Azure Stream Analytics のノーコード エディターを使用して、データを変換し、Azure SQL データベースに格納する
この記事では、ノーコード エディターを使用して Stream Analytics ジョブを簡単に作成する方法について説明します。このジョブでは、Event Hubs インスタンス (イベント ハブ) からデータを継続的に読み取り、データを変換し、結果を Azure SQL データベースに書き込みます。
前提条件
Azure Event Hubs と Azure SQL Database のリソースは、パブリックにアクセスでき、ファイアウォールの内側に配置されておらず、また Azure Virtual Network 内でセキュリティ保護されていない必要があります。 Event Hubs のデータは、JSON、CSV、または Avro 形式でシリアル化される必要があります。
この記事の手順を試す場合は、次の手順に従ってください。
イベント ハブを作成します (まだない場合)。 イベント ハブでデータを生成します。 [Event Hubs インスタンス] ページで、左側のメニューから [データの生成 (プレビュー)] を選択し、[データセット] に対して [Stock data] を選択し、[送信] を選択してサンプル データをイベント ハブに送信します。 この記事の手順をテストする場合は、この手順が必要です。
![Event Hubs インスタンスの [データの生成 (プレビュー] ページを示すスクリーンショット。](media/no-code-transform-filter-ingest-sql/send-stock-data-to-event-hub.png)
Azure SQL データベース を作成します。 データベースの作成時に注意すべき重要な点をいくつか次に示します。
[基本] ページで、[サーバー] に対して [新規作成] を選択します。 次に、[SQL Database サーバーの作成] ページで、[SQL 認証を使用する] を選択し、管理者ユーザー ID とパスワードを指定します。
[ネットワーク] ページで、次の手順に従います。
- パブリック エンドポイントを有効にします。
- [Azure サービスおよびリソースにこのサーバーへのアクセスを許可する] で [はい] を選択します。
- [現在のクライアント IP アドレスを追加する] に対して [はい] を選択します。
[追加の設定] ページで、[既存のデータを使用する] に対して [いいえ] を選択します。
この記事では、「データベースのクエリを実行する」と「リソースをクリーンアップする」セクションの手順はスキップします。
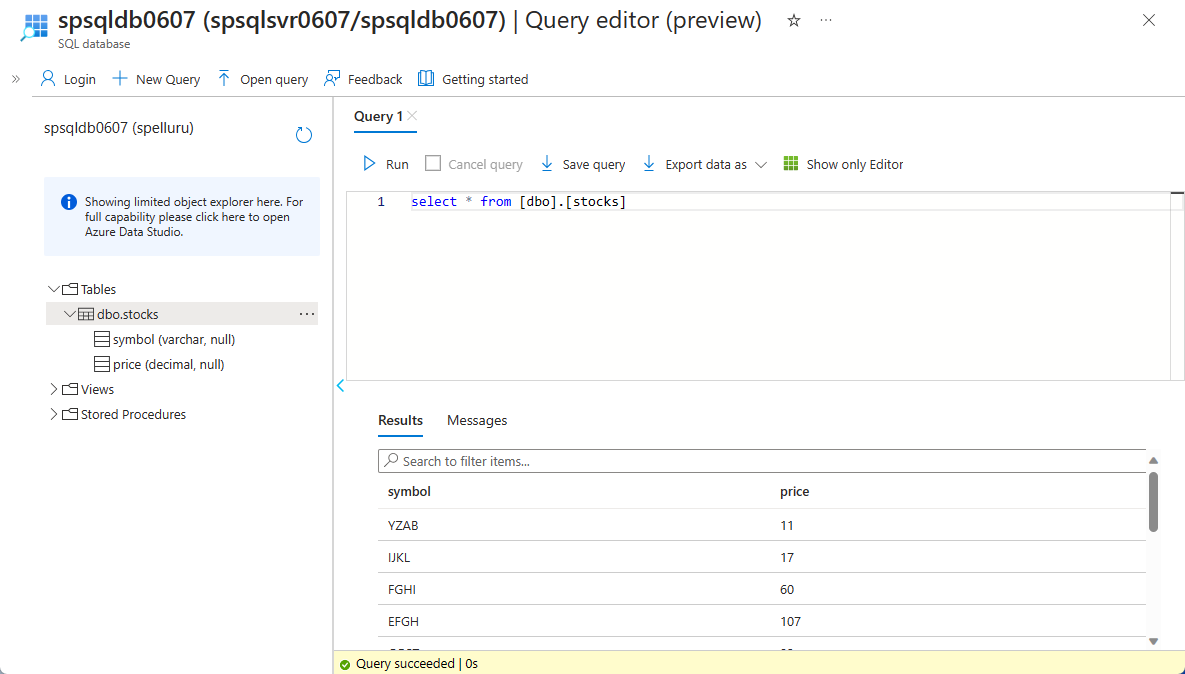
手順をテストする場合は、クエリ エディター (プレビュー) を使用して SQL データベースにテーブルを作成します。
create table stocks ( symbol varchar(4), price decimal )
![Event Hubs インスタンスの [データの生成 (プレビュー] ページを示すスクリーンショット。](media/no-code-transform-filter-ingest-sql/send-stock-data-to-event-hub.png#lightbox)
ノーコード エディターを使用して Stream Analytics ジョブを作成する
このセクションでは、ノーコード エディターを使用して Azure Stream Analytics ジョブを作成します。 ジョブにより、Event Hubs インスタンス (イベント ハブ) からのデータ ストリーミングが変換され、結果データが Azure SQL データベースに格納されます。
Azure portal で、イベント ハブの [Event Hubs インスタンス] ページに移動します。
左側のメニューで [機能]>[データの処理] を選択し、[データの変換および SQL データベースへの保存] カードで [開始] を選択します。
![[開始] を選択した ADLS Gen2 カードへのフィルターと取り込みを示すスクリーンショット。](media/no-code-transform-filter-ingest-sql/event-hub-process-data-templates.png)
Stream Analytics の名前を入力して、[作成] を選択します。 右側に Event Hubs ウィンドウがある Stream Analytics ジョブ ダイアグラムが表示されます。
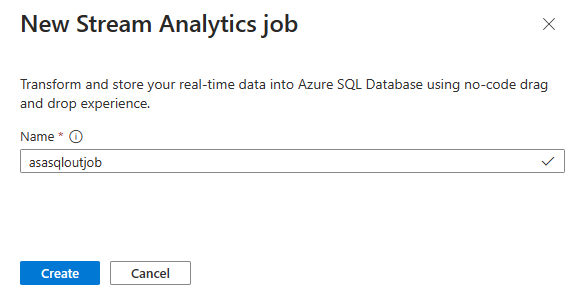
[イベント ハブ] ウィンドウで、[シリアル化] と [認証モード] の設定を確認し、[接続] を選択します。
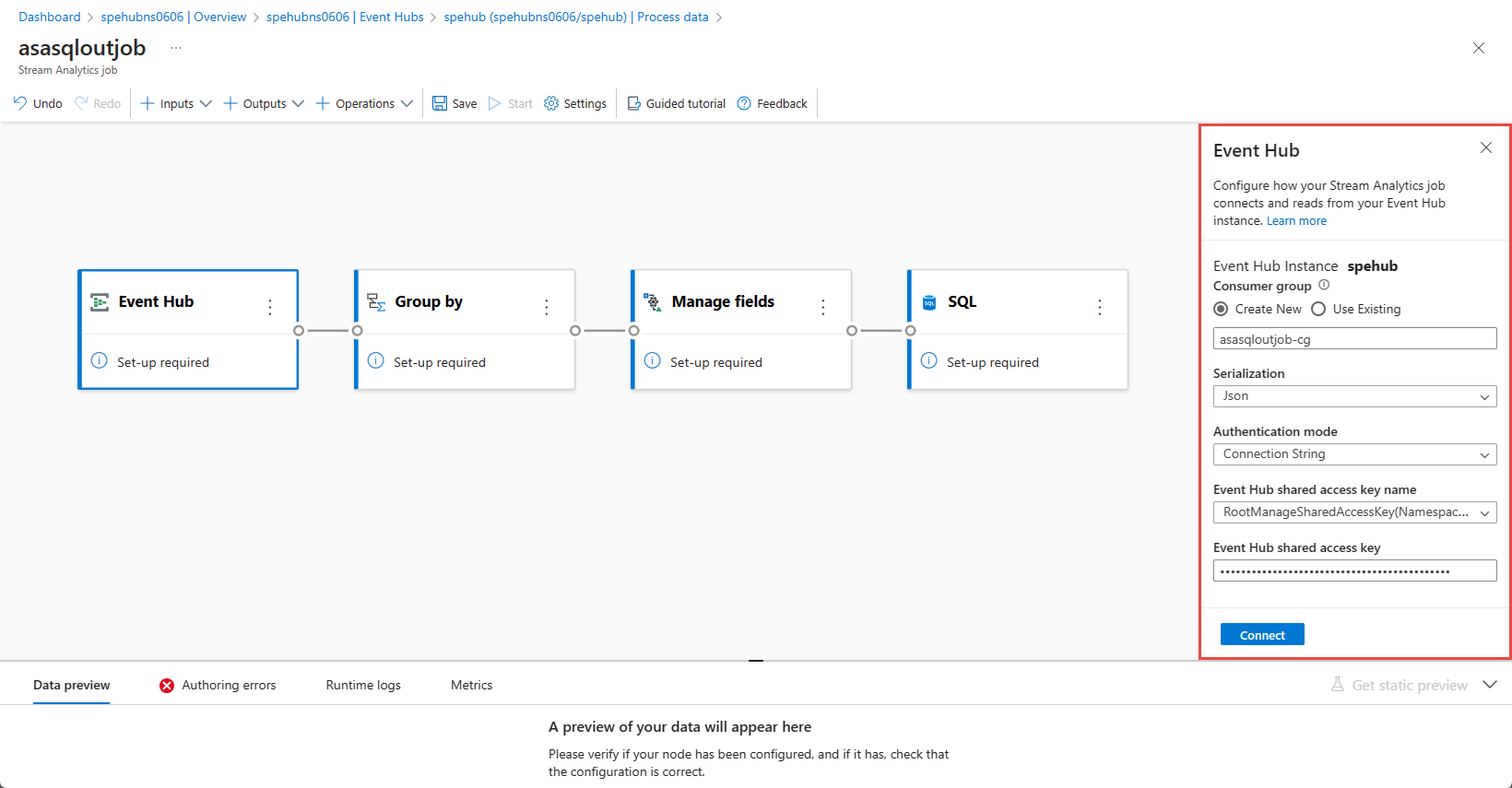
接続が正常に確立されて、Event Hubs インスタンスにデータが含まれると、次の 2 つが表示されます。
入力データに存在するフィールド。 [フィールドの追加] を選択するか、フィールドの横にある 3 つのドット記号を選択して削除、名前の変更、または型の変更を行うことができます。
ダイアグラム ビューの [データ プレビュー] テーブルでの受信データのライブ サンプル。 それは定期的に自動更新されます。 [ストリーミング プレビューの一時停止] を選択すると、サンプル入力データの静的ビューを見ることができます。
![[Data Preview] (データのプレビュー) の下にサンプル データが示されているスクリーンショット。](media/no-code-transform-filter-ingest-sql/no-code-sample-input.png)
データを集計するには、[グループ化] タイルを選びます。 [グループ化] 構成パネルでは、グループ化するフィールドと時間枠を指定できます。
次の例では、価格の平均とシンボルが使用されています。

手順の結果は、[データ プレビュー] セクションで確認できます。

[フィールドの管理] タイルを選択します。 [フィールドの管理] 構成パネルで、[フィールドの追加] ->[インポートされたスキーマ] -> フィールドの順に選択して、出力するフィールドを選択します。
すべてのフィールドを追加する場合は、[すべてのフィールドを追加] を選択します。 フィールドの追加中に、出力に別の名前を指定できます。 たとえば
AVG_ValueをValueにします。 選択内容を保存すると、[データ プレビュー] ペインにデータが表示されます。次の例では、[Symbol] と [AVG_Value] が選択されています。 [Symbol] は [シンボル] にマップされ、[AVG_Value] は [価格] にマップされます。

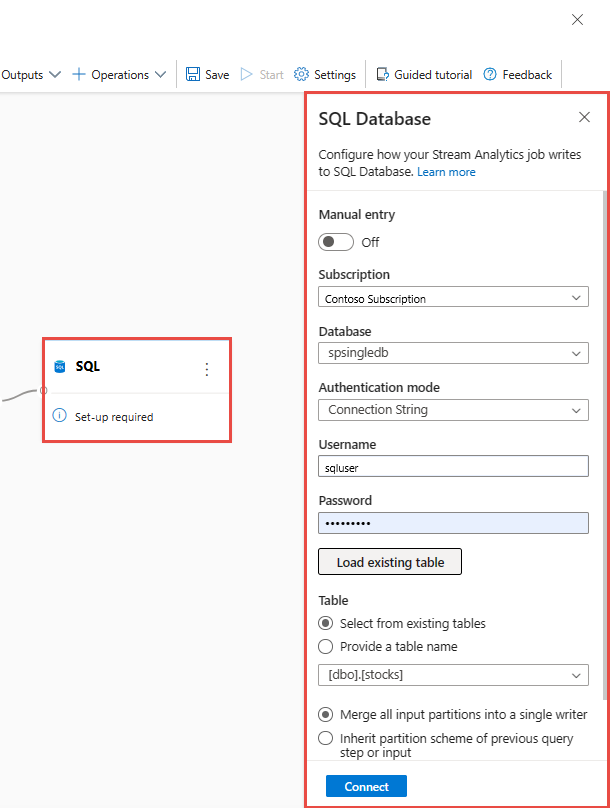
[SQL] タイルを選びます。 [SQL Database] 構成パネルで、必要なパラメーターを入力して接続します。 テーブルが自動的に選択されるようにするには、[Load existing table](既存のテーブルを読み込む) を選択します。 次の例では、
[dbo].[stocks]が選択されています。 次に、 [接続] を選択します。注意
書き込み先として選ぶテーブルのスキーマは、データ プレビューによって生成されるフィールドの数およびその型と、正確に一致している必要があります。
[データ プレビュー] ペインに、SQL データベースに取り込まれたデータのプレビューが表示されます。
![[静的プレビューの取得] と [静的プレビューの更新] のオプションを示すスクリーンショット。](media/no-code-transform-filter-ingest-sql/no-code-output-static-preview.png)
[保存] を選択してから、Stream Analytics ジョブの [開始] を選択します。
![[保存] と [開始] のオプションを示すスクリーンショット。](media/no-code-transform-filter-ingest-sql/no-code-save-start.png)
ジョブを開始するには、次のものを指定します。
ジョブを実行するストリーミング ユニット (SU) の数。 SU は、ジョブに割り当てられるコンピューティングとメモリの量を表します。 3 から始めて、必要に応じて調整することをお勧めします。
[出力データのエラー処理] – データ エラーが原因でジョブの送信先への出力が失敗した場合に必要な動作を指定できます。 既定では、ジョブは書き込み操作が成功するまで再試行します。 出力イベントを削除することもできます。
![[Stream Analytics ジョブの開始] のオプションを示すスクリーンショット。このオプションでは、出力時刻を変更し、ストリーミング ユニットの数を設定し、[出力データのエラー処理] のオプションを選択できます。](media/no-code-transform-filter-ingest-sql/no-code-start-job.png)
[開始] を選択すると、ジョブは 2 分以内に実行を開始します。 下部のペインで [メトリック] パネルが開きます。 このパネルが更新されるまでには若干の時間がかかります。 パネルの右上隅にある [最新の情報に更新] を選択して、グラフを更新します。 Web ブラウザーの別のタブまたはウィンドウで次の手順に進みます。

[Stream Analytics ジョブ] タブの [データの処理] セクションでジョブを確認することもできます。必要に応じて、[メトリックを開く] を選択して監視するか、停止して再起動します。
![実行中のジョブの状態が表示されている [Stream Analytics ジョブ] タブのスクリーンショット。](media/no-code-transform-filter-ingest-sql/no-code-list-jobs.png)
別のブラウザー ウィンドウまたはタブでポータルのイベント ハブに移動し、(前提条件で行ったように) サンプルの Stock data (株価データ) をもう一度送信します。 [Event Hubs インスタンス] ページで、左側のメニューから [データの生成 (プレビュー)] を選択し、[データセット] に対して [Stock data] を選択し、[送信] を選択してサンプル データをイベント ハブに送信します。 [メトリック] パネルが更新されるまでには数分かかる可能性があります。
Azure SQL データベースにレコードが挿入されていることがわかります。
![[開始] を選択した ADLS Gen2 カードへのフィルターと取り込みを示すスクリーンショット。](media/no-code-transform-filter-ingest-sql/event-hub-process-data-templates.png#lightbox)



![[Data Preview] (データのプレビュー) の下にサンプル データが示されているスクリーンショット。](media/no-code-transform-filter-ingest-sql/no-code-sample-input.png#lightbox)




![[静的プレビューの取得] と [静的プレビューの更新] のオプションを示すスクリーンショット。](media/no-code-transform-filter-ingest-sql/no-code-output-static-preview.png#lightbox)
![[保存] と [開始] のオプションを示すスクリーンショット。](media/no-code-transform-filter-ingest-sql/no-code-save-start.png#lightbox)
![[Stream Analytics ジョブの開始] のオプションを示すスクリーンショット。このオプションでは、出力時刻を変更し、ストリーミング ユニットの数を設定し、[出力データのエラー処理] のオプションを選択できます。](media/no-code-transform-filter-ingest-sql/no-code-start-job.png#lightbox)

![実行中のジョブの状態が表示されている [Stream Analytics ジョブ] タブのスクリーンショット。](media/no-code-transform-filter-ingest-sql/no-code-list-jobs.png#lightbox)

Event Hubs の geo レプリケーション機能を使用する場合の考慮事項
Azure Event Hubs では最近、geo レプリケーション機能のプレビューがローンチされました。 この機能は、Azure Event Hubs の Geo ディザスター リカバリー 機能とは異なります。
フェールオーバーの種類が [適用]、レプリケーションの整合性が [非同期]である場合、Stream Analytics ジョブでは、Azure Event Hubs 出力への出力が 1 回のみ行われることは保証されません。
Event Hubs を出力とするプロデューサーである Azure Stream Analytics が、フェールオーバー期間中および Event Hubs によるスロットリング中に、プライマリとセカンダリの間のレプリケーションのラグが最大構成ラグに達すると、ジョブでウォーターマーク遅延を検出する場合があります。
Event Hubs を入力とするコンシューマーである Azure Stream Analytics が、フェールオーバー期間中にウォーターマーク遅延を検出し、フェールオーバーの完了後、データをスキップするか、重複データを見つけようとする場合があります。
これらの注意事項により、Event Hubs のフェールオーバーが完了した直後に、適切な開始時刻で Stream Analytics ジョブを再起動することをお勧めします。 また、Event Hubs の geo レプリケーション機能はパブリック プレビュー段階であるため、現時点で運用環境の Stream Analytics ジョブにこのパターンを使用することはお勧めしません。 現在の Stream Analytics の動作は、Event Hubs の geo レプリケーション機能が一般公開される前に改善され、Stream Analytics の運用ジョブで使用できるようになります。
次のステップ
Azure Stream Analytics の詳細と、作成したジョブを監視する方法を理解してください。