HPC の Message Passing Interface を設定する
適用対象: ✔️ Linux VM ✔️ Windows VM ✔️ フレキシブル スケール セット ✔️ 均一スケール セット
メッセージ パッシング インターフェイス (MPI) は、分散型メモリ並列化用のオープン ライブラリであり、デファクト スタンダードです。 多くの HPC ワークロードにわたってよく使用されています。 RDMA 対応の HB シリーズおよび N シリーズ VM 上の HPC ワークロードは、MPI を使用し、低待機時間で高帯域幅の InfiniBand ネットワーク経由で通信できます。
- Azure の SR-IOV 対応 VM サイズでは、ほぼすべてのフレーバーの MPI を Mellanox OFED と一緒に使用できます。
- SR-IOV に対応していない VM の場合、サポートされている MPI 実装では、VM 間の通信に Microsoft Network Direct (ND) インターフェイスが使用されます。 そのため、Microsoft MPI (MS MPI) 2012 R2 以降と Intel MPI 5.x バージョンのみがサポートされています。 Intel MPI ランタイム ライブラリの以降のバージョン (2017、2018) は、Azure RDMA ドライバーと互換性がある場合とない場合があります。
SR-IOV 対応の RDMA 対応 VM の場合、Ubuntu-HPC VM イメージ と AlmaLinux-HPC VM イメージが適しています。 これらの VM イメージは最適化されていて、RDMA 用の OFED ドライバー、一般的に使用されているさまざまな MPI ライブラリ、科学コンピューティング パッケージが事前に読み込まれているため、最も簡単に始められます。
これらの例は RHEL に向けたものですが、手順は一般的であり、Ubuntu (18.04、20.04、22.04) や SLES (12 SP4、15 SP4) などの互換性のあるすべての Linux オペレーティング システムで使用できます。 その他の MPI 実装を別のディストリビューションで設定するための例については、azhpc-images リポジトリにより多く用意されています。
Note
特定の MPI ライブラリ (プラットフォーム MPI など) を使用して SR-IOV が有効になっている VM で MPI ジョブを実行するには、分離とセキュリティを実現するために、テナント全体にパーティションキー (p キー) を設定する必要がある場合があります。 p キーの値を決定し、MPI ライブラリでその値を MPI ジョブのために正しく設定することの詳細については、「パーティション キーを検出する」セクションの手順に従ってください。
Note
次はコード スニペットの例です。 パッケージの最新の安定バージョンを使用するか、 azhpc イメージ リポジトリを参照することをお勧めします。
MPI ライブラリを選択する
HPC アプリケーションで特定の MPI ライブラリが推奨されている場合は、最初にそのバージョンを使用します。 選択できる MPI について柔軟性があり、最高のパフォーマンスを必要とする場合に、HPC-X を試します。 全体として、HPC-X MPI では、InfiniBand インターフェイスに UCX フレームワークを使用して最高のパフォーマンスが発揮され、Mellanox InfiniBand のハードウェアとソフトウェアのすべての機能が利用されます。 さらに、HPC-X と OpenMPI は ABI 互換性があるため、OpenMPI でビルドされた HPC-X で HPC アプリケーションを動的に実行できます。 同様に、Intel MPI、MVAPICH、MPICH は ABI 互換性があります。
次の図は、一般的な MPI ライブラリのアーキテクチャを示しています。
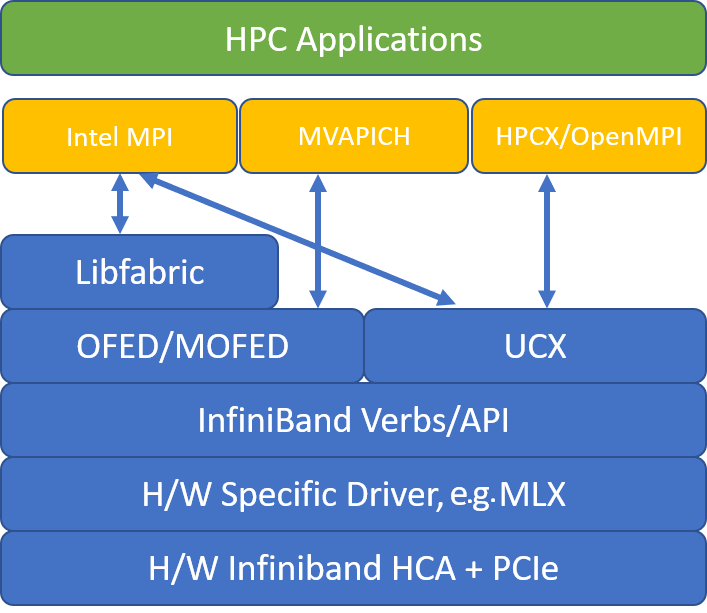
HPC-X
HPC-x ソフトウェア ツールキットには UCX および HCOLL が含まれており、UCX に対して構築できます。
HPCX_VERSION="v2.6.0"
HPCX_DOWNLOAD_URL=https://azhpcstor.blob.core.windows.net/azhpc-images-store/hpcx-v2.6.0-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
wget --retry-connrefused --tries=3 --waitretry=5 $HPCX_DOWNLOAD_URL
tar -xvf hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
mv hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64 ${INSTALL_PREFIX}
HPCX_PATH=${INSTALL_PREFIX}/hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64
次のコマンドには、HPC-X と OpenMPI で推奨される mpirun のいくつかの引数が示されています。
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
ここで、
| パラメーター | Description |
|---|---|
NPROCS |
MPI プロセスの数を指定します (例: -n 16)。 |
$HOSTFILE |
MPI プロセスが実行される場所を示すために、ホスト名または IP アドレスを含むファイルを指定します。 (例: --hostfile hosts)。 |
$NUMBER_PROCESSES_PER_NUMA |
各 NUMA ドメインで実行される MPI プロセスの数を指定します。 例: NUMA あたり 4 つの mpi プロセスを指定するには、--map-by ppr:4:numa:pe=1 を使用します。 |
$NUMBER_THREADS_PER_PROCESS |
MPI プロセスあたりのスレッド数を指定します。 例: NUMA あたり 1 つの MPI プロセスと 4 つのスレッドを指定するには、--map-by ppr:1:numa:pe=4 を使用します。 |
-report-bindings |
コアにマッピングされている MPI プロセスを出力します。これは、MPI プロセスの固定が正しいことを確認するのに役立ちます。 |
$MPI_EXECUTABLE |
MPI ライブラリにリンクが構築される MPI 実行可能ファイルを指定します。 MPI コンパイラ ラッパーでは、これが自動的に実行されます。 たとえば、mpicc や mpif90 などです。 |
OSU 待機時間のマイクロベンチマークを実行する例を次に示します。
${HPCX_PATH}mpirun -np 2 --map-by ppr:2:node -x UCX_TLS=rc ${HPCX_PATH}/ompi/tests/osu-micro-benchmarks-5.3.2/osu_latency
MPI コレクティブの最適化
MPI コレクティブ通信プリミティブでは、グループ通信操作を実装するための柔軟で移植可能な方法が提供されます。 これらは、さまざまな科学的並列アプリケーションで広く使用されており、アプリケーションのパフォーマンス全体に大きな影響を与えます。 コレクティブ通信用の HPC-X および HCOLL ライブラリを使用したコレクティブ通信のパフォーマンスを最適化する構成パラメーターについて詳しくは、TechCommunity の記事を参照してください。
たとえば、密結合された MPI アプリケーションで大量のコレクティブ通信が行われていると思われる場合は、Hierarchical Collectives (HCOLL) を有効にしてみることができます。 それらの機能を有効にするには、次のパラメーターを使用します。
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Note
HPC-X 2.7.4 + では、MOFED の UCX バージョン と HPC-X のものが異なる場合は、明示的に LD_LIBRARY_PATH を渡す必要がある場合があります。
OpenMPI
前述したように UCX をインストールします。 HCOLL は HPC-X ソフトウェア ツールキットの一部であり、特別なインストールは不要です。
リポジトリで入手可能なパッケージから OpenMPI をインストールできます。
sudo yum install –y openmpi
UCX で OpenMPI の最新の安定したリリースをビルドすることをお勧めします。
OMPI_VERSION="4.0.3"
OMPI_DOWNLOAD_URL=https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-${OMPI_VERSION}.tar.gz
wget --retry-connrefused --tries=3 --waitretry=5 $OMPI_DOWNLOAD_URL
tar -xvf openmpi-${OMPI_VERSION}.tar.gz
cd openmpi-${OMPI_VERSION}
./configure --prefix=${INSTALL_PREFIX}/openmpi-${OMPI_VERSION} --with-ucx=${UCX_PATH} --with-hcoll=${HCOLL_PATH} --enable-mpirun-prefix-by-default --with-platform=contrib/platform/mellanox/optimized && make -j$(nproc) && make install
最適なパフォーマンスを得るには、ucxと hcoll を使用して OpenMPI を実行し ます。 また、「HPC-X」の例も参照してください。
${INSTALL_PREFIX}/bin/mpirun -np 2 --map-by node --hostfile ~/hostfile -mca pml ucx --mca btl ^vader,tcp,openib -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_IB_PKEY=0x0003 ./osu_latency
前述のように、パーティション キーを確認します。
Intel MPI
選択したバージョンの Intel MPI をダウンロードします。 Intel MPI 2019 リリースは、Open Fabrics Alliance (OFA) フレームワークから Open Fabrics Interfaces (OFI) f フレームワークに切り替えられており、現在は libfabric がサポートされています。 InfiniBand のサポートには、mlx と verbs の 2 つのプロバイダーがあります。 バージョンに応じて I_MPI_FABRICS 環境変数を変更します。
- Intel MPI 2019 および 2021:
I_MPI_FABRICS=shm:ofi、I_MPI_OFI_PROVIDER=mlxを使用してください。mlxプロバイダーは UCX を使用します。 Verb の使用が不安定で、パフォーマンスが低下しています。 詳しくは、TechCommunity 記事をご覧ください。 - Intel MPI 2018:
I_MPI_FABRICS=shm:ofaを使用 - Intel MPI 2016:
I_MPI_DAPL_PROVIDER=ofa-v2-ib0を使用
Intel MPI 2019 Update 5 以上の推奨されるいくつかの mpirun 引数を次に示します。
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
ここで、
| パラメーター | 説明 |
|---|---|
FI_PROVIDER |
使用する libfabric プロバイダーを指定します。これは、使用されている API、プロトコル、およびネットワークに影響します。 verbs はもう 1 つのオプションですが、一般に mlx の方がパフォーマンスに優れています。 |
I_MPI_DEBUG |
追加のデバッグ出力のレベルを指定します。これにより、プロセスが固定される場所と使用されるプロトコルとネットワークに関する詳細を指定できます。 |
I_MPI_PIN_DOMAIN |
プロセスを固定する方法を指定します。 たとえば、コア、ソケット、または NUMA ドメインへ固定できます。 この例では、この環境変数を numa に設定しています。これは、プロセスが NUMA ノード ドメインに固定されることを意味します。 |
MPI コレクティブの最適化
他にもいくつかのオプションを試してみることができます。特に、集合演算で著しく時間がかかっている場合です。 Intel MPI 2019 Update 5 以上では、プロバイダー mlx がサポートされ、UCX フレームワークを使用して InfiniBand と通信します。 また、HCOLL もサポートされています。
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
SR-IOV 非対応 VM
SR-IOV 非対応 VM の場合、5.x ランタイムの無料評価版をダウンロードする例は次のとおりです。
wget http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/9278/l_mpi_p_5.1.3.223.tgz
インストール手順については、Intel MPI ライブラリのインストール ガイドをご覧ください。 必要に応じて (最新バージョンの Intel MPI に必要な) non-root non-debugger プロセスに対して ptrace を有効にすることをお勧めします。
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
SUSE Linux
SUSE Linux Enterprise Server の VM イメージ バージョンが SLES 12 SP3 for HPC、SLES 12 SP3 for HPC (Premium)、SLES 12 SP1 for HPC、SLES 12 SP1 for HPC (Premium)、SLES 12 SP4、SLES 15 の場合、RDMA ドライバーがインストールされ、 VM には Intel MPI パッケージが配布されます。 次のコマンドを実行して Intel MPI をインストールします。
sudo rpm -v -i --nodeps /opt/intelMPI/intel_mpi_packages/*.rpm
MVAPICH
MVAPICH2 をビルドする例を次に示します。 以下で使用されているものよりも新しいバージョンを利用できる場合があることに注意してください。
wget http://mvapich.cse.ohio-state.edu/download/mvapich/mv2/mvapich2-2.3.tar.gz
tar -xv mvapich2-2.3.tar.gz
cd mvapich2-2.3
./configure --prefix=${INSTALL_PREFIX}
make -j 8 && make install
OSU 待機時間のマイクロベンチマークを実行する例を次に示します。
${INSTALL_PREFIX}/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=48 ./osu_latency
次の一覧に、推奨されるいくつかの mpirun 引数を示します。
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
ここで、
| パラメーター | 説明 |
|---|---|
MV2_CPU_BINDING_POLICY |
使用するバインド ポリシーを指定します。これは、プロセスがコア ID に固定される方法に影響します。 この例では、scatter を指定するので、プロセスが NUMA ドメイン間で均等に分散されます。 |
MV2_CPU_BINDING_LEVEL |
プロセスを固定する場所を指定します。 この例では numanode に設定しています。これは、プロセスが NUMA ドメインのユニットに固定されることを意味します。 |
MV2_SHOW_CPU_BINDING |
プロセスが固定されている場所に関するデバッグ情報を取得する必要がある場合に指定します。 |
MV2_SHOW_HCA_BINDING |
各プロセスで使用されているホスト チャネル アダプターに関するデバッグ情報を取得する必要がある場合に指定します。 |
プラットフォーム MPI
プラットフォーム MPI のコミュニティ エディションに必要なパッケージをインストールします。
sudo yum install libstdc++.i686
sudo yum install glibc.i686
Download platform MPI at https://www.ibm.com/developerworks/downloads/im/mpi/index.html
sudo ./platform_mpi-09.01.04.03r-ce.bin
インストール プロセスに従います。
MPICH
前述したように UCX をインストールします。 MPICH をビルドします。
wget https://www.mpich.org/static/downloads/3.3/mpich-3.3.tar.gz
tar -xvf mpich-3.3.tar.gz
cd mpich-3.3
./configure --with-ucx=${UCX_PATH} --prefix=${INSTALL_PREFIX} --with-device=ch4:ucx
make -j 8 && make install
MPICH を実行します。
${INSTALL_PREFIX}/bin/mpiexec -n 2 -hostfile ~/hostfile -env UCX_IB_PKEY=0x0003 -bind-to hwthread ./osu_latency
前述のように、パーティション キーを確認します。
OSU MPI ベンチマーク
OSU MPI ベンチマークをダウンロードし、解凍します。
wget http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.5.tar.gz
tar –xvf osu-micro-benchmarks-5.5.tar.gz
cd osu-micro-benchmarks-5.5
特定の MPI ライブラリを使用してベンチマークをビルドします:
CC=<mpi-install-path/bin/mpicc>CXX=<mpi-install-path/bin/mpicxx> ./configure
make
MPI ベンチマークは mpi/ フォルダー下にあります。
パーティション キーを検出する
同じテナント (可用性セットまたは仮想マシン スケール セット) 内の他の VM と通信するために、パーティション キー (p キー) を検出します。
/sys/class/infiniband/mlx5_0/ports/1/pkeys/0
/sys/class/infiniband/mlx5_0/ports/1/pkeys/1
2 つのうち大きいほうは、MPI で使用する必要があるテナント キーです。 例:p キーが次の場合、MPI では 0x800b を使用する必要があります。
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/0
0x800b
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/1
0x7fff
インターフェイスには HPC VM イメージ内として mlx5_ib* という名前が付けられていることに留意してください。
テナント (可用性セットまたは仮想マシン スケール セット) が存在する限り、p キーは同じままであることにも注意してください。 これは、ノードが追加または削除された場合でも当てはまります。 新しいテナントには、別の p キーが割り当てられます。
MPI のユーザー制限を設定する
MPI のユーザー制限を設定します。
cat << EOF | sudo tee -a /etc/security/limits.conf
* hard memlock unlimited
* soft memlock unlimited
* hard nofile 65535
* soft nofile 65535
EOF
MPI の SSH キーを設定する
SSH キーが必要な MPI タイプの場合、設定します。
ssh-keygen -f /home/$USER/.ssh/id_rsa -t rsa -N ''
cat << EOF > /home/$USER/.ssh/config
Host *
StrictHostKeyChecking no
EOF
cat /home/$USER/.ssh/id_rsa.pub >> /home/$USER/.ssh/authorized_keys
chmod 600 /home/$USER/.ssh/authorized_keys
chmod 644 /home/$USER/.ssh/config
上記の構文は共有ホーム ディレクトリを想定しており、それ以外の場合は、.ssh ディレクトリを各ノードにコピーする必要があります。
次のステップ
- InfiniBand 対応の HB シリーズおよび N シリーズの VM について学習します。
- HBv3 シリーズの概要および HC シリーズの概要に関する記事を確認します。
- HB シリーズ VM の最適な MPI プロセス配置に関する記事を参照します。
- Azure Compute Tech Community のブログで、最新の発表、HPC ワークロードの例、およびパフォーマンスの結果について参照します。
- HPC ワークロードの実行をアーキテクチャの面から見た概要については、「Azure でのハイ パフォーマンス コンピューティング (HPC)」をご覧ください。