収集を可能にするツールと、アプリの正常性に関する情報を照会して表示するためのツールが含まれます。
クラウドネイティブ アプリにおける重大な問題への対応に関する課題
アプリケーションの問題に対処する必要がある場合は、適切な担当者に警告する何らかの方法が必要です。 これが、クラウドネイティブ アプリケーションの 3 番目の監視パターンであり、ログと監視に依存します。 問題を診断し、場合によっては監視ツールにフィードできるように、アプリケーションでログを記録する必要があります。 アプリケーション メトリックと正常性データを 1 か所に集約するために監視が必要です。 この設定が完了すると、特定のメトリックが許容可能なレベルを超えたときにアラートをトリガーするルールを作成できます。
一般に、アラートは、緊急の問題をチーム メンバーに通知する適切なアラートが特定の状態によってトリガーされるように、監視階層の最上位に置かれます。 アラートが必要になる可能性があるシナリオには、次のものがあります。
- 1 分間のダウンタイム後、アプリケーションのサービスの 1 つが応答しない。
- 1% を超える要求に対して失敗した HTTP 応答がアプリケーションから返される。
- アプリケーションの主要エンドポイントの平均応答時間が 2000 ミリ秒を超える。
クラウドネイティブ アプリのアラート
監視ツールに対するクエリを作成して、既知のエラー状態を調べることができます。 たとえば、クエリで受信ログを検索して、Web サーバー上の問題を示す HTTP 状態コード 500 を検出することができます。 これらのうちの 1 つでも検出されるとすぐに、送信元サービスの所有者に電子メールまたは SMS を送信して、調査を開始することができます。
ただし、通常、500 エラーが 1 つだけでは、問題が発生したと判断するには十分ではありません。 これは、ユーザーがパスワードを誤入力したか、形式が正しくないデータを入力したことを意味する場合もあります。 平均よりも多い数の 500 エラーが検出されたときにのみ起動するようにアラート クエリを作成することができます。
アラートにおける最も有害なパターンの 1 つは、人が調査できないほど多くのアラートを発することです。 サービスの所有者は、前に調査して問題ないと判断したエラーに対しては、たちまち鈍感になるものです。 その後本物のエラーが発生しても、何百もの偽陽性のノイズに紛れてしまいます。 オオカミ少年の寓話がたびたび子供たちに語られるのは、この危険性を警告するためです。 重要なのは、発するアラートが確実に実際の問題を示していることです。
.NET