Azure ワークロードでの責任ある AI
ワークロード設計における責任ある AI の目的は、AI アルゴリズムの使用が 、透明で包括的であることを保証することです。 適切に設計されたセキュリティの原則は、 コンフィデンシャルと整合性に重点を置いています。 ユーザーのプライバシーを維持し、データを保護し、設計の整合性を保護するためにセキュリティ対策を講じる必要があります。意図しない目的で誤用されるべきではありません。
AI ワークロードでは、多くの場合、不透明なロジックを使用するモデルによって決定が行われます。 ユーザーはシステムの機能を信頼し、意思決定が責任を持って行われると確信する必要があります。 操作、コンテンツ毒性、IP 侵害、製造された応答などの非倫理的な行動は避ける必要があります。
メディア エンターテイメント企業が AI モデルを使用して推奨事項を提供するユース ケースを考えてみましょう。 責任ある AI と適切なセキュリティを実装しないと、不適切なアクターがモデルを制御する可能性があります。 このモデルは、有害な結果につながる可能性のあるメディア コンテンツを推奨する可能性があります。 組織にとって、この動作はブランドの損害、安全でない環境、法的な問題につながる可能性があります。 したがって、システムのライフサイクル全体を通して倫理的な注意を維持することは不可欠であり、交渉不可能です。
倫理的な決定は、人間の成果を念頭に置いてセキュリティとワークロードの管理に優先順位を付ける必要があります。 Microsoft の責任ある AI フレームワークについて理解し原則が設計に反映され、測定されていることを確認します。 この図は、フレームワークの主要な概念を示しています。
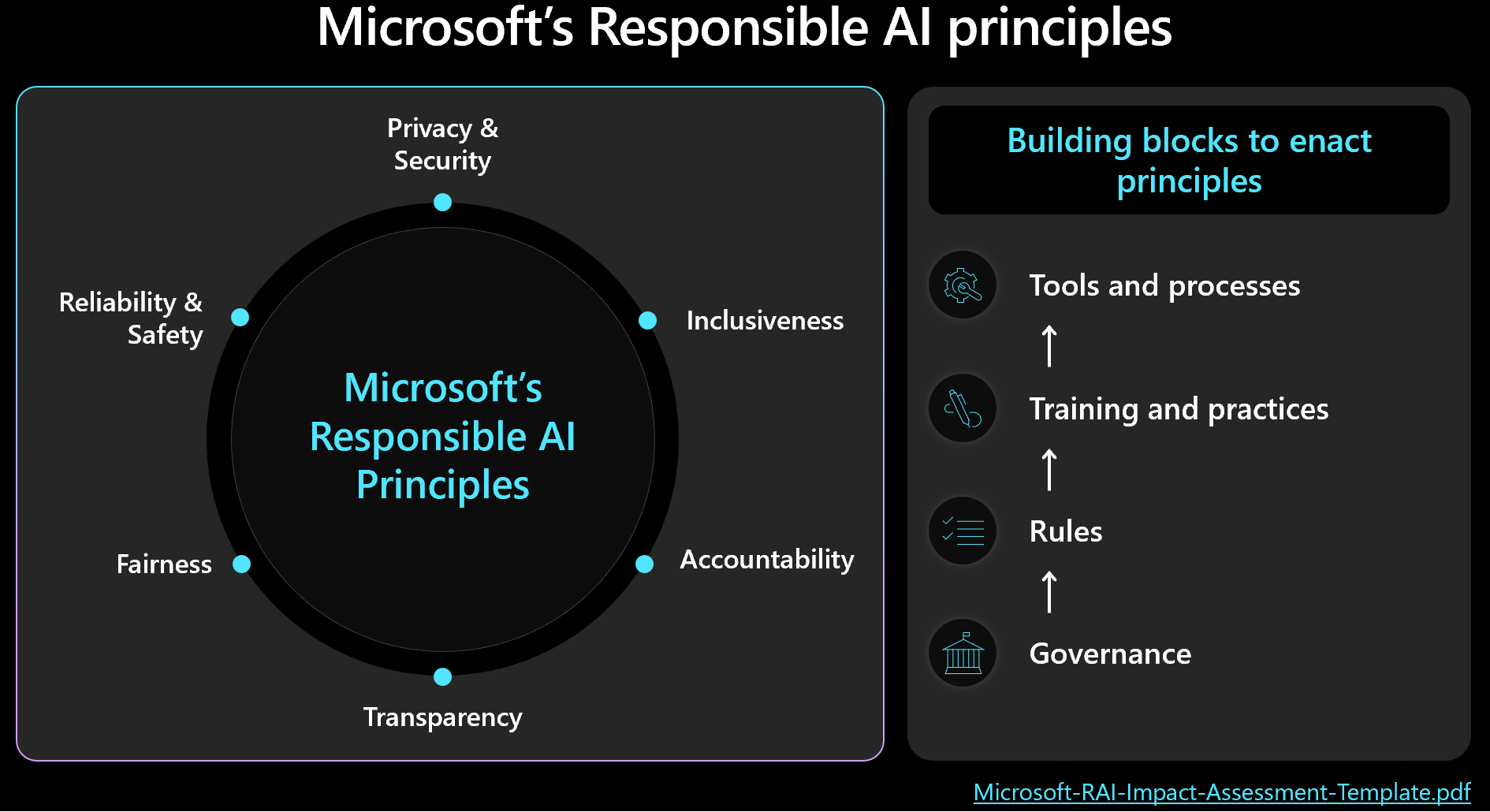
重要
予測の精度と責任ある AI メトリックは、多くの場合相互接続されます。 モデルの精度を向上させると、その公平性と現実との整合性が向上します。 ただし、倫理的 AI は正確性と頻繁に一致しますが、正確性だけではすべての倫理的な考慮事項は含まれません。 これらの倫理的原則を責任を持って検証することが重要です。
この記事では、倫理的な意思決定、ユーザー入力の検証、および安全なユーザー エクスペリエンスの確保に関する推奨事項を示します。 また、ユーザー データが確実に保護されるように、データ セキュリティに関するガイダンスも提供します。
推奨事項
この記事で提供される推奨事項の概要を次に示します。
| 推奨 | 説明 |
|---|---|
| ライフサイクルの各段階で倫理的プラクティスを適用するポリシーを作成。 | ワークロード コンテキストに合わせてカスタマイズされた倫理的要件を明示的に示すチェックリスト項目を含めます。 例としては、ユーザー データの透明性、同意の構成、および "忘れられる権利" を処理するための手順が含まれます。 ▪ 責任ある AI ポリシーを開発する ▪ 責任ある AI ポリシーに関するガバナンスを強化する |
| プライバシーを最大限に高める目的でユーザー データを保護する。 | 必要なものだけを収集し、適切なユーザーの同意を得て収集します。 技術コントロールを適用して、ユーザー プロファイルとそのデータを保護し、そのデータへのアクセスを保護します。 ▪ ユーザー データを倫理的に処理する ▪ 受信データと送信データを取り込む |
| AI の意思決定を明確にし、理解しやすい状態に保つ。 | レコメンデーション アルゴリズムのしくみを明確に説明し、データの使用状況とアルゴリズムの意思決定に関する分析情報をユーザーに提供して、プロセスを確実に理解して信頼できるようにします。 ▪ ユーザー エクスペリエンスを安全に作成する |
責任ある AI ポリシーを開発する
倫理的で責任ある AI の使用状況に対するアプローチを文書化。 ワークロード チームが責任を理解できるように、ライフサイクルの各段階で適用されるポリシーを明示的に指定します。 Microsoft の責任ある AI 標準にはガイドラインが用意されていますが、これらの意味を具体的にコンテキストに対して定義する必要があります。
たとえば、ポリシーには、ユーザー データの透明性と同意の構成に関するメカニズムのチェックリスト項目を含める必要があります。理想的には、ユーザーがデータを含めずにオプトアウトできるようにします。 データ パイプライン、分析、モデル トレーニング、その他のステージはすべて、その選択を尊重する必要があります。 もう 1 つの例として、"忘れられる権利" を処理する手順があります。組織の倫理部門と法務チームに相談して、情報に基づいた意思決定を行います。
ユーザーがプロセスを理解して信頼できるように、データの使用状況とアルゴリズム上の意思決定に関する透過的なポリシーを作成します。 これらの決定を文書化して、将来の訴訟の可能性について明確な履歴を保持します。
倫理的 AI の実装には、研究チーム、ポリシー チーム、エンジニアリング チームの 3 つの重要な役割が含まれます。 これらのチーム間のコラボレーションを運用化する必要があります。 組織に既存のチームがある場合は、その作業を利用します。それ以外の場合は、これらのプラクティスを自分で確立します。
職務の分離について説明責任を持つ:
研究チームは 組織のガイドライン、業界標準、法律、規制、既知のレッド チームの戦術に関するコンサルティングを行い、リスク検出を行います。
ポリシー チームは、親組織と政府の規制のガイドラインを組み込みワークロードに固有のポリシーを開発します。
エンジニアリング チームは ポリシーをプロセスと成果物に実装し、準拠の検証とテストを確実に行います。
各チームはガイドラインを正式に作成しますが、 workload チームは、文書化された独自のプラクティスに対して責任を負う必要があります。 チームは、追加の手順や意図的な逸脱を明確に文書化し、許可される内容にあいまいさがないようにする必要があります。 また、ソリューションの潜在的な欠点や予期しない結果についても透過的にしてください。
責任ある AI ポリシーにガバナンスを適用する
組織と規制のガバナンスと に合わせてワークロードを設計。 たとえば、透明性が組織の要件である場合は、ワークロードへの適用方法を決定します。 設計、ライフサイクル、コード、またはその他のコンポーネントの領域を特定します。このコンポーネントでは、その標準を満たすために透明性機能を導入する必要があります。
必要なガバナンス、アカウンタビリティ、レビュー ボード、およびレポートの義務について理解します。 設計 再設計を回避し、倫理的またはプライバシー上の懸念を軽減するために ガバナンス 協議会によって承認およびサインオフされていることを確認します。 複数の承認レイヤーを通過することが必要な場合があります。 ガバナンスの一般的な構造を次に示します。
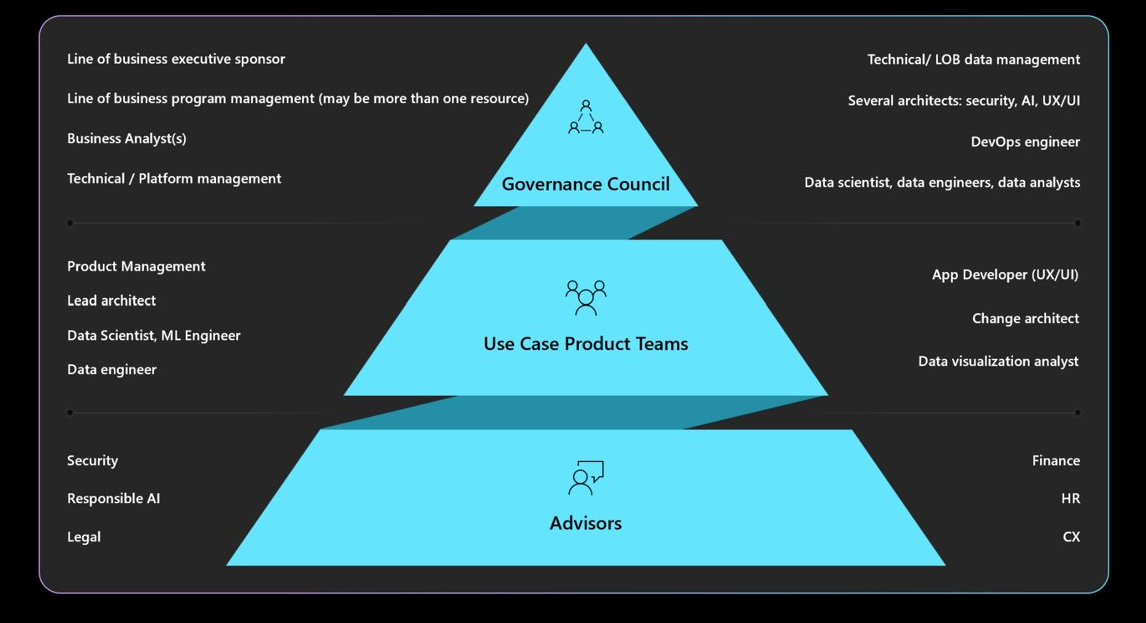
組織のポリシーと承認者については、「クラウド導入フレームワーク: 責任ある AI 戦略を定義する」を参照してください。
ユーザー エクスペリエンスを安全にする
ユーザー エクスペリエンスは、業界のガイドラインに基づく必要があります。 Microsoft Human-AI エクスペリエンス デザイン ライブラリを活用します。このライブラリには、原則が含まれており Microsoft 製品やその他の業界ソースの例を使用して実装の実行と提供を行います。
ユーザーの操作のライフサイクル全体を通して、システムを使用するユーザーの意図、セッション中、およびシステム エラーによる中断に至るワークロードの責任があります。 考慮すべきいくつかのプラクティスを次に示します。
透明度を構築します。 システムがクエリに対する応答をどのように生成したかをユーザーに認識させる。
モデルによって参照されるデータ ソースへのリンクを含めて、情報の起源を示すことでユーザーの信頼度を高めます。 データ設計では、これらのソースがメタデータに含まれていることを確認する必要があります。 取得拡張アプリケーションのオーケストレーターは、検索を実行すると、たとえば 20 個のドキュメント チャンクを取得し、上位 10 個のチャンク (3 つの異なるドキュメントに属する) をコンテキストとしてモデルに送信します。 その後、UI は、モデルの応答を表示するときに、これら 3 つのソース ドキュメントを参照して、透明性とユーザーの信頼を高めることができます。
フロントエンド インターフェイスとバックエンド システム間の仲介役として機能するエージェントを使用する場合、透明性がより重要になります。 たとえば、チケット発行システムでは、オーケストレーション コードはユーザーの意図を解釈し、エージェントに API 呼び出しを行って必要な情報を取得します。 これらの相互作用を公開すると、ユーザーはシステムのアクションを認識できます。
複数のエージェントが関係する自動化されたワークフローの場合は、各ステップを記録するログ ファイルを作成します。 この機能は、エラーの特定と修正に役立ちます。 さらに、ユーザーに意思決定の説明を提供し、透明性を運用化できます。
注意事項
透明性に関する推奨事項を実装する場合は、情報が多すぎるユーザーを圧倒しないようにします。 段階的なアプローチを使用します。ここでは、中断を最小限に抑える UI メソッドから始めます。
たとえば、モデルの信頼度スコアを持つヒントを表示します。 ソース ドキュメントへのリンクなど、ユーザーがクリックして詳細を取得できるリンクを組み込むことができます。 このユーザーが開始するメソッドは、UI を中断を伴わない状態を維持し、ユーザーが選択した場合にのみ追加情報を探すことができます。
フィードバックを収集します。 フィードバック メカニズムを実装します。
各回答の後に広範なアンケートを使用してユーザーを圧倒しないようにします。 代わりに、1 から 5 のスケールで回答の特定の側面に対して、サムの上下や評価システムなどの単純で迅速なフィードバック メカニズムを使用します。 この方法により、侵入することなく詳細なフィードバックが可能になり、時間の経過に伴うシステムの改善に役立ちます。 ユーザーの応答の背後には二次的な理由がある可能性があるため、フィードバックに潜在的な偏りがあることに注意してください。
フィードバック メカニズムを実装すると、データ ストレージが必要なため、アーキテクチャに影響します。 これをユーザー データとして扱い、必要に応じてプライバシー制御のレベルを適用します。
応答フィードバックに加えて、ユーザー エクスペリエンスの有効性に関するフィードバックを収集します。 これを行うには、システムの監視スタックを使用してエンゲージメント メトリックを収集します。
コンテンツの安全対策を運用化する
カスタム ソリューション コード、適切なツール、効果的なセキュリティ プラクティスを使用して、AI ライフサイクルのあらゆる段階にコンテンツの安全性を統合します。 いくつかの戦略を次に示します。
データの匿名化。 データが取り込みからトレーニングまたは評価に移行するにつれて、個人情報の漏洩や生のユーザー データの漏洩を回避するリスクを最小限に抑えるためのチェックが行われます。
Conテント モードration。 要求と応答をリアルタイムで評価し、これらの API に到達できることを確認するコンテンツ セーフティ API を使用します。
脅威を特定して軽減する。 よく知られているセキュリティ プラクティスを AI シナリオに適用します。 たとえば、脅威モデリングを実施し、脅威とその軽減策を文書化します。 Red Team の演習などの一般的なセキュリティ プラクティスは、AI ワークロードに適用できます。 赤色のチームは、有害なコンテンツを生成するためにモデルを操作できるかどうかをテストできます。 これらのアクティビティは、AI 運用に統合する必要があります。
赤いチーム テストの実施については、「 大きな言語モデル (LLM) とそのアプリケーションに対するレッド チーミングの計画を参照してください。
適切なメトリックを使用します。 モデルの倫理的行動の測定に有効な適切なメトリックを使用します。 メトリックは、AI モデルの種類によって異なります。 生成モデルの測定は、回帰モデルには適用されない場合があります。 平均寿命を予測し、結果が保険率に影響を与えるモデルを考えてみましょう。 このモデルのバイアスは倫理的な問題につながる可能性がありますが、その問題はコア メトリック テストの逸脱に起因します。 倫理的メトリックと精度メトリックが相互に結び付くことが多いため、精度を向上すると、倫理的な問題を減らすことができます。
倫理的なインストルメンテーションを追加。 AI モデルの結果は説明可能である必要があります。 トレーニングに使用されるデータ計算される特徴、接地データなど、推論がどのように行われるかを正当化してトレースする必要があります。 差別的 AI では、意思決定を段階的に正当化できます。 ただし、生成モデルの場合、結果の説明は複雑になる可能性があります。 意思決定プロセスを文書化し 潜在的な法的影響に対処し、透明性を提供します。
この説明性の側面は、AI ライフサイクル全体にわたって実装する必要があります。 データクリーニング、系列、選択基準、および処理は、決定を追跡する必要がある重要な段階です。
ツール
Microsoft Purview などのコンテンツの安全性とデータの追跡可能性のためのツールを統合する必要があります。 Azure AI Content Safety API は、コンテンツの安全性テストを容易にするためにテストから呼び出すことができます。
Azure AI Foundry には、モデルの動作を評価するメトリックが用意されています。 詳細については、「 生成 AI の評価と監視メトリックを参照してください。
モデルのトレーニングについては、Azure Machine Learning によって提供される メトリックを確認することをお勧めします。
受信データと送信データを検査する
脱獄などの迅速なインジェクション攻撃は、AI ワークロードにとって一般的な懸念事項です。 この場合、一部のユーザーは意図しない目的でモデルを誤用しようとする可能性があります。 安全を確保するために、データを して攻撃を防ぎ、不適切なコンテンツを除外します。 この分析は、ユーザーの入力とシステムの応答の両方に適用して、受信フローと送信フローの両方に完全な接続テント モードがあることを確認する必要があります。
Azure OpenAI などの複数のモデル呼び出しを行って 1 つのクライアント要求を処理するシナリオでは、すべての呼び出しにコンテンツの安全性チェックを適用すると、コストがかかり、不要になる可能性があります。 セキュリティ サーバー側の責任として維持しながら、アーキテクチャで動作することを中心に検討してください。 アーキテクチャに、特定のバックエンド機能をオフロードするためのゲートウェイがモデル推論エンドポイントの前にあるとします。 このゲートウェイは、バックエンドがネイティブでサポートしていない可能性がある要求と応答の両方について、コンテンツの安全性チェックを処理するように設計できます。 ゲートウェイは一般的なソリューションですが、オーケストレーション レイヤーは、より単純なアーキテクチャでこれらのタスクを効果的に処理できます。 どちらの場合も、必要に応じてこれらのチェックを選択的に適用し、パフォーマンスとコストを最適化できます。
検査は、さまざまな形式をカバーするマルチモーダルにする必要があります。 画像などのマルチモーダル入力を使用する場合は、有害または暴力を受ける可能性のある非表示のメッセージを分析することが重要です。 これらのメッセージはすぐには表示されず、見えないインクと同様に、慎重に検査する必要があります。 この目的には、Content Safety API などのツールを使用します。
プライバシーとデータのセキュリティ ポリシーを適用するには、ユーザー データとグラウンド データを調べて、プライバシー規制に準拠している必要があります。 データがシステムを通過する際に、データがサニタイズまたはフィルター処理されていることを確認します。 たとえば、以前のカスタマー サポートの会話からのデータは、接地データとして機能する可能性があります。 再利用する前にサニタイズする必要があります。
ユーザー データを倫理的に処理する
倫理的プラクティスには、ユーザー データ管理の慎重な処理が含まれます。 これには、データを使用するタイミングと、ユーザー データに依存しないようにするタイミングの把握が含まれます。
ユーザー データを共有しない推論。 分析情報を得るためにユーザー データを他の組織と安全に共有するには、クリアリングハウス モデルを使用。 このシナリオでは、組織は信頼できるサード パーティにデータを提供し、集計データを使用してモデルをトレーニングします。 このモデルは、すべての機関で使用でき、個々のデータ セットを公開することなく、共有された分析情報を得ることができます。 目標は、詳細なトレーニング データを共有せずにモデルの推論機能を使用することです。
多様性と包摂性を高める。 ユーザー データが必要な場合は、不足しているジャンルや作成者など、さまざまなデータを使用して偏りを最小限に抑えます。 ユーザーが新しいさまざまなコンテンツを探索することを奨励する機能を実装します。 使用状況を継続的に監視し、単一のコンテンツ タイプを過剰に表現しないように推奨事項を調整します。
「忘れられる権利」を尊重。 可能な限り、ユーザー データの使用は避けてください。 ユーザー データが熱心に削除されるように、必要な対策を講じて、"忘れられる権利" に準拠していることを確認します。
コンプライアンスを確保するために、システムからユーザー データを削除する要求がある場合があります。 小規模なモデルの場合は、個人情報を除外するデータを使用して再トレーニングすることで、これを実現できます。 複数の小規模な独立してトレーニングされたモデルで構成できる大規模なモデルの場合、プロセスはより複雑になり、コストと労力が大幅に増加します。 このような状況の処理に関する法的および倫理的なガイダンスを求め、責任ある AI ポリシーに含まれていることを確認します(「責任ある AI ポリシーの開発。
責任を持って保持。 データを削除できない場合は、 データ収集に対する明示的なユーザーの同意を保持し 明確なプライバシー ポリシーを提供します。 データの収集と保持は、絶対に必要な場合にのみ行います。 不要になったときにデータを積極的に削除する操作を行います。 たとえば、実用的なチャット履歴をすぐに消去し、保持前に機密データを匿名化します。 保存データに高度な暗号化方法が使用されていることを確認します。
サポートの説明可能性。 説明性の要件をサポートするために、システム内の決定をトレースします。 レコメンデーション アルゴリズムのしくみを明確に説明し、ユーザーに特定のコンテンツが推奨される理由に関する分析情報を提供します。 目標は、AI ワークロードとその結果が透過的で正当であることを確認し、意思決定の方法、使用されたデータ、モデルのトレーニング方法を詳しく説明することです。
ユーザー データの暗号化。 入力データは、ユーザーがデータを入力した時点から、データ処理パイプラインのすべての段階で暗号化する必要があります。 これには、あるポイントから別のポイントに移動する際にデータが格納され、必要に応じて推論中にデータが含まれます。 セキュリティと機能のバランスを取りますが、ライフサイクル全体を通じてデータをプライベートに することを目指します。
暗号化手法の詳細については、「 アプリケーションの設計」を参照してください。
堅牢なアクセス制御を提供します。 複数の種類の ID がユーザー データにアクセスする可能性があります。 ユーザーとシステム間の通信をカバーする、コントロール プレーンとデータ プレーンの両方にロールベースのアクセス制御 (RBAC) を実装します。
また、プライバシーを保護するために適切なユーザーセグメント化を維持します。 たとえば、Copilot for Microsoft 365 では、ユーザーの特定のドキュメントや電子メールに基づいて回答を検索して提供し、そのユーザーに関連するコンテンツのみにアクセスできるようにします。
アクセス制御の適用については、「 アプリケーションの設計」を参照してください。
サーフェス領域を減らす。 適切に設計されたフレームワークセキュリティの柱の基本的な戦略は、攻撃対象領域を最小限に抑え、リソースを強化することです。 この戦略は、API エンドポイントを厳密に制御し、重要なデータのみを公開し、応答で余分な情報を回避することによって、標準のエンドポイント セキュリティ プラクティスに適用する必要があります。 設計の選択は、柔軟性と制御のバランスを取る必要があります。
匿名エンドポイントがないことを確認します。 一般に、クライアントに必要以上の制御を与えないようにします。 ほとんどのシナリオでは、実験環境を除き、クライアントはハイパーパラメーターを調整する必要はありません。 仮想エージェントとの対話などの一般的なユース ケースでは、クライアントは不要な制御を制限することでセキュリティを確保するために重要な側面のみを制御する必要があります。
詳細については、「 アプリケーションの設計」を参照してください。