Teradata の移行の後で、Microsoft Azure に最新のデータ ウェアハウスを実装する
この記事は、Teradata から Azure Synapse Analytics に移行する方法に関するガイダンスを提供する 7 つのパートから成るシリーズのパート 7 です。 この記事では、最新のデータ ウェアハウスを実装するためのベスト プラクティスに焦点を当てます。
Azure へのデータ ウェアハウスの移行を超えて
既存のデータ ウェアハウスを Azure Synapse Analytics に移行する主な理由は、グローバルにセキュリティで保護された、スケーラブルで低コストのクラウドネイティブな従量課金制分析データベースを利用することです。 Azure Synapse では、移行したデータ ウェアハウスを完全な Microsoft Azure 分析エコシステムと統合して、その他の Microsoft テクノロジを活用したり、移行したデータ ウェアハウスを最新化したりできます。 これらのテクノロジには、次のものがあります。
コスト効果の高いデータ インジェスト、ステージング、クレンジング、変換のための Azure Data Lake Storage。 Data Lake Storage によって、急速に増加するステージング テーブルによって占有されるデータ ウェアハウス容量を解放できます。
クラウドやオンプレミスのデータ ソースやストリーミング データへのコネクタを備え、IT との連携やセルフサービスによるデータ統合を実現する Azure Data Factory。
以下のような複数のテクノロジで一貫した信頼できるデータを共有する Common Data Model。
- Azure Synapse
- Azure Synapse Spark
- Azure HDInsight
- Power BI
- Adobe Customer Experience Platform
- Azure IoT
- Microsoft ISV パートナー
以下を含む Microsoft のデータ サイエンス テクノロジ。
- Azure Machine Learning Studio
- Azure Machine Learning
- Azure Synapse Spark (サービスとしての Spark)
- Jupyter Notebooks
- RStudio
- ML.NET
- .NET for Apache Spark。これにより、データ サイエンティストが Azure Synapse データを使用して大規模に機械学習モデルをトレーニングできます。
PolyBase を使用して論理データ ウェアハウスを作成することで、大量のデータを処理し、ビッグ データを Azure Synapse データと結合するための Azure HDInsight。
Azure Synapse からのライブ ストリーミング データと統合するための Azure Event Hubs、Azure Stream Analytics、および Apache Kafka。
ビッグ データの増加により、Azure Synapse で使用するためにカスタム構築されたトレーニング済みの機械学習モデルを実現するための機械学習の需要が急激に増加しています。 機械学習モデルにより、データベース内分析をバッチ、イベントドリブン、およびオンデマンドで大規模に実行できるようになります。 また、複数の BI ツールやアプリケーションから Azure Synapse のデータベース内分析を利用できるため、一貫性のある予測と推薦事項が保証されます。
さらに、Azure Synapse を Azure 上の Microsoft パートナー ツールと統合すれば、価値を生み出すまでの時間を短縮することもできます。
これらをより詳しく見ていく中で、Azure Synapse に移行した後に、Microsoft の分析エコシステムの技術を活用してデータ ウェアハウスを最新化する方法について理解していきましょう。
Data Lake Storage と Data Factory へのオフロード データ ステージングと ETL 処理
デジタル変革により、キャプチャして分析すべき新しいデータが大量に生み出されたことで、企業にとって重要な課題が発生しています。 良い例として、モバイル デバイスからのサービス アクセスのために、オンライン トランザクション処理 (OLTP) システムを開いて作成されたトランザクション データがあります。 このデータの多くはデータ ウェアハウスに入り、OLTP システムが主なソースとなります。 従業員よりも顧客の方がトランザクション率を上昇させる要因となっている現在、データ ウェアハウスのステージング テーブルのデータは急速に増加しています。
企業へのデータの急速な流入に加え、モノのインターネット (IoT) などの新しいデータ ソースもあるため、企業はデータ統合の ETL 処理をスケールアップする必要があります。 1 つの方法が、データ ウェアハウスの最新化プログラムの一環として、データ インジェスト、データ クレンジング、変換、統合をデータ レイクにオフロードし、そこで大規模に処理する方法です。
データ ウェアハウスを Azure Synapse に移行すれば、Microsoft では Data Lake Storage にデータを取り込みステージングを行うことで、ETL 処理を最新化できます。 その後、Data Factory を使用して大規模なデータをクリーニング、変換、統合してから、PolyBase を使用して Azure Synapse に並列で読み込むことができます。
ELT 戦略では、データ ボリュームや頻度の増加に合わせて簡単にスケーリングできるように、ELT 処理を Data Lake Storage にオフロードすることを検討してください。
Microsoft Azure Data Factory
Azure Data Factory は、高度にスケーラブルな ETL および ELT 処理のための従量課金制のハイブリッド データ統合サービスです。 Data Factory には、コードなしでデータ統合パイプラインを構築するための Web ベースの UI が用意されています。 Data Factory を使用して、以下を実行できます。
コードなしでスケーラブルなデータ統合パイプラインを構築します。
大規模なデータを簡単に取得できます。
使用した分だけ支払えばよいのです。
オンプレミス、クラウド、SaaS ベースのデータ ソースに接続します。
クラウドおよびオンプレミスのデータを大規模に取り込み、移動、クリーニング、変換、統合、分析します。
オンプレミスとクラウドの両方のデータ ストアにまたがるパイプラインをシームレスに作成、監視、管理します。
顧客の増加に合わせた従量課金制のスケールアウトを実現します。
これらの機能をコードを記述せずに使用したり、Data Factory パイプラインにカスタム コードを追加したりできます。 次のスクリーンショットは、Data Factory パイプラインの 1 例を示しています。

ヒント
Data Factory を使うと、コーディングしなくても、スケーラブルなデータ統合パイプラインを構築できます。
次のようなあらゆる場所から、Data Factory パイプライン開発を実装します。
Microsoft Azure portal。
Microsoft Azure PowerShell。
複数言語 SDK を使用して .NET と Python からプログラムで実行する。
Azure Resource Manager (ARM) テンプレート。
REST API。
ヒント
Data Factory では、オンプレミス、クラウド、SaaS のデータに接続できます。
コードを記述することを好む開発者やデータ サイエンティストは、Java、Python、.NET のプログラミング言語で使用できるソフトウェア開発キット (SDK) を使用して、これらの言語で Data Factory パイプラインを簡単に作成できます。 Data Factory パイプラインは、オンプレミスのデータ センター、Microsoft Azure、その他のクラウド、SaaS オファリングのデータの接続、取り込み、クリーニング、変換、分析を行うことができるため、ハイブリッド データ パイプラインにすることができます。
データを統合および分析する Data Factory パイプラインを開発した後、それらのパイプラインをグローバルに展開し、バッチで実行するようにスケジュールしたり、サービスとしてオンデマンドで呼び出したり、イベントドリブン ベースでリアルタイムで実行したりできます。 Data Factory パイプラインは、1 つまたは複数の実行エンジン上で実行し、実行を監視してパフォーマンスを確保し、エラーを追跡することもできます。
ヒント
Azure Data Factory では、データの統合と分析はパイプラインで制御します。 Data Factory は、ビジネス ユーザー向けのデータ ラングリング機能を備えた IT プロフェッショナル向けのエンタープライズ クラスのデータ統合ソフトウェアです。
ユース ケース
Data Factory では、次のような複数のユース ケースがサポートされています。
クラウドおよびオンプレミスのデータ ソースからデータを準備、統合、エンリッチし、Microsoft Azure Synapse 上に移行したデータ ウェアハウスやデータ マートのデータを充実させる。
機械学習モデルの開発や分析モデルの再トレーニングに使用するトレーニング データを生成するために、クラウドおよびオンプレミスのデータ ソースからデータを準備、統合、およびエンリッチする。
データ準備と分析のオーケストレーションを行い、センチメント分析など、バッチ処理でデータを処理および分析するための予測および模範的な分析パイプラインを作成する。 分析結果に基づいて対策を講じるか、データ ウェアハウスに分析結果を追加する。
Azure Cosmos DB などの運用データ ストアを基に、Azure クラウド上で動作するデータドリブンのビジネス アプリケーションデータを用のデータを準備、統合、リッチ化する。
ヒント
データ サイエンスでトレーニング データ セットを構築して、機械学習モデルを開発します。
データ ソース
Data Factory では、クラウドとオンプレミスの両方のデータ ソースのコネクタを使用できます。 "セルフホステッド統合ランタイム" と呼ばれるエージェント ソフトウェアによって、オンプレミスのデータ ソースに安全にアクセスし、セキュリティで保護されたスケーラブルなデータ転送をサポートしています。
Azure Data Factory を使用してデータを変換する
Data Factory パイプライン内で、取り込み、クリーンアップ、変換、統合を行い、これらのソースから任意の種類のデータを分析します。 データは、構造化、JSON や Avro などの半構造化、または非構造化にすることができます。
プロの ETL 開発者は、Data Factory のマッピング データ フローを使用することで、データのフィルター処理、分割、いくつかの型の結合、ルックアップ、ピボット、ピボット解除、並べ替え、和集合、集計を、コードを一切記述することなく行うことができます。 さらに、Data Factory では、代理キーや、挿入、アップサート、更新、テーブルの再作成、テーブルの切り捨てなどの複数の書き込み処理オプション、および複数の種類のターゲット データ ストア (シンクとも呼ばれます) がサポートされています。 ETL 開発者は、データ列にウィンドウを配置する必要がある時系列集計などの集計を作成することもできます。
ヒント
プロの ETL 開発者は、Data Factory のマッピング データ フローを使用して、コードを記述することなく、データのクリーンアップ、変換、統合を行うことができます。
Data Factory パイプラインでデータをアクティビティとして変換するマッピング データ フローを実行でき、必要に応じて 1 つのパイプラインに複数のマッピング データ フローを含めることができます。 このようにして、困難なデータ変換と統合タスクを、組み合わせることができる小さなマッピング データフローに分割することで、複雑さに対処できます。 また、必要に応じてカスタム コードを追加できます。 この機能に加えて、Data Factory マッピング データ フローには次の機能があります。
データのクリーニングと変換、集計の計算、データのエンリッチを行う式を定義します。 たとえば、これらの式で、日付フィールドに特徴エンジニアリングを実行して、複数のフィールドに分割して、機械学習モデルの開発時にトレーニング データを作成できます。 数学、テンポラル、分割、マージ、文字列連結、条件、パターン一致、置換、およびその他の多くの関数を含む豊富な関数セットから式を構築できます。
データ変換パイプラインがデータ ソースのスキーマ変更の影響を受けないように、スキーマ ドリフトを自動的に処理します。 この機能は、デバイスがアップグレードされるか、IoT データを収集するゲートウェイ デバイスの読み取りミスがあった場合に、予告なくスキーマが変更される可能性があるストリーミング IoT データにとって特に重要です。
データをパーティション分割して、大規模に並列で変換を実行できるようにします。
ストリーミング データを検査して、変換するストリームのメタデータを表示します。
ヒント
Data Factory では、受信データ (ストリーミング データなど) のスキーマ変更を自動的に検出して管理する機能がサポートされています。
次のスクリーンショットは、Data Factory マッピング データ フローの例を示しています。

データ エンジニアは、開発時にデバッグ機能を有効にしておくことで、データ品質をプロファイリングし、個々のデータ変換の結果を表示できます。
ヒント
Data Factory では、ETL 処理を大規模に実行できるようにデータをパーティション分割することもできます。
必要な場合、コードを含むリンク サービスをパイプラインに追加することで、Data Factory の変換機能と分析機能を拡張できます。 たとえば、Azure Synapse Spark プール ノートブックには、トレーニングされたモデルを使用して、マッピング データ フローによって統合されたデータをスコア付けできる Python コードが含まれていることがあります。
統合データと、Data Factory パイプライン内部の分析からのあらゆる結果を、Data Lake Storage、Azure Synapse、HDInsight の Hive テーブルなどの 1 つ以上のデータ ストアに格納できます。 また、Data Factory 分析パイプラインによって生成された分析情報に基づいて動作する他のアクティビティを呼び出すこともできます。
ヒント
Data Factory では、独自のコードを記述してパイプラインの一部として実行することができるため、Data Factory パイプラインには拡張性があります。
Spark を使用してデータ統合をスケーリングする
Data Factory は実行時に、Azure Synapse Spark プール (Microsoft のサービスとしての Spark オファリング) を内部的に利用して、Azure クラウド内のデータをクリーンアップして統合しています。 大量かつ高速なデータ (クリック ストリーム データなど) を大規模にクリーンアップ、統合、分析できます。 Microsoft の目的は、他の Spark ディストリビューションでも Data Factory パイプラインを実行することです。 Data Factory を使用すると、Spark 上で ETL ジョブを実行できるだけでなく、Pig スクリプトや Hive クエリを呼び出して、HDInsight に保存されているデータにアクセスし、変換することができます。
ラングリング データ フローを使用してセルフサービス データ準備と Data Factory ETL 処理をリンクする
データ ラングリングにより、ビジネス ユーザー (シティズン データ インテグレーターやデータ エンジニアとも呼ばれます) は、このプラットフォームを利用して、コードを記述せずに大規模なデータを視覚的に検出、探索、準備できます。 この Data Factory 機能は使いやすく、セルフサービス ビジネス ユーザーがドロップダウン変換を含むスプレッドシートスタイルの UI を使用してデータを準備し統合できる、Microsoft Excel Power Query または Microsoft Power BI データフローに似ています。 次のスクリーンショットは、Data Factory ラングリング データ フローの例を示しています。

Excel や Power BI とは異なり、Data Factory ラングリング データ フローでは、Power Query を使用して M コードを生成した後、クラウド規模で実行するために超並列メモリ内 Spark ジョブに変換します。 Data Factory のマッピング データ フローとラングリング データ フローの組み合わせにより、プロの ETL 開発者とビジネス ユーザーは共同作業を行い、一般的なビジネス目的のためにデータを準備、統合、分析できます。 前述の Data Factory マッピング データ フロー図は、Data Factory と Azure Synapse Spark プール ノートブックの両方を同じ Data Factory パイプラインで組み合わせる方法を示しています。 Data Factory でのマッピング データ フローとラングリング データ フローの組み合わせにより、IT ユーザーとビジネス ユーザーは、それぞれが作成したデータ フローを把握し、データ フローの再利用をサポートして、再発明を最小限に抑え、生産性と一貫性を最大限に高めます。
ヒント
Data Factory では、ラングリング データ フローとマッピング データ フローの両方がサポートされているため、ビジネス ユーザーと IT ユーザーは共通のプラットフォームでデータを共同で統合できます。
分析パイプラインでデータと分析をリンクする
データのクリーニングと変換に加えて、Data Factory では同じパイプラインにデータ統合と分析を組み合わせることができます。 Data Factory を使用して、データ統合と分析の両方のパイプラインを作成できます。後者は前者の拡張機能です。 分析モデルをパイプラインにドロップして、予測または推奨事項のためのクリーンで統合されたデータを生成する分析パイプラインを作成できます。 その後、予測または推奨事項にすぐに対応するか、これらをデータ ウェアハウスに格納して、BI ツールで表示できる新しい分析情報と推奨事項を提供できます。
データのバッチ スコアリングを行うために、Data Factory パイプライン内でサービスとして呼び出す分析モデルを開発できます。 Azure Machine Learning スタジオでコードを使わずに、または Azure Synapse Spark プール ノートブックや RStudio で R を使って Azure Machine Learning SDK で、分析モデルを開発できます。 Azure Synapse Spark プール ノートブックで Spark 機械学習パイプラインを実行すると、分析は大規模に行われます。
統合データと、あらゆる Data Factory 分析パイプライン結果を、Data Lake Storage、Azure Synapse、HDInsight の Hive テーブルなどの 1 つ以上のデータ ストアに格納できます。 また、Data Factory 分析パイプラインによって生成された分析情報に基づいて動作する他のアクティビティを呼び出すこともできます。
一貫性のある信頼できるデータを共有するレイク データベースを使用する
データ統合セットアップの主な目的は、データを 1 回統合し、データ ウェアハウスだけでなく、あらゆる場所で再利用できることです。 たとえば、統合データをデータ サイエンスで使用できます。 再利用により、再発明が回避され、誰もが信頼できる一貫性のある一般的に理解されるデータが確保されます。
Common Data Model では、企業全体で共有および再利用できるコア データ エンティティについて説明します。 再利用を実現するために、Common Data Model では、論理データ エンティティを記述する一連の共通データ名と定義が確立されます。 一般的なデータ名の例としては、Customer (顧客)、Account (取引先企業)、Product (製品)、Supplier (仕入れ先)、Orders (受注)、Payments (支払い)、Returns (返品) などがあります。 IT プロフェッショナルとビジネス プロフェッショナルは、データ統合ソフトウェアを使用して、共通データ資産を作成して保存し、最大限に再利用し、あらゆる場所で一貫性を高めることができます。
Azure Synapse では、レイク内のデータの標準化に役立つ業界固有のデータベース テンプレートを提供しています。 レイク データベース テンプレートは、定義済みのビジネス領域向けにスキーマを提供し、構造化された方法でデータをレイク データベースに読み込むことができるようにします。 この機能は、データ統合ソフトウェアを使用してレイク データベースの共通データ資産を作成するときに利用され、その結果、アプリケーションや分析システムで使用できる自己記述的な信頼できるデータとなります。 Data Factory を使用して、Data Lake Storage に共通のデータ資産を作成できます。
ヒント
Data Lake Storage は、Microsoft Azure Synapse、Azure Machine Learning、Azure Synapse Spark、HDInsight を支える共有ストレージです。
Power BI、Azure Synapse Spark、Azure Synapse、Azure Machine Learning では、共通のデータ資産を使用できます。 次の図は、Azure Synapse でレイク データベースを使用できる方法を示しています。
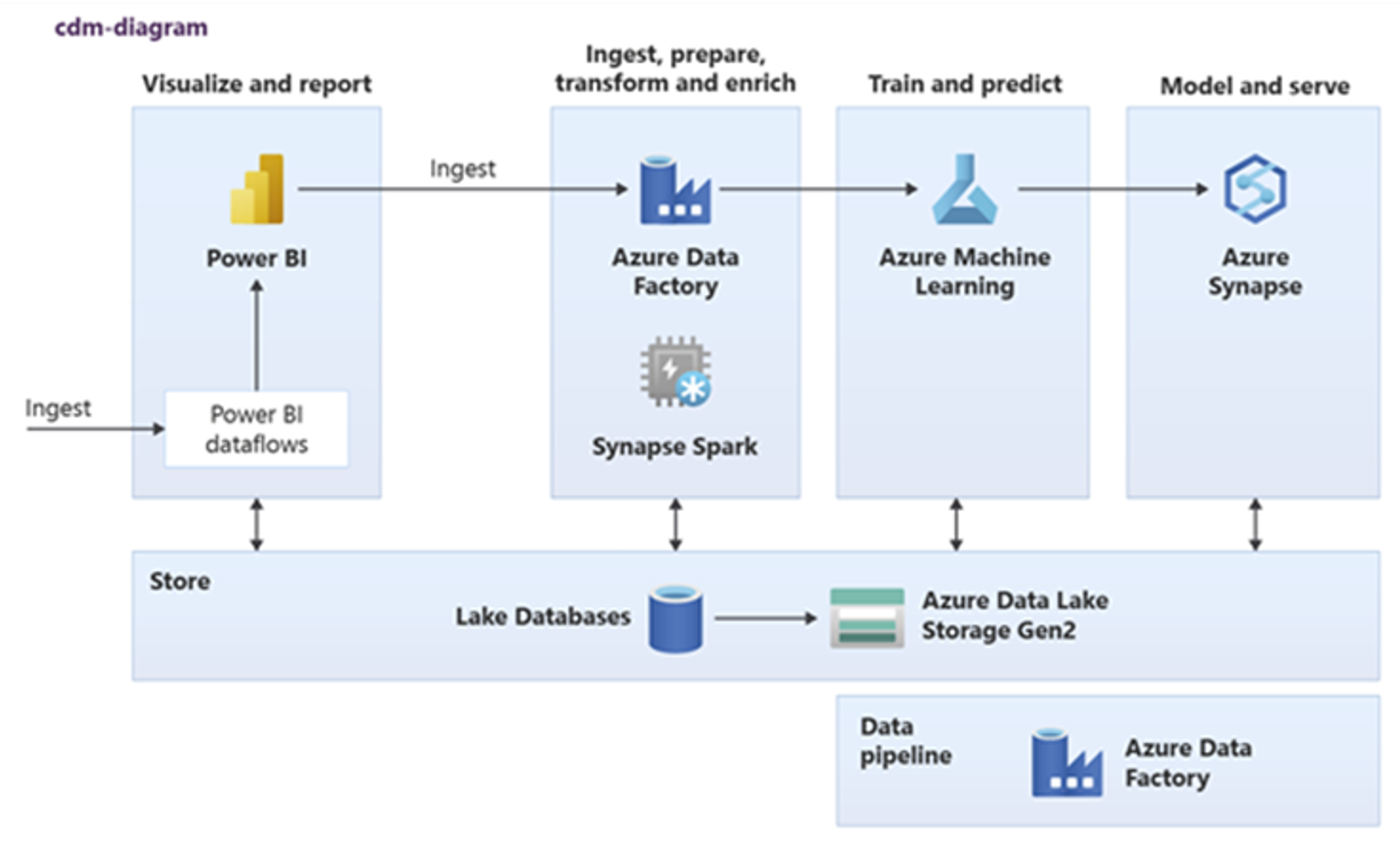
ヒント
共通データ資産を最大限に再利用するには、データを統合して、共有ストレージにレイク データベース論理エンティティを作成してください。
Azure での Microsoft データ サイエンス テクノロジとの統合
データ ウェアハウスを最新化する際のもう 1 つの重要な目的は、競争上の優位性を得るための分析情報を生成することです。 移行したデータ ウェアハウスを、Azure の Microsoft およびサードパーティのデータ サイエンス テクノロジと統合することで、分析情報を生成できます。 次のセクションでは、Microsoft が提供する機械学習とデータ サイエンス テクノロジについて説明し、これらを最新のデータ ウェアハウス環境で Azure Synapse とともにどのように使用できるかを見ていきます。
Azure のデータ サイエンスのための Microsoft テクノロジ
Microsoft からは、高度な分析をサポートするさまざまなテクノロジが提供されています。 これらのテクノロジを使用すると、機械学習を使用して予測分析モデルを構築したり、ディープ ラーニングを使用して非構造化データを分析したりできます。 このテクノロジには、次のものがあります。
Azure Machine Learning Studio
Azure Machine Learning
Azure Synapse Spark プール ノートブック
ML.NET (API、CLI、または ML.NET Model Builder for Visual Studio)
.NET for Apache Spark
データ サイエンティストは、RStudio (R) と Jupyter Notebook (Python) を使用して分析モデルを開発することも、Keras や TensorFlow などのフレームワークを使用することもできます。
ヒント
コードなしまたはコード量が少ないアプローチを使用するか、Python、R、.NET などのプログラミング言語を使用して、機械学習モデルを開発します。
Azure Machine Learning Studio
Azure Machine Learning Studio は、ドラッグ アンド ドロップによる Web ベースの UI を介して、予測分析を構築、デプロイ、共有できるフル マネージド クラウド サービスです。 次のスクリーンショットは、Azure Machine Learning Studio の UI を示しています。

Azure Machine Learning
Azure Machine Learning には、データを速やかに準備し、機械学習モデルをトレーニングしてデプロイするのに役立つ、Python 用の SDK とサービスが用意されています。 Azure Machine Learning は、Jupyter Notebook を使用する Azure Notebooks で使用でき、PyTorch、TensorFlow、scikit-learn、Spark MLlib (Spark 用機械学習ライブラリ) などのオープンソース フレームワークを使用できます。
ヒント
Azure Machine Learning には、いくつかのオープンソース フレームワークを使用して機械学習モデルを開発するための SDK が用意されています。
また、Azure Machine Learning を使用して、エンドツーエンドのワークフローを管理し、プログラムによってクラウドでスケーリングし、クラウドとエッジの両方にモデルをデプロイする機械学習パイプラインを構築することもできます。 Azure Machine Learning には、Azure portal でプログラムまたは手動によって作成できる論理スペースであるワークスペースが含まれています。 これらのワークスペースは、コンピューティング ターゲット、実験、データ ストア、トレーニング済みの機械学習モデル、Docker イメージ、デプロイ済みのサービスをすべて 1 か所に保持して、チームが共同で作業できるようにします。 Azure Machine Learning は、Visual Studio for AI 拡張機能を備えた Visual Studio から使用できます。
ヒント
関連するデータ ストア、実験、トレーニング済みモデル、Docker イメージ、およびデプロイ済みのサービスをワークスペースに整理して管理します。
Azure Synapse Spark プール ノートブック
Azure Synapse Spark プール ノートブックは、Azure に最適化された Apache Spark サービスです。 Azure Synapse Spark プール ノートブックでは、次のことが可能です。
データ エンジニアは、Data Factory を使用してスケーラブルなデータ準備ジョブを構築して実行できます。
データ サイエンティストは、Scala、R、Python、Java、SQL などの言語で記述されたノートブックを使用して大規模な機械学習モデルを構築して実行し、結果を視覚化できます。
ヒント
Azure Synapse Spark は、Microsoft によって提供された、動的にスケーラブルなサービスとしての Spark であり、データ準備のスケーラブルな実行、モデル開発、デプロイ済みモデル実行を提供します。
Azure Synapse Spark プール ノートブックで実行されているジョブでは、Azure Blob Storage、Data Lake Storage、Azure Synapse、HDInsight、および Apache Kafka などのストリーミング データ サービスから大規模にデータを取得、処理、分析できます。
ヒント
Azure Synapse Spark では、Azure 上のさまざまな Microsoft 分析エコシステム データ ストア内のデータにアクセスできます。
Azure Synapse Spark プール ノートブックでは、総保有コスト (TCO) を削減するために自動スケーリングと自動終了がサポートされています。 データ サイエンティストは、MLflow オープンソース フレームワークを使用して機械学習ライフサイクルを管理できます。
ML.NET
ML.NET は、Windows、Linux、macOS 用のオープンソースでクロスプラットフォームの機械学習フレームワークです。 Microsoft は、.NET 開発者が ML.NET Model Builder for Visual Studio などの既存のツールを使用してカスタム機械学習モデルを開発し、それらを .NET アプリケーションに統合できるように ML.NET を作成しました。
ヒント
Microsoft は、その機械学習機能を .NET 開発者まで拡張しました。
.NET for Apache Spark
.NET for Apache Spark は、Spark のサポートを、R、Scala、Python、Java を超えて .NET まで拡張し、すべての Spark API で .NET 開発者が Spark にアクセスできるようにすることを目的としています。 .NET for Apache Spark は現在、HDInsight の Apache Spark でのみ使用できますが、Microsoft では、.NET for Apache Spark を Azure Synapse Spark プール ノートブックで使用できるようにする予定です。
データ ウェアハウスで Azure Synapse Analytics を使用する
機械学習モデルを Azure Synapse と組み合わせるために、次のことができます。
ストリーミング データに対してバッチ モードまたはリアルタイムで機械学習モデルを使用して、新しい分析情報を生成し、それらの分析情報を Azure Synapse で既知のものに追加します。
Azure Synapse のデータを使用して、他のアプリケーションなどの別の場所にデプロイするための新しい予測モデルを開発およびトレーニングします。
データ ウェアハウス内のデータを分析し、新しい事業価値を推進するために、他のあらゆる場所でトレーニングされたモデルを含む機械学習モデルを Azure Synapse にデプロイします。
ヒント
Azure Synapse のデータを使用して、Azure Synapse Spark プール ノートブックで機械学習モデルを大規模にトレーニング、テスト、評価、実行します。
データ サイエンティストは、RStudio、Jupyter Notebook、Azure Synapse Spark プール ノートブックを Azure Machine Learning と共に使用して、Azure Synapse のデータを使用して Azure Synapse Spark プール ノートブックで大規模に実行される機械学習モデルを開発できます。 たとえば、データ サイエンティストはさまざまなマーケティング キャンペーンを推進するために、顧客をセグメント化する教師なしモデルを作成できます。 教師あり機械学習を使用してモデルをトレーニングし、顧客のチャーンの傾向を予測したり、顧客が価値を高めるために次のベストなオファーを推奨したりするなど、特定の結果を予測します。 次の図は、Azure Synapse を Azure Machine Learning に利用する方法を示しています。
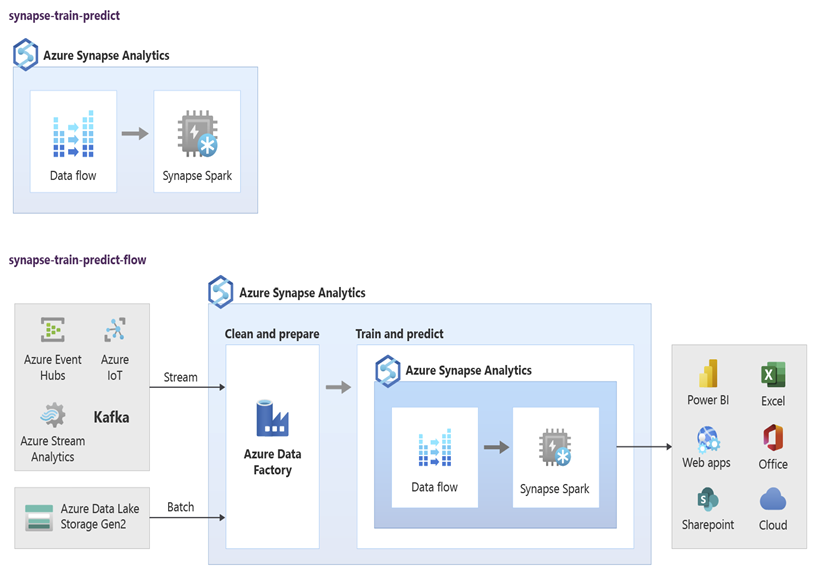
別のシナリオでは、ソーシャル ネットワーク データやレビュー Web サイト データを Data Lake Storage に取り込み、自然言語処理を使用してデータを Azure Synapse Spark プール ノートブックで大規模に準備および分析し、製品やブランドに関する顧客のセンチメントをスコアリングできます。 その後、それらのスコアをデータ ウェアハウスに追加できます。 ビッグ データ分析を使用して、製品の売上に対する否定的なセンチメントの影響を理解することで、データ ウェアハウス内の既知の内容に追加します。
ヒント
Azure の機械学習を使用して新しい分析情報をバッチまたはリアルタイムで生成し、データ ウェアハウスで既知のものに追加します。
ライブ ストリーミング データを Azure Synapse Analytics に統合する
最新のデータ ウェアハウス内のデータを分析する場合は、ストリーミング データをリアルタイムで分析し、データ ウェアハウス内の履歴データと結合できる必要があります。 例として、IoT データと製品または資産データを組み合わせることがあります。
ヒント
データ ウェアハウスを IoT デバイスまたはクリックストリームからのストリーミング データと統合します。
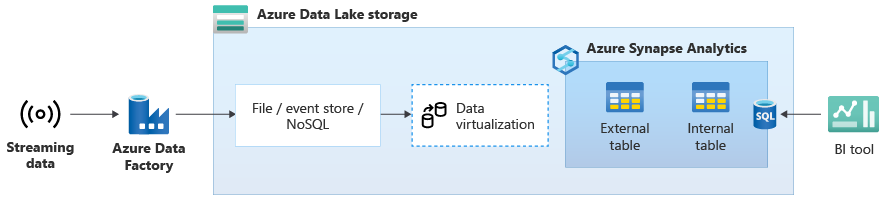
データ ウェアハウスを Azure Synapse に正常に移行したら、Azure Synapse の追加機能を利用して、データ ウェアハウスの最新化演習の一環としてライブ ストリーミング データ統合を導入できます。 そのためには、Event Hubs、Apache Kafka などの他のテクノロジ、または可能ならば既存の ETL ツール (ストリーミング データ ソースをサポートしている場合) を使用して、ストリーミング データを取り込みます。 データを Data Lake Storage に格納します。 次に、PolyBase を使用して Azure Synapse に外部テーブルを作成し、Data Lake Storage にストリーミングされるデータにそれをポイントして、リアルタイム ストリーミング データへのアクセスを提供する新しいテーブルがデータ ウェアハウスに含まれるようにします。 Azure Synapse にアクセスできる任意の BI ツールの標準 T-SQL を使用して、データがデータ ウェアハウスにあるかのように、この外部テーブルに対してクエリを実行します。 また、ストリーミング データを履歴データを含む他のテーブルに結合し、ライブ ストリーミング データを履歴データに結合するビューを作成して、ビジネス ユーザーが簡単にデータにアクセスできるようにすることもできます。
ヒント
Event Hubs または Apache Kafka から Data Lake Storage にストリーミング データを取り込み、PolyBase 外部テーブルを使用して Azure Synapse からデータにアクセスします。
次の図では、Azure Synapse 上のリアルタイム データ ウェアハウスが、Data Lake Storage 内のストリーミング データと統合されています。
PolyBase を使用して論理データ ウェアハウスを作成する
PolyBase を使用すると、多数の分析データ ストアへのユーザー アクセスを簡素化する論理データ ウェアハウスを作成できます。 多くの企業では、データ ウェアハウスに加えて、過去数年にわたって "ワークロード最適化" 分析データ ストアを採用しています。 Azure 上の分析プラットフォームには、次のものがあります。
ビッグ データ分析用の Azure Synapse Spark プール ノートブック (サービスとしての Spark) を備える Data Lake Storage。
同様にビッグ データ分析用の HDInsight (サービスとしての Hadoop)。
Azure Cosmos DB で実行できるグラフ分析用の NoSQL Graph データベース
移動中のデータのリアルタイム分析用の Event Hubs と Stream Analytics。
また、これらのプラットフォームの Microsoft 以外の同等製品や、顧客、サプライヤー、製品、資産などに関する一貫した信頼できるデータを得るためにアクセスする必要があるマスター データ管理 (MDM) システムがある場合もあります。
ヒント
PolyBase により、Azure 上の多数の基になる分析データ ストアへのアクセスが簡素化され、ビジネス ユーザーがアクセスしやすくなります。
これらの分析プラットフォームは、企業の内部と外部の新しいデータ ソースが急増し、新しいデータをキャプチャして分析したいというビジネス ユーザーの要求のために出現しました。 新しいデータ ソースには次のようなものがあります。
IoT センサー データやクリックストリーム データなど、マシンによって生成されたデータ。
ソーシャル ネットワーク データ、レビュー Web サイト データ、顧客の受信メール、画像、ビデオなどの人間が生成したデータ。
その他の外部データ (公開されている政府のデータや気象データなど)。
この新しいデータは、通常はデータ ウェアハウスにフィードする構造化トランザクション データやメイン データ ソースの範囲を超え、多くの場合は次のものが含まれています。
- JSON、XML、Avro などの半構造化データ。
- テキスト、音声、画像、動画などの非構造化データ。処理と分析がより複雑になります。
- 大量のデータ、高速データ、またはその両方。
その結果、自然言語処理、グラフ分析、ディープ ラーニング、ストリーミング分析、大量の構造化データの複雑な分析など、より複雑な新しい種類の分析が発生しています。 これらの種類の分析は、一般に、データ ウェアハウスでは発生しないため、この図に示すように、さまざまな種類の分析ワークロード用のさまざまな分析プラットフォームが見られるのは驚くべきことではありません。
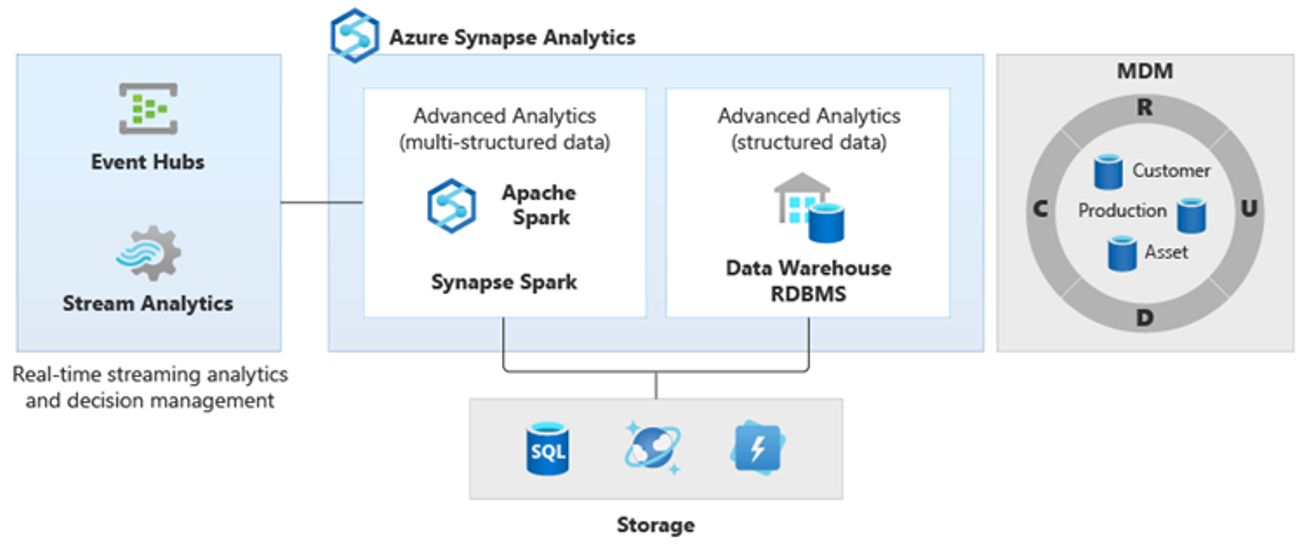
ヒント
複数の分析データ ストア内のデータがすべて 1 つのシステム内にあるように見せ、それを Azure Synapse に結合する機能は、論理データ ウェアハウス アーキテクチャと呼ばれます。
これらのプラットフォームでは新しい分析情報が生成されるため、新しい分析情報を Azure Synapse で既知のものと組み合わせる要件が発生することは当然のことであり、PolyBase を使うとそれが可能です。
Azure Synapse 内で PolyBase のデータ仮想化を使用することで、論理データ ウェアハウスを実装できます。それにより、Azure Synapse 内のデータは、HDInsight などの他の Azure やオンプレミスの分析データ ストア内のデータ、Azure Cosmos DB 内のデータ、または Stream Analytics や Event Hubs から Data Lake Storage に流れ込むストリーミング データに結合されます。 この方法により、ユーザーに対する複雑さが低下します。ユーザーは、Azure Synapse で外部テーブルにアクセスし、アクセスしているデータが複数の基になる分析システムに格納されていることを知る必要はありません。 次の図は、比較的シンプルでも強力な UI メソッドを使用してアクセスされる複雑なデータ ウェアハウス構造を示しています。
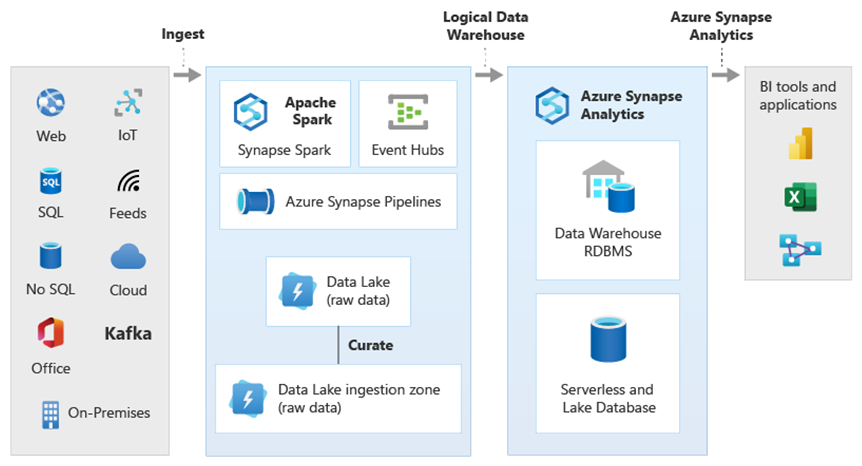
この図では、Microsoft 分析エコシステムの他のテクノロジと Azure Synapse の論理データ ウェアハウス アーキテクチャの機能を組み合わせる方法が示されています。 たとえば、データを Data Lake Storage に取り込み、Data Factory を使ってデータをキュレーションして、Microsoft のレイク データベースの論理データ エンティティを表す信頼できるデータ製品を作成できます。 この信頼でき、一般的に解釈できるデータは、Azure Synapse、Azure Synapse Spark プール ノートブック、Azure Cosmos DB など、さまざまな分析環境で使用および再利用できます。 これらの環境で生成されるすべての分析情報には、PolyBase によって可能にされた論理データ ウェアハウス データ仮想化レイヤーを介してアクセスできます。
ヒント
論理データ ウェアハウス アーキテクチャにより、ビジネス ユーザーによるデータへのアクセスが簡素化され、データ ウェアハウス内の既知のものに新しい価値が加えられます。
まとめ
データ ウェアハウスを Azure Synapse Analytics に移行した後は、Microsoft 分析エコシステムの他のテクノロジを利用できます。 そうすることで、データ ウェアハウスを最新化するだけでなく、他の Azure 分析データ ストアで生成された分析情報を統合された分析アーキテクチャに組み合わせます。
ETL 処理を拡張して、あらゆる種類のデータを Data Lake Storage に取り込んでから、Data Factory を使用して大規模に準備および統合し、信頼できて一般的に理解できるデータ資産を作成できます。 それらの資産は、データ ウェアハウスで使用でき、データ サイエンティストやその他のアプリケーションからアクセスできます。 リアルタイムでバッチ指向の分析パイプラインを構築し、機械学習モデルを作成して、バッチで、ストリーミング データに対してリアルタイムに、サービスとしてオンデマンドで実行することができます。
PolyBase または COPY INTO を使ってデータ ウェアハウスの範囲を超え、Azure 上の複数の基になる分析プラットフォームの分析情報に簡単にアクセスできます。 これを行うには、ストリーミング、ビッグ データ、従来のデータ ウェアハウスの分析情報に BI ツールやアプリケーションからアクセスすることをサポートする、総合的な統合ビューを論理データ ウェアハウスに作成します。
データ ウェアハウスを Azure Synapse に移行することで、Azure で実行されている豊富な Microsoft 分析エコシステムを利用して、ビジネスの新しい価値を促進できます。
次のステップ
専用 SQL プールへの移行については、「Azure Synapse Analytics 専用 SQL プールへデータ ウェアハウスを移行する」をご覧ください。