Azure Backup を使用して Azure Linux VM で Oracle Database をバックアップおよび復旧する
適用対象: ✔️ Linux VM
この記事では、Azure Backup を使用して、Oracle Database ファイルと Oracle 高速リカバリ領域を含む、仮想マシン (VM) ディスクのディスク スナップショットを作成する方法について説明します。 Azure Backup を使用すると、バックアップとして適した完全なディスク スナップショットを作成できます。これらは Recovery Services コンテナーに格納されます。
また、Azure Backup は、アプリケーション整合性バックアップを提供することで、追加の修正なしでデータを復元できるようにもします。 アプリケーション整合性バックアップは、ファイル システムと Oracle Automatic Storage Management (ASM) データベースの両方で機能します。
アプリケーション整合性データの復元により復元時間が短縮され、迅速に実行状態に戻ることができます。 復元後も Oracle Database の復旧は必要です。 別の Azure ファイル共有にキャプチャされ格納されている、Oracle のアーカイブされた再実行ログ ファイルを使用して復旧を容易にします。
この記事では、次のタスクについて説明します。
- アプリケーション整合性バックアップを使用してデータベースをバックアップする。
- 復旧ポイントからデータベースを復元および復旧する。
- 復旧ポイントから VM を復元する。
前提条件
Azure Cloud Shell で Bash 環境を使用します。 詳細については、「Azure Cloud Shell の Bash のクイックスタート」を参照してください。

CLI リファレンス コマンドをローカルで実行する場合、Azure CLI をインストールします。 Windows または macOS で実行している場合は、Docker コンテナーで Azure CLI を実行することを検討してください。 詳細については、「Docker コンテナーで Azure CLI を実行する方法」を参照してください。
ローカル インストールを使用する場合は、az login コマンドを使用して Azure CLI にサインインします。 認証プロセスを完了するには、ターミナルに表示される手順に従います。 その他のサインイン オプションについては、Azure CLI でのサインインに関するページを参照してください。
初回使用時にインストールを求められたら、Azure CLI 拡張機能をインストールします。 拡張機能の詳細については、Azure CLI で拡張機能を使用する方法に関するページを参照してください。
az version を実行し、インストールされているバージョンおよび依存ライブラリを検索します。 最新バージョンにアップグレードするには、az upgrade を実行します。
バックアップと復旧プロセスを実行するには、最初にインストール済みの Oracle Database 12.1 以降のインスタンスがある Linux VM を作成する必要があります。
「Azure VM に Oracle Database インスタンスを作成する」の手順に従って 、Oracle Database インスタンスを作成します。
環境の準備
環境を準備するには、次の手順に従います。
VM に接続します
VM で Secure Shell (SSH) セッションを作成するには、次のコマンドを使用します。
<publicIpAddress>を VM のパブリック アドレスの値で置き換えます。ssh azureuser@<publicIpAddress>ルート ユーザーに切り替えます。
sudo su -oracleユーザーを /etc/sudoers ファイルに追加します。echo "oracle ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
Oracle のアーカイブされた再実行ログ ファイル用に Azure Files ストレージを設定する
Oracle Database インスタンスのアーカイブされた再実行ログ ファイルは、データベースの復旧において重要な役割を果たします。 これらのファイルには、過去に作成されたデータベース スナップショットをロールフォワードするために必要となる、コミット済みのトランザクションが保存されています。
データベースが ARCHIVELOG モードの場合、オンラインの再実行ログファイルがいっぱいになって切り替わると、その内容がアーカイブされます。 バックアップと合わせて、これはデータベースが失われたときにポイントインタイム リストアを実現するために必要となります。
Oracle には、再実行ログファイルを様々な場所にアーカイブする機能が用意されています。 業界のベスト プラクティスは、これらの場所の少なくとも 1 つをリモート ストレージにすることです。それをホスト ストレージから分離して、独立したスナップショットを使用して保護するためです。 Azure Files は、これらの要件を満たしています。
Azure ファイル共有とは、サーバー メッセージ ブロック (SMB) プロトコルまたはネットワーク ファイル システム (NFS) プロトコルを使用して、Linux VM または Windows VM に通常のファイル システム コンポーネントとしてアタッチするストレージです。 アーカイブ ログ ストレージとして使用するために (SMB 3.0 プロトコルを使用して) Linux 上に Azure ファイル共有を設定するには、「 Linux に SMB Azure ファイル共有をマウントする」を参照してください。 設定が完了したら、このガイドに戻り、残りのすべての手順を完了します。
データベースを準備する
このプロセスのこの部分では、Azure VM に Oracle Database インスタンスを作成する」に従ったと想定します。 その結果、次のような影響が出ています。
vmoracle19cという名前の VM 上で実行されているoratest1という名前の Oracle インスタンスがある。- 標準の Oracle 構成ファイル /etc/oratab に依存する標準の Oracle
oraenvスクリプトを使用してシェル セッションの環境変数を設定している。
VM 上の各データベースに対して次の手順を実行します。
oracleユーザーに切り替えます。sudo su - oracleoraenvスクリプトを実行して環境変数ORACLE_SIDを設定します。ORACLE_SIDの名前を入力するように求められます。. oraenvデータベースのアーカイブ ログ ファイルのもう 1 つの保存先として Azure ファイル共有を追加します。
この手順では、Linux VM に Azure ファイル共有を構成してマウントしたことを前提としています。 VM にインストールされているデータベースごとに、データベース セキュリティ識別子 (SID) を名前とするサブディレクトリを作成します。
この例では、マウント ポイント名は
/backupで、SID はoratest1です。 そのため、サブディレクトリ/backup/oratest1を作成し、所有権をoracleユーザーに変更します。/backup/SIDを自分のマウント ポイント名とデータベース SID に置き換えてください。sudo mkdir /backup/oratest1 sudo chown oracle:oinstall /backup/oratest1データベースに接続します。
sqlplus / as sysdbaデータベースがまだ実行されていない場合は、起動します。
SQL> startupデータベースの最初のアーカイブ ログの保存先を、前に作成したファイル共有ディレクトリに設定します。
SQL> alter system set log_archive_dest_1='LOCATION=/backup/oratest1' scope=both;データベースの回復ポイントの目標 (RPO) を定義します。
一貫した RPO を実現するには、オンライン再実行ログ ファイルをアーカイブする頻度を考慮してください。 以下の要因によって、頻度が制御されます。
- オンライン再実行ログファイルのサイズ。 オンライン ログ ファイルは、空き領域がなくなると切り替えられてアーカイブされます。 オンライン ログ ファイルが大きいほど、空き領域がなくなるまでの時間が長くなります。 時間が長くなる分、アーカイブ生成の頻度が減少します。
ARCHIVE_LAG_TARGETパラメーターの設定は、現在のオンライン ログ ファイルを切り替えてアーカイブするまでに許容される最大秒数を制御します。
切り替えとアーカイブの頻度と、それに伴うチェックポイント操作を最小限に抑えるために、Oracle のオンライン再実行ログファイルは一般的に大きなサイズ (例えば 1024 M、4096M、8192M など) になっています。 ビジー状態のデータベース環境では、ログは数秒または数分ごとに切り替わってアーカイブされる可能性が依然として高くなります。 それ程アクティブではないデータベースでは、最新のトランザクションがアーカイブされるまでに数時間あるいは数日かかる場合があり、アーカイブの頻度は大幅に減少します。
一貫性のある RPO を確保するように
ARCHIVE_LAG_TARGETを設定することをお勧めします。ARCHIVE_LAG_TARGETの値は 5 分 (300 秒) に設定することが適切です。 そうすると、すべてのデータベース復旧操作で必ず障害から5分以内の時点に復旧できます。ARCHIVE_LAG_TARGETを設定するには、次のコマンドを実行します。SQL> alter system set archive_lag_target=300 scope=both;RPO ゼロで Azure に可用性の高い Oracle Database インスタンスをデプロイする方法について理解を深めたい場合は、「Oracle Database のリファレンス アーキテクチャ」を参照してください。
データベースが、オンライン バックアップを有効にするためのアーカイブ ログ モードになっていることを確認します。
最初にログ アーカイブの状態を確認します。
SQL> SELECT log_mode FROM v$database; LOG_MODE ------------ NOARCHIVELOGNOARCHIVELOGモードになっている場合は、次のコマンドを実行します。SQL> SHUTDOWN IMMEDIATE; SQL> STARTUP MOUNT; SQL> ALTER DATABASE ARCHIVELOG; SQL> ALTER DATABASE OPEN; SQL> ALTER SYSTEM SWITCH LOGFILE;テーブルを作成して、バックアップおよび復元操作をテストします。
SQL> create user scott identified by tiger quota 100M on users; SQL> grant create session, create table to scott; SQL> connect scott/tiger SQL> create table scott_table(col1 number, col2 varchar2(50)); SQL> insert into scott_table VALUES(1,'Line 1'); SQL> commit; SQL> quit
Azure Backup を使用してデータをバックアップする
Azure Backup サービスは、データをバックアップし、それを Microsoft Azure クラウドから回復するためのソリューションを提供します。 Azure Backup では、元のデータが誤って破壊されることを防ぐために、独立して分離されたバックアップを提供しています。 バックアップは Recovery Services コンテナーに格納され、復旧ポイントの管理が組み込まれているため、必要に応じて復元できます。
このセクションでは、Azure Backup を使用して、実行中の VM と Oracle Database インスタンスのアプリケーション整合性スナップショットを作成します。 このデータベースはバックアップ モードになるため、Azure Backup で VM ディスクのスナップショットを作成している間に、トランザクション上一貫性のあるオンライン バックアップを実行できます。 スナップショットはストレージの完全なコピーであり、増分または書き込み時コピーのスナップショットではありません。 これは、データベースの復元元として効果的なバックアップ メディアです。
Azure Backup のアプリケーション整合性スナップショットを使用する利点は、データベースの大きさに関わらず迅速に作成できる点です。 スナップショットは作成が完了したら即時に復旧操作に利用できます。スナップショットが Recovery Services コンテナーに転送されるのを待つ必要はありません。
Azure Backup を使用してデータベースをバックアップするには、次の手順を実行します。
- Azure Backup フレームワークについて理解する。
- アプリケーション整合性バックアップ用に環境を準備します。
- アプリケーション整合性バックアップを設定します。
- VM のアプリケーション整合性バックアップをトリガーします。
Azure Backup フレームワークを理解する
Azure Backup サービスは、さまざまなアプリケーションのための Windows VM および Linux VM のバックアップ中にアプリケーション整合性を確保するためのフレームワークを提供します。 このフレームワークでは、ディスクのスナップショットを取得する前に、事前スクリプトを呼び出してアプリケーションを休止させる必要があります。 スナップショットの完了後、事後スクリプトを呼び出してアプリケーションの凍結を解除します。
Microsoft ではこのフレームワークを拡張し、Azure Backup サービスにおいて特定のアプリケーション用にパッケージ化された事前スクリプトと事後スクリプトを提供するようにしました。 これらの事前スクリプトと事後スクリプトは既に Linux イメージに読み込まれているため、インストールの必要はありません。 アプリケーションに名前を付けるだけで、Azure Backup が関連するスクリプトを自動的に呼び出します。 Microsoft がパッケージ化された事前スクリプトと事後スクリプトの管理を行うため、スクリプトのサポート、所有権、有効性について安心できます。
現在のところ、拡張フレームワークでサポートされているアプリケーションは Oracle 12.x 以降と MySQL です。 詳細については、「マネージド Azure VM バックアップのサポート マトリックス」を参照してください。
Azure Backup 用の独自のスクリプトを作成して、12.x 以前のデータベースで使用することもできます。 スクリプトの例は GitHub から入手できます。
バックアップを実行するたびに、拡張フレームワークは、VM にインストールされているすべての Oracle Database インスタンス上で事前スクリプトと事後スクリプトを実行します。 workload.conf ファイル内の configuration_path パラメーターは、Oracle /etc/oratab ファイル (または oratab 構文に従うユーザー定義ファイル) の場所を示します。 詳細については、「アプリケーション整合性バックアップを設定する」を参照してください。
Azure Backup は、configuration_path が示す場所にあるファイルに一覧表示されている各データベースに対して事前スクリプトと事後スクリプトを実行します。 例外は、# で始まる行 (コメントとして扱われる)、または+ASM で始まる行 (Oracle ASM インスタンス) です。
Azure Backup 拡張フレームワークは、ARCHIVELOG モードで動作する Oracle Database インスタンスのオンライン バックアップを作成します。 事前スクリプトと事後スクリプトでは、ALTER DATABASE BEGIN と END BACKUP のコマンドを使用してアプリケーションの一貫性を実現します。
データベースのバックアップに一貫性を持たさせるには、NOARCHIVELOG モードのデータベースは、スナップショットが開始される前にクリーンにシャットダウンする必要があります。
アプリケーション整合性バックアップ用に環境を準備する
Oracle Database では、最小限の権限を使用して職務を分離するために、ジョブの役割の分離が採用されています。 個別のオペレーティング システム (OS) グループを個別のデータベース管理ロールに関連付けます。 ユーザーには、OS グループのメンバーシップに応じて異なるデータベース権限が付与されます。
SYSBACKUP データベース ロール (汎用名 OSBACKUPDBA) は、データベースのバックアップ操作を実行するための限定的な権限を提供します。 Azure Backup にはこれが必要です。
Oracle のインストール時に、SYSBACKUP ロールに関連する backupdba をOS グループ名として使用することをお勧めします。 ただし、任意の名前を使用できるため、先に Oracle SYSBACKUP ロールを表す OS グループの名前を決定しておく必要があります。
oracleユーザーに切り替えます。sudo su - oracleOracle 環境を設定します。
export ORACLE_SID=oratest1 export ORAENV_ASK=NO . oraenvOracle
SYSBACKUPロールを表す OS グループの名前を決定します。grep "define SS_BKP" $ORACLE_HOME/rdbms/lib/config.c出力は次の例のようになります。
#define SS_BKP_GRP "backupdba"出力にある二重引用符で囲まれた値が、Oracle
SYSBACKUPロールが外部で認証されている Linux OS グループの名前です。 この例ではbackupdbaです。 実際の値をメモしておきます。次のコマンドを実行して、この OS グループが存在することを確認します。
<group name>は、前のコマンドが返した値 (引用符なし) に置き換えてください。grep <group name> /etc/group出力は次の例のようになります。
backupdba:x:54324:oracle重要
出力が手順 3 で取得した Oracle OS グループの値と一致しない場合は、次のコマンドを使用して、Oracle
SYSBACKUPロールを表す OS グループを作成します。<group name>を、手順 3 で取得したグループ名に置き換えます。sudo groupadd <group name>前の手順で検証または作成した OS グループに属する新しいバックアップ ユーザーを
azbackupという名前で作成します。<group name>を検証済みのグループ名に置き換えます。 このユーザーが ASM ディスクを開けられるよう、oinstallグループにも追加します。sudo useradd -g <group name> -G oinstall azbackup新しいバックアップ ユーザーの外部認証を設定します。
バックアップ ユーザー
azbackupは、パスワードの入力が求められないようにするため、外部認証を使用してデータベースにアクセスできる必要があります。 このアクセスを可能にするには、azbackupを介して外部で認証されるデータベース ユーザーを作成する必要があります。 データベースではユーザー名にプレフィックスが使用されます。このプレフィックスを検索する必要があります。VM にインストールされている各データベースに対し、次の手順を実行します。
SQL Plus を使用してデータベースにサインインし、外部認証の既定の設定を確認します。
sqlplus / as sysdba SQL> show parameter os_authent_prefix SQL> show parameter remote_os_authent出力は次の例のようになります。ここでは、
ops$がデータベース ユーザー名のプレフィックスとして表示されています。NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ os_authent_prefix string ops$ remote_os_authent boolean FALSEazbackupユーザーの外部認証用にデータベース ユーザーops$azbackupを作成し、SYSBACKUP権限を付与します。SQL> CREATE USER ops$azbackup IDENTIFIED EXTERNALLY; SQL> GRANT CREATE SESSION, ALTER SESSION, SYSBACKUP TO ops$azbackup;
GRANTステートメントの実行時にエラーORA-46953: The password file is not in the 12.2 formatが発生した場合は、次の手順に従って、orapwd ファイルを 12.2 形式に移行します。 VM 上のすべての Oracle Database インスタンスに対して、次の手順を実行します。SQL Plus を終了します。
古い形式のパスワード ファイルを新しい名前に変えます。
パスワード ファイルを移行します。
古いファイルを削除します。
次のコマンドを実行します。
mv $ORACLE_HOME/dbs/orapworatest1 $ORACLE_HOME/dbs/orapworatest1.tmp orapwd file=$ORACLE_HOME/dbs/orapworatest1 input_file=$ORACLE_HOME/dbs/orapworatest1.tmp rm $ORACLE_HOME/dbs/orapworatest1.tmpSQL Plus で
GRANT操作を再実行します。
バックアップ メッセージをデータベース警告ログに記録するストアド プロシージャを作成します。 VM にインストールされている各データベースに対し、以下のコードを実行します。
sqlplus / as sysdba SQL> GRANT EXECUTE ON DBMS_SYSTEM TO SYSBACKUP; SQL> CREATE PROCEDURE sysbackup.azmessage(in_msg IN VARCHAR2) AS v_timestamp VARCHAR2(32); BEGIN SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD HH24:MI:SS') INTO v_timestamp FROM DUAL; DBMS_OUTPUT.PUT_LINE(v_timestamp || ' - ' || in_msg); SYS.DBMS_SYSTEM.KSDWRT(SYS.DBMS_SYSTEM.ALERT_FILE, in_msg); END azmessage; / SQL> SHOW ERRORS SQL> QUIT
アプリケーション整合性バックアップを設定する
ルート ユーザーに切り替えます。
sudo su -/etc/azure フォルダーがあるかどうかを確認します。 存在しない場合は、アプリケーション整合性バックアップ用の作業ディレクトリを作成します。
if [ ! -d "/etc/azure" ]; then mkdir /etc/azure fiフォルダー内に workload.conf ファイルがあるかどうかを確認します。 存在しない場合は、このファイルを /etc/azure ディレクトリに作成し、以下の内容を指定します。 コメントは必ず
[workload]で始まる必要があります。 ファイルが既に存在する場合は、以下の内容になるようにフィールドを編集するだけです。 そうでない場合は、次のコマンドを実行すると、ファイルが作成され、内容が設定されます。echo "[workload] workload_name = oracle configuration_path = /etc/oratab timeout = 90 linux_user = azbackup" > /etc/azure/workload.confworkload.conf ファイルでは、次の形式が使用されます。
workload_nameパラメーターは、データベース ワークロードの種類を示します。 この場合、パラメーターをOracleに設定すると、Azure Backup は Oracle Database インスタンスに対して正しい事前スクリプトと事後スクリプト (整合性コマンド) を実行できます。timeoutパラメーターは、各データベースでのストレージ スナップショット完了までの最大許容時間を秒単位で示します。linux_userパラメーターは、データベースの休止操作を実行するために Azure Backup が使用する、Linux ユーザー アカウントを示します。 このユーザー (azbackup) は、以前に作成しました。configuration_pathパラメーターは、VM 上のテキスト ファイルへの絶対パス名を示します。 各行には、VM で実行されているデータベース インスタンスが表示されます。 これは通常、データベースのインストール時に Oracle によって生成される /etc/oratab ファイルですが、任意の名前の任意のファイルを指定できます。 これは次の書式規則に従う必要があります。- テキスト ファイルである。 各フィールドはコロン文字で区切られている (
:)。 - 各行の最初のフィールドは、
ORACLE_SIDインスタンスの名前である。 - 各行の 2 番目のフィールドが、その
ORACLE_SIDインスタンスのORACLE_HOMEの絶対パス名である。 - 最初の 2 つのフィールドの後のテキストはすべて無視されます。
- 行がポンド記号 (
#) で始まる場合、行全体がコメントとして無視されます。 - 最初のフィールドが
+ASMを値とする場合、これは Oracle ASM インスタンスを意味するため無視されます。
- テキスト ファイルである。 各フィールドはコロン文字で区切られている (
VM のアプリケーション整合性バックアップをトリガーする
Azure portal で、rg-oracle リソース グループに移動し、vmoracle19c 仮想マシンを選択します。
[バックアップ] ペインで、次の操作を行います。
- [Recovery Services コンテナー] で、[新規作成] を選択します。
- コンテナーの名前には、myVault を使用します。
- [リソース グループ] で、rg-oracle を選択します。
- [バックアップ ポリシーの選択] では、 [(新規) DailyPolicy] を使用します。 バックアップの頻度または保持期間を変更する場合は、代わりに [新しいポリシーの作成] を選択します。
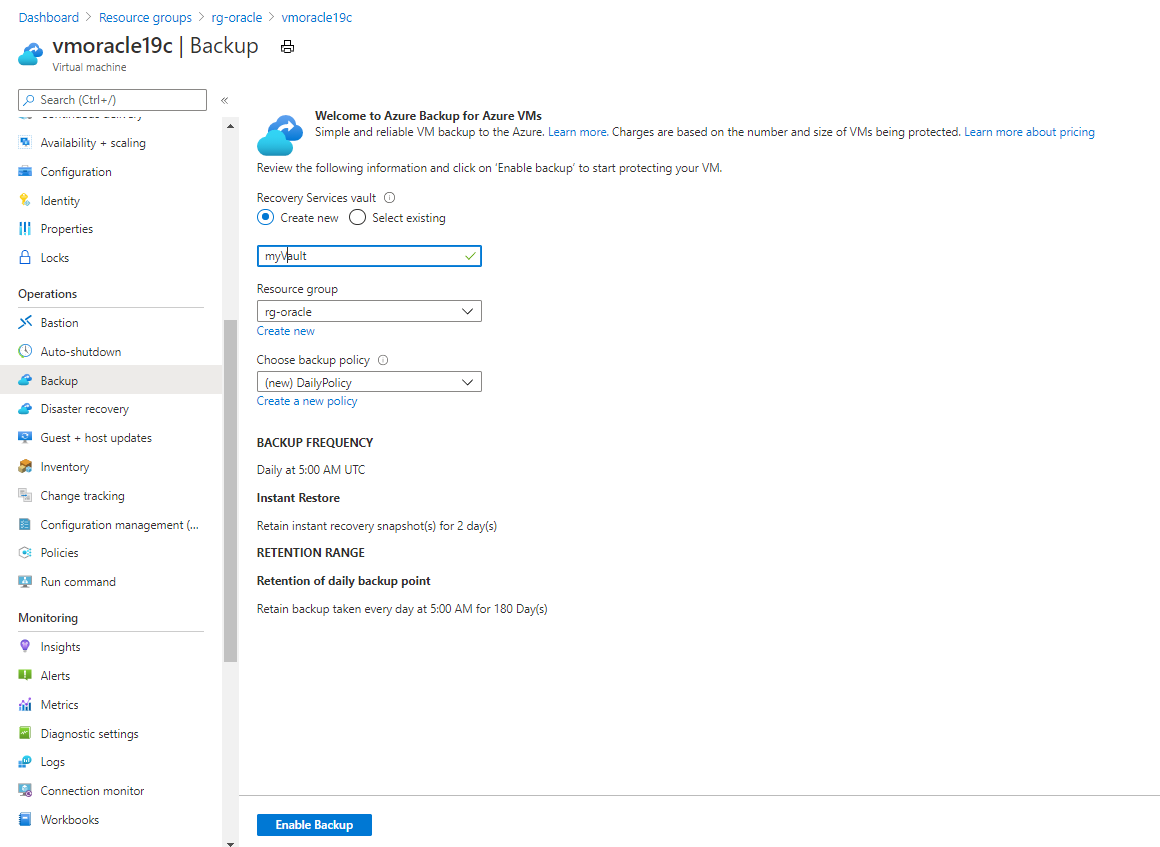
[バックアップの有効化] を選択します。
スケジュールされた時間に達するまでバックアップ プロセスは開始されません。 即時バックアップをセットアップするには、次の手順を完了します。
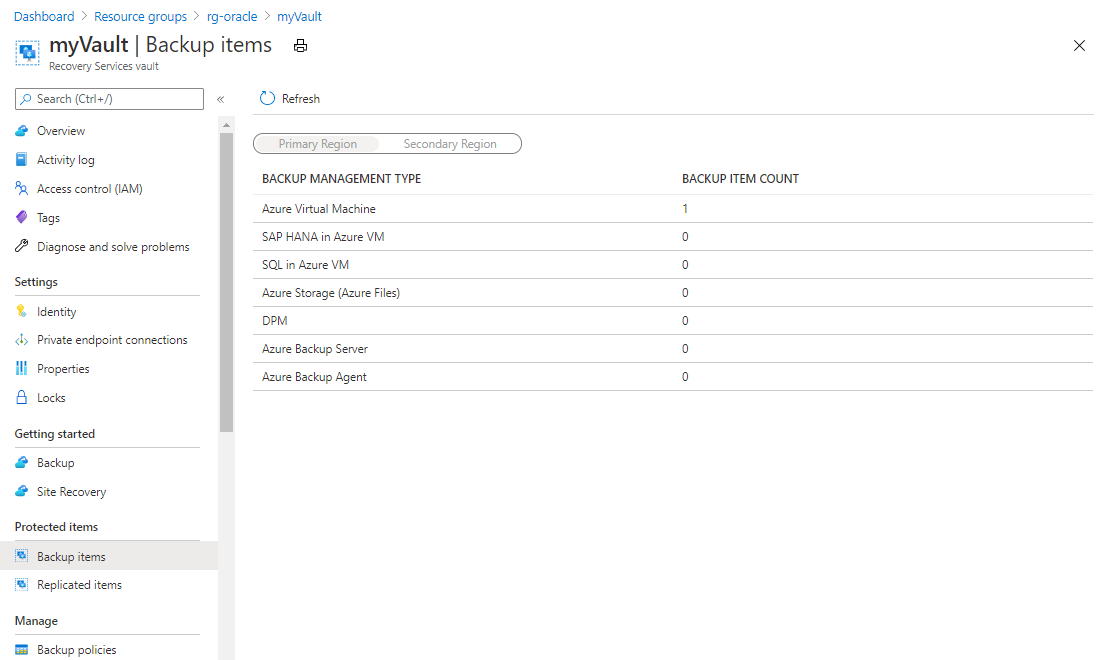
リソース グループ ページで、新しく作成した myVault という名前の Recovery Services コンテナーを選択します。 場合によっては、ページを更新して表示させる必要があります。
[myVault のバックアップ項目] ペインの [バックアップ項目数] の下で、バックアップ項目の数を選択します。
[バックアップ項目 (Azure 仮想マシン)] ペインで、省略記号 (...) ボタンを選択し、 [今すぐバックアップ] を選択します。
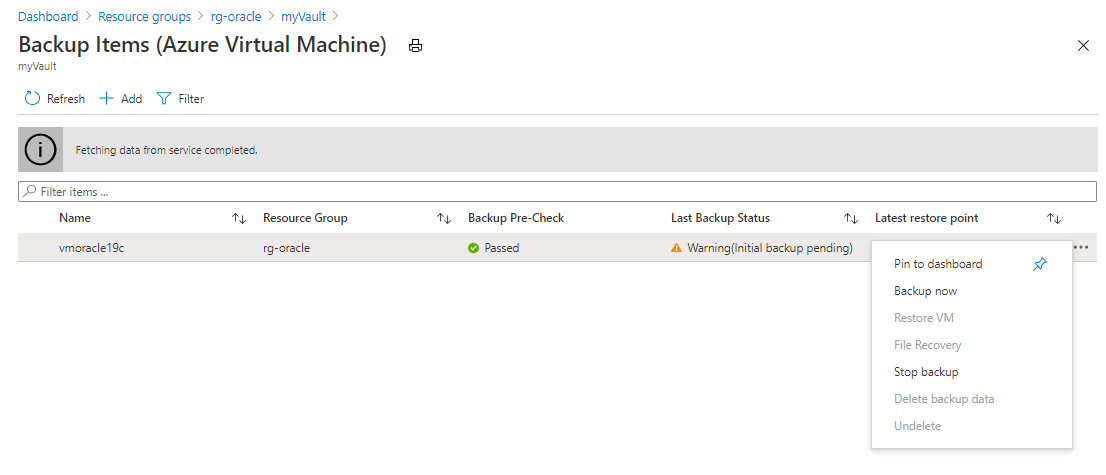
[バックアップの保持期間] の既定値をそのまま使用し、[OK] を選択します。 バックアップ プロセスが完了するまで待ってから、
バックアップ ジョブの状態を表示するには、[バックアップ ジョブ] を選択します。

バックアップ ジョブを選択すると、ジョブの状態の詳細が表示されます。
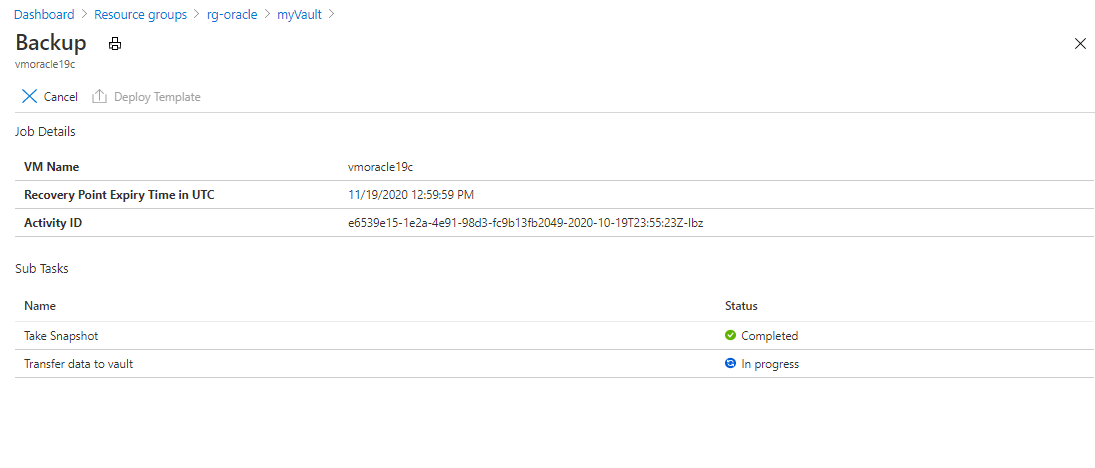
スナップショット実行の所要時間は数秒間ですが、ボールトへの転送に時間がかかる場合があります。 転送が完了するまで、バックアップ ジョブは完了しません。
アプリケーション整合性バックアップの場合は、 /var/log/azure/Microsoft.Azure.RecoveryServices.VMSnapshotLinux/extension.log にあるログ ファイル内のエラーに対処します。
VM を復元する
VM 全体を復元することは、選択した復元ポイントから VM およびそれに接続されているディスクを新しい VM に復元することを意味します。 このアクションでは、VM 上で実行されるすべてのデータベースも復元されます。 その後、各データベースを復旧する必要があります。
VM 全体を復元するには、次の手順を実行します。
VM を復元する場合、次の 2 つの主な選択肢があります。
- バックアップの生成元の VM を復元する。
- バックアップの生成元の VM に影響を与えずに新しい VM を復元 (複製) する。
この演習の最初の手順 (VM の停止、削除、復旧) では、最初のユース ケースをシミュレートします。
VM を停止して削除する
Azure portal で、vmoracle19c 仮想マシンに移動して、[停止] を選択します。
仮想マシンが実行中ではなくなったら、[削除] を選択し、[はい] を選択します。
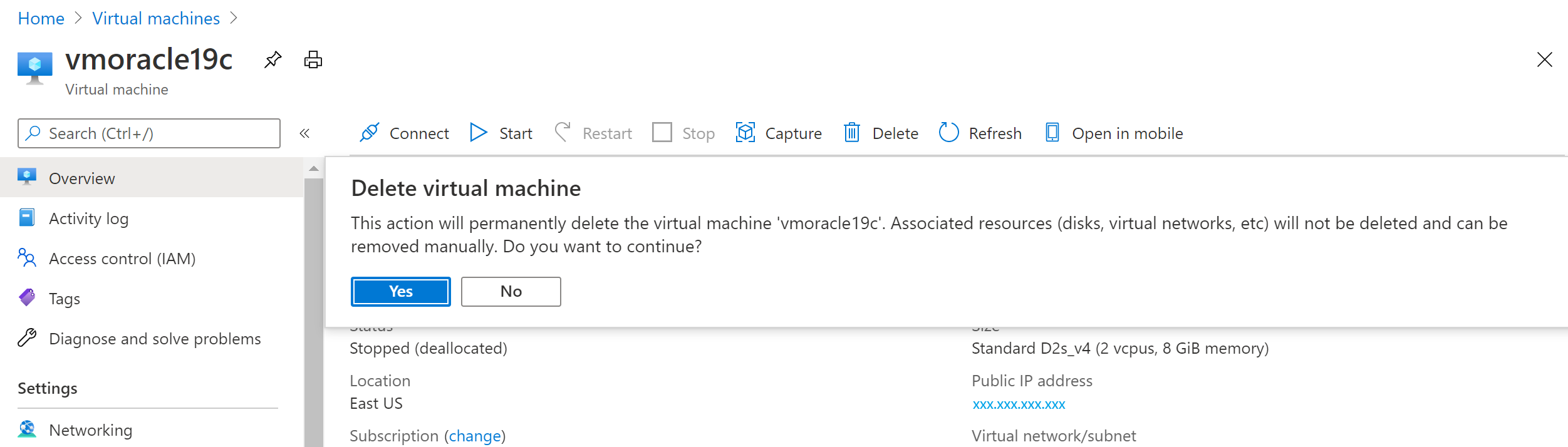
VM を復旧する
Azure portal でステージング用のストレージ アカウントを作成します。
Azure portal で、[+ リソースの作成] を選択し、[ストレージ アカウント] を検索して選択します。
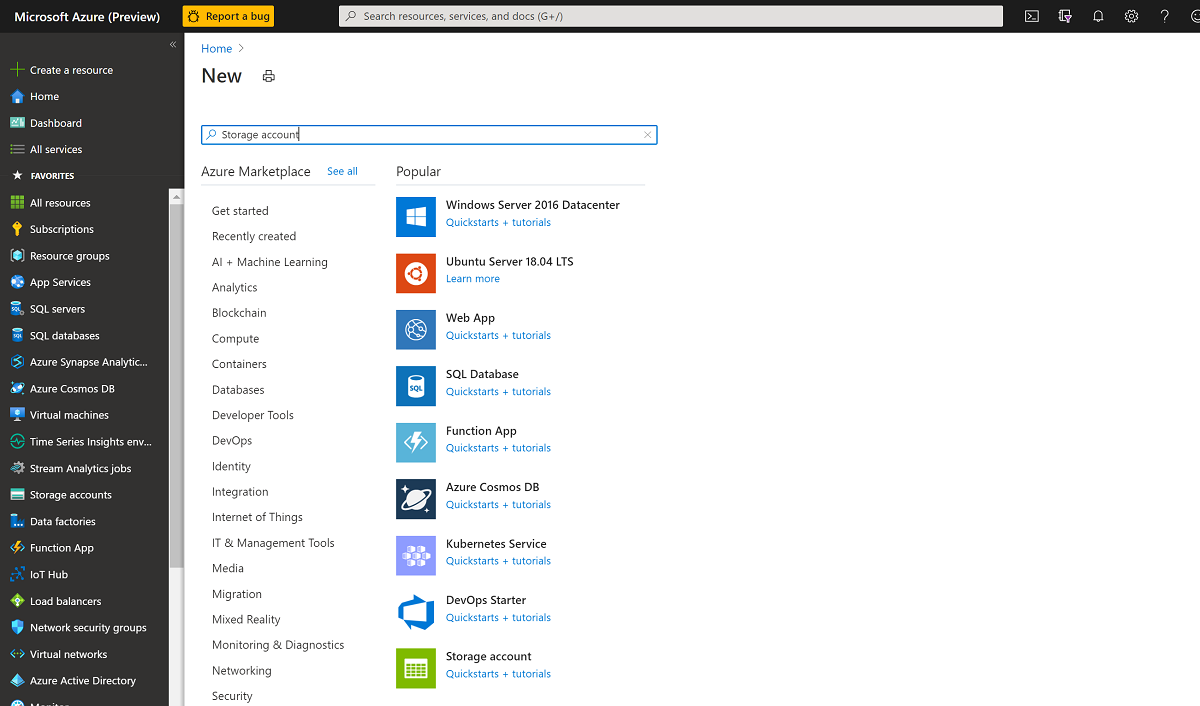
[ストレージ アカウントの作成] ペインで次の操作を行います。
- [リソース グループ] では、既存のリソース グループである rg-oracle を選択します。
- [ストレージ アカウント名] では、「oracrestore」と入力します。
- [場所] が、リソース グループ内の他のすべてのリソースと同じリージョンに設定されていることを確認します。
- [パフォーマンス] を [Standard] に設定します。
- [アカウントの種類] では、[StorageV2 (汎用 v2)] を選択します。
- [レプリケーション] には [ローカル冗長ストレージ (LRS)] を選択します。
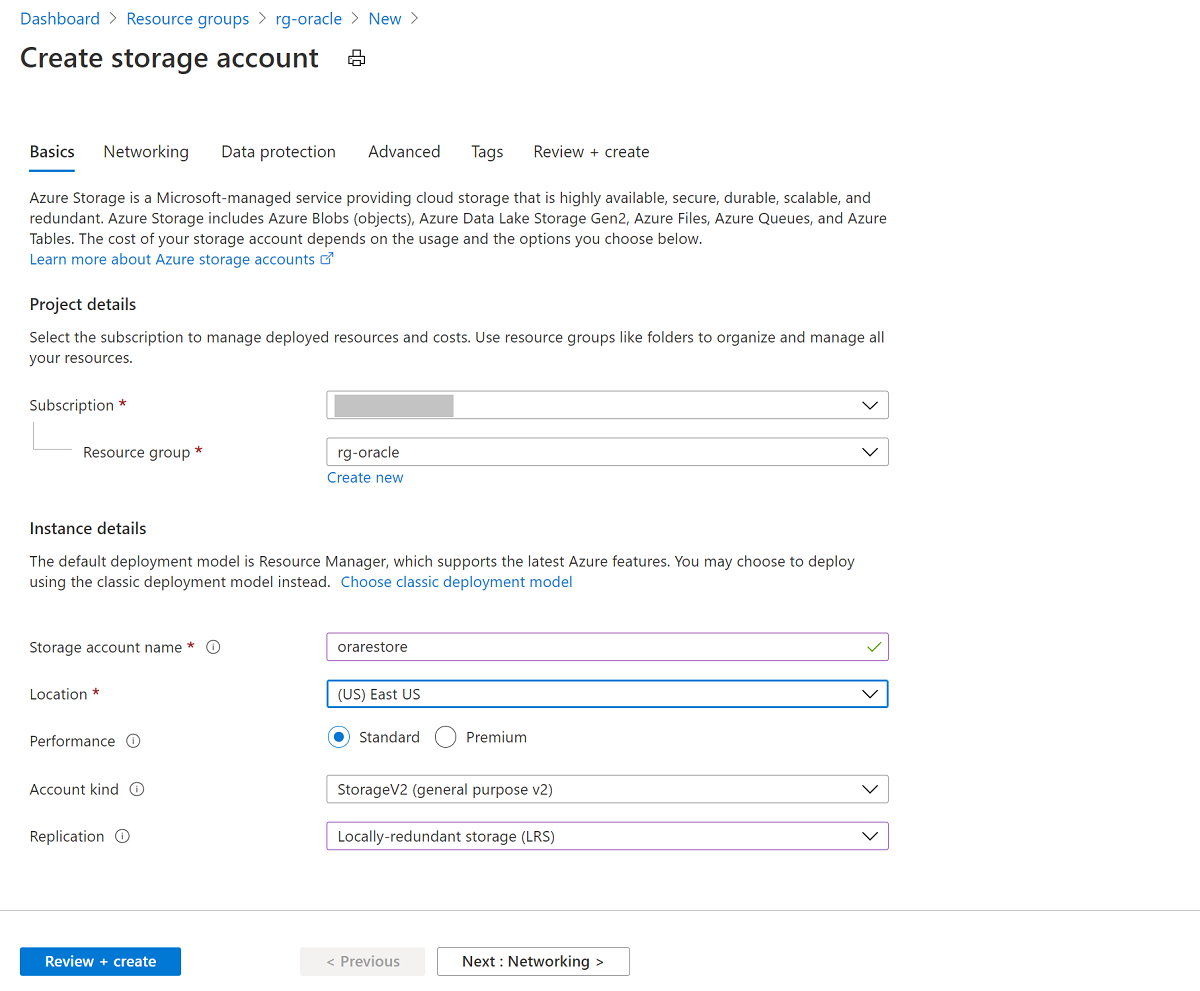
[確認と作成]、[作成] の順に選択します。
Azure portal で、Recovery Services コンテナー myVault を検索して選択します。

[概要] ペインで、[バックアップ項目] を選択します。 次に、[Azure 仮想マシン] を選択します。この項目の [バックアップ項目数] は 0 以外の数値となっているはずです。
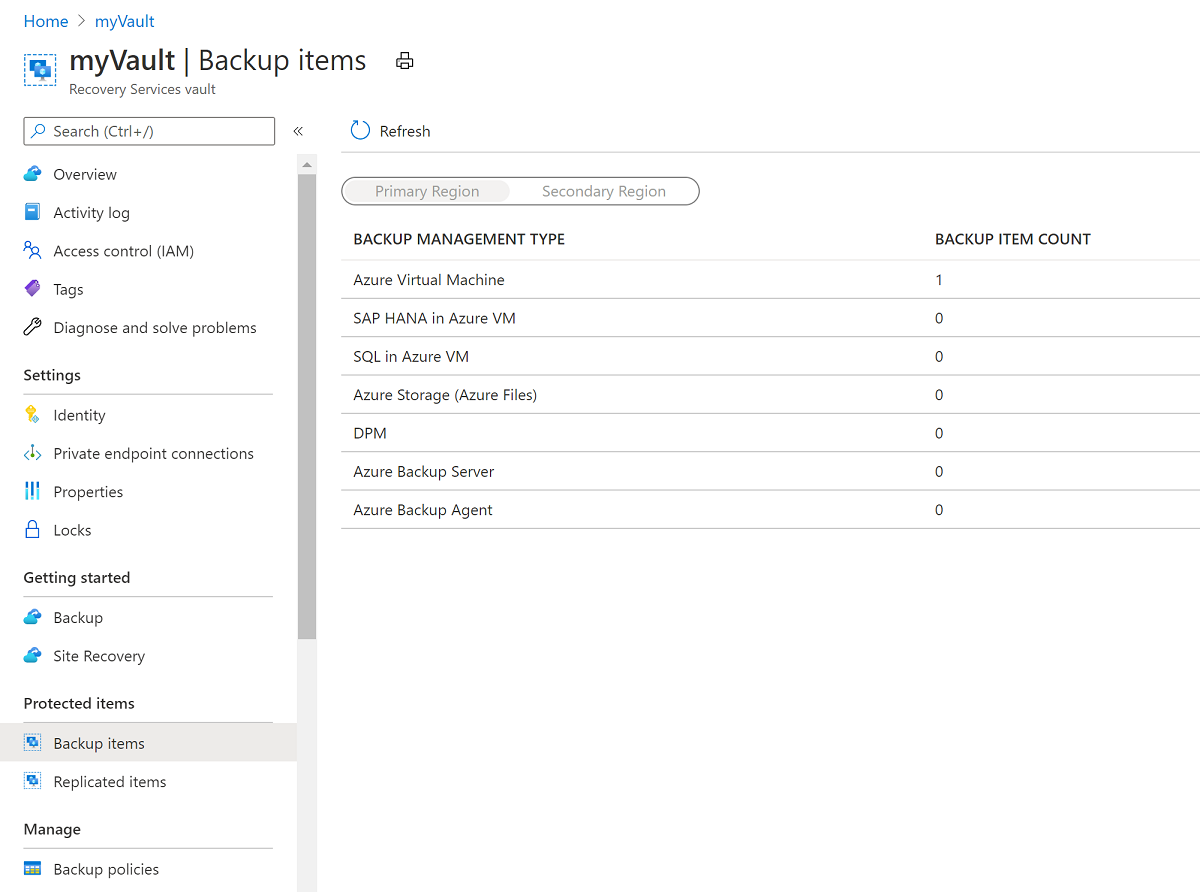
[バックアップ項目 (Azure 仮想マシン)] ペインで、vmoracle19c VM を選択します。
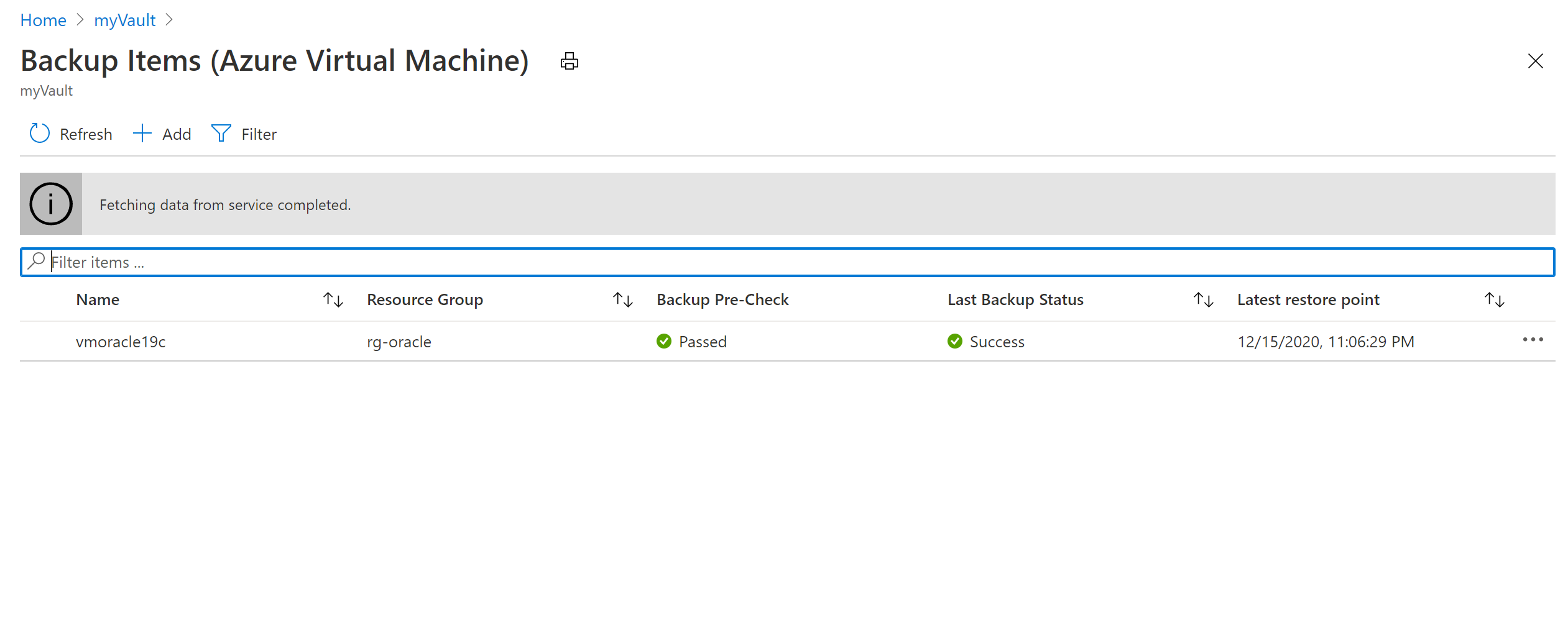
vmoracle19c ペインで、整合性の種類が [アプリケーション整合性] である復元ポイントを選択します。 省略記号 (...) を選択し、[VM の復元] を選択します。
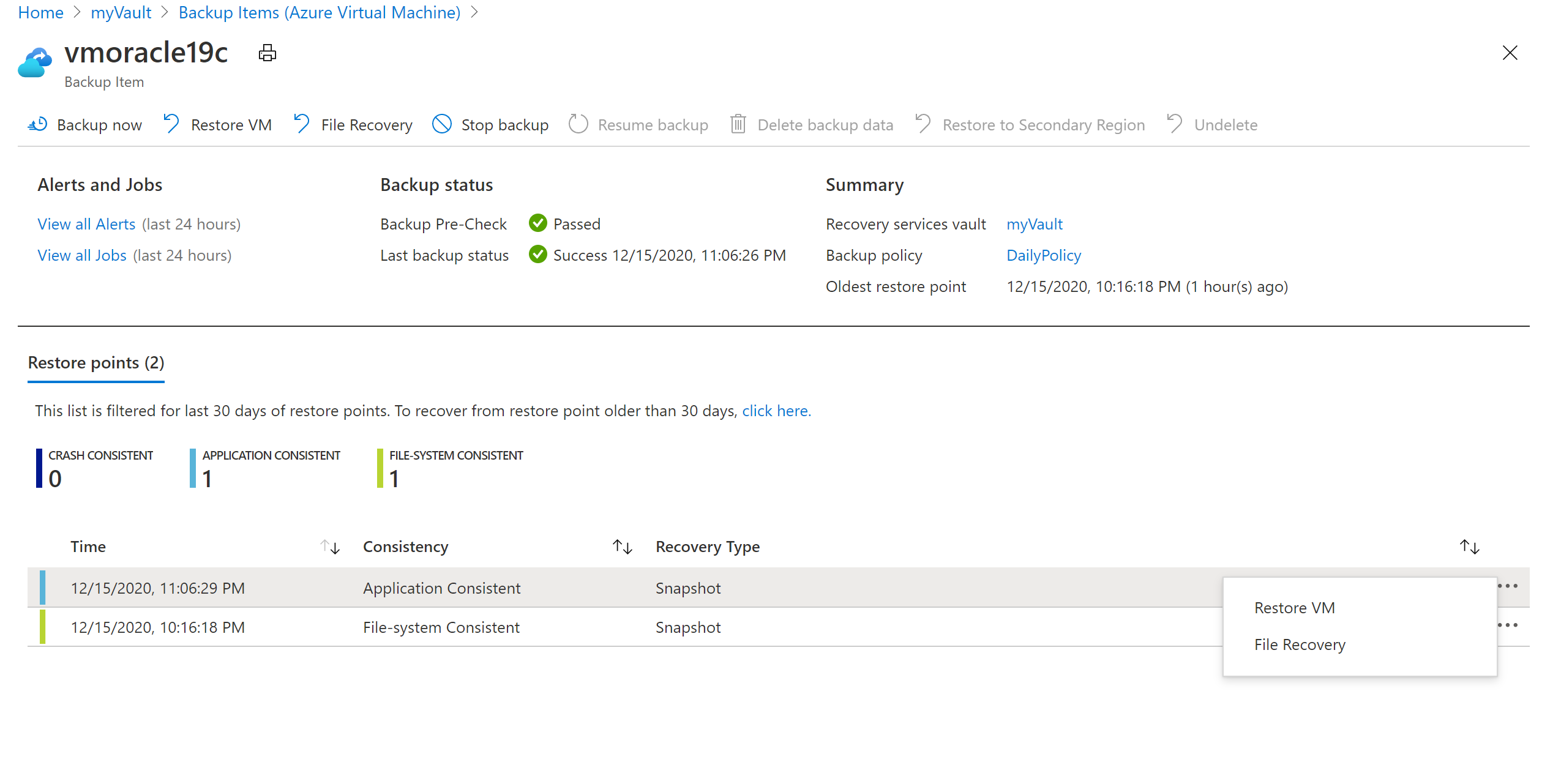
[仮想マシンの復元] ペインで、次の操作を行います。
[新規作成] を選択します。
[復元の種類] では、[新しい仮想マシンの作成] を選択します。
[仮想マシン名] には「vmoracle19c」と入力します。
[仮想ネットワーク] では、vmoracle19cVNET を選択します。
サブネットは、仮想ネットワークの選択内容に基づいて自動的に設定されます。
[ステージング場所] では、VM を復元するプロセスには、同じリソース グループとリージョンにある Azure ストレージ アカウントが必要です。 先ほど設定したストレージ アカウントまたは復元タスクを選択できます。
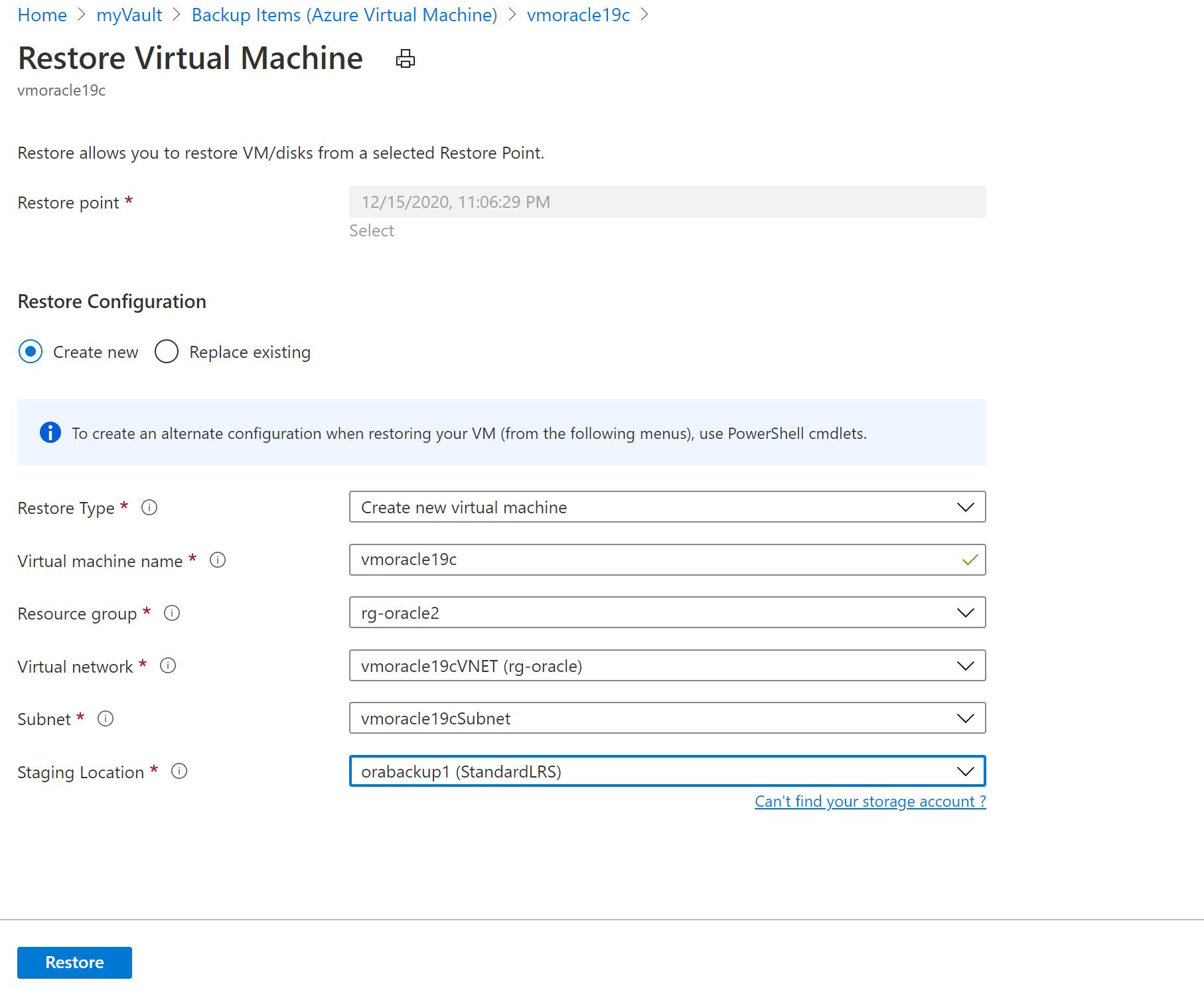
VM を復元するには、[復元] ボタンを選択します。
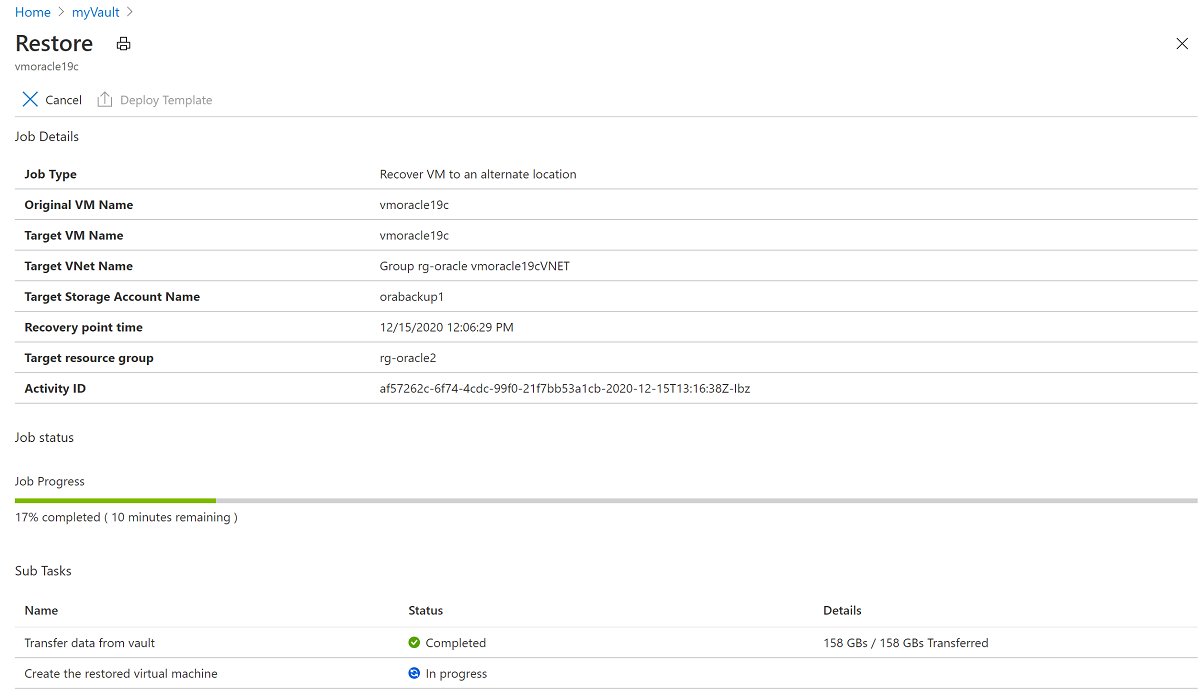
復元プロセスの状態を表示するには、[ジョブ] を選択し、[バックアップ ジョブ] を選択します。
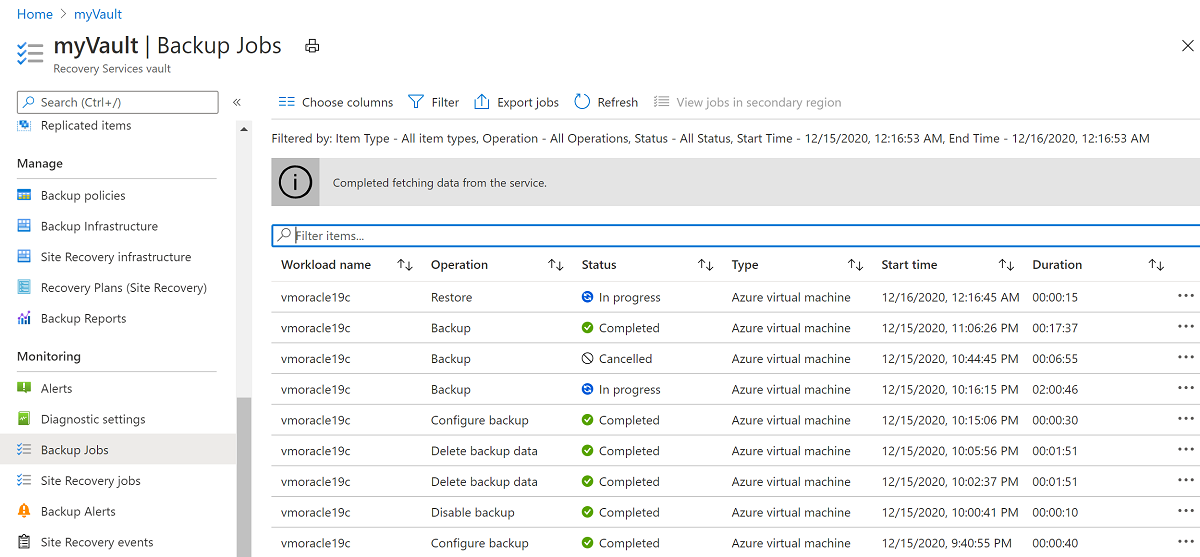
[進行中] の復元操作を選択して、復元プロセスの状態の詳細を表示します。
パブリック IP アドレスを設定する
VM が復元されたら、元の IP アドレスを新しい VM に再割り当てする必要があります。
Azure portal で、vmoracle19c という名前の仮想マシンに移動します。 vmoracle19c-nic-XXXXXXXXXXXX のような新しいパブリック IP と NIC が割り当てられていますが、DNS アドレスはないことがわかります。 元の VM が削除されたとき、そのパブリック IP と NIC は保持されました。 次の手順では、それらを新しい VM に再アタッチします。
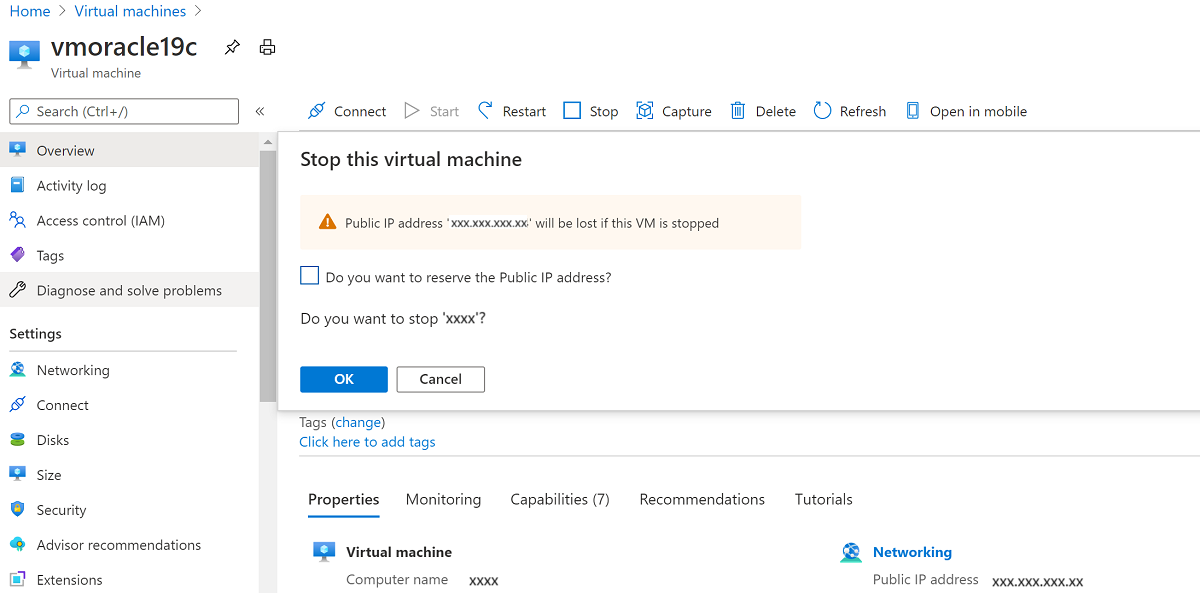
VM を停止します。
[ネットワーク] に移動します。
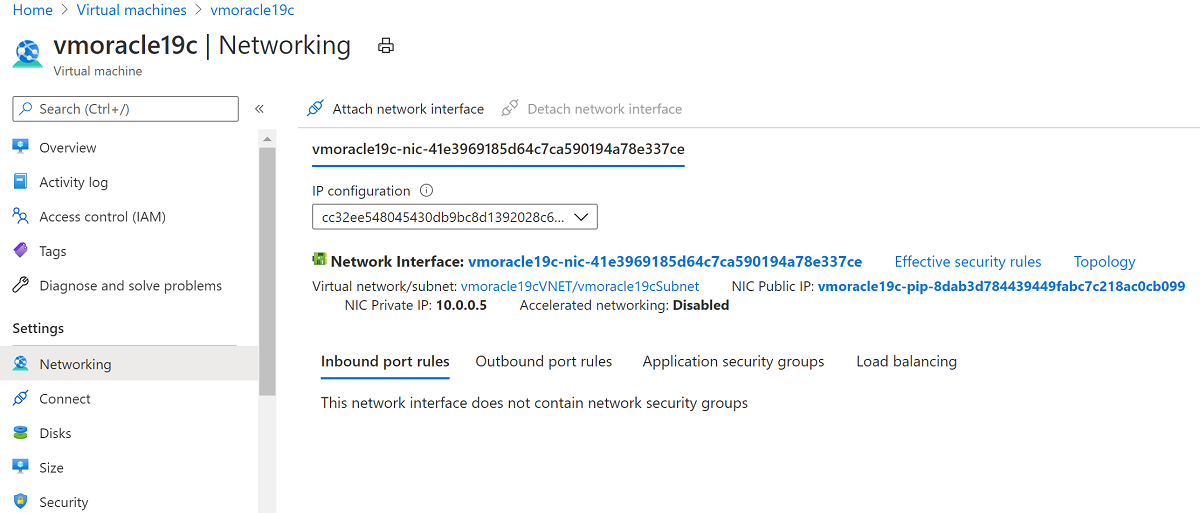
[ネットワーク インターフェイスの接続] を選択します。 元のパブリック IP アドレスがまだ関連付けられている元の NIC vmoracle19cVMNic を選択します。 [OK] をクリックします。
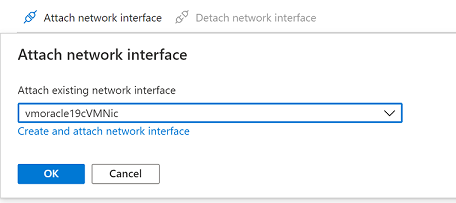
VM の復元操作で作成した NIC はプライマリ インターフェイスとして構成されているため、デタッチします。 [ネットワーク インターフェイスのデタッチ] を選択し、 vmoracle19c-nic-XXXXXXXXXXXXXXX に似た NIC を選択し、[OK] を選択します。
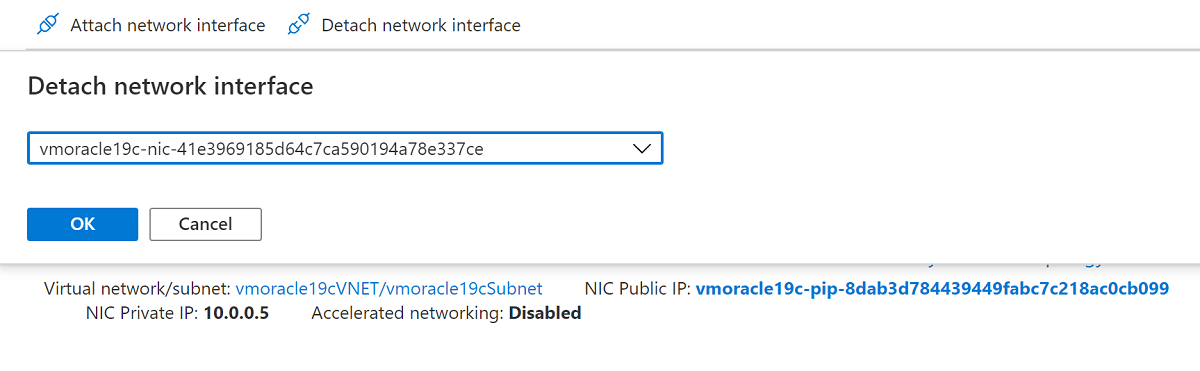
再作成された VM に、元の NIC が再アタッチされました。この NIC には、元の IP アドレスとネットワーク セキュリティ グループ規則に関連付けられています。
[概要] ペインに戻り、[開始] を選択します。
データベースを回復する
VM の完全な復元後にデータベースを復旧するには以下の手順を行います。
VM に再接続します。
ssh azureuser@<publicIpAddress>VM 全体が復元されたら、VM 上のデータベースを復旧することが重要です。これは、各データベースに対して次の手順を実行することで行います。
自動開始で VM の起動時にデータベースの起動が試みられたために、インスタンスが実行されていることがあります。 ただし、データベースには復旧が必要であり、まだマウント ステージである可能性があります。 マウント ステージを開始する前に、準備シャットダウンを実行します。
sudo su - oracle sqlplus / as sysdba SQL> shutdown immediate SQL> startup mountデータベース復旧を実行します。
復元されたデータベースの制御ファイルに記録されている Oracle システム変更番号 (SCN) で復元を停止しないよう
RECOVER AUTOMATIC DATABASEコマンドに通知するため、USING BACKUP CONTROLFILE構文を指定することが重要です。この復元されたデータベースの制御ファイルは、他の部分のデータベースと同様、スナップショットです。 その中に格納されている SCN は、スナップショットの時点のものです。 この時点以降に記録されたトランザクションがある可能性があり、データベースにコミットされた最後のトランザクションの時点まで復旧することが望ましいです。
SQL> recover automatic database using backup controlfile until cancel;使用可能な最後のアーカイブ ログ ファイルが適用されたら、「
CANCEL」と入力して復旧を終了します。復旧が正常に完了すると、メッセージ
Media recovery completeが表示されます。ただし、
BACKUP CONTROLFILE句を使用している場合、recover コマンドはオンライン ログ ファイルを無視します。 ポイントインタイム リストアを完了するには、現在のオンライン再実行ログの変更が必要になる可能性があります。 このような状況では、以下の例のようなメッセージが表示される場合があります。SQL> recover automatic database until cancel using backup controlfile; ORA-00279: change 2172930 generated at 04/08/2021 12:27:06 needed for thread 1 ORA-00289: suggestion : /u02/fast_recovery_area/ORATEST1/archivelog/2021_04_08/o1_mf_1_13_%u_.arc ORA-00280: change 2172930 for thread 1 is in sequence #13 ORA-00278: log file '/u02/fast_recovery_area/ORATEST1/archivelog/2021_04_08/o1_mf_1_13_%u_.arc' no longer needed for this recovery ORA-00308: cannot open archived log '/u02/fast_recovery_area/ORATEST1/archivelog/2021_04_08/o1_mf_1_13_%u_.arc' ORA-27037: unable to obtain file status Linux-x86_64 Error: 2: No such file or directory Additional information: 7 Specify log: {<RET>=suggested | filename | AUTO | CANCEL}重要
現在のオンライン再実行ログが失われたり破損したりして使用できない場合は、この時点で回復を取り消すこともあります。
この状況を修正するには、どのオンライン ログがアーカイブされていなかったのかを特定し、プロンプトにその完全修飾ファイル名を指定します。
データベースを開きます。
RESETLOGSオプションは 、RECOVERコマンドでUSING BACKUP CONTROLFILEオプションを使用する場合に必要です。RESETLOGSは、履歴を最初にリセットしてデータベースの新しいインカネーションを作成します。これは、以前のデータベース インカネーションが復旧でどのくらいスキップされたかを判断する方法がないためです。SQL> alter database open resetlogs;データベースの内容が復旧されたことを確認します。
SQL> select * from scott.scott_table;
これで、Azure Linux VM での Oracle Database のバックアップと復旧が完了しました。
Oracle コマンドと概念の詳細については、Oracle のドキュメント (以下を含む) を参照してください。
- データベース全体の Oracle ユーザー管理のバックアップの実行
- ユーザー管理データベースの完全復旧の実行
- Oracle STARTUP コマンド
- Oracle RECOVER コマンド
- Oracle ALTER DATABASE コマンド
- Oracle LOG_ARCHIVE_DEST_n パラメーター
- Oracle ARCHIVE_LAG_TARGET パラメーター
VM の削除
VM が必要なくなったら、次のコマンドを使用して、リソース グループ、VM、およびすべての関連リソースを削除できます。
コンテナー内のバックアップの論理的な削除を無効にします。
az backup vault backup-properties set --name myVault --resource-group rg-oracle --soft-delete-feature-state disableVM の保護を停止し、バックアップを削除します。
az backup protection disable --resource-group rg-oracle --vault-name myVault --container-name vmoracle19c --item-name vmoracle19c --delete-backup-data true --yesすべてのリソースを含むリソース グループを削除します。
az group delete --name rg-oracle