Oracle 移行の設計とパフォーマンス
この記事は、Oracle から Azure Synapse Analytics に移行する方法に関するガイダンスを提供する 7 つのパートから成るシリーズのパート 1 です。 この記事での焦点は、設計とパフォーマンスのベスト プラクティスです。
概要
レガシのオンプレミス Oracle 環境の保守とアップグレードのコストと複雑さのために、既存の Oracle ユーザーの多くは、最新のクラウド環境によって提供されるイノベーションを活用したいと考えています。 サービスとしてのインフラストラクチャ (IaaS) とサービスとしてのプラットフォーム (PaaS) クラウド環境を使用すると、インフラストラクチャのメンテナンスやプラットフォーム開発などのタスクをクラウド プロバイダーに委任できます。
ヒント
Azure 環境には、データベースだけでなく、包括的な一連の機能とツールが用意されています。
Oracle と Azure Synapse Analytics は両方とも、極度に大規模なデータ量に対して高いクエリ パフォーマンスを実現するために、超並列処理 (MPP) 手法を使用する SQL データベースですが、アプローチには基本的な違いがいくつかあります。
多くの場合、レガシ Oracle システムは、比較的コストの高いハードウェアを使用してオンプレミスにインストールされます。一方、Azure Synapse は Azure ストレージとコンピューティング リソースを使用したクラウドベースです。
Oracle 構成のアップグレードは、物理ハードウェアの追加や、長時間かかる可能性のあるデータベースの再構成またはダンプと再読み込みを伴う大規模なタスクです。 ストレージとコンピューティング リソースは Azure 環境では分離されていて、エラスティック スケーリング機能があるため、これらのリソースは、独立してスケーリング (アップまたはダウン) できます。
必要に応じて Azure Synapse を一時停止したりそのサイズを変更したりして、リソースの使用率とコストを削減できます。
Microsoft Azure は、グローバルに使用できる、高度なセキュリティで保護されたスケーラブルなクラウド環境であり、Azure Synapse とサポート ツールおよび機能のエコシステムが組み込まれています。 次の図は、Azure Synapse エコシステムをまとめたものです。
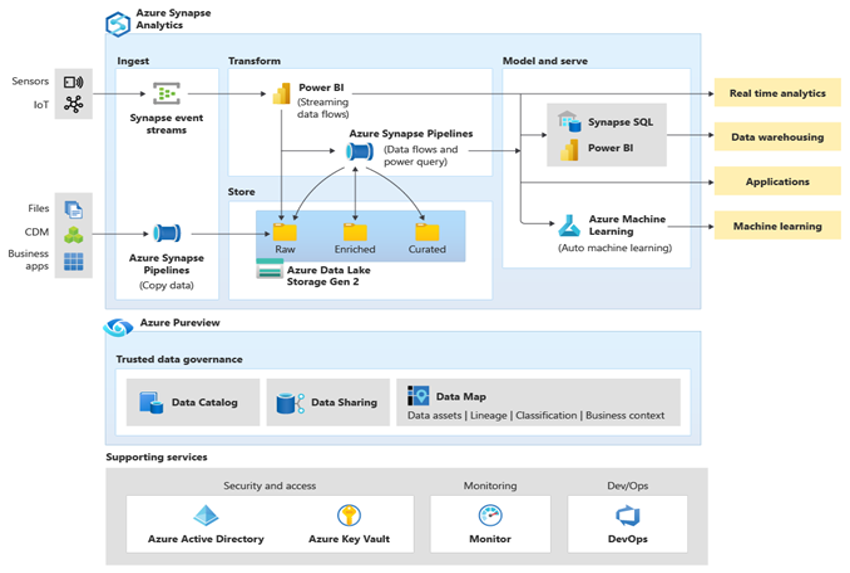
Azure Synapse では、MPP や自動メモリ内キャッシュなどの手法を使用して、最高のリレーショナル データベース パフォーマンスを実現しています。 これらの手法の結果は、独立したベンチマークで確認できます。たとえば、GigaOm によって最近実施されたものでは、Azure Synapse が他の一般的なクラウド データ ウェアハウス オファリングと比較されています。 Azure Synapse 環境に移行するお客様には、次のような多くの利点があります。
パフォーマンスと費用対効果の向上。
機敏性の向上と価値実現までの時間の短縮。
より高速なサーバーのデプロイとアプリケーション開発。
実際の使用量に対してのみ課金される柔軟なスケーラビリティ。
セキュリティ/コンプライアンスの向上。
ストレージとディザスター リカバリーのコスト削減。
全体的な TCO の削減、コスト管理の向上、運用支出 (OPEX) の合理化。
このような利点を最大限に活用するには、新規または既存のデータとアプリケーションを Azure Synapse プラットフォームに移行します。 多くの組織で、移行には、Oracle などのレガシ オンプレミス プラットフォームから Azure Synapse への既存のデータ ウェアハウスの移動が含まれます。 おおまかに、移行プロセスには次の手順が含まれます。
準備 🡆
スコープ (移行する対象) を定義する。
移行のためのデータとプロセスのインベントリを作成する。
データ モデルの変更を定義する (ある場合)。
ソース データ抽出メカニズムを定義する。
使用する適切な Azure およびサードパーティのツールと機能を特定する。
新しいプラットフォームのスタッフ トレーニングを早期に実施する。
Azure のターゲット プラットフォームをセットアップする。
移行 🡆
小規模で簡単なものから始める。
可能な限り、処理を自動化します。
Azure の組み込みツールと機能を活用して移行の労力を減らす。
テーブルとビューのメタデータを移行する。
維持する履歴データを移行する。
ストアド プロシージャとビジネス プロセスを移行またはリファクタリングする。
ETL/ELT の段階的読み込みプロセスを移行またはリファクタリングする。
移行後
プロセスのすべてのステージを監視してドキュメント化する。
今後の移行のため、得られた経験を利用してテンプレートを作成する。
必要な場合、(新しいプラットフォームのパフォーマンスとスケーラビリティを使用して) データ モデルを再エンジニアリングする。
アプリケーションとクエリ ツールをテストする。
クエリ パフォーマンスのベンチマークと最適化を行う。
この記事では、データ ウェアハウスを既存の Oracle 環境から Azure Synapse に移行するときのパフォーマンスの最適化に関する一般的な情報とガイドラインを示します。 パフォーマンスの最適化の目的は、移行後に Azure Synapse で同等以上のデータ ウェアハウスのパフォーマンスを実現することです。
設計上の考慮事項
移行のスコープ
Oracle 環境から移行する準備をしているときに、次の移行の選択肢を検討してください。
初期移行のワークロードを選択する
レガシ Oracle 環境は通常、時間の経過とともに進化して、複数の主題領域と混合ワークロードを含むようになります。 移行プロジェクトをどこから開始するのかを決定するときに、次の作業が可能になる領域を選択します。
新しい環境の利点を迅速に提供することで、Azure Synapse への移行の実現可能性が証明される。
社内の技術スタッフが、他の領域を移行するときに使用するプロセスとツールに関する経験を得ることができる。
さらに移行を行うために、ソース Oracle 環境と既に配置済みの現在のツールおよびプロセスに固有のテンプレートを作成する。
Oracle 環境からの初期移行の適切な候補とは、上記の項目をサポートし、次を満たすものです。
オンライン トランザクション処理 (OLTP) ワークロードではなく、BI/Analytics ワークロードを実装する。
スターやスノーフレークのスキーマなどの、最小限の変更で移行できるデータ モデルが使用されている。
ヒント
移行する必要があるオブジェクトのインベントリを作成し、移行プロセスを文書化してください。
初期移行で移行されるデータの量は、Azure Synapse 環境の機能と利点を示すために十分な大きさに、ただし、価値をすばやく示すために大きすぎないようにする必要があります。 1 から 10 テラバイトの範囲のサイズが一般的です。
移行プロジェクトに対する最初のアプローチは、Azure クラウド環境の利点をすばやく確認できるように、必要なリスク、労力、時間を最小限に抑えることです。 次のアプローチでは、初期移行の範囲をデータ マートのみに制限し、ETL 移行や履歴データ移行などのより広範な移行の側面には対応しません。 ただし、移行されたデータ マート レイヤーにデータと必要なビルド プロセスがバックフィルされたら、プロジェクトの後のフェーズでこれらの側面に対処できます。
リフト アンド シフト移行と段階的アプローチ
一般に、計画された移行の目的と範囲に関係なく、2 種類の移行があります。リフト アンド シフトそのままと、変更を組み込む段階的なアプローチです。
リフト アンド シフト
リフト アンド シフト移行では、既存のデータ モデル (スター スキーマなど) は、そのまま新しい Azure Synapse プラットフォームに移行されます。 このアプローチでは、Azure クラウド環境への移動の利点を実現するために必要な作業を減らして、リスクと移行時間を最小限に抑えます。 リフト アンド シフト移行は、次のシナリオに適しています。
- 移行する単一のデータ マートを持つ既存の Oracle 環境がある場合、または
- 適切に設計されたスターまたはスノーフレークのスキーマに既に含まれているデータを含む既存の Oracle 環境がある場合、または
- 最新のクラウド環境に移動するための時間とコストが切迫している場合。
ヒント
リフト アンド シフトは、後続のフェーズでデータ モデルへの変更が実装される場合でも、適切な開始点です。
変更を組み込む段階的なアプローチ
レガシ データ ウェアハウスが長期間にわたって進化している場合、必要なパフォーマンス レベルを維持するために再エンジニアリングが必要なことがあります。 モノのインターネット (IoT) ストリームなどの新しいデータをサポートするために、再エンジニアリングが必要になる場合もあります。 再エンジニアリング プロセスの一環として、スケーラブルなクラウド環境のメリットを利用するために、Azure Synapse に移行します。 移行には、基になるデータ モデルの変更 (Inmon モデルからデータ コンテナーへの移動など) が含まれることがあります。
Microsoft は、既存のデータ モデルをそのまま Azure に移動してから、Azure 環境のパフォーマンスと柔軟性を生かして、再エンジニアリングの変更を適用することをお勧めします。 そうすることで、既存のソース システムに影響を与えることなく、Azure の機能を使用して変更を加えることができます。
Microsoft の機能を使用してメタデータに基づく移行を実装する
Azure 環境の機能を使用することで、移行プロセスを自動化し、調整できます。 このアプローチにより、既存の Oracle 環境 (既に能力いっぱいに近い状態で実行されている場合があります) のパフォーマンスへの影響が最小限に抑えられます。
SQL Server Migration Assistant (SSMA) for Oracle では、移行プロセスの多くの部分 (場合によっては関数や手続き型コードも含みます) を自動化できます。 SSMA では、ターゲット環境として Azure Synapse がサポートされます。

SSMA for Oracle は、Oracle データ ウェアハウスまたはデータ マートを Azure Synapse に移行するために役立ちます。 SSMA は、既存の Oracle 環境からのテーブル、ビュー、データの移行のプロセスを自動化するように設計されています。
Azure Data Factory は、クラウドベースのデータ統合サービスであり、データの移動と変換を調整および自動化するデータ ドリブン ワークフローのクラウドでの作成をサポートします。 Data Factory を使用して、さまざまなデータ ストアからデータを取り込むデータ ドリブン ワークフロー (パイプライン) を作成し、スケジュールを設定できます。 Data Factory は、Azure HDInsight Hadoop、Spark、Azure Data Lake Analytics、Azure Machine Learning などのコンピューティング サービスを使ってデータを処理し、変換できます。
Data Factory を使用して、ソースのデータを Azure SQL のターゲットに移行できます。 このオフライン データ移動を利用すると、移行のダウンタイムを大幅に短縮できます。
Azure Database Migration Services は、Oracle などの環境からの移行の計画と実行に役立ちます。
Azure 機能を使用した移行プロセスの管理を計画するときは、移行するすべてのデータ テーブルとその場所を一覧表示するメタデータを作成します。
Oracle と Azure Synapse の設計の違い
前述のように、Oracle と Azure Synapse Analytics のデータベースのアプローチには、いくつかの基本的な違いがあります。 SSMA for Oracle は、それらのギャップを埋めるのに役立つだけでなく、移行を自動化します。 SSMA は、非常に大量のデータに対して最も効率的な方法ではありませんが、小規模なテーブルには適しています。
複数のデータベースおよび 1 つのデータベースとスキーマ
Oracle 環境には、多くの場合、複数の個別のデータベースが含まれています。 たとえば、データ インジェストとステージングのテーブル、コア ウェアハウス テーブル、データ マート (セマンティック レイヤーと呼ばれることもあります) に対して個別のデータベースが存在する場合があります。 ETL または ELT パイプラインのプロセスでは、データベースをまたがる結合を実装し、個別のデータベース間でデータを移動できます。
一方、Azure Synapse 環境には 1 つのデータベースがあり、スキーマを使用して、論理的に分離されたグループにテーブルが分割されます。 Oracle 環境から移行される個別のデータベースを模倣するために、ターゲットの Azure Synapse データベース内で一連のスキーマを使用することをお勧めします。 Oracle 環境で既にスキーマが使用されている場合は、Oracle の既存のテーブルとビューを新しい環境に移動するときに、新しい名前付け規則を使用する必要が生じることがあります。 たとえば、元の個別のデータベース名を維持するために、Oracle の既存のスキーマとテーブルの名前を連結して Azure Synapse の新しいテーブル名にしてから、新しい環境でスキーマ名を使用することが考えられます。 基になるテーブルに SQL ビューを使用して論理構造を維持することもできますが、このアプローチには潜在的な欠点がいくつかあります。
Azure Synapse のビューは読み取り専用であるため、データの更新は、基になるベース テーブルで行われる必要があります。
既にビューの 1 つ以上のレイヤーが存在している場合にビュー レイヤーを追加すると、パフォーマンスが低下するおそれがあります。
ヒント
Azure Synapse 内で複数のデータベースを 1 つのデータベースに統合し、スキーマ名を使用して、テーブルを論理的に分離します。
テーブルに関する考慮事項
異なる環境間でテーブルを移行するとき、通常は生データと、それを記述するメタデータのみが物理的に移行されます。 インデックスなどの、ソース システムの他のデータベース要素は、通常は移行されません。新しい環境ではこれらが不要であるか、実装方法が異なる可能性があるためです。
インデックスなどの、ソース環境でのパフォーマンスの最適化は、新しい環境でパフォーマンスの最適化を追加することが検討される箇所を示します。 たとえば、ソース Oracle 環境のクエリで頻繁にビットマップ インデックスが使用される場合、Azure Synapse 内に非クラスター化インデックスを作成する必要があることを示しています。 テーブル レプリケーションなどの、他のネイティブ パフォーマンスの最適化手法が、同一条件でインデックスをそのまま作成するよりも適している場合があります。 SSMA for Oracle を使用すると、テーブルの分散とインデックス作成についての移行に関する推奨事項が得られます。
ヒント
既存のインデックスは、移行後のウェアハウスでのインデックス作成の候補を示します。
サポートされていない Oracle データベース オブジェクトの種類
Oracle 固有の機能は、多くの場合、Azure Synapse の機能に置き換えることができます。 ただし、一部の Oracle データベース オブジェクトは、Azure Synapse では直接サポートされません。 サポートされていない Oracle データベース オブジェクトの次の一覧で、Azure Synapse で同等の機能を実現する方法について説明します。
さまざまなインデックス作成オプション: Oracle のいくつかのインデックス作成オプション (ビットマップインデックス、関数ベースのインデックス、ドメイン インデックスなど) には、Azure Synapse 内に直接相当するものはありません。
インデックスが作成されている列とインデックスの種類は、次の方法で確認できます。
システム カタログ テーブルとビューに対するクエリを実行する (
ALL_INDEXES、DBA_INDEXES、USER_INDEXES、DBA_IND_COLなど)。 次のスクリーンショットに示すように、Oracle SQL Developer の組み込みクエリを使用できます。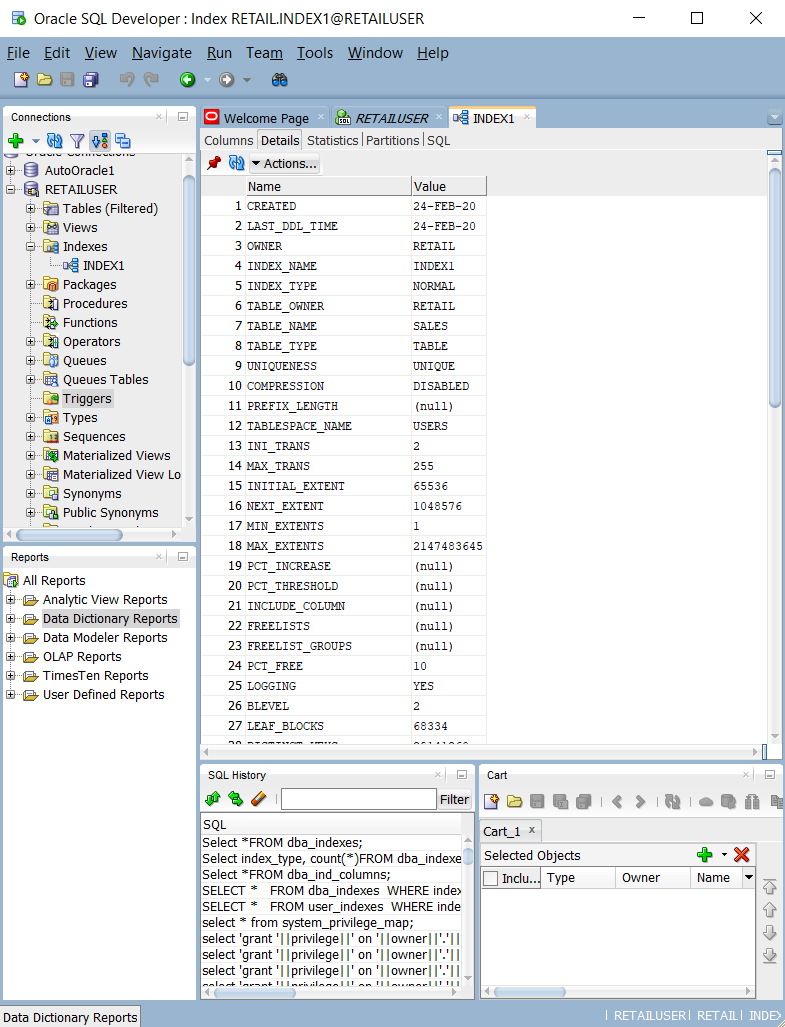
または、次のクエリを実行して、特定の種類のすべてのインデックスを見つけます。
SELECT * FROM dba_indexes WHERE index_type LIKE 'FUNCTION-BASED%';監視が有効になっている場合に
dba_index_usageまたはv$object_usageビューに対するクエリを実行する。 次のスクリーンショットに示すように、Oracle SQL Developer でこれらのビューに対してクエリを実行できます。
関数ベースのインデックス (関数の結果を基になるデータ列に含むインデックス) には、Azure Synapse に直接相当するものはありません。 最初にデータを移行してから、Azure Synapse で、関数ベースのインデックスを使用する Oracle クエリを実行してパフォーマンスを測定することをお勧めします。 Azure Synapse でのこれらのクエリのパフォーマンスが許容できない場合は、事前に計算された値を含む列を作成してから、その列にインデックスを作成することを検討してください。
Azure Synapse 環境を構成する場合は、使用中のインデックスのみを実装するのが適切です。 Azure Synapse では、現在、次に示すインデックスの種類をサポートしています。
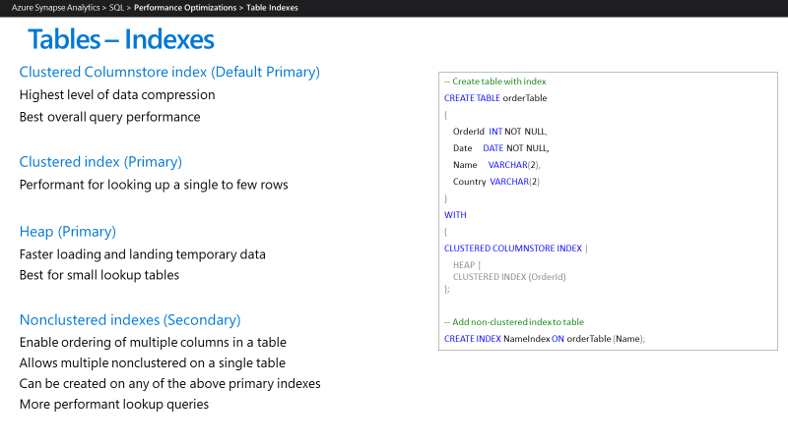
並列クエリ処理やデータと結果のメモリ内キャッシュなどの Azure Synapse 機能を使用すると、パフォーマンス目標を達成するためにデータ ウェアハウス アプリケーションに必要なインデックスが少なくなる可能性があります。 Azure Synapse では、次のインデックスの種類を使用することをお勧めします。
クラスター化列ストア インデックス: テーブルにインデックス オプションが指定されていない場合、既定では、Azure Synapse によってクラスター化列ストア インデックスが作成されます。 クラスター化列ストア テーブルでは、データ圧縮のレベルが最も高く、クエリ全体のパフォーマンスが最適であり、一般的にクラスター化インデックス テーブルまたはヒープ テーブルよりパフォーマンスが優れています。 通常、クラスター化列ストア インデックスは、大規模なテーブルに最適です。 テーブルを作成する際に、テーブルのインデックスの作成方法がわからない場合は、クラスター化列ストアを選択してください。 ただし、クラスター化列ストア インデックスが最適なオプションではないシナリオがいくつか存在します。
- 並べ替えキーに事前に並べ替えられたデータを持つテーブルは、"順序付き" クラスター化列ストア インデックスによって有効になっているセグメントの削除の恩恵を受ける可能性があります。
- varchar(max)、nvarchar(max)、または varbinary(max) データ型を含むテーブル。クラスター化列ストア インデックスではこれらのデータ型がサポートされていないためです。 代わりに、ヒープまたはクラスター化インデックスの使用を検討してください。
- 一時的なデータを含むテーブル。列ストア テーブルはヒープ テーブルや一時テーブルよりも効率が低い場合があるためです。
- 1 億行未満を格納する小さなテーブルの場合、 代わりに、ヒープ テーブルの使用を検討してください。
順序付きクラスター化列ストア インデックス: 効率的なセグメント削除を有効にすると、Azure Synapse 専用 SQL プール内の順序付きクラスター化列ストア インデックスクエリ述語と一致しない大量の順序付きデータをスキップすることで、パフォーマンスが大幅に向上します。 順序指定 CCI テーブルへのデータの読み込みは、データの並べ替え操作のため、非順序指定 CCI テーブルよりも時間がかかる可能性があります。ただし、その後、順序付けされた CCI では、クエリをより高速で実行できます。 順序付けされたクラスター化列ストア インデックスの詳細については、「順序指定クラスター化列ストア インデックスを使用したパフォーマンスのチューニング」を参照してください。
クラスター化インデックスと非クラスター化インデックス: 1 つの行を迅速に取得する必要がある場合、クラスター化インデックスがクラスター化列ストア インデックスよりパフォーマンスが優れていると考えられます。 1 つの行の検索または少数の行の検索を極端な速度で実行する必要があるクエリでは、クラスター インデックスまたは非クラスター化セカンダリ インデックスの使用を検討してください。 クラスター化インデックスを使用するデメリットは、クラスター化インデックスの列で非常に選択的なフィルターを使用するクエリしか効果が得られないことです。 他の列のフィルター処理を向上するには、他の列に非クラスター化インデックスを追加します。 ただし、テーブルに追加する各インデックスでは、より多くの領域を使用し、読み込みの処理時間が長くなります。
ヒープ テーブル: Azure Synapse にデータを一時的にランディングする場合、ヒープ テーブルを使用すると、全体的なプロセスが速くなる場合があります。 この理由は、ヒープ テーブルへのデータの読み込みがインデックス テーブルへのデータの読み込みよりも高速であり、場合によっては後続の読み取りをキャッシュから実行できることです。 さまざまな変換を実行する前にデータをステージングするためにのみ読み込む場合は、データをヒープ テーブルに読み込むと、クラスター化列ストア テーブルに読み込む場合よりもはるかに高速になります。 また、テーブルを永続記憶域に読み込む場合より、データを一時テーブルに読み込む方が速くなります。 1 億行未満の小さなルックアップ テーブルの場合、通常はヒープ テーブルが適しています。 クラスター列ストア テーブルは、含まれる行が 1 億行を超えて初めて最適な圧縮が実現します。
クラスター化テーブル: データの取得時にディスク I/O を削減するため、Oracle テーブルは、頻繁に一緒にアクセスされる (共通の値に基づいて) テーブル行が物理的にまとめて格納されるように整理できます。 また、Oracle には、個々のテーブルにハッシュ クラスター オプションも用意されています。これより、ハッシュ値がクラスター キーに適用され、同じハッシュ値を持つ行が物理的にまとめて格納されます。 Oracle データベース内のクラスターを一覧表示するには、
SELECT * FROM DBA_CLUSTERS;クエリを使用します。 テーブルがクラスター内にあるかどうかを判断するには、SELECT * FROM TAB;クエリを使用します。これによって各テーブルのテーブル名とクラスター ID が示されます。Azure Synapse では、具体化またはレプリケートされたテーブルを使用して同様の結果を得ることができます。これらのテーブルの種類では、クエリ実行時に必要な I/O が最小限に抑えられるためです。
具体化されたビュー: Oracle では、具体化されたビューをサポートしていて、多くの列を持つ大規模なテーブル (クエリで定期的に使用される列はわずかしかない) に 1 つ以上使用することが推奨されています。 具体化されたビューは、ベース テーブルのデータが更新されるとシステムで自動的に更新されます。
2019 年に、Microsoft は、Oracle と同じ機能を持つ具体化されたビューが Azure Synapse でサポートされることを発表しました。 具体化されたビューは現在、Azure Synapse のプレビュー機能です。
データベース内トリガー: Oracle では、トリガー イベントが発生したときに自動的に実行されるようにトリガーを構成できます。 トリガー イベントには、次のものがあります。
データ操作言語 (DML) ステートメント (
INSERT、UPDATE、DELETEなど) がテーブルで実行される。 顧客テーブルでINSERTステートメントの前に起動するトリガーを定義した場合、このトリガーは新しい行が顧客テーブルに挿入される前に 1 回起動されます。DDL ステートメント (
CREATEやALTERなど) が実行される。 このトリガーは、スキーマの変更を記録するための監査の目的に多く使用されます。システム イベント (Oracle データベースの起動やシャットダウンなど)。
ユーザー イベント (サインインやサインアウトなど)。
Oracle データベースで定義されているトリガーの一覧を取得するには、
ALL_TRIGGERS、DBA_TRIGGERS、またはUSER_TRIGGERSビューに対するクエリを実行します。 次のスクリーンショットは、Oracle SQL Developer でのDBA_TRIGGERSクエリを示しています。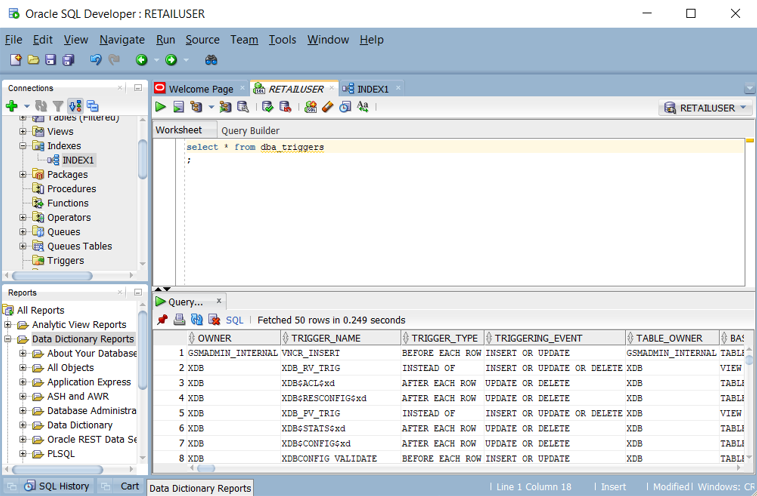
Azure Synapse では Oracle データベース トリガーをサポートしていません。 ただし、Data Factory を使用すると同等の機能を追加できますが、これを行うには、トリガーを使用するプロセスをリファクタリングする必要があります。
同意語: Oracle では、いくつかのデータベース オブジェクトの種類で代替名として同意語を定義できます。 これらのオブジェクトの種類には、テーブル、ビュー、シーケンス、プロシージャ、ストアド関数、パッケージ、具体化されたビュー、Java クラス スキーマ オブジェクト、ユーザー定義オブジェクト、または別の同意語が含まれます。
Azure Synapse では現在、同意語を定義できません。ただし、Oracle の同意語がテーブルまたはビューを参照している場合は、代替名と一致するように Azure Synapse でビューを定義できます。 Oracle の同意語が関数またはストアド プロシージャを参照している場合、Azure Synapse では、ターゲットを呼び出す同意語に一致する名前を持つ別の関数またはストアド プロシージャを作成できます。
ユーザー定義型: Oracle では、一連の個別フィールド (それぞれに独自の定義と既定値を持つ) を含めることができる、ユーザー定義オブジェクトをサポートしています。 これらのオブジェクトは、組み込みのデータ型 (
NUMBERやVARCHARなど) と同じ方法によってテーブル定義内で参照できます。 Oracle データベース内のユーザー定義型の一覧を取得するには、ALL_TYPES、DBA_TYPES、またはUSER_TYPESビューに対するクエリを実行します。Azure Synapse では現在、ユーザー定義の種類をサポートしていません。 移行する必要があるデータにユーザー定義のデータ型が含まれている場合は、それらを従来のテーブル定義に "フラット化" するか、データの配列である場合は、別のテーブルで正規化します。




Oracle のデータ型のマッピング
ほとんどの Oracle データ型には、Azure Synapse に直接相当するものがあります。 次の表に、Oracle データ型を Azure Synapse にマッピングするお勧めの方法を示します。
| Oracle データ型 | Azure Synapse のデータ型 |
|---|---|
| BFILE | サポートされていません。 VARBINARY (MAX) にマップします。 |
| BINARY_FLOAT | サポートされていません。 FLOAT にマップします。 |
| BINARY_DOUBLE | サポートされていません。 DOUBLE にマップします。 |
| BLOB | 直接サポートされていません。 VARBINARY(MAX) に置き換えます。 |
| CHAR | CHAR |
| CLOB | 直接サポートされていません。 VARCHAR(MAX) に置き換えます。 |
| DATE | Oracle の DATE には、時刻情報も含めることができます。 用途に応じて、DATE または TIMESTAMP にマップします。 |
| DECIMAL | DECIMAL |
| DOUBLE | PRECISION DOUBLE |
| FLOAT | FLOAT |
| INTEGER | INT |
| INTERVAL YEAR TO MONTH | INTERVAL データ型はサポートされません。 日付の計算には、DATEDIFF や DATEADD などの日付比較関数を使用します。 |
| INTERVAL DAY TO SECOND | INTERVAL データ型はサポートされません。 日付の計算には、DATEDIFF や DATEADD などの日付比較関数を使用します。 |
| LONG | サポートされていません。 VARCHAR(MAX) にマップします。 |
| LONG RAW | サポートされていません。 VARBINARY (MAX) にマップします。 |
| NCHAR | NCHAR |
| NVARCHAR2 | NVARCHAR |
| NUMBER | FLOAT |
| NCLOB | 直接サポートされていません。 NVARCHAR(MAX) に置き換えます。 |
| NUMERIC | NUMERIC |
| ORD メディア データ型 | サポートされていません |
| RAW | サポートされていません。 VARBINARY にマップします。 |
| 実数 | 実数 |
| ROWID | サポートされていません。 同様の GUID にマップします。 |
| SDO 地理空間データ型 | サポートされていません |
| SMALLINT | SMALLINT |
| timestamp | DATETIME2 または CURRENT_TIMESTAMP() 関数 |
| TIMESTAMP WITH LOCAL TIME ZONE | サポートされていません。 DATETIMEOFFSET にマップします。 |
| TIMESTAMP WITH TIME ZONE | TIME はタイム ゾーン オフセットなしで壁時計 time を使用して保存されるため、サポートされていません。 |
| URIType | サポートされていません。 VARCHAR に格納します。 |
| UROWID | サポートされていません。 同様の GUID にマップします。 |
| VARCHAR | VARCHAR |
| VARCHAR2 | VARCHAR |
| XMLType | サポートされていません。 XML データを VARCHAR に格納します。 |
Oracle では、一連の個別フィールド (それぞれに独自の定義と既定値を持つ) を含めることができる、ユーザー定義オブジェクトを定義することもできます。 それにより、これらのオブジェクトは、組み込みのデータ型 (NUMBER や VARCHAR など) と同じ方法によってテーブル定義内で参照できます。 Azure Synapse では現在、ユーザー定義の種類をサポートしていません。 移行する必要があるデータにユーザー定義のデータ型が含まれている場合は、それらを従来のテーブル定義に "フラット化" するか、データの配列である場合は、別のテーブルで正規化します。
ヒント
移行準備段階で、サポートされていないデータ型の数と種類を評価してください。
サードパーティ ベンダーから、データ型のマッピングなどの、移行を自動化するツールとサービスが提供されています。 サードパーティの ETL ツールが既に Oracle 環境で使用されている場合は、そのツールを使用して、必要なデータ変換を実装します。
SQL DML 構文の相違点
Oracle SQL と Azure Synapse T-SQL には、SQL DML 構文の違いがあります。 これらの違いについては、「Oracle 移行の SQL 問題を最小限に抑える」で詳しく説明します。 場合によっては、SSMA for Oracle や Azure Database Migration Services などの Microsoft ツール、またはサードパーティの移行製品やサービスを使用して、DML の移行を自動化できます。
関数、ストアド プロシージャ、シーケンス
Oracle のような成熟した環境からデータ ウェアハウスを移行するときは、単純なテーブルやビュー以外の要素の移行が必要になる可能性があります。 Azure 環境内のツールが関数、ストアド プロシージャ、シーケンスの機能を置き換えることができるかどうかを確認します。これは、通常、組み込みの Azure ツールを使用する方が、それらを Azure Synapse 用に再コーディングするよりも効率的であるためです。
準備段階の一環として、移行する必要があるオブジェクトのインベントリを作成し、それらを処理する方法を定義して、移行計画に適切なリソースを割り当てます。
SSMA for Oracle や Azure Database Migration Services などの Microsoft ツール、またはサードパーティの移行製品やサービスを使用して、関数、ストアド プロシージャ、シーケンスの移行を自動化できます。
以降のセクションでは、関数、ストアド プロシージャ、シーケンスの移行についてさらに説明します。
関数
ほとんどのデータベース製品と同様に、Oracle では SQL 実装内で、システムとユーザー定義の関数がサポートされています。 レガシ データベース プラットフォームを Azure Synapse に移行するときに、一般的なシステム機能は通常変更なしで移行できます。 一部のシステム関数では、構文が若干異なることがありますが、必要な変更は自動化できます。 Oracle データベース内の関数の一覧を取得するには、適切な WHERE 句を使用してALL_OBJECTS ビューに対するクエリを実行します。 次のスクリーンショットに示すように、Oracle SQL Developer を使用して関数の一覧を取得できます。

Azure Synapse に同等のものがない Oracle システム関数または任意のユーザー定義関数については、ターゲット環境言語を使用してそれらの関数を再コーディングします。 Oracle のユーザー定義関数は、PL/SQL、Java、または C 言語でコーディングされています。Azure Synapse では、Transact-SQL 言語を使用してユーザー定義関数を実装します。
ストアド プロシージャ
ほとんどの最新のデータベース製品では、データベース内にプロシージャを格納できます。 Oracle には、この目的のために PL/SQL 言語が用意されています。 ストアド プロシージャには通常、SQL ステートメントと手続き型のロジックの両方が含まれていて、データまたは状態が返されます。 Oracle データベース内のストアド プロシージャの一覧を取得するには、適切な WHERE 句を使用してALL_OBJECTS ビューに対するクエリを実行します。 次のスクリーンショットに示すように、Oracle SQL Developer を使用してストアド プロシージャの一覧を取得できます。

Azure Synapse では T-SQL を使用したストアド プロシージャがサポートされているため、移行されたストアド プロシージャをその言語で再コーディングする必要があります。
シーケンス
Oracle では、シーケンスとは、CREATE SEQUENCE を使用して作成される名前付きデータベース オブジェクトのことです。 シーケンスは、CURRVAL および NEXTVAL メソッド経由で一意の数値を提供します。 主キーに対する代理キーの値として、生成された一意の数値を使用できます。
Azure Synapse は CREATE SEQUENCE を実装しませんが、IDENTITY 列または系列内の次のシーケンス番号を生成する SQL コードを使用してシーケンスを実装できます。
Oracle 環境からのメタデータとデータの抽出
データ定義言語の生成
ANSI SQL 標準では、データ定義言語 (DDL) コマンドの基本的な構文を定義しています。 DDL コマンドの中には、CREATE TABLE や CREATE VIEW など、Oracle と Azure Synapse の両方に共通するものがありますが、インデックス作成、テーブルの分散、パーティション分割オプションなどの実装固有の機能も用意されています。
既存の Oracle の CREATE TABLE と CREATE VIEW スクリプトを編集して、Azure Synapse の同等の定義を実現できます。 これを行うために、変更されたデータ型を使用し、Oracle 固有の句 (TABLESPACE など) を削除または変更する必要が生じる場合があります。
Oracle 環境内では、システム カタログ テーブルが現在のテーブルとビューの定義を指定します。 ユーザーが保守するドキュメントとは異なり、システム カタログ情報は常に完全であり、現在のテーブル定義と同期されます。 システム カタログ情報にアクセスするには、Oracle SQL Developer などのユーティリティを使用します。 Oracle SQL Developer では、編集できる CREATE TABLE DDL ステートメントを生成して、Azure Synapse で同等のテーブルを作成できます。
または、SSMA for Oracle を使用して、既存の Oracle 環境から Azure Synapse にテーブルを移行できます。 SSMA for Oracle では、次のスクリーンショットに示すように、適切なデータ型マッピングおよび推奨されるテーブルと分散の種類が適用されます。

同様の結果を得るために、システム カタログ情報を処理するサードパーティの移行および ETL のツールを使用することもできます。
Oracle からのデータの抽出
Oracle SQL Developer、SQL*Plus、SCLcl などの標準の Oracle ユーティリティを使用して、Oracle テーブルから生のテーブル データを CSV ファイルなどのフラット区切りファイルに抽出できます。 次に、gzip を使用してフラット区切りファイルを圧縮し、AzCopy や Azure Data Box などの Azure データ トランスポート ツールを使用して圧縮ファイルを Azure Blob Storage にアップロードできます。
大規模なファクト テーブルを移行する場合は特に、テーブル データを可能な限り効率的に抽出します。 Oracle テーブルの場合は、並列処理を使用して抽出スループットを最大にします。 並列処理を実現するには、個別のデータ セグメントを個々に抽出する複数のプロセスを実行するか、パーティション分割によって並列抽出を自動化できるツールを使用します。
ヒント
最も効率的にデータを抽出するには並列処理を使用します。
十分なネットワーク帯域幅を使用できる場合、オンプレミスの Oracle システムから Azure Synapse テーブルまたは Azure Blob Data Storage に直接データを抽出できます。 そのためには、Data Factory プロセス、Azure Database Migration Service、またはサードパーティのデータ移行または ETL 製品を使用します。
抽出されたデータ ファイルには、CSV、Optimized Row Columnar (ORC)、または Parquet 形式の区切りテキストが含まれている必要があります。
Oracle 環境からデータと ETL を移行する詳細については、「Oracle 移行のためのデータ移行、ETL、読み込み」を参照してください。
Oracle 移行のパフォーマンスに関する推奨事項
パフォーマンスの最適化の目標は、Azure Synapse への移行後のデータ ウェアハウスのパフォーマンスを同等以上にすることです。
パフォーマンス チューニング アプローチの概念の類似点
Oracle データベースのパフォーマンス チューニングの概念の多くは、Azure Synapse データベースにあてはまります。 次に例を示します。
データ分布を使用して、同じ処理ノードに結合するデータを併置します。
特定の列に対して最小のデータ型を使用して、ストレージ領域を節約し、クエリ処理を高速化します。
結合する列のデータ型が同じになるようにして、結合処理を最適化し、データ変換の必要性を削減します。
オプティマイザーで最適な実行プランを生成するのに役立つように、統計を常に最新にしておきます。
組み込みのデータベース機能を使用してパフォーマンスを監視し、リソースが効率的に使用されるようにします。
ヒント
移行の開始時に、Azure Synapse のチューニング オプションの学習を優先してください。
パフォーマンス チューニング アプローチの相違点
このセクションでは、Oracle と Azure Synapse のパフォーマンス チューニングの詳細な実装の違いについて説明します。
データ分散オプション
パフォーマンスのために、Azure Synapse はマルチノード アーキテクチャを使用して設計されていて、並列処理を使用します。 Azure Synapse でテーブルのパフォーマンスを最適化するために、DISTRIBUTION ステートメントを使用して、CREATE TABLE ステートメントでデータ分散オプションを定義できます。 たとえば、ハッシュ分散テーブルを指定できます。これは、決定論的なハッシュ関数を使用してコンピューティング ノード間でテーブル行を分散します。 Oracle の多くの実装 (特に以前のオンプレミス システム) では、この機能をサポートしていません。
Oracle とは異なり、Azure Synapse では、小さなテーブルのレプリケーションを使用して、小さなテーブルと大きなテーブルの間のローカル結合がサポートされます。 たとえば、スター スキーマ モデル内の小さなディメンション テーブルと大きなファクト テーブルを考えてみましょう。 Azure Synapse では、小さなディメンション テーブルをすべてのノードにレプリケートして、大きなテーブルの結合キーの値に一致するローカルで使用可能なディメンション行を確保できます。 ディメンション テーブルのレプリケーションのオーバーヘッドは、小さなディメンション テーブルでは比較的低くなります。 大きなディメンション テーブルの場合は、ハッシュ分散アプローチの方が適しています。 データ分散オプションの詳細については、レプリケート テーブルを使用するための設計ガイダンスと分散テーブルを設計するためのガイダンスを参照してください。
ヒント
ハッシュ分散により、大きなファクト テーブルでのクエリのパフォーマンスが向上します。 ラウンド ロビン分散は、読み込み速度の向上に役立ちます。
ハッシュ分散は、ベース テーブルの分散をより均等にするために、複数の列に適用できます。 複数列分散を使用すると、分散用に最大 8 つの列を選択できます。 これにより、時間の経過に伴うデータの偏りを減らすだけでなく、クエリのパフォーマンスも向上します。
Note
複数列分散は現在、Azure Synapse Analytics ではプレビューの段階です。 複数列分散は、CREATE MATERIALIZED VIEW、CREATE TABLE、CREATE TABLE AS SELECT で使用できます。
配布アドバイザー
Azure Synapse SQL では、各テーブルを分散する方法をカスタマイズできます。 テーブルの分散戦略は、クエリのパフォーマンスに大きく影響します。
Distribution Advisor は、クエリを分析し、クエリのパフォーマンスを向上させるためにテーブルに最適な分散戦略を推奨する、Synapse SQL の新機能です。 アドバイザーによって考慮されるクエリは、自分で提供することも、DMV で使用できる履歴クエリからプルすることもできます。
Distribution Advisor の使用方法の詳細と例については、「Azure Synapse SQL の Distribution Advisor」を参照してください。
データのインデックス作成
Azure Synapse では、Oracle のシステム管理ゾーン マップとは操作と使用方法が異なる、ユーザーが定義できるいくつかのインデックス作成オプションがサポートされています。 Azure Synapse の異なるインデックス作成オプションの詳細については、専用 SQL プール テーブルのインデックス作成に関するページを参照してください。
移行元 Oracle 環境内のインデックス定義では、データの使用方法と、Azure Synapse 環境内でインデックスを作成するための候補列を実用的に示します。 通常は、レガシ Oracle 環境からすべてのインデックスを移行する必要はありません。Azure Synapse ではインデックスに過剰に依存せず、優れたパフォーマンスを実現するために次の機能を実装しているためです。
並列クエリ処理。
メモリ内データと結果セットのキャッシュ。
I/O を減らすためのデータ分散 (小さなディメンション テーブルのレプリケーションなど)。
データのパーティション分割
エンタープライズ データ ウェアハウスでは、ファクト テーブルに数十億行が含まれる場合があります。 パーティション分割でこれらのテーブルを別々の部分に分割し、処理されるデータ量を減らすと、これらのテーブルの維持とクエリを最適化できます。 Azure Synapse では、CREATE TABLE ステートメントは、テーブルのパーティション分割指定を定義します。
パーティション分割に使用できるフィールドは、テーブルごとに 1 つのみです。 多くのクエリは日付または日付範囲でフィルター処理されるため、多くの場合、このフィールドは日付フィールドになります。 CREATE TABLE AS (CTAS) ステートメントを使用して、新しい分散のテーブルを再作成することで、初期読み込み後にテーブルのパーティション分割を変更できます。 Azure Synapse でのパーティション分割の詳細については、「専用 SQL プールでのテーブルのパーティション分割」を参照してください。
データ読み込み用の PolyBase または COPY INTO
PolyBase では、並列読み込みストリームを使用して大量のデータをデータ ウェアハウスに効率的に読み込むことができます。 詳細については、PolyBase データ読み込み戦略に関する記事を参照してください。
COPY INTO でも、高スループットのデータ インジェストと、さらに次の処理がサポートされます。
- フォルダーとサブフォルダー内のすべてのファイルからのデータ取得。
- 同じストレージ アカウント内の複数の場所からのデータ取得。 コンマ区切りのパスを使用して、複数の場所を指定できます。
- Azure Data Lake Storage (ADLS) と Azure Blob Storage。
- CSV、PARQUET、ORC の各ファイル形式。
ヒント
データの読み込みには、PARQUET ファイル形式と共に COPY INTO を使用することをお勧めします。
ワークロードの管理
混合ワークロードを実行すると、ビジー状態のシステムでリソースの問題が発生する可能性があります。 正常なワークロード管理スキームでは、リソースが効果的に管理され、リソースが確実に効率よく利用され、投資収益率 (ROI) が最大化されます。 ワークロードの分類、ワークロードの重要度、ワークロードの分離により、ワークロードでのシステム リソースの利用方法をより詳細に制御できます。
ワークロード管理ガイドでは、ワークロードの分析、ワークロードの重要度の管理と監視の手法、およびリソース クラスのワークロード グループへの変換手順について説明しています。 Azure portal と DMV に対する T-SQL クエリを使用してワークロードを監視し、該当するリソースが効率的に利用されるようにします。
次のステップ
Oracle 移行の ETL と読み込みについては、このシリーズの次の記事「Oracle 移行のためのデータ移行、ETL、読み込み」を参照してください。