Azure Stream Analytics でのカスタム BLOB 出力のパーティション分割
Azure Stream Analytics は、カスタムのフィールドまたは属性とカスタムの DateTime パス パターンを使用したカスタムの BLOB 出力のパーティション分割をサポートしています。
カスタム フィールドまたは属性
カスタム フィールドまたは入力属性では、出力をよりきめ細かく制御できるようになるため、ダウンストリームのデータ処理およびレポート ワークフローが機能強化されます。
パーティション キーのオプション
入力データをパーティション分割するために使用されるパーティション キーまたは列名には、BLOB 名に使用できる任意の文字を含めることができます。 入れ子になったフィールドは、エイリアスと一緒に使用しない限り、パーティション キーとして使用できません。 ただし、特定の文字を使用してファイルの階層を作成できます。 たとえば、列を作成し、この列で他の 2 つの列のデータを結合して、一意のパーティション キーを作成するには、次のクエリを使用できます。
SELECT name, id, CONCAT(name, "/", id) AS nameid
パーティション キーは、NVARCHAR(MAX)、BIGINT、FLOAT、または BIT (互換性レベル 1.2 以上) である必要があります。 DateTime、Array、Records 型はサポートされていませんが、文字列に変換すると、パーティション キーとして使用できます。 詳細については、Azure Stream Analytics のデータ型に関するページを参照してください。
例
あるジョブが、外部のビデオ ゲーム サービスに接続されたライブ ユーザー セッションから入力データを取得するとします。ここで、取り込まれたデータには、セッションを識別するための列 client_id が含まれます。 データを client_id でパーティション分割するには、ジョブの作成時に BLOB 出力プロパティ内にパーティション トークン {client_id} が含まれるように BLOB パス パターン フィールドを設定します。 さまざまな client_id 値を含むデータは Stream Analytics ジョブを通して流れるため、出力データは、フォルダーごとの 1 つの client_id 値に基づいて個別のフォルダーに保存されます。

同様に、ジョブ入力が、各センサーに sensor_id が割り当てられた数百万のセンサーからのセンサー データであった場合は、各センサー データを異なるフォルダーにパーティション分割するために、パス パターンは {sensor_id} になります。
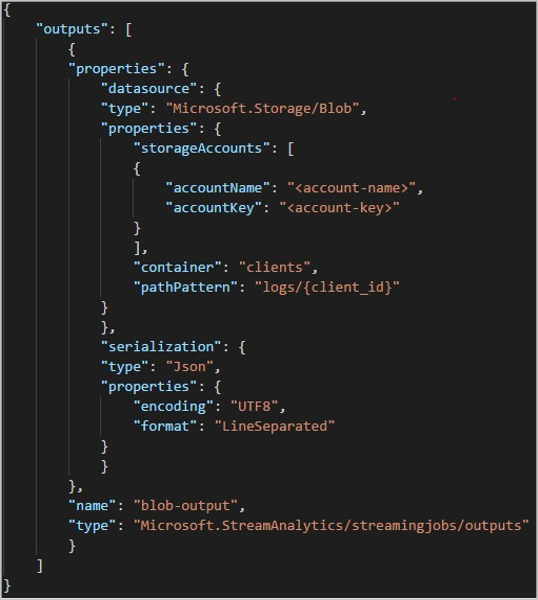
REST API を使用すると、その要求に使用される JSON ファイルの出力セクションは次の画像のようになります。
ジョブが実行を開始すると、clients コンテナーは次の画像のようになります。
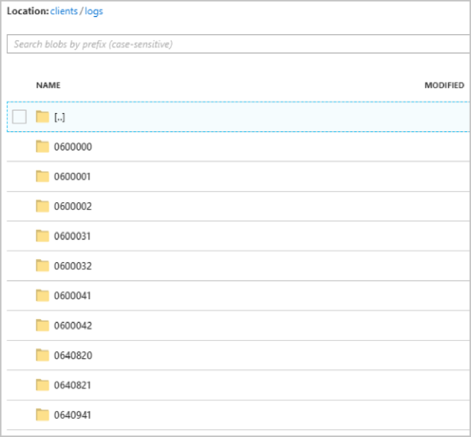
各フォルダーには、各 BLOB に 1 つ以上のレコードが含まれる複数の BLOB を含めることができます。 前の例では、"06000000" のラベルが付けられたフォルダー内に、次のコンテンツを含む 1 つの BLOB が存在します。
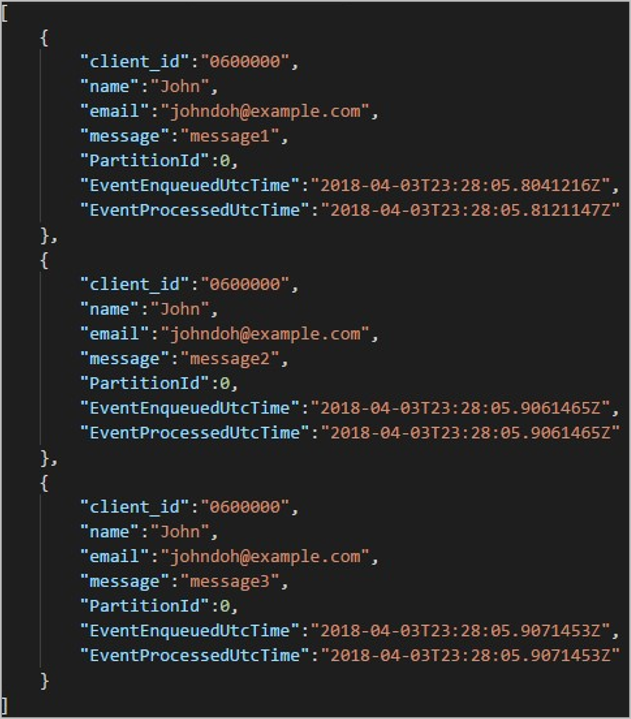
出力パス内の出力をパーティション分割するために使用される列は client_id であったため、BLOB 内の各レコードにはフォルダー名に一致する client_id 列が含まれることに注意してください。
制限事項
パス パターンの BLOB 出力プロパティで指定できるカスタムのパーティション キーは 1 つだけです。 次のすべてのパス パターンが有効です。
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
複数の入力フィールドを使用する場合は、
CONCATを使用して、BLOB 出力のカスタムのパス パーティションに対するクエリで複合キーを作成できます。 たとえばselect concat (col1, col2) as compositeColumn into blobOutput from inputです。 その後は、Azure Blob Storage のカスタム パスとしてcompositeColumnを指定できます。パーティション キーは大文字と小文字が区別されないため、
Johnやjohnなどのパーティション キーは同等です。 また、式もパーティション キーとして使用できません。 たとえば、{columnA + columnB}では機能しません。入力ストリームがパーティション キーのカーディナリティが 8,000 未満のレコードで構成されている場合、レコードは既存の BLOB に追加されます。 必要な場合にのみ、新しい BLOB が作成されます。 カーディナリティが 8,000 を超える場合、既存の BLOB が書き込まれる保証はありません。 パーティション キーが同じ任意の数のレコードに対して新しい BLOB は作成されません。
BLOB 出力が不変として構成されている場合、データが送信されるたびに Stream Analytics によって新しい BLOB が作成されます。
カスタム DateTime パス パターン
カスタムの DateTime パス パターンを使用すると Hive Streaming 規則に合致する出力形式を指定できます。これにより、Stream Analytics は、ダウンストリーム処理するためのデータを Azure HDInsight と Azure Databricks に送信できるようになります。 カスタムの DateTime パス パターンを簡単に実装するには、BLOB 出力の [パス プレフィックス] フィールドで datetime キーワードと書式指定子を使用します。 たとえば {datetime:yyyy} です。
サポートされているトークン
次の書式指定子トークンを単独でまたは組み合わせて使用して、カスタムの DateTime 形式を指定できます。
| 書式指定子 | 説明 | サンプル時間 2018-01-02T10:06:08 に対する結果 |
|---|---|---|
| {datetime:yyyy} | 4 桁の数値としての年 | 2018 |
| {datetime:MM} | 月 (01 ~ 12) | 01 |
| {datetime:M} | 月 (1 ~ 12) | 1 |
| {datetime:dd} | 日 (01 ~ 31) | 02 |
| {datetime:d} | 日 (1 ~ 31) | 2 |
| {datetime:HH} | 24 時間表記での時 (00 ~ 23) | 10 |
| {datetime:mm} | 分 (00 ~ 60) | 06 |
| {datetime:m} | 分 (0 ~ 60) | 6 |
| {datetime:ss} | 秒 (00 ~ 60) | 08 |
カスタムの DateTime パターンを使用しない場合は、{date} や {time} のトークンを [パス プレフィックス] フィールドに追加して、組み込みの DateTime 形式のドロップダウンを生成できます。
拡張性と制限事項
プレフィックス文字数の制限に達するまで、任意の数のトークン {datetime:<specifier>} をパス パターン内で使用できます。 日時ドロップダウンに既に一覧されている組み合わせ以外の書式指定子を 1 つのトークンの中で組み合わせて使用することはできません。
logs/MM/dd のパス パーティションの場合:
| 有効な式 | 無効な式 |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
パス プレフィックス内で、同じ書式指定子を複数回使用できます。 トークンは毎回繰り返す必要があります。
Hive Streaming 規則
BLOB ストレージ用のカスタムのパス パターンを Hive Streaming 規則と共に使用して、フォルダー名に column= によるラベルが付けられることを想定できます。
たとえば year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH} です。
カスタム出力は Stream Analytics と Hive 間でデータを移植するためのテーブルの変更と手動でのパーティションの追加という煩わしい操作を排除します。 代わりに、以下を使用して、多数のフォルダーを自動的に追加できます。
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
例
Stream Analytics Azure portal クイックスタートに従って、ストレージ アカウント、リソース グループ、Stream Analytics ジョブ、入力ソースを作成します。 クイックスタートで使用したものと同じサンプル データを使用します。 サンプル データは GitHub でも入手できます。
次の構成の BLOB 出力シンクを作成します。
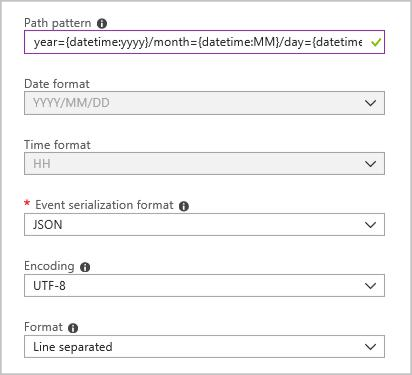
完全なパス パターンは次のとおりです。
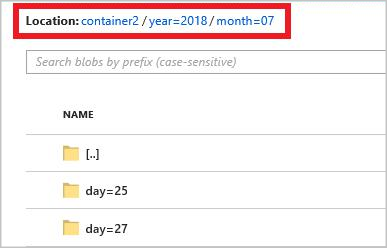
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
ジョブを開始すると、パス パターンに基づくフォルダー構造が BLOB コンテナー内に作成されます。 日レベルまでドリルダウンできます。