Azure Synapse Analytics でサーバーレス SQL プールを使用して Delta Lake (v1) ファイルのクエリを実行する
この記事では、サーバーレス Synapse SQL プールを使用して Delta Lake ファイルを読み取るクエリを作成する方法について説明します。 Delta Lake は、ACID (原子性、一貫性、分離性、持続性) トランザクションを Apache Spark とビッグ データ ワークロードに導入するオープンソースのストレージ レイヤーです。 詳細については、Delta Lake のテーブル対してクエリを実行する方法に関するビデオを参照してください。
重要
サーバーレス SQL プールは、Delta Lake バージョン 1.0 のクエリを実行できます。 Delta Lake 1.2 バージョン以降に導入された変更 (列の名前変更など) は、サーバーレスではサポートされていません。 削除ベクター、v2 チェックポイントなどの上位バージョンの Delta を使用している場合は、レイクハウス用の Microsoft Fabric SQL エンドポイントなどのその他のクエリ エンジンの使用を検討する必要があります。
Synapse ワークスペースのサーバーレス SQL プールを使用すると、Delta Lake 形式で格納されているデータを読み取り、レポート ツールに提供できます。 サーバーレス SQL プールは、Apache Spark、Azure Databricks、または Delta Lake 形式の他のプロデューサーを使用して作成された Delta Lake ファイルを読み取ることができます。
Azure Synapse の Apache Spark プールを使用すると、データ エンジニアが Scala、PySpark、.NET を使用して Delta Lake ファイルを変更できます。 サーバーレス SQL プールは、データ アナリストがデータ エンジニアによって作成された Delta Lake ファイルに関するレポートを作成するのに役立ちます。
重要
サーバーレス SQL プールを使った Delta Lake 形式のクエリは一般提供機能です。 ただし、Spark Delta テーブルのクエリはまだパブリック プレビュー段階であり、運用環境には対応していません。 Spark プールを使って作成された Delta テーブルに対してクエリを実行した場合に発生する可能性のある既知の問題があります。 「サーバーレス SQL プールのセルフヘルプ」で既知の問題を確認してください。
前提条件
重要
データ ソースは、カスタム データベースにのみ作成できます (マスター データベースや、Apache Spark プールからレプリケートされたデータベースではありません)。
この記事のサンプルを使用するには、次の手順を完了する必要があります:
- NYC Yellow Taxi ストレージ アカウントを参照するデータソースでデータベースを作成します。
- 手順 1 で作成したデータベースでセットアップ スクリプトを実行して、オブジェクトを初期化します。 このセットアップ スクリプトにより、データ ソース、データベース スコープの資格情報、これらのサンプルで使用される外部ファイル形式が作成されます。
データベースを作成し、コンテキストをデータベースに切り替えた場合 (クエリ エディターでデータベースを選択するための USE database_name ステートメントまたはドロップダウンを使用)、データ セットのルート URI を含む外部データソースを作成し、それを使用して Delta Lake ファイルのクエリを実行できます。 次に例を示します。
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
データ ソースが SAS キーまたはカスタム ID で保護されている場合は、データベース スコープ資格情報を使用してデータ ソースを構成できます。
ストレージのルート フォルダーを示す場所を持つ外部データ ソースを作成します。 外部データ ソースを作成したら、データ ソースと OPENROWSET 関数内のファイルへの相対パスを使用します。 この方法では、ファイルの完全な絶対 URI を使用する必要はありません。 その後で、ストレージの場所にアクセスするためのカスタム資格情報を定義できます。
Delta Lake フォルダーの読み取り
重要
サンプル データ ソースとテーブルを設定するには、 前提条件 のセットアップ スクリプトを使用します。
OPENROWSET 関数を使用すると、ルート フォルダーの URL を指定することで、Delta Lake ファイルの内容を読み取ることができます。
DELTA ファイルの内容を確認する最も簡単な方法は、OPENROWSET 関数にファイルの URL を指定し、DELTA 形式を指定することです。 ファイルが一般公開されている場合、または Microsoft Entra ID でこのファイルにアクセスできる場合は、次の例に示すようなクエリを使用して、ファイルの内容を表示することができます。
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
列名とデータ型は、Delta Lake ファイルから自動的に読み取られます。
OPENROWSET 関数は、文字列に対して VARCHAR(1000) のような最善の推測型を使用します。
OPENROWSET 関数の URI は、_delta_log というサブフォルダーを含むルート Delta Lake フォルダーを参照する必要があります。
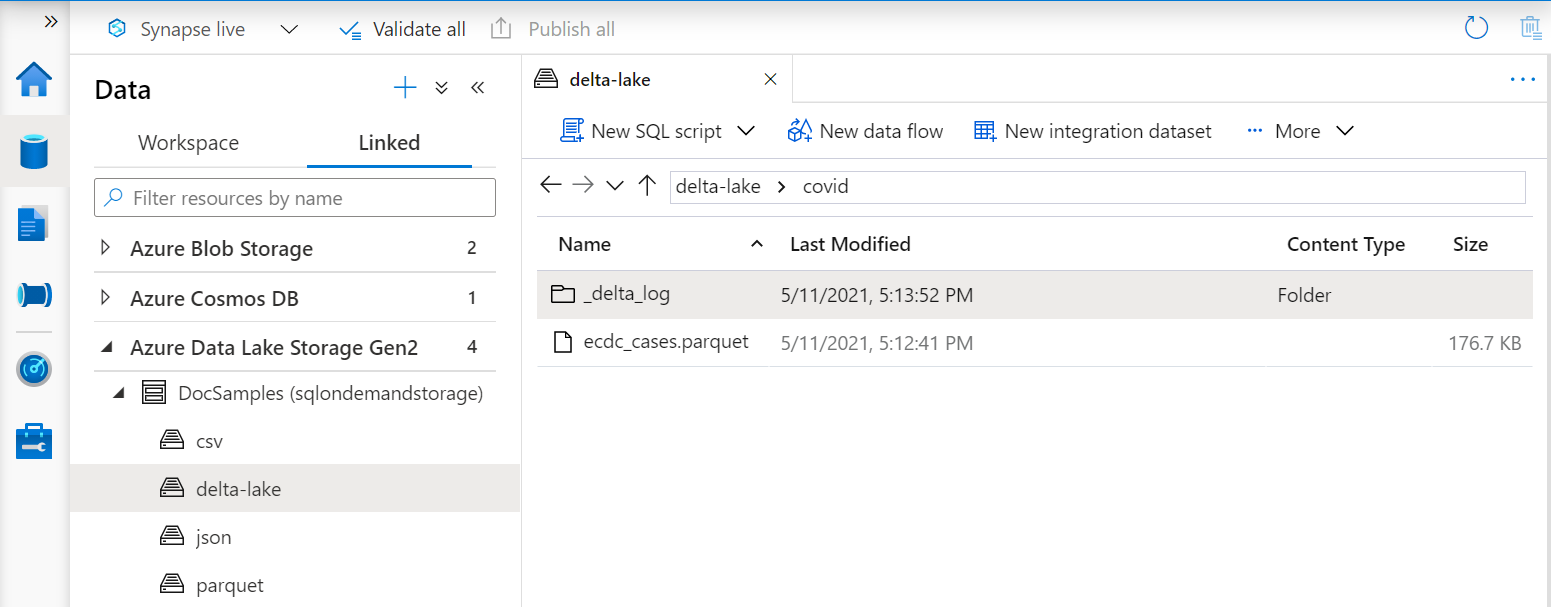
このサブフォルダーがない場合は、Delta Lake 形式が使用されていません。 次の例の Apache Spark Python スクリプトのようなスクリプトを使用して、フォルダー内のプレーンな Parquet ファイルを Delta Lake 形式に変換できます:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
クエリのパフォーマンスを向上させるために、WITH 句に明示的な型を指定することを検討してください。
Note
サーバーレス Synapse SQL プールでは、スキーマ推論を使用して列とその型が自動的に決定されます。 スキーマ推論のルールは、Parquet ファイルで使用されるルールと同じです。 SQL のネイティブ型への Delta Lake の型マッピングについては、Parquet の型マッピングに関するページを確認してください。
ファイルにアクセスできることを確認します。 ファイルが SAS キーまたはカスタム Azure ID で保護されている場合は、SQL ログインのためのサーバー レベルの資格情報を設定する必要があります。
重要
Delta Lake ファイル内の文字列値は UTF-8 エンコードを使用してエンコードされているため、UTF-8 データベース照合順序 (Latin1_General_100_BIN2_UTF8 など) を使用するようにしてください。
Delta Lake ファイル内のテキスト エンコードと照合順序が一致しないと、予期しない変換エラーが発生する可能性があります。
現在のデータベースの既定の照合順序は、 という T-SQL ステートメントを使用して簡単変更できます。
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8;照合順序の詳細については、「Synapse SQL でサポートされる照合順序の種類」を参照してください。
スキーマを明示的に指定する
OPENROWSET を使用すると、WITH 句によってファイルから読み取る列を明示的に指定できます。
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
結果セット スキーマを明示的に指定することで、型のサイズを最小化し、ペシミスティックな VARCHAR (1000) ではなく文字列型の列に対してより正確な型 VARCHAR (6) を使用できます。 型を最小化すると、クエリのパフォーマンスが大幅に向上する可能性があります。
重要
必ず WITH 句の文字列の列すべてに対して UTF-8 照合順序 (Latin1_General_100_BIN2_UTF8 など) を明示的に指定するようにしてください。または、データベース レベルで UTF-8 照合順序を設定してください。
ファイル内のテキスト エンコードと文字列の列の照合順序が一致しないと、予期しない変換エラーが発生する可能性があります。
現在のデータベースの既定の照合順序は、 という T-SQL ステートメントを使用して容易に変更できます。
alter database current collate Latin1_General_100_BIN2_UTF8
geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8という定義を使用して、列の型に照合順序を簡単に設定できます。
データセット
NYC Yellow Taxi データセットがこのサンプルで使用されます。 元の PARQUET データ セットは DELTA 形式に変換されます。この例では DELTA バージョンが使用されます。
パーティション分割されたデータに対してクエリを実行する
このサンプルで指定されたデータ セットは、個別のサブフォルダーに分割 (パーティション分割) されます。
Parquet とは異なり、FILEPATH 関数を使用して特定のパーティションを対象にする必要はありません。
OPENROWSET は、Delta Lake フォルダー構造内のパーティション分割列を識別し、これらの列を使用してデータを直接クエリできるようにします。 この例では、2017 年の最初の 3 か月について、年、月、および payment_type 別の料金が示されています。
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
OPENROWSET 関数は、where 句の year および month と一致しないパーティションを削除します。 このファイル/パーティションの排除手法では、データセットを大幅に削減し、パフォーマンスを向上させ、クエリのコストを削減できます。
OPENROWSET 関数の中にあるフォルダー名 (この例では yellow) は、DeltaLakeStorage データ ソース内の LOCATION を使用して連結され、_delta_log というサブフォルダーを含むルート Delta Lake フォルダーへの参照となっている必要があります。
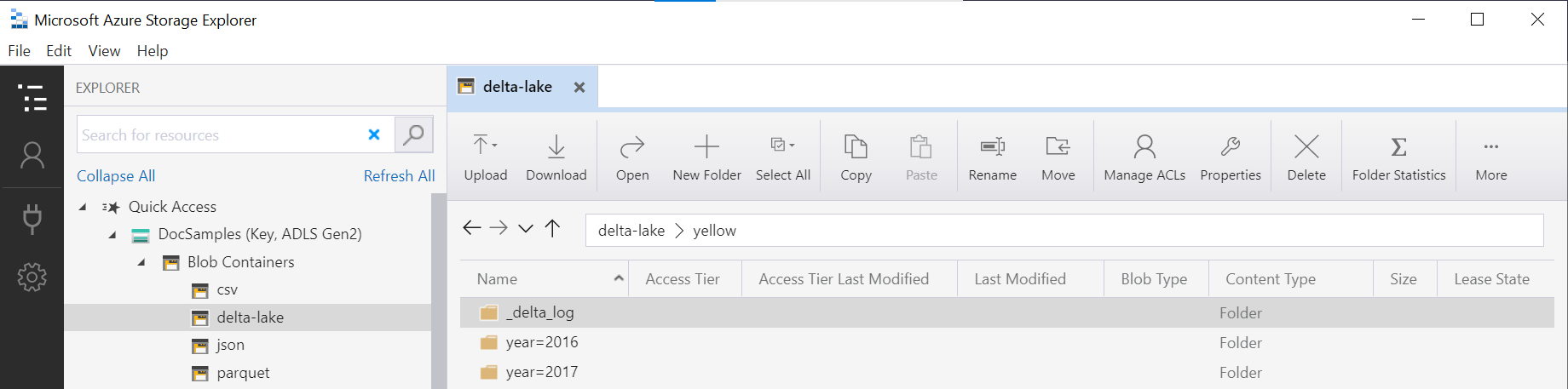
このサブフォルダーがない場合は、Delta Lake 形式が使用されていません。 次の Apache Spark Python スクリプトを使用して、フォルダー内のプレーンな Parquet ファイルを Delta Lake 形式に変換できます。
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
DeltaTable.convertToDeltaLake 関数の 2 番目の引数は、フォルダー パターン (この例では year=*/month=*) とその型の一部であるパーティション分割列 (年と月) を表します。
制限事項
- 制限事項と既知の問題については、Synapse サーバーレス SQL プールのセルフヘルプ ページをご覧ください。
関連するコンテンツ
次の記事に進んで、Parquet の入れ子にされた型に対してクエリを実行する方法を学習してください。 Delta Lake ソリューションの構築を続行する場合は、Delta Lake フォルダーにビューまたは外部テーブルを作成する方法について学習してください。