Project Flash - Azure Resource Graph を使用して Azure 仮想マシンの可用性を監視する
Azure Resource Graph は、Flash で提供されるソリューションの 1 つです。 Flash は、お客様が仮想マシン (VM) の正常性を監視するための堅牢で信頼性の高い迅速なメカニズムを構築することに特化したプロジェクトの内部名です。
この記事では、Azure Resource Graph を使用した Azure 仮想マシンの可用性の監視について説明します。 Flash ソリューションの概要については、「Flash の概要」を参照してください。
Flash で提供されるその他のソリューションに特化したドキュメントは、次の記事から選択してください。
- Event Grid システム トピックを使用して Azure 仮想マシンの可用性を監視する
- Azure Monitor を使用して Azure 仮想マシンの可用性を監視する
- Azure Resource Health を使用して Azure 仮想マシンの可用性を監視する
Azure Resource Graph - HealthResources
この機能は現在一般提供されています。 また、大規模な調査を行うのに役立ちます。 この機能は、Kusto クエリ言語 (KQL) の使用により、情報取得向けの非常にユーザーフレンドリなエクスペリエンスを提供します。 また、リソース情報のセントラル ハブとして機能し、過去のデータを簡単に検索できます。
既に流れている VM の可用性状態に加えて、Microsoft は、VM の可用性の注釈を Azure Resource Graph (ARG) に公開し、詳細な失敗の帰属とダウンタイム分析を行うとともに、14 日間の変更追跡メカニズムを有効にし、VM の可用性の過去の変更をトレースして迅速にデバッグできるようにしました。 このような新しい追加により、ARG の HealthResources データセットにおける VM 可用性情報が一般提供されることをお知らせします。 このオファリングを使用すると、ユーザーは次のことができます。
- 定期的かつ段階的な監視を行うために、すべての Azure サブスクリプションにわたる VM の可用性の最新のスナップショットを、一度に低待機時間で効率的にクエリを実行します。
- 段階的なビジネス SLA への影響を正確に評価し、中断や失敗の署名の種類に応じて、決定的な軽減策のアクションを迅速にトリガーします。
- ARG に存在するリソース メタデータと VM の可用性に関する情報を結合して、アプリケーションの包括的な正常性を監視するようにカスタム ダッシュボードを設定します。
- 詳細な調査を行うための変更追跡メカニズムを使用して、14 日間のローリング ウィンドウにわたって VM の可用性に関連する変更を追跡します。
サンプル クエリ
- Azure Service Health 向けの Azure Resource Graph サンプル クエリ - Azure Service Health | Microsoft Learn
- Azure Resource Graph の VM の可用性に関する情報 - Azure Virtual Machines | Microsoft Learn
- テーブル別のサンプル Azure Resource Graph クエリのリスト - Azure Resource Graph | Microsoft Learn
作業の開始
ユーザーは、PowerShell、REST API、Azure CLI、または Azure portal を介して ARG にクエリを実行できます。 次の手順では、Azure portal からデータにアクセスする方法の詳細を説明します。
Azure portal にアクセスしたら、Resource Graph Explorer に移動します。

[テーブル] タブを選択し、[HealthResources] テーブルを (シングル) クリックして、VM の可用性情報 (可用性の状態と正常性の注釈) の最新のスナップショットを取得します。
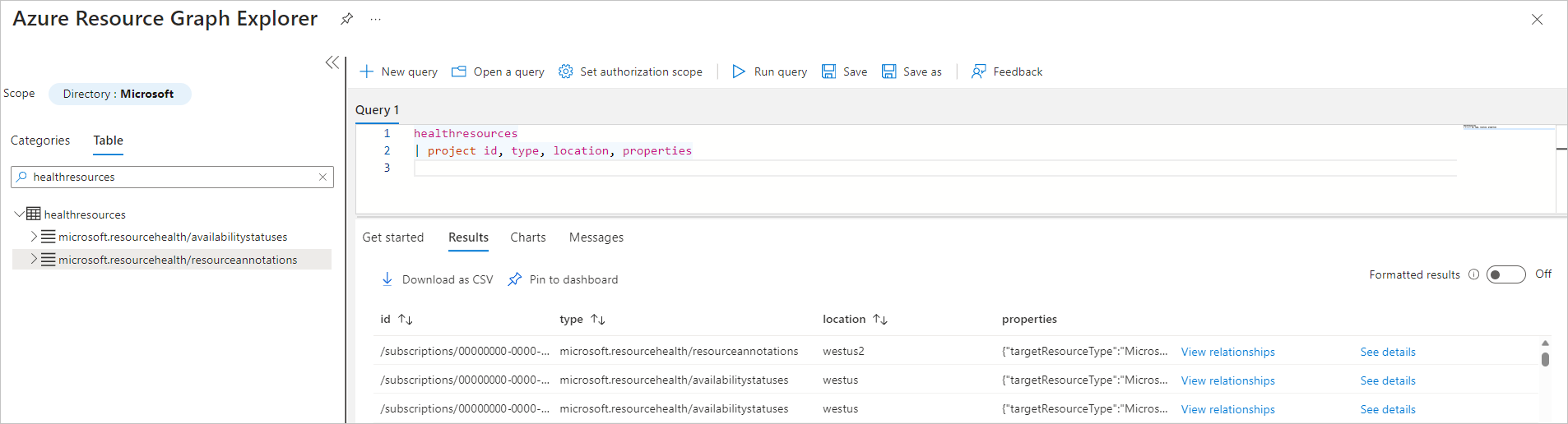


HealthResources テーブルには、次の 2 種類のイベントが設定されます。

- resourcehealth/availabilitystatuses
このイベントは、基になる Azure プラットフォームによって実行される正常性チェックに基づいて、VM の最新の可用性の状態を示します。 VM に対して現在出力されている可用性の状態は次のとおりです。
- Available: VM が正常に稼働しています。
- 使用不可: VM の正常な機能への中断が検出されたため、アプリケーションが期待どおりに実行されません。
- Unknown: プラットフォームで VM の正常性を正確に検出できません。 ユーザーは通常、数分後に更新された状態を確認できます。
最新の VM の可用性状態を投票するには、次の詳細を含むプロパティ フィールドを参照してください。
サンプル
{
"targetResourceType": "Microsoft.Compute/virtualMachines",
"previousAvailabilityState": "Available",
"targetResourceId": "/subscriptions//resourceGroups//providers/Microsoft.Compute/virtualMachines/",
"occurredTime": "2022-10-11T11:13:59.9570000Z",
"availabilityState": "Unavailable"
}
プロパティの説明
| プロパティ | 説明 | 対応するリソース正常性カテゴリ (RHC) |
|---|---|---|
| targetResourceType | 正常性データが流れるリソースの種類 | resourceType |
| targetResourceId | Resource ID | resourceId |
| occurredTime | プラットフォームによって最新の可用性の状態が出力されたときのタイムスタンプ | eventTimestamp |
| previousAvailabilityState | VM の以前の可用性の状態 | previousHealthStatus |
| availabilityState | VM の現在の可用性の状態 | currentHealthStatus |
このデータの詳細を探索するためのスターター クエリの一覧については、「サンプル クエリのドキュメント HealthResources セクション」を参照してください。
- resourcehealth/resourceannotations (新しく追加されました)
このイベントは、ユーザーが必要に応じて中断を調査して軽減するのに役立つように、必要な障害属性について詳しく説明することで、VM の可用性に対するあらゆる変更をコンテキスト化します。 プラットフォームによって出力される VM 可用性の注釈の完全な一覧を参照してください。 これらの注釈は、大きく次の 3 つに分類できます。
- ダウンタイム注釈: これらの注釈は、VM の可用性が Unavailable に切り替わることがプラットフォームで検出されたときに出力されます。 (たとえば、予期しないホストのクラッシュや、再起動を伴う修復作業など)。
- 情報注釈: これらの注釈は、VM の可用性に影響を与えないコントロール プレーン アクティビティ中に出力されます。 (VM の割り当て/停止/削除/開始など)。 通常、応答にその他の顧客アクションは必要ありません。
- 劣化注釈: これらの注釈は、VM の可用性が危険にさらされていることが検出されたときに生成されます。 (障害予測モデルで、いつでも VM の再起動を引き起こすおそれがある、劣化したハードウェア コンポーネントが予測されるときなど)。 予期しないデータの損失やダウンタイムを回避するには、注釈メッセージで指定された期限までに再デプロイすることを強くお勧めします。 次のいずれかのシナリオで、Azure Virtual Machine Scale Sets Resource Health またはアクティビティ ログにアラートが表示される場合があります。
- Azure Virtual Machine Scale Sets 内の VM は、停止、割り当て解除、削除、または開始の処理中です。
- Virtual Machine Scale Sets に対してスケールインまたはスケールアウト操作を実行しました。
- このアラートは、Virtual Machine Scale Sets の集約されたプラットフォームの正常性が一時的に "低下している" 状態であることを示します。
リソースに関連する VM 可用性の注釈に投票するするには、次の詳細を含むプロパティ フィールドを参照してください。
サンプル
{
"targetResourceType": "Microsoft.Compute/virtualMachines", "targetResourceId": "/subscriptions//resourceGroups//providers/Microsoft.Compute/virtualMachines/",
"annotationName": "VirtualMachineHostRebootedForRepair",
"occurredTime": "2022-09-25T20:21:37.5280000Z",
"category": "Unplanned",
"summary": "We're sorry, your virtual machine isn't available because an unexpected failure on the host server. Azure has begun the auto-recovery process and is currently rebooting the host server. No further action is required from you at this time. The virtual machine will be back online after the reboot completes.",
"context": "Platform Initiated",
"reason": "Unexpected host failure"
}
プロパティの説明
| プロパティ | 説明 | 対応する RHC |
|---|---|---|
| targetResourceType | 正常性データが流れるリソースの種類 | resourceType |
| targetResourceId | Resource ID | resourceId |
| occurredTime | プラットフォームによって最新の可用性の状態が出力されたときのタイムスタンプ | eventTimestamp |
| annotationName | 出力された注釈の名前 | eventName |
| reason | 顧客によって観測された可用性への影響の概要 | タイトル |
| category | 注釈のトリガー元のプラットフォーム アクティビティが、計画メンテナンスであるか計画外の修復であるかを示します。 このフィールドは、顧客や VM によって開始されるイベントには適用されません。 使用可能な値: Planned | Unplanned | Not Applicable | Null | category |
| context | 注釈をトリガーしたアクティビティが、許可されているユーザーまたはプロセス (顧客開始) によるものか、Azure プラットフォーム (プラットフォーム開始) によるものか、結果として可用性に影響を及ぼすゲスト OS のアクティビティ (VM 開始) によるものかを示します。 使用可能な値: Platform-Initiated、User-initiated、VM-initiated、Not Applicable、Null | context |
| まとめ | 注釈が出力される原因と、ユーザーが実行できる修復手順について詳しく説明するステートメント | まとめ |
このデータの詳細を探索するためのスターター クエリの一覧については、「サンプル クエリのドキュメント HealthResources セクション」を参照してください。
HealthResources データセットに表示される注釈メタデータについては、複数の機能強化を予定しています。 これらの機能強化により、ユーザーはより豊富な失敗属性にアクセスできるようになり、中断への対応を決定的に準備できます。 並行して、履歴ルックバックの期間を少なくとも 30 日間に延長し、ユーザーが VM の可用性の過去の変化を包括的に追跡できるようにすることを目指しています。
次のステップ
提供されるソリューションの詳細については、対応するソリューションの記事に進んでください。
- Event Grid システム トピックを使用して Azure 仮想マシンの可用性を監視する
- Azure Monitor を使用して Azure 仮想マシンの可用性を監視する
- Azure Resource Health を使用して Azure 仮想マシンの可用性を監視する
Azure 仮想マシンを監視する方法の一般的な概要については、「Azure 仮想マシンの監視」および Azure 仮想マシンの監視のリファレンスに関するページを参照してください。